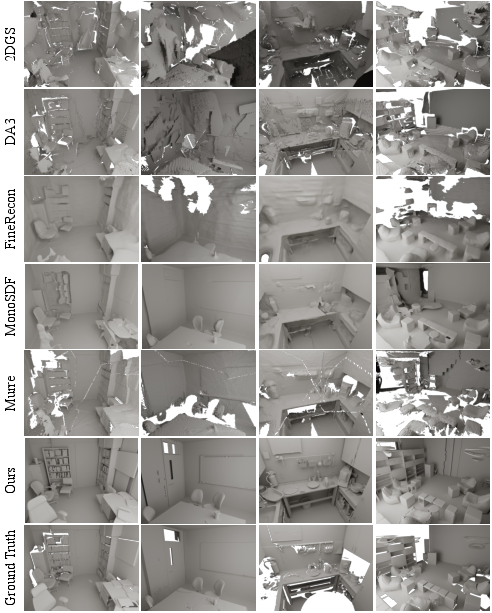
- The paper presents a tightly-coupled framework using Trellis.2 generative priors to produce complete, semantically consistent 3D scene reconstructions from multi-view RGB inputs.
- It employs a projection-based multi-view conditioning pathway with per-chunk latent aggregation and LoRA adaptation to ensure pose-consistent and realistic mesh recovery.
- Empirical results on ScanNet++ and synthetic datasets demonstrate enhanced geometric fidelity, completeness, and physically-based texture recovery for editable PBR meshes.
GenRecon: Bridging Generative Priors for Multi-View 3D Scene Reconstruction
Problem Domain and Motivation
High-fidelity multi-view 3D scene reconstruction from RGB images remains a pivotal challenge for computer vision and graphics, with strict fidelity requirements driven by immersive AR/VR, robotics, and digital content pipelines. Existing paradigms bifurcate into per-scene optimization and feed-forward prediction, both exhibiting strong limitations: optimization-based methods (e.g., neural implicit surfaces, Gaussian splatting) fail in occluded or weakly textured regions, often generating incomplete or oversmoothed geometry; while direct regression models (e.g., depth foundation models, volumetric fusion) recover observed surfaces robustly but lack explicit generative priors, resulting in unstructured, deterministic outputs that do not interpolate plausible content for unobserved regions.
Methodological Advancements
GenRecon proposes a tightly-coupled solution leveraging a strong generative 3D prior—specifically, Trellis.2—to elevate the scene-level mesh reconstruction. The pipeline frames scene recovery as conditional 3D generation across overlapping spatial chunks, jointly synthesizing a coherent mesh covering the entire spatial extent. This approach inherits object-level generative fidelity and semantic completeness, while addressing two critical requirements for scene-level scaling: multi-image conditioning and explicit pose control.
A spatially-grounded, projection-based multi-view conditioning pathway is introduced, lifting DINOv3 image features from each posed RGB input into per-view 3D volumes aligned with each chunk. Aggregation via an IBRNet-style mechanism ensures permutation invariance across views, constructing a 3D conditioning grid that retains geometric correspondence and global context. Conditioned latent generation occurs through parameter-efficient LoRA adaptation, preserving the pretrained prior's structure.
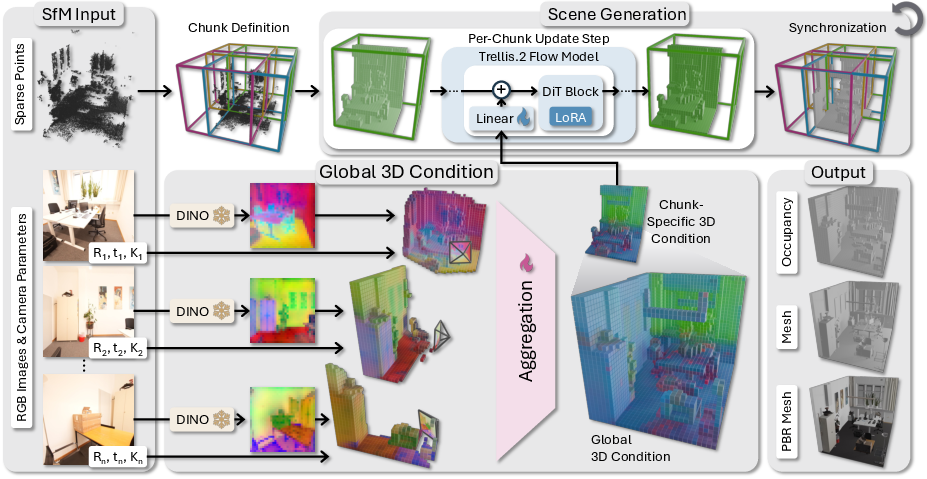
Figure 1: End-to-end pipeline: posed images and sparse SfM points define scene chunks; conditioned 3D features are aggregated and injected into the generative denoiser for joint mesh synthesis.
Within each chunk, generative modeling proceeds via flow-matching, maintaining spatial consistency, even at chunk boundaries, through boundary-sensitive multi-chunk latent aggregation. The final scene-level latent is decoded into a PBR mesh suitable for physically-based rendering and downstream editing.
Empirical Evaluation
The method is benchmarked against state-of-the-art reconstruction pipelines spanning optimization, feed-forward, and diffusion-based priors on both synthetic (3D-FRONT) and real-world (ScanNet++) indoor datasets. GenRecon demonstrates quantitatively superior results across all evaluated metrics: geometric alignment (Chamfer distance), completeness, angular normal errors, perceptual/semantic similarity (LPIPS, CLIP), and F-score within tolerance (10 cm). Notable findings include:
Ablation studies further demonstrate the effectiveness of the projection-based 3D conditioning, with pose-consistent chunk alignment emerging only when this pathway is utilized. Moreover, chunk generation quality scales with the number of conditioning views, yet even single-view inputs yield spatially correct and semantically plausible geometry.

Figure 3: Ablation experiments on unseen SAGE-10k chunks: 3D conditioning enables pose-correct generation from a single view; performance improves with increased view count.
Large-scale scene reconstructions validate the scalability of the chunk-based pipeline, enabling mesh recovery for extensive indoor environments.

Figure 4: High-fidelity mesh generation for large indoor environments, visualized via top-down and detailed close-ups.
Physically-Based Texture Recovery and Relighting
Distinct from most prior feed-forward and optimization pipelines, GenRecon provides editable PBR meshes with material properties (albedo, metallic, roughness), facilitating realistic scene relighting under varying illumination and seamless integration into graphics authoring engines.

Figure 5: PBR channel predictions (lit, albedo, metallic/roughness) for ScanNet++ reconstructions; recovered materials respond plausibly in rendering environments.

Figure 6: Relighting experiments: recovered scenes can be realistically illuminated under arbitrary configurations.
Limitations and Future Directions
While GenRecon sets a new benchmark for indoor scene mesh recovery, known limitations include reduced performance on non-Lambertian surfaces due to limited representation in training data and potential hallucination of geometry in weakly observed regions attributable to the strong prior. Chunk partitioning is not yet adaptive for unusually large or complex spatial extents.
Anticipated developments include enhancing generative prior capabilities via larger and more diverse training corpora, adaptive chunking strategies, explicit modeling for challenging materials, and extension toward open-world reconstruction. The framework lays foundational groundwork for integrating generative modeling in practical, scalable 3D asset pipelines—potentially catalyzing advances in simulation, embodied AI, and real-time content creation.
Conclusion
GenRecon effectively bridges object-level generative 3D priors with multi-view, scene-scale mesh recovery, introducing a spatially-grounded conditioning mechanism and efficient chunk-based synthesis. The achieved mesh fidelity, completeness, and PBR material recovery mark a substantial advance over existing paradigms, supporting practical relighting and editing. The approach is extensible and signals future progress toward robust, high-fidelity scene recovery solutions spanning graphics, robotics, and AI simulation.