Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
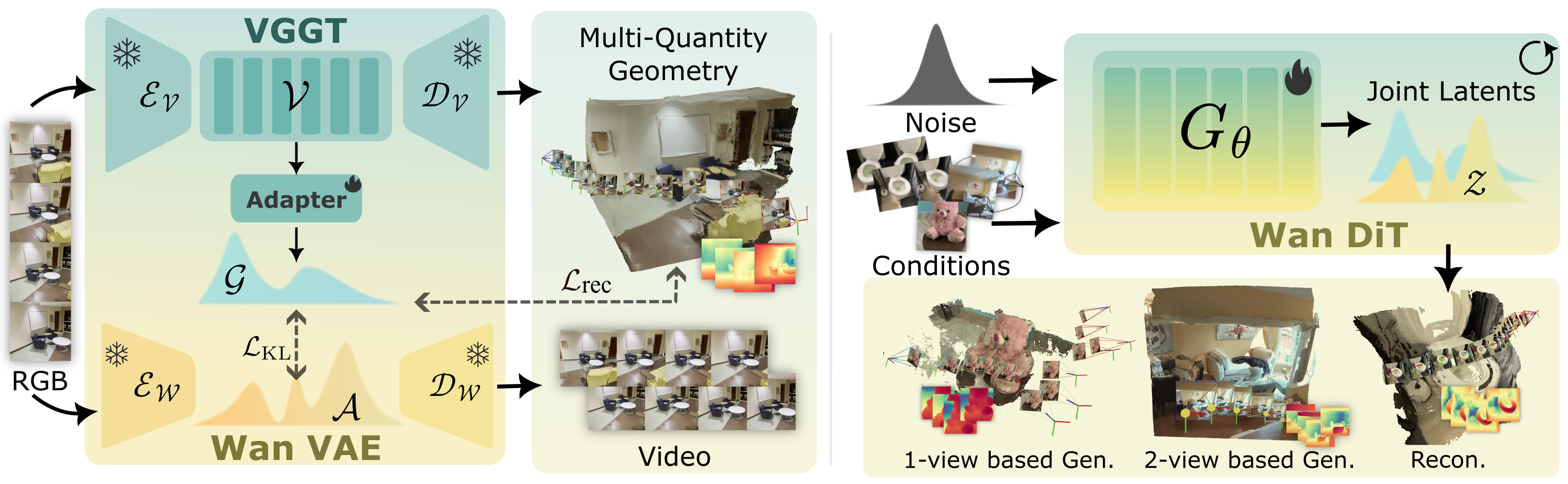
Abstract: We present Gen3R, a method that bridges the strong priors of foundational reconstruction models and video diffusion models for scene-level 3D generation. We repurpose the VGGT reconstruction model to produce geometric latents by training an adapter on its tokens, which are regularized to align with the appearance latents of pre-trained video diffusion models. By jointly generating these disentangled yet aligned latents, Gen3R produces both RGB videos and corresponding 3D geometry, including camera poses, depth maps, and global point clouds. Experiments demonstrate that our approach achieves state-of-the-art results in single- and multi-image conditioned 3D scene generation. Additionally, our method can enhance the robustness of reconstruction by leveraging generative priors, demonstrating the mutual benefit of tightly coupling reconstruction and generative models.
















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Gen3R, a new AI method that can create short videos and their matching 3D scenes at the same time. Think of it as a system that not only paints a moving picture but also builds the scene’s 3D shape—so you can tell where the camera is, how far objects are, and what the whole space looks like.
What questions does it try to answer?
- Can we make a model that quickly creates both good-looking videos and accurate 3D geometry from just one or two input images?
- Can we combine the strengths of two kinds of AI:
- “Reconstruction” models that are great at understanding 3D from images, and
- “Diffusion” models that are great at generating realistic-looking videos?
- If we combine them well, will the 3D be more consistent and the videos look better, without slow, heavy optimization?
How does the method work? (Simple explanation)
Gen3R works by getting two expert AIs to “speak the same language” so they can work together:
- Two experts:
- A reconstruction expert (VGGT): Very good at figuring out 3D stuff—like depth, camera position, and point clouds—from images. Inside, it uses “tokens” (kind of like compact notes about the scene).
- A video-generation expert (a diffusion model): Very good at making realistic videos from noise, using a “latent space” (a compressed, hidden form of the video).
- A translator (the adapter):
- The reconstruction expert’s tokens and the video expert’s latents don’t match naturally.
- The paper trains an “adapter,” like a translator, that converts the reconstruction tokens into a compact “geometry latent” that matches the video model’s format and size.
- Making the two match better (alignment):
- Just translating shape isn’t enough—these latents also need to follow similar “distributions” (think: similar style or range of values).
- They add a gentle rule (a KL loss) to push the geometry latents to have a distribution similar to the video latents. This makes joint generation stable and high-quality.
- Joint generation:
- Now that both the appearance (how it looks) and geometry (how it’s shaped) live in a compatible latent space, the diffusion model is fine-tuned to generate both at once.
- The system can take one or two input images (your starting views), optionally camera hints, and a short text prompt, and then generate:
- A video (RGB frames)
- Depth maps (how far each pixel is)
- Camera poses (where the camera is and where it points)
- A global point cloud (a 3D “dot” model of the scene)
- Fast decoding:
- The appearance latents are decoded into video frames.
- The geometry latents go through the adapter back into tokens, then the reconstruction model’s heads turn those into depth, camera, and 3D point clouds.
- This is “feed-forward,” meaning it runs in one pass—no slow, repeated optimization loops.
Quick definitions:
- Diffusion model: Starts with pure noise and learns to “denoise” it step by step until a clear video appears—like sculpting a statue by removing marble dust.
- Latent space: A compressed “secret code” of images or videos that’s faster to work with.
- Tokens: Summaries of image patches used by transformers—like notes a student writes while reading.
- Point cloud: A 3D picture made of points, like stars forming the shape of an object.
- Depth map: A picture where brightness shows how far things are from the camera.
- Camera pose: The camera’s position and direction in 3D space.
What did they find?
- Higher video quality: Compared to strong baselines, Gen3R makes clearer, sharper, and more consistent videos from one or two input images.
- Better 3D geometry: It produces more complete and accurate 3D shapes (point clouds) with good global consistency—objects line up better across views.
- Works with different inputs: It can generate from:
- one image (imagining the rest),
- two images (filling in the in-between views),
- or a short sequence (feed-forward reconstruction).
- Strong camera control: The estimated camera motions are more accurate, so the virtual camera moves realistically through the scene.
- Improves reconstruction too: Even when used just to reconstruct (not to generate), the method can be more robust than the original reconstruction model alone, because the generative part helps fill in missing or uncertain details.
In short: By making the geometry and appearance latents “disentangled but aligned,” the model keeps the benefits of both worlds—sharp looks and solid 3D.
Why is this important?
- Faster and more practical: Feed-forward generation means you can create 3D-aware videos quickly, which is useful for games, virtual reality, simulation, and robot training.
- Better training data: It can generate realistic scenes with consistent 3D, helping train other AI systems (like self-driving or AR).
- Creative tools: Artists and designers can create immersive scenes from a single picture or a pair of photos.
- A new recipe for AI design: The idea of aligning the hidden spaces of different expert models (reconstruction and generation) can inspire future systems that combine strengths without needing massive 3D datasets.
Bottom line
Gen3R shows that if you teach two expert AIs to share a common “language” in their hidden representations, you can get a fast, flexible system that makes both beautiful videos and reliable 3D geometry—all from minimal input. This could speed up content creation and improve many 3D applications in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete, unresolved issues and limitations identified in the paper that future work could address:
- Dependence on a specific reconstruction backbone (VGGT): It is unclear how well the approach transfers to other foundation reconstruction models (e.g., Dust3R, MAST3R, MAST3R variants) or to future VGGT successors; a systematic study of portability is missing.
- Geometry latent alignment choice: The method aligns geometry latents to the RGB latent distribution via a KL term, but no alternatives are explored (e.g., adversarial, contrastive, MMD, optimal transport) nor is a theoretical justification provided for why matching to appearance latents is optimal for geometry modeling.
- Sensitivity to loss balancing: There is no analysis of how the weighting of the reconstruction vs. KL alignment losses affects convergence, stability, and the trade-off between geometry fidelity and generative flexibility.
- Latent dimensionality and layout design: The geometry latent channel size (e.g., c=16), spatial-temporal downsampling, and the choice to concatenate latents along width are fixed; no ablation assesses alternative dimensionalities, concatenation axes, or more expressive fusion (e.g., cross-attention) and their impact on quality and compute.
- Token selection and compression strategy: Geometry tokens are taken from four specific VGGT layers; there is no study of which layers (or learned layer aggregation) best preserve geometry, nor of different adapter architectures or compression ratios.
- Distributional alignment granularity: The KL regularization appears to match marginal latent distributions but may ignore spatiotemporal or modality-specific structure; it is unknown whether matching higher-order or structured statistics would further improve 3D consistency.
- Geometry-appearance disentanglement: The paper asserts “disentangled yet aligned” latents but does not quantify disentanglement (e.g., via mutual information or intervention tests), nor analyze leakage where appearance cues may unduly influence geometry (or vice versa).
- Camera representation and metric scale: Camera parameters are 9D, but metric scale is unresolved (evaluation uses Umeyama alignment). It remains unclear whether the method can produce metric-scale-consistent cameras/depths or how to enforce/learn absolute scale.
- Long-horizon temporal consistency and drift: The model is trained and evaluated mostly on 49-frame clips at 560×560; there is no analysis of drift, loop-closure consistency, or global coherence over longer trajectories.
- Robustness to camera intrinsics/aspect ratios: Inputs are resized to square crops; behavior under varied focal lengths, aspect ratios, rolling shutter, and OOD intrinsics remains untested.
- Dynamic/non-rigid scenes: The approach presumes static geometry; it is unknown how it handles moving objects, articulated motion, or general 4D geometry. No evaluation on dynamic-scene datasets is provided.
- Text-only conditioning: Although text prompts are included during training, the method is not evaluated for pure text-to-3D(-video) generation; capability, controllability, and failure modes in text-only conditioning remain open.
- Geometry-RGB cross-consistency: There is no explicit evaluation of whether the generated RGB frames and predicted geometry are mutually consistent (e.g., via reprojection errors, silhouette consistency, or photometric consistency checks).
- Evaluation breadth for 3D quality: Geometry is assessed only via point-cloud accuracy/completeness/CD post-alignment; no surface-based metrics (e.g., F-Score, normal error), mesh quality, or multi-view consistency metrics are reported.
- Error propagation from VGGT: During diffusion fine-tuning, the geometry target latents originate from VGGT; the extent to which Gen3R inherits, amplifies, or corrects VGGT’s systematic errors (e.g., in low-texture or reflective regions) is not quantified.
- Completeness vs. accuracy trade-offs: VGGT exhibits high accuracy but low completeness (and vice versa for generative variants). Strategies to control this trade-off (e.g., priors for unseen regions, uncertainty-aware completion) are not explored.
- Uncertainty estimation: The pipeline does not quantify uncertainty in geometry (depth/camera) or appearance; downstream users cannot distinguish confident from hallucinated regions.
- Camera controllability limits: While AUC@30 is reported, there is no study of the range of camera motions the model can reliably follow, failure modes under large baselines, or sensitivity to noisy/partial camera inputs.
- Robustness to occlusion and sparse conditioning: The method supports 1–2 input views but lacks a systematic evaluation under extreme occlusions, highly sparse conditioning, or strong viewpoint extrapolations.
- Domain generalization and shift: The model is trained on a mix of datasets (including synthetic and driving), but evaluations are reported on a subset; performance under severe domain shifts (e.g., night, adverse weather, unusual lenses) is not reported.
- Output representation limitations: The method produces point clouds and per-view depth, not meshes or differentiable 3D representations suited for rendering (e.g., Gaussians, NeRFs). Conversions to usable surface representations and their quality are unaddressed.
- Lack of joint optimization at decode time: The geometry is obtained by per-frame unprojection with generated cameras; there is no global refinement or joint optimization (e.g., pose-geometry bundle adjustment, surface fusion), leaving room for drift and misalignment.
- Scaling to higher resolutions and longer sequences: Training and inference at 560×560 with 49 frames may limit use in high-fidelity content creation; memory, compute, and quality behavior at larger scales are not characterized.
- Compute and accessibility: Training uses 24 H20 GPUs with accumulation; the inference cost and throughput are not reported. Practicality for broader use and deployment constraints remain unclear.
- Failure case analysis: The paper does not detail typical failure modes (e.g., thin structures, textureless walls, specular/transparent materials), nor propose mitigations.
- Data and supervision assumptions: Although no explicit 3D GT is required, the approach relies on datasets with camera calibrations; it is unknown how to train or adapt in scenarios without reliable cameras (e.g., self-supervised or weakly supervised setups).
- Interoperability with downstream pipelines: How well the generated outputs integrate into SLAM, simulation, or content creation workflows (e.g., post-processing, editing, relighting) is not evaluated.
- Ethical and safety considerations: There is no discussion of risks from hallucinated or incorrect geometry/camera predictions in downstream robotics, AR, or autonomous systems, nor mechanisms to detect or prevent unsafe failure modes.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, based on Gen3R’s joint generation of RGB video and 3D geometry (camera poses, depth, point clouds) from one or a few input images, using a feed-forward pipeline.
- Industry (Creative Media/Entertainment)
- Rapid previsualization and virtual production: Turn a concept frame or location photo into a short, camera-controllable shot with consistent 3D structure for storyboarding and blocking.
- Potential tools/workflows: A “Gen3R Studio” plugin for Blender/Unreal/Unity that ingests 1–2 reference frames, generates a short video + point cloud, then converts point clouds to meshes (e.g., via Poisson, TSDF) or 3D Gaussian Splatting for real-time previews.
- Assumptions/dependencies: Requires GPU inference; point clouds need meshing/material inference for final use; hallucinated geometry should be vetted before on-set use.
- Background and set extension: Generate plausible, depth-consistent scene backplates from sparse references, improving occlusion and compositing in 2D/3D pipelines.
- Assumptions/dependencies: Quality varies with domain shift; lighting/material realism may require further refinement.
- Industry (Gaming/AR/VR)
- Level blockout from concept images: Produce preliminary 3D layouts (camera poses + depth + global point cloud) from 1–2 concept frames, then refine in-engine.
- Potential tools/workflows: Unity/Unreal importers to convert outputs to meshes or 3DGS; in-editor tools to retarget/clean camera paths and scale.
- Assumptions/dependencies: Geometry is non-metric (scale ambiguity); requires post-processing to ensure navigability and physics.
- Room-scale AR/VR scenes from few images: Prototype interactive 6-DoF experiences for design reviews and demos.
- Assumptions/dependencies: Temporal coherence and pose consistency are good, but safety-critical AR uses need further validation.
- Industry (Real Estate/Marketing)
- Quick virtual tours from limited photos: Generate short fly-throughs with depth for realistic parallax and occlusion, suitable for listings or previews.
- Potential tools/workflows: Broker tools that accept a few images and output tours; optional mesh conversion for web viewers.
- Assumptions/dependencies: Geometry may be plausible rather than exact; disclaimers advised to avoid misrepresentation.
- Industry (Autonomous Driving/Simulation)
- Scenario synthesis and augmentation: Generate plausible multi-view sequences with aligned geometry for rare or edge-case scenes from sparse references.
- Potential tools/workflows: Data augmentation pipelines that take a dashcam frame and produce additional viewpoints + depth; export to simulators.
- Assumptions/dependencies: Not metrically accurate; use for data augmentation, not ground truth.
- Industry (Construction/Architecture – AEC)
- Rapid site capture from minimal imagery: Create approximate as-built context from 1–2 photos for early-stage design visualization.
- Potential tools/workflows: Pipeline to align outputs with known CAD scale; mesh and texture for BIM viewers.
- Assumptions/dependencies: Not a substitute for survey-grade capture; scale and accuracy must be calibrated externally.
- Industry (E-commerce/Retail)
- Scene staging for product visuals: Generate photorealistic, depth-consistent backgrounds from a single product-in-context image for catalog imagery or ads.
- Assumptions/dependencies: No semantic editing yet; ensure product/brand guidelines are met.
- Robotics (R&D)
- Fast scene priors for navigation and planning: From one or two onboard frames, infer geometry and poses to prime SLAM/VO, fill occlusions, or simulate additional views.
- Potential tools/workflows: ROS nodes that wrap Gen3R to produce depth/pose priors; blending with classic SLAM back-ends.
- Assumptions/dependencies: Outputs may be non-metric and may hallucinate; use as priors with uncertainty, not as ground truth.
- Academia (Computer Vision/Graphics)
- Benchmarks and research on joint appearance–geometry generation: Use Gen3R’s disentangled, aligned latent spaces to study controllability, geometry-appearance trade-offs, and priors for reconstruction.
- Potential tools/workflows: Ablation-friendly training scripts to toggle KL alignment, conditions (1-view/2-view), and camera cues.
- Assumptions/dependencies: Requires access to pre-trained VGGT and video diffusion (e.g., Wan2.1) and multi-view datasets.
- Software (Developer Tools)
- Authoring SDKs and converters: Build utilities to convert Gen3R outputs (point clouds, depth, camera) to meshes/3DGS/NeRF-compatible formats; integrate with DCCs/game engines.
- Assumptions/dependencies: Quality control needed for topology and materials; runtime cost manageable but GPU recommended.
- Daily Life
- “3D memories” from a single photo: Generate short move-around videos with depth-aware parallax for social media or personal archives.
- Assumptions/dependencies: Cloud inference likely; privacy concerns for personal spaces; results are approximate reconstructions.
- Policy/Compliance (Near-term guidance)
- Disclosure and labeling: Introduce automatic metadata or watermarks for generated 3D content in listings/ads to reduce misrepresentation risks.
- Assumptions/dependencies: Requires integration with content management systems and agreement on provenance standards.
Long-Term Applications
These use cases are promising but require additional research, scaling, or productization (e.g., metric accuracy, multi-sensor fusion, real-time performance, domain adaptation).
- Robotics and Autonomy (Safety-Critical)
- Generative priors in-the-loop SLAM and planning: Tight integration where Gen3R provides uncertainty-aware geometry to improve robustness under low-texture/occlusion.
- Dependencies: Uncertainty estimates, metric scale calibration, failure detection; rigorous evaluation and certification.
- On-device, near real-time inference: Running on robot/AR hardware for live scene completion and camera control.
- Dependencies: Model compression/distillation, accelerators, streaming architectures.
- Digital Twins (Smart Cities, Facilities, Energy)
- City- or facility-scale generative recon from sparse imagery: Populate missing geometry and generate consistent video for inspections, training, and planning.
- Dependencies: Multi-sensor fusion (LiDAR, IMU), global scale and coordinate frames, semantic layers, PBR material inference.
- Healthcare and Surgical Simulation
- Operating room or organ-level scene generation from limited views to aid planning/training.
- Dependencies: Domain-specific training with medical data, strict validation, privacy and regulatory approvals.
- Forensics/Cultural Heritage
- Reconstruction of scenes from limited archival or incident photos for analysis or preservation, including plausible completion of occluded regions.
- Dependencies: Provenance tracking, uncertainty quantification, auditability to separate evidence from generated content.
- Advanced Content Creation
- Text + sparse-image scene design tools: High-level control over camera paths, layout, and style with guaranteed 3D consistency, feeding directly into real-time engines.
- Dependencies: Fine-grained controllability in latent space, semantic/structure editing, robust meshing/material pipelines.
- Autonomous Driving/Simulation-at-Scale
- Procedural generation of long, consistent driving sequences from minimal seeds, with controllable camera/ego-motion and plausible geometry for data diversity.
- Dependencies: Traffic agents, semantics, and physics; long-horizon temporal consistency; bias mitigation.
- Standards and Policy
- Provenance and safety standards for AI-generated 3D content: Watermarking, disclosure norms, and acceptable-use policies in real estate, advertising, and public communication.
- Dependencies: Cross-industry coordination, legal frameworks, content validation tools.
- Multimodal World Models
- Unified appearance–geometry latent models that learn temporal dynamics, semantics, and physics for predictive simulation and interactive agents.
- Dependencies: Large-scale, multi-sensor datasets; architectures for dynamics and uncertainty; compute scaling.
- Consumer AR Glasses/Phones
- Instant, on-device 6-DoF scene generation for immersive memories, navigation hints, and creative tools.
- Dependencies: Efficient models and on-device AI, battery/thermal constraints, privacy-preserving on-device processing.
- End-to-End 3D Asset Pipelines
- Automatic mesh and material reconstruction (PBR), semantic tagging, and scene graph generation directly from Gen3R latents for turnkey asset libraries.
- Dependencies: Reliable meshing/UVs/material inference; consistent scale; quality metrics and auto-QC.
Cross-Cutting Assumptions and Dependencies (affecting feasibility)
- Technical
- Outputs are point clouds/depth with camera poses; conversion to production-ready meshes or 3D Gaussian Splatting is typically required.
- Metric scale is not guaranteed without external calibration; poses are consistent but may be up to scale.
- Model quality depends on training data distribution; domain shifts (e.g., specialized industrial/medical scenes) reduce reliability without adaptation.
- Compute needs: Training is heavy; inference requires a modern GPU; real-time use demands significant optimization.
- Reliability and Ethics
- Geometry can be plausible but incorrect; avoid use as ground truth in safety-critical or regulatory contexts without validation.
- Content provenance and consent: Training data licenses and user privacy for captured spaces must be respected; generated content should be labeled where material.
- Integration
- Downstream pipelines must handle uncertainty, scaling, and unit systems; toolchains for meshing, material inference, and editing are necessary.
- For robotics/SLAM, treat outputs as priors with uncertainty and fuse with sensor data to ensure robustness.
Glossary
- 3D Gaussian Splatting (3DGS): A 3D representation that models scenes as collections of anisotropic Gaussian primitives for fast differentiable rendering. Example: "and 3DGS~\cite{3dgs, 3dgsreview, rtg_slam, ges}"
- AUC@30: Area Under the Curve up to a 30-degree threshold used to evaluate camera pose estimation accuracy by combining rotation and translation errors. Example: "reporting AUC@30, which combines both Relative Rotation Accuracy~(RRA) and Relative Translation Accuracy~(RTA)"
- Asymmetric VAE: A variational autoencoder where the encoder and decoder have different structures or modalities (e.g., images to geometry tokens and back). Example: "We aim to recast VGGT~\cite{vggt} as an asymmetric geometry VAE"
- Chamfer Distance (CD): A distance metric between two point sets measuring average nearest-neighbor distances in both directions. Example: "and finally compute Accuracy, Completeness, and Chamfer Distance~(CD)~\cite{cd}"
- Classifier-Free Guidance (CFG): A technique for conditioning diffusion models that balances conditional and unconditional predictions to control generation strength. Example: "the text prompt is dropped with a probability for CFG~\cite{cfg}"
- Cost volume: A tensor that encodes matching costs across disparities or depths for multi-view or stereo reconstruction. Example: "it requires multi-view inputs to construct cost volumes"
- Differentiable rendering: Rendering that allows gradients to flow from image-space losses back to 3D scene parameters for learning. Example: "and using differentiable rendering to train directly on 2D images"
- DPT heads: Dense Prediction Transformer heads that decode transformer tokens into dense outputs like depth or normals. Example: "decoded by several individual DPT heads~\cite{dpt}"
- Farthest Point Sampling (FPS): A sampling strategy that iteratively selects points farthest from the current set to cover a point cloud evenly. Example: "using Farthest Point Sampling~(FPS)~\cite{pointnetpp}"
- Feed-forward 3D scene generation: Generating 3D content in a single pass without per-scene optimization, often via learned models. Example: "have extended video diffusion frameworks to feed-forward 3D scene generation"
- Feed-forward reconstruction model: A model that predicts scene geometry directly from images in a single forward pass, without iterative optimization. Example: "transformer-based feed-forward reconstruction models, such as Dust3R~\cite{dust3r} and VGGT~\cite{vggt}"
- Geometric latents: Latent representations that encode scene geometry for generative modeling or decoding into depth, pose, and point clouds. Example: "produces geometric latents "
- Geometry tokens: Intermediate transformer tokens carrying geometric information (e.g., depth, pose) at reduced spatial resolution. Example: "encodes them into high-dimensional geometry tokens "
- Incremental outpainting: Extending images or views beyond their borders progressively to cover new areas, often for multi-view generation. Example: "or incremental outpainting~\cite{scenescape, luciddreamer, wonderjourney, wonderworld,3drecipe}"
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from another; used to align latent distributions. Example: "we impose a KL loss on the geometry adapter"
- Latent Diffusion Model (LDM): A diffusion model that operates in a compressed latent space (e.g., VAE space) rather than pixel space for efficiency. Example: "follow the Latent Diffusion Model paradigm"
- Latent manifold: The structured, lower-dimensional space learned by a model that captures underlying factors of variation. Example: "intrinsic latent manifold learned by reconstruction models"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric comparing images using deep features. Example: "compute PSNR, SSIM~\cite{ssim}, and LPIPS~\cite{lpips}"
- Multi-view synthesis: Generating new views from one or more input images by modeling scene geometry and appearance across viewpoints. Example: "followed by 3D reconstruction through multi-view synthesis~\cite{cat3d, syncdreamer, zeronvs, mvdream, reconfusion, gaussvideodreamer, dimensionx, reconx, mvsplat360, genxd}"
- NeRF: Neural Radiance Fields; a neural representation that models a continuous 3D scene to render novel views. Example: "such as NeRF~\cite{nerf, mipnerf, mipnerf360, zipnerf}"
- PSNR: Peak Signal-to-Noise Ratio; a fidelity metric comparing generated images to ground truth in terms of reconstruction error. Example: "compute PSNR, SSIM~\cite{ssim}, and LPIPS~\cite{lpips}"
- Relative Rotation Accuracy (RRA): A metric evaluating the accuracy of estimated relative camera rotations. Example: "Relative Rotation Accuracy~(RRA)"
- Relative Translation Accuracy (RTA): A metric evaluating the accuracy of estimated relative camera translations. Example: "Relative Translation Accuracy~(RTA)"
- Score distillation sampling (SDS): A technique that distills gradients from a diffusion model’s score function to optimize a target (e.g., a 3D representation). Example: "score distillation sampling~(SDS)~\cite{dreamfusion, magic3d, prolificdreamer, dreamgaussian}"
- SSIM: Structural Similarity Index Measure; an image quality metric modeling perceived structural similarity. Example: "compute PSNR, SSIM~\cite{ssim}, and LPIPS~\cite{lpips}"
- Token-to-Latent Adapter: A learned module that maps high-dimensional tokens to a compact latent space (and back) for joint generation. Example: "Token-to-Latent Adapter"
- Umeyama algorithm: A method for estimating similarity transformation (scale, rotation, translation) between two point sets. Example: "We first use the Umeyama algorithm~\cite{umeyama} to align the generated point clouds"
- Unproject (unprojection): Converting per-pixel depth and camera intrinsics/extrinsics into 3D points in world coordinates. Example: "we unproject the depth maps using the generated camera parameters"
- VAE: Variational Autoencoder; an encoder–decoder model that learns a probabilistic latent space with a KL prior for generative tasks. Example: "training a VAE to learn a compact latent space for 3D scenes"
- VBench Score: An evaluation suite of metrics for video generation quality and consistency (e.g., I2V Subject, I2V Background, Imaging Quality). Example: "We additionally report the VBench Score~\cite{vbench, vbenchpp}"
- Video diffusion model: A diffusion-based generative model that synthesizes videos by denoising sequences in a latent or pixel space. Example: "we fine-tune a video diffusion model~\cite{wan}, denoted as "
- VQ-VAE: Vector-Quantized VAE; a VAE variant using discrete latent codes via vector quantization. Example: "most LDMs use VAE or VQ-VAE to constrain the latents"
Collections
Sign up for free to add this paper to one or more collections.