- The paper introduces a task-agnostic approach that conditions regeneration on both degraded 3D shapes and 2D guidance using VecSet latent tokens.
- It designs an efficient token concatenation conditioning mechanism that outperforms traditional cross-attention methods in restoring fine details.
- Automated paired dataset construction enables robust application in shape enhancement, reconstruction, and editing across diverse real-world scenarios.
3D-ReGen: A Unified Framework for 3D Geometry Regeneration
3D content creation frequently involves multimodal interactions bridging 2D concept art with various forms of coarse 3D data, such as noisy scans or block-outs. Most prior work on 3D generative modeling focuses on overfit-to-sample workflows, lacking explicit control and versatility in downstream tasks like enhancement, editing, and reconstruction. "3D-ReGen: A Unified 3D Geometry Regeneration Framework" (2604.28134) proposes a generalized, task-agnostic approach: conditioning generative output not just on a 2D image but also on an auxiliary, potentially degraded, 3D shape. Formally, the target distribution is p(H∣L,I), where H is high-information geometry, L is low- or degraded input geometry, and I is an optional guidance image.
Architectural Design and Conditioning Mechanism
The core innovation of 3D-ReGen is an architectural shift to a unified mechanism based on the VecSet latent space. Both the conditioning and target shapes (L, H) are encoded using VecSet transformer-based encoders, yielding a compact set of latent tokens. Conditioning is implemented via simple concatenation of VecSet tokens (after zero-initialized MLP transformation and positional embedding addition) with noisy generative tokens—yielding flexible, efficient conditioning that outperforms cross-attention-based alternatives (as demonstrated empirically).
The VecSet representation allows for variable token counts; coarse shapes are encoded with fewer tokens, reducing computational load without loss of fidelity.
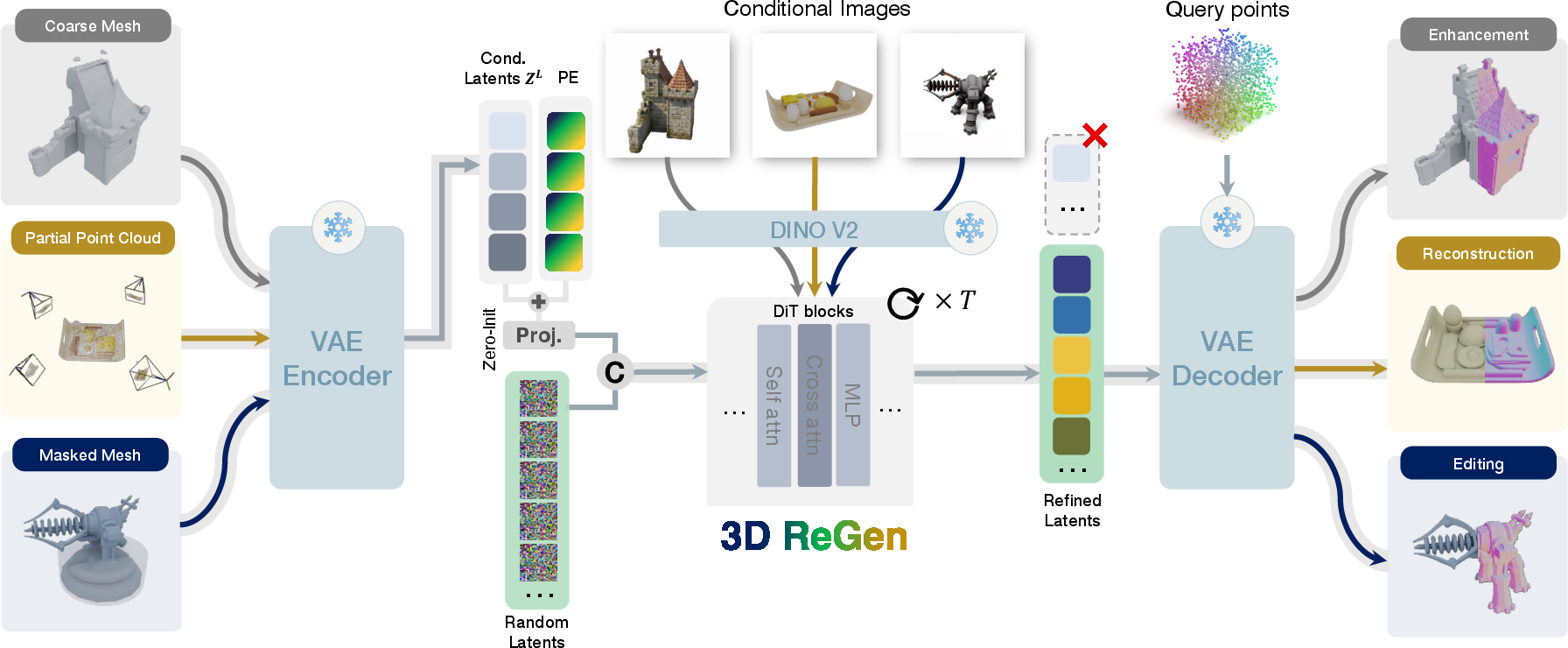
Figure 1: 3D-ReGen's architecture employs explicit VecSet conditioning, permitting structured control of regenerated geometry and fine-grained detail fidelity.
Automatic Paired Dataset Construction
A key challenge addressed is the lack of paired (H,L) data for diverse regeneration tasks. The paper presents principled pipelines for generating such pairs from large unannotated 3D datasets via task-specific augmentations:
- Enhancement: Compose multi-object grids and degrade VecSet tokens with moderate diffusion noise, mimicking typical generative errors in compositional synthesis.
- Reconstruction: Use photogrammetry outputs (VGGT) from random views as L, aligned with ground-truth H.
- Editing: Mask regions on H and provide image guidance for inpainting, representing edited H0.
This procedure yields datasets with realistic degradation patterns matching practical scenarios more closely than generic smoothing or mesh simplification.
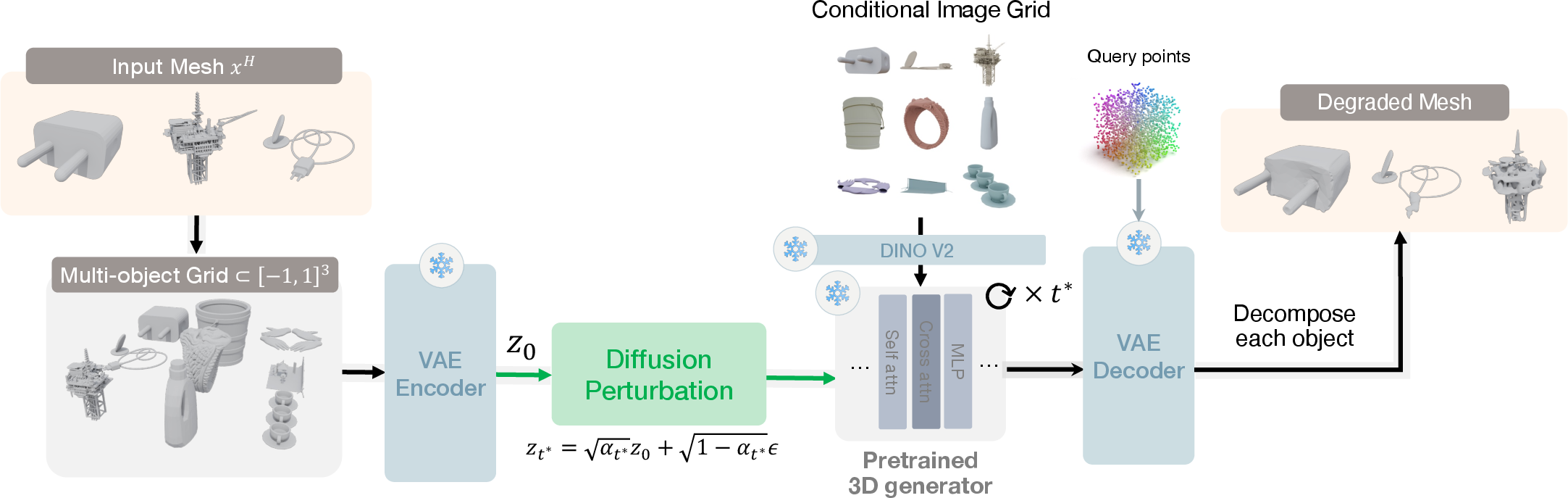
Figure 2: The pipeline creates compositional enhancement pairs by arranging high-quality meshes, applying diffusion-based degradation, and extracting lower-fidelity mesh tokens as H1.
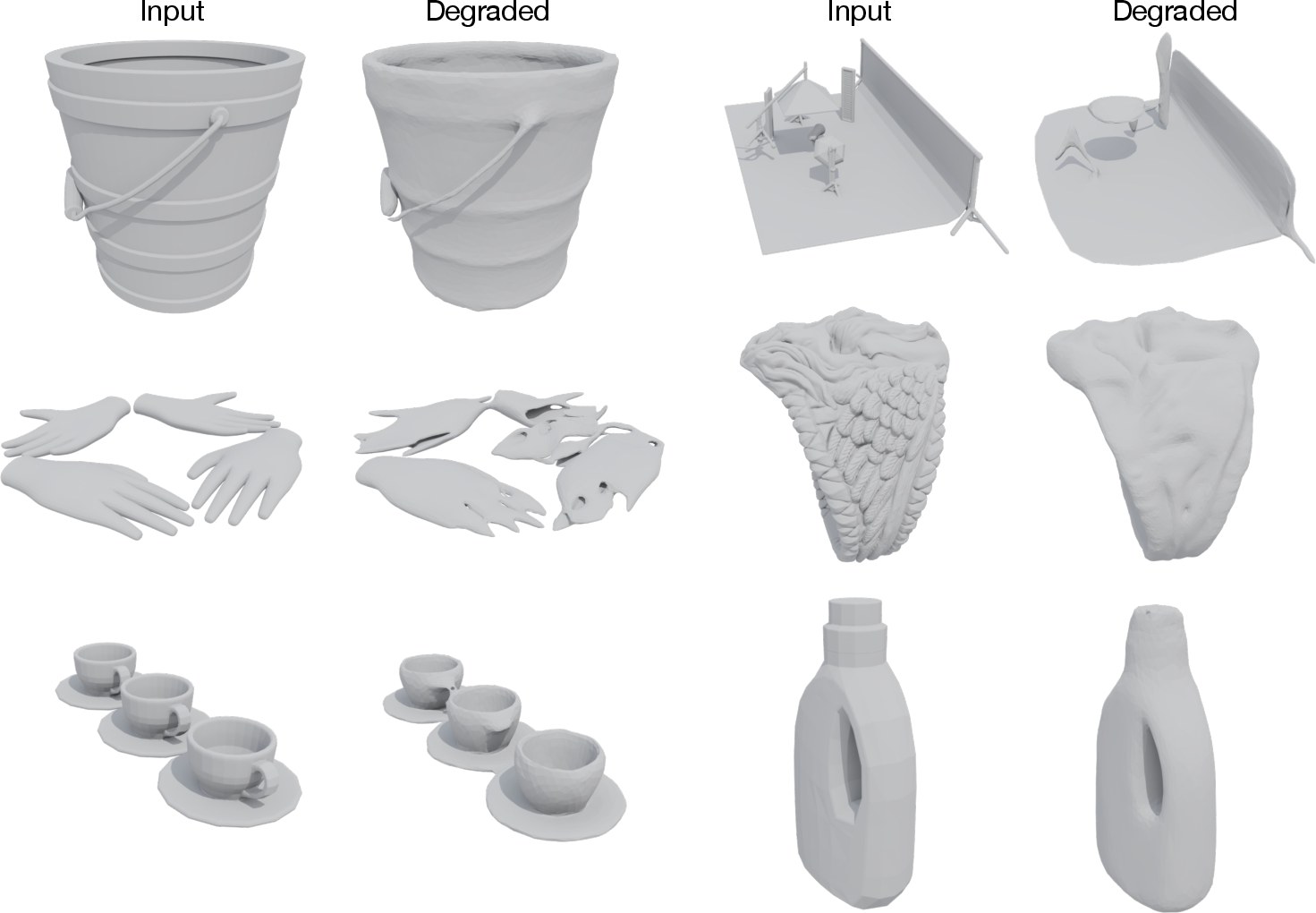
Figure 3: Paired examples illustrating the geometric diversity and controlled degradation achievable via synthetic grid-based augmentation.
Application Domains
Compositional Shape Enhancement
3D-ReGen upgrades low-resolution or corrupted scene components, leveraging the global scene context and object-level decomposition (AutoPartGen segmentation), and achieves superior detail restoration and geometric fidelity relative to specialized enhancement baselines.
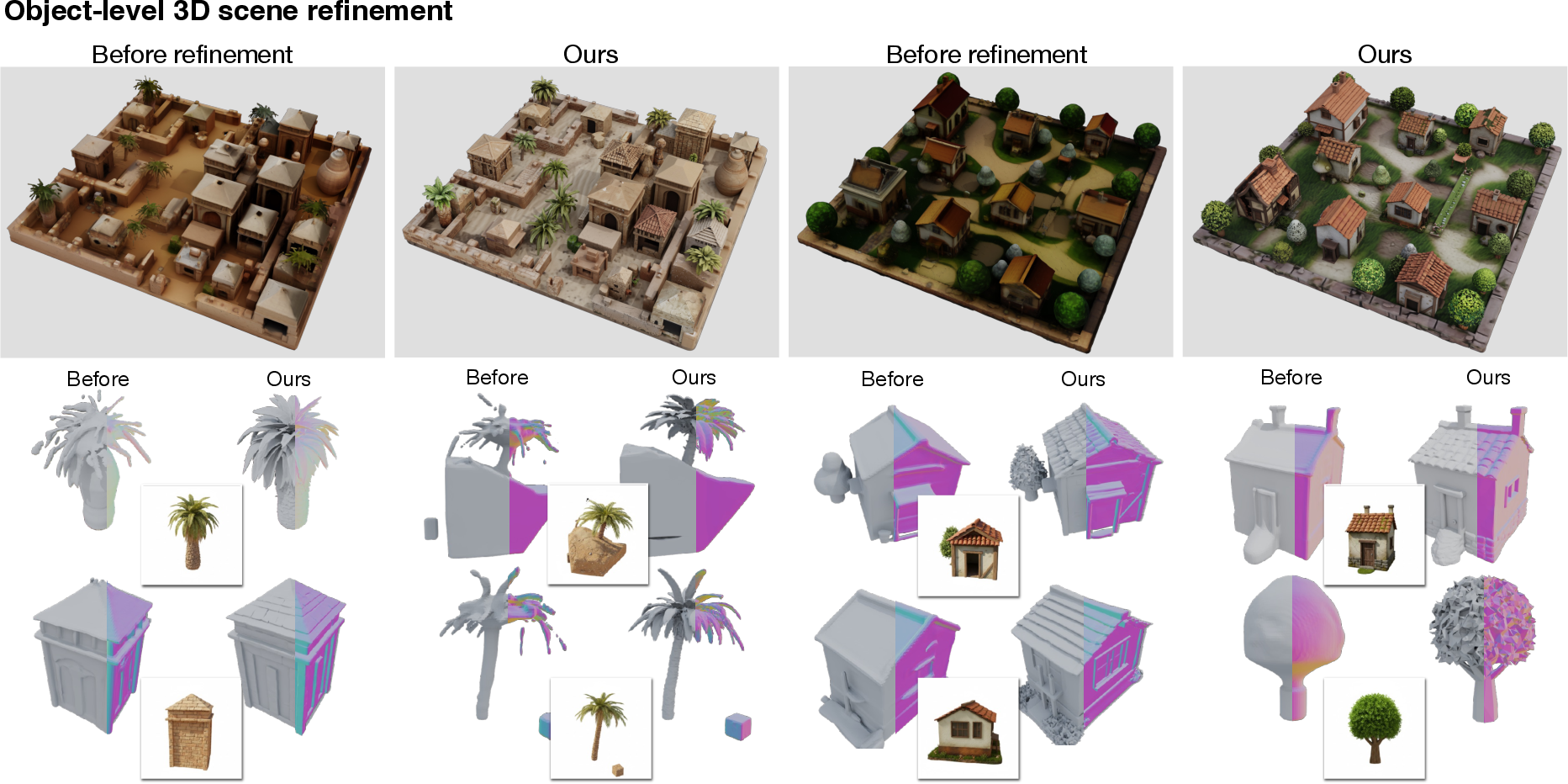
Figure 4: Object-level scene refinement—degraded scene objects are segmented and enhanced using 3D-ReGen.

Figure 5: Comparison against enhancement baselines, demonstrating higher fidelity and finer details.
Guided Image-to-3D Reconstruction
By refining incomplete VGGT photogrammetry outputs, 3D-ReGen produces complete, artifact-free geometry from sparse views and achieves strong metrics in both geometric and perceptual quality. Its performance matches or surpasses specialized multi-view baselines, even with fewer input views.
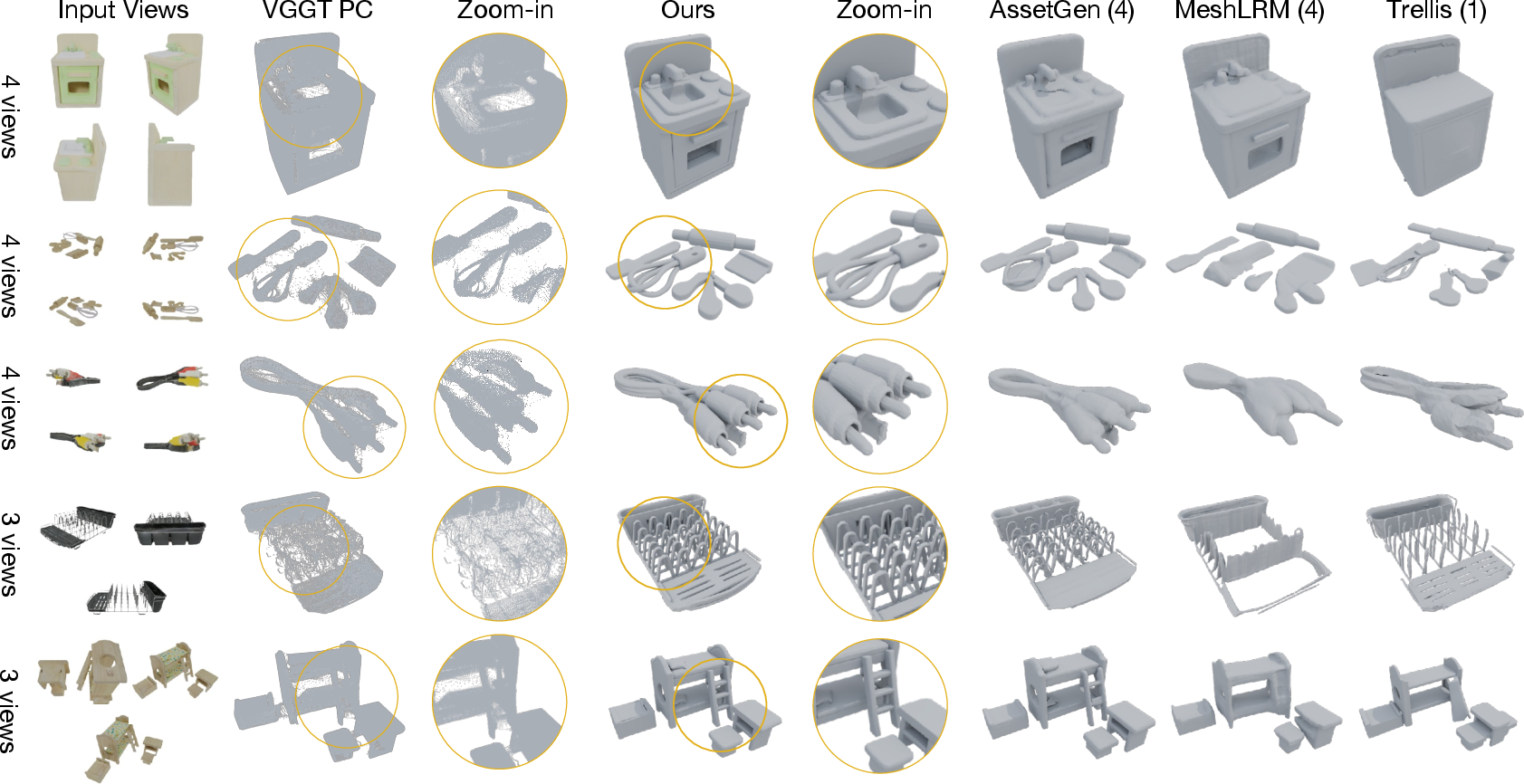
Figure 6: 3D-ReGen preserves and cleans geometry from VGGT point clouds, maintaining more detail than image-only baselines.
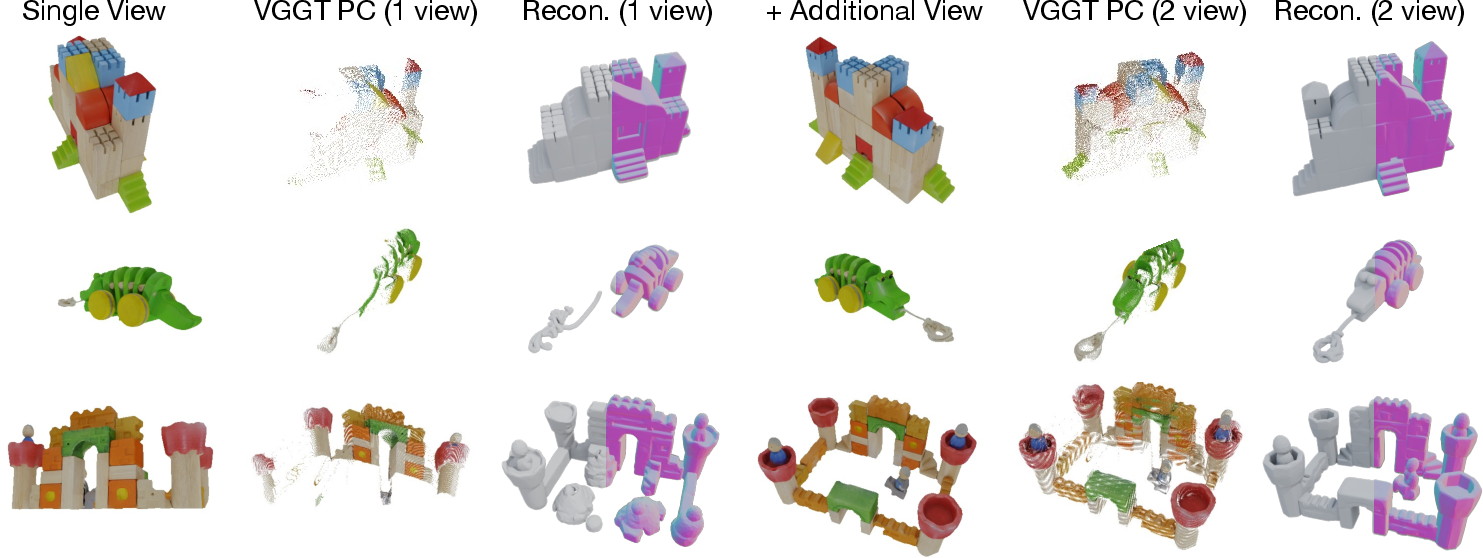
Figure 7: Incremental reconstruction improves occluded regions with additional views, showing quantitative gains with more input images.
3D Shape Editing
Feed-forward editing enables localized shape modifications guided by inpainted reference images and 3D masks, maintaining structural consistency and detail while avoiding expensive inversion or 2D-to-3D lifting.

Figure 8: Examples of shape modification via region masking and image inpainting yielding semantically controlled edits.
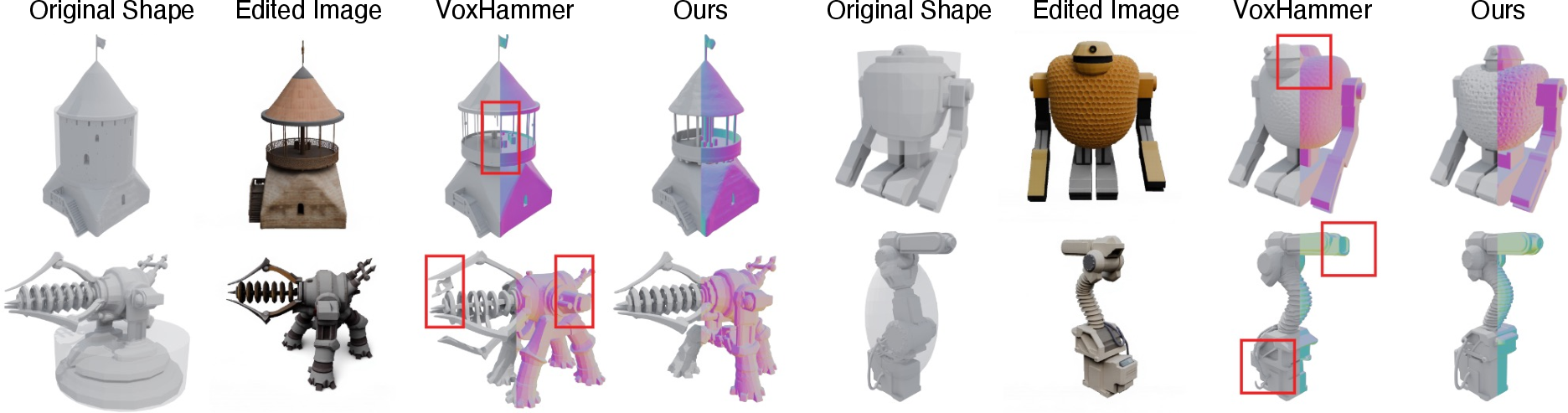
Figure 9: Comparison with VoxHammer—3D-ReGen provides more faithful structure preservation and detail fidelity.
Ablation Studies
Systematic ablations show the superiority of the token concatenation conditioning mechanism over cross-attention or point cloud feature fusion approaches. Diffusion-based parameterization is demonstrated to outperform direct flow-based mapping, producing sharper, more accurate geometry. 3D-ReGen generalizes beyond the enhancement task to reconstruction and editing without architectural modification.
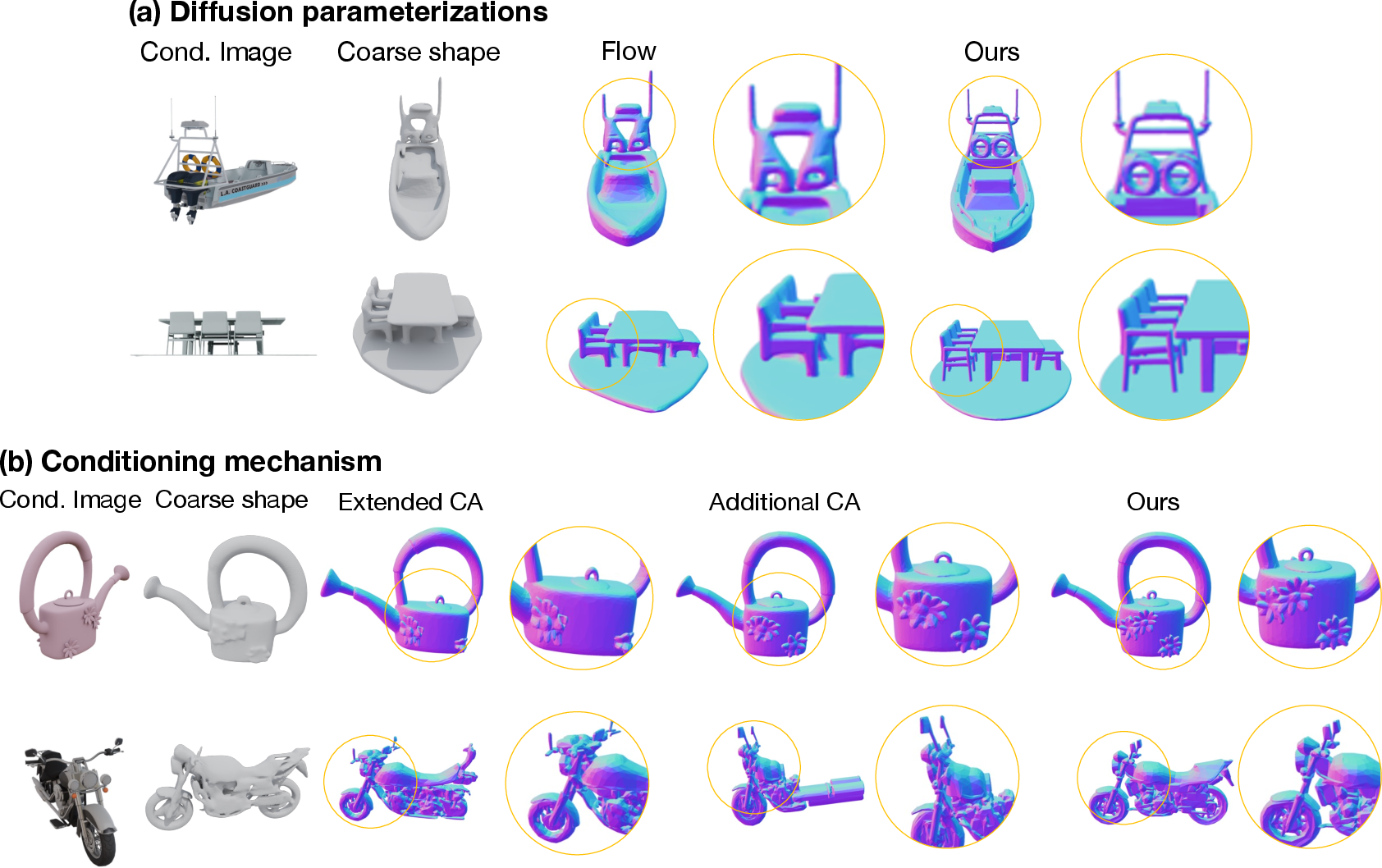
Figure 10: Qualitative diffusion parameterization ablation—diffusion-based training yields more consistent and sharp outputs.

Figure 11: Additional ablation samples reaffirming improved detail with the proposed conditioning mechanism.
Qualitative Enhancement and Block-Out Regeneration
3D-ReGen is robust to severe degradation in both image and shape conditions, and shows domain transfer potential for legacy asset or compression artifact enhancement. In block-out-driven synthesis, it reliably matches input proportions and pose, adding image-guided fine details, outpacing CLAY and other point-cloud-conditioned generators.
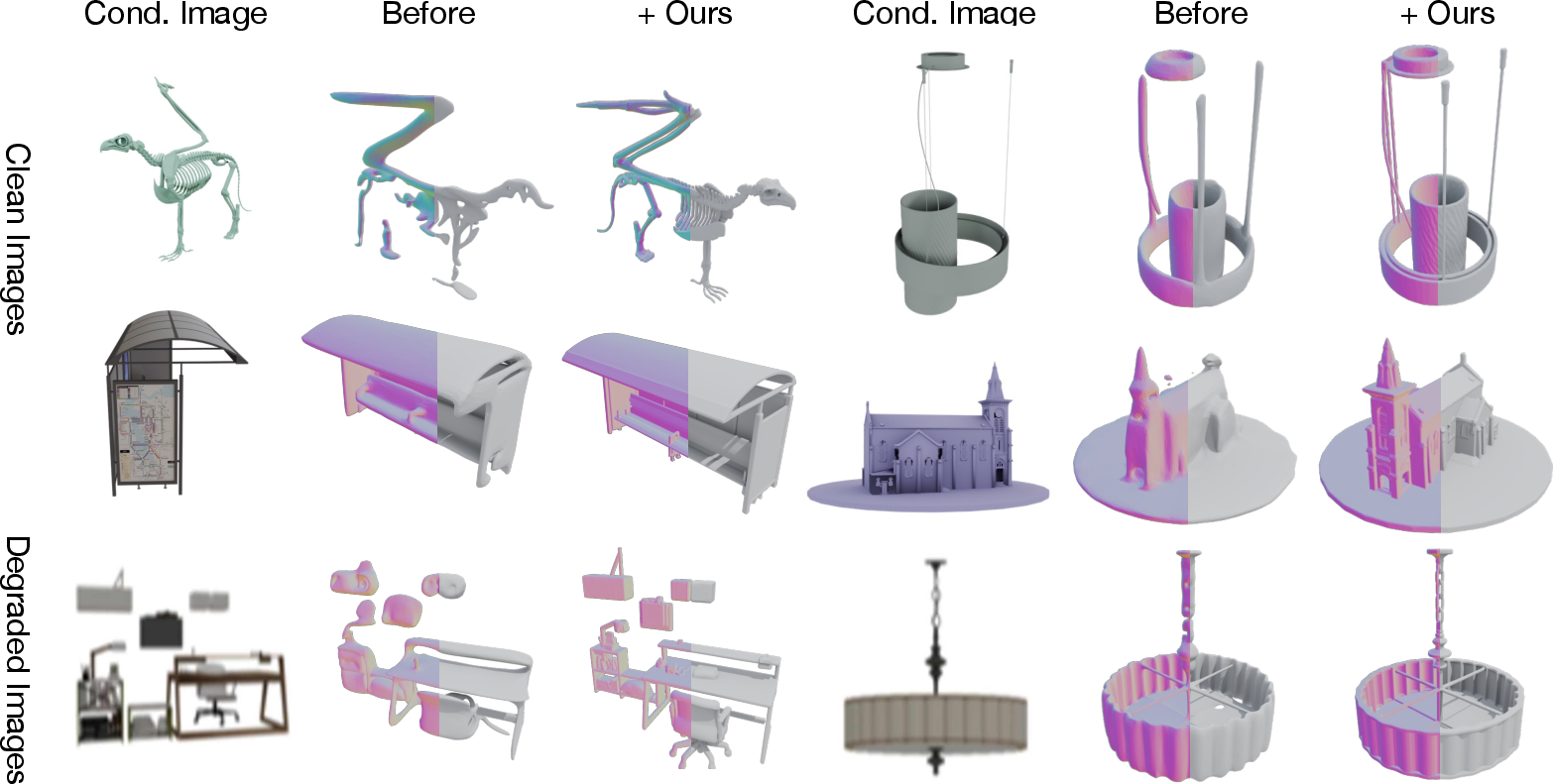
Figure 12: Robust enhancement of shapes from degraded conditions as evaluated on held-out validation samples.
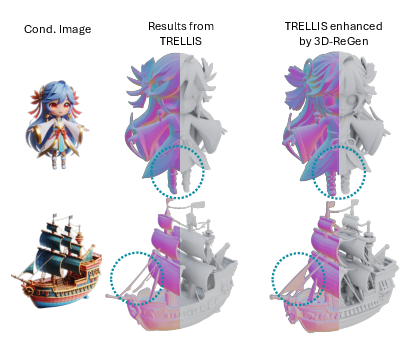
Figure 13: Enhancement of legacy/low-quality assets, matching input image details more closely than baselines.

Figure 14: Block-out regeneration—fine detail synthesis while preserving underlying structure, superior to CLAY.
Practical and Theoretical Implications
The study establishes that a unified latent space and conditioning mechanism can generalize across diverse 3D regeneration tasks, removing the need for task-specific networks. This architectural principle scales to arbitrary degradation types, varying token counts, and multiple forms of guidance. It bridges generative modeling with practical asset workflows, enabling interactive enhancement, reconstruction, and editing in 3D creation pipelines.
Practically, this unlocks robust enhancement of compositional scene assets, closed-loop refinement from scan data, and structure-preserving editing—all within a scalable feed-forward framework. Theoretically, results suggest that the rich latent space of VecSet tokens and diffusion-based denoising provide sufficient representational capacity and flexibility for unified 3D geometry task generalization.

Figure 15: Comparative performance in enhancement tasks against CLAY and other baselines, highlighting detail restoration and geometric coherence.
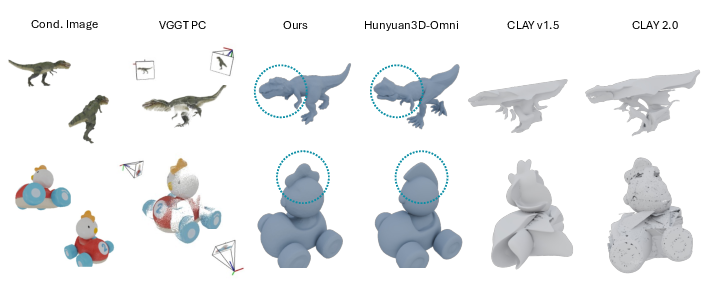
Figure 16: Two-view reconstruction—3D-ReGen produces more faithful shapes compared to Hunyuan3D-Omni and CLAY.
Future Directions
Extending this framework to dynamic scenes, integrating active-voxel representations for further generalizability, and incorporating richer control signals (e.g., skeletons or structural primitives) are promising directions. The unified architecture invites development of broader generative 3D priors for automatic asset upgrading, large-scale editing, and context-aware reconstruction.
Conclusion
3D-ReGen presents a scalable, task-agnostic approach to 3D geometry regeneration, addressing enhancement, reconstruction, and editing with a single architectural backbone. Its flexible conditioning mechanism and automated paired data construction enable robust performance and geometric consistency across modalities and downstream tasks. The methodology lays groundwork for future unified generative frameworks in controllable 3D content creation and manipulation.

