Reconstruction by Generation: 3D Multi-Object Scene Reconstruction from Sparse Observations
Abstract: Accurately reconstructing complex full multi-object scenes from sparse observations remains a core challenge in computer vision and a key step toward scalable and reliable simulation for robotics. In this work, we introduce RecGen, a generative framework for probabilistic joint estimation of object and part shapes, as well as their pose under occlusion and partial visibility from one or multiple RGB-D images. By leveraging compositional synthetic scene generation and strong 3D shape priors, RecGen generalizes across diverse object types and real-world environments. RecGen achieves state-of-the-art performance on complex, heavily occluded datasets, robustly handling severe occlusions, symmetric objects, object parts, and intricate geometry and texture. Despite using nearly 80% fewer training meshes than the previous state of the art SAM3D, RecGen outperforms it by 30.1% in geometric shape quality, 9.1% in texture reconstruction, and 33.9% in pose estimation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Read Summary of “Reconstruction by Generation: 3D Multi-Object Scene Reconstruction from Sparse Observations”
What’s this paper about? (Overview)
This paper introduces a system called RecGen that can rebuild detailed 3D “digital twins” of real-world objects and scenes from just one or a few pictures taken by a color-and-depth camera (like a Kinect or a phone with depth sensing). Even if objects are partly hidden, oddly shaped, or look similar from many angles (like a bottle), RecGen can guess their full shape, where they are in space, and what they look like.
Why this matters: Robots and games need realistic 3D scenes to practice and test in. Building those by hand takes a lot of time. RecGen aims to make it fast and reliable to turn a few photos into accurate 3D models you can use in simulation.
What questions were the researchers trying to answer?
In simple terms, they asked:
- Can we rebuild full 3D objects (including the hidden parts) from just a few views?
- Can we figure out exactly where each object is in space and how it’s turned (its “pose”: position + rotation + size)?
- Can we do both shape and pose at the same time so they agree with each other, instead of in separate steps that might break?
- Can we handle hard cases, like objects that are partly covered, have tricky shapes, or are symmetric (look the same from many angles)?
- Can we also recover object parts (like a drawer in a cabinet), not just whole objects?
- Can we use more than one camera view when available to make the results even better?
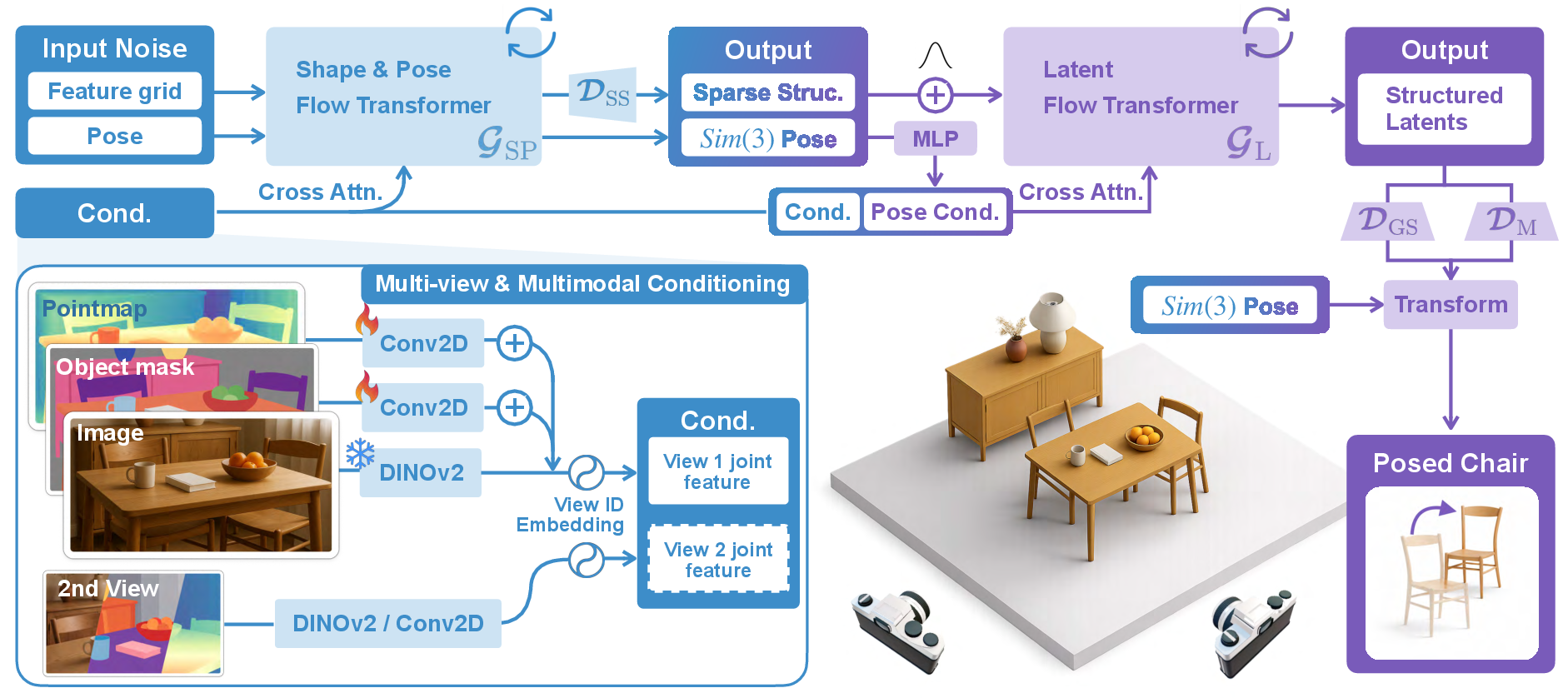
How does RecGen work? (Methods explained simply)
Think of trying to complete a puzzle when some pieces are covered. RecGen “imagines” the missing pieces based on what it has seen before and the hints from the photos and depth.
Here’s the process in two stages:
- Rough structure and pose first
- Inputs: one or two color images, depth maps (how far each pixel is), and simple object masks (which pixels belong to the object).
- RecGen uses these to:
- Sketch a rough 3D “skeleton” of the object in space.
- Estimate the object’s exact position, rotation, and size (this is the “6-DoF pose,” meaning 3 directions of position and 3 directions of rotation, plus scale).
- It does this with a “generative” model that starts from a noisy guess and steadily improves it—like sharpening a blurry photo step by step—guided by what it sees in the images and depth. This joint estimation stops errors that happen when shape and pose are predicted separately.
- Fill in the details: smooth surfaces and textures
- Once the rough structure and pose are ready, RecGen adds fine details: a clean 3D mesh (the object’s surface) and realistic colors/textures.
- It “paints” the model in a way that matches the object’s orientation in the camera. This is important for symmetric objects (like a label on a round bottle that should face the right way).
Helpful tricks RecGen uses:
- Depth as 3D points: It turns depth pixels into 3D points to give the model a strong sense of real-world shape.
- Context-aware masks: Instead of erasing the background, it keeps some area around the object so the model understands what’s hiding what.
- Training with occlusions and noise: They trained on a huge synthetic dataset where objects are often partly covered and depth has realistic noise. This teaches RecGen to handle messy, real scenes.
- Multi-view support: If you have two cameras or two angles, RecGen can combine them to reduce uncertainty.
Analogy:
- Stage 1 is like building a cardboard model to the right size and position.
- Stage 2 is like smoothing it into a proper shape and painting it so it looks real.
What did they find? Why is it important?
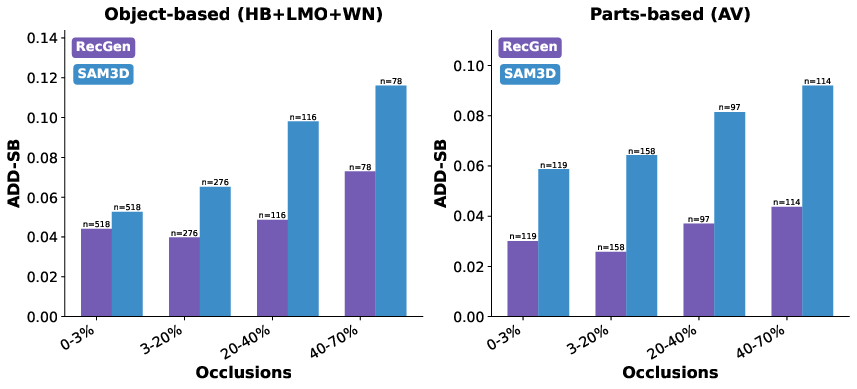
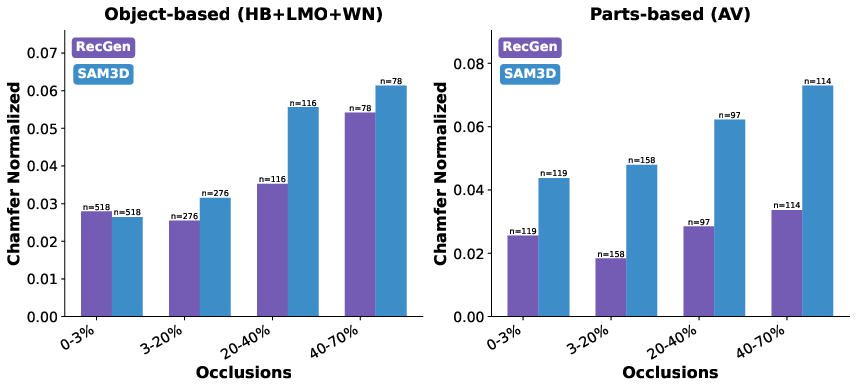
The researchers tested RecGen on tough datasets with clutter, occlusions, and symmetric objects and compared it to other strong methods, especially a recent system called SAM3D.
Main takeaways:
- Better 3D shapes: RecGen made shapes that were about 30% more accurate than SAM3D on average.
- Better pose (position and rotation): RecGen estimated pose about 34% better than SAM3D, which is crucial for using these models in simulations or with robots.
- Better textures in the right orientation: For symmetric objects, RecGen kept text and labels aligned with the object’s actual orientation better than previous methods.
- Works with less training data: It used around 80% fewer training meshes than SAM3D but still performed better.
- Handles parts, not just whole objects: RecGen could also recover individual parts (like a door handle or a drawer) more accurately than other methods.
- Even better with two views: When given a second view, results improved further, reducing guesswork for hidden areas.
Why this matters:
- Building digital twins faster and cheaper: You can quickly turn a few photos into accurate 3D scenes without expensive scanning rigs or lots of manual work.
- More reliable robot training: Robots that learn in simulation need accurate models—especially object size, pose, and how parts move. RecGen brings this closer to reality.
- Robust in the real world: Because it was trained on occlusions and realistic depth noise, it works better in messy, everyday scenes.
What could this lead to? (Implications and impact)
- Scalable simulation: Companies and researchers can create large, realistic virtual environments more easily for training robots, testing AR/VR systems, and building games.
- Better robot manipulation: Understanding object parts and exact poses helps robots open doors, pull drawers, or pick up items more reliably.
- Fewer steps, fewer errors: By combining shape and pose into one system, RecGen reduces the usual mistakes that happen when these are done separately.
- Multi-camera setups: Homes, factories, and labs often have more than one camera. RecGen can make full use of that to improve accuracy.
In short, RecGen is a smarter, more robust way to “rebuild the world” from just a few views, helping turn simple photos into detailed, usable 3D scenes for robotics and beyond.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what remains missing, uncertain, or unexplored in the paper, phrased to inform concrete follow-up research.
- Dependence on ground-truth instance/part masks
- The method assumes accurate per-object/per-part segmentation masks and cropped regions at inference. Robustness to imperfect masks, missed detections, and over-segmentation is not evaluated. An end-to-end pipeline that jointly detects/segments and reconstructs (or that is resilient to mask noise) is left open.
- Limited multi-view conditioning (only up to two views)
- Training and inference explicitly support one or two views; scalability to N-view settings, view selection, and cross-view fusion strategies (e.g., consistent latent fusion, optimization with view-specific residual losses) are not explored.
- Cross-view consistency and calibration assumptions
- Multi-view experiments presume known intrinsics and view identities; extrinsic calibration uncertainties and cross-view consistency constraints (e.g., shared object identity and a single Sim(3) across views) are not modeled or enforced. Methods to jointly refine extrinsics and shape/pose in-the-loop are unaddressed.
- Per-object reconstruction in “multi-object scenes”
- Despite the scene framing, the approach reconstructs objects independently given masks and does not reason about global scene layout, inter-object contacts, or collisions. Scene-level consistency and physically plausible placement are not enforced or evaluated.
- Reliance on synthetic training; limited real-world validation breadth
- Training is entirely synthetic (3.2M renders), with appearance subsets excluded for texture quality. Real-world evaluation is limited to pose/shape datasets (mostly object-centric) and a small part benchmark derived from ArtVIP (rendered). Broader tests on diverse real captures, cluttered household scenes, and photometric realism (with ground-truth scans) are missing.
- Depth modeling and sensor domain gaps
- Training uses stereo-estimated depth (FoundationStereo) to improve realism but does not model other sensor failure modes (e.g., ToF multipath, structured light quantization), missing depth, or specular/transparent surfaces. The generalization of pointmap conditioning to these conditions is not studied.
- Assumption of isotropic scale (Sim(3)) and metric consistency
- The pose includes an isotropic scale parameter even when metric depth is available; the implications for metric fidelity, especially in multi-view scenarios, and the effect of camera calibration errors on scale estimation remain unclear.
- Symmetry handling beyond appearance alignment
- While pose-conditioned texturing improves orientation-consistent textures on symmetric objects, rigorous treatment of rotational equivalence classes during training/inference (e.g., symmetry-aware pose distributions and uncertainty reporting) is not addressed.
- No articulation modeling despite part-level recovery
- The method estimates part geometry and pose but does not infer joint types, kinematic chains, motion limits, or articulation parameters that would enable manipulation planning; learning these from sparse views is open.
- Robustness to thin structures, transparent/reflective materials, and deformables
- Failure modes on hard cases (thin geometries, wires, glossy/transparent objects, deformable/soft items, textureless surfaces) are not characterized; dataset coverage and inductive biases for these categories remain unclear.
- Texture generation remains comparable to SAM3D after ICP
- Despite pose-aware conditioning, perceived texture quality after pose alignment is only on par with SAM3D on average. Integrating depth cues into the appearance module, multi-resolution training, and larger/diverse texture datasets are identified but not executed; systematic studies on view-consistency and PBR material recovery are absent.
- Sparse structure resolution and topology guarantees
- Stage-1 structure uses a 64³ occupancy grid compressed to a 16³×8 latent, potentially limiting very fine details. Topological correctness (manifoldness, watertightness), sharp-edge preservation, and small-part fidelity are not evaluated or guaranteed.
- No test-time optimization or likelihood-based view consistency
- The framework is purely feed-forward generative; it does not include test-time refinement against observed RGB-D (e.g., differentiable rendering or ICP-in-the-loop) to resolve ambiguities or correct residual errors under challenging occlusions.
- Uncertainty quantification and multi-hypothesis selection
- Although labeled “multi-hypothesis,” the paper does not formalize uncertainty, nor does it provide principled hypothesis ranking/selection or diversity guarantees. Mechanisms for uncertainty-aware downstream decision-making are not provided.
- Data efficiency and compute footprint
- Training relies on 64×H100 GPUs for ~48 hours and a 1.2B-parameter backbone; sensitivity to compute budget, ablations on sample steps vs. quality, and potential for distilled or smaller models are not explored.
- End-to-end real-to-sim readiness
- While motivated by digital twin generation for robotics, there is no evaluation of physical usability in simulators (e.g., collision-free meshes, mass/inertia estimates, stable contact geometry) or downstream policy performance. Post-hoc physics-based refinement and sim integration are left for future work.
- Robustness to camera calibration errors
- The method assumes accurate intrinsics and uses them to build pointmaps. Sensitivity to intrinsic/extrinsic errors and potential self-calibration strategies are not analyzed.
- Instance and part correspondence across views
- The pipeline presumes per-view masks for the same object/part; automated cross-view association and tracking (in multi-camera or video settings) are not addressed.
- Evaluation metrics and protocols
- Shape quality is reported after ICP alignment, which partially conflates shape and pose. Additional metrics for topology, surface normals, and watertightness, as well as view-consistent rendering metrics across multiple novel views, would better quantify reconstruction quality.
- Generalization beyond rigid categories
- The method targets rigid objects and parts; extending to nonrigid or articulated-in-motion observations, and handling category-level priors for highly variable classes, remain open.
- Domain biases in the synthetic dataset
- Scene composition (random occluders, lighting) may not reflect real indoor distributions. A systematic study of domain shift, bias sources (object categories, materials, scales), and strategies such as domain adaptation is missing.
- Multi-object joint reasoning
- The approach does not exploit relationships among objects (e.g., support, co-occurrence, stacking) to regularize scale and pose. Learning relational priors for joint multi-object inference remains unexplored.
- Failure analysis and diagnostics
- The paper emphasizes improvements but lacks a thorough error taxonomy (e.g., when depth helps vs. hurts, typical failure poses or shapes), hindering targeted future improvements.
- Limited exploration of manifold-aware pose modeling
- Pose parameters are normalized and represented in 6D/9D Euclidean embeddings; flows that operate directly on SO(3)/Sim(3) manifolds or that incorporate object symmetries as quotient spaces are not explored.
Practical Applications
Immediate Applications
Below are concrete ways RecGen’s joint shape–pose reconstruction from sparse RGB‑D can be used today across sectors, along with potential tools/workflows and feasibility notes.
- Robotics: scene-to-simulation pipelines for training and evaluation
- Use case: Rapidly convert a robot’s lab scenes (tables, bins, tools) into textured, posed digital twins for policy learning, grasp planning, and benchmarking (e.g., Isaac Sim, Habitat, Gazebo).
- Workflow: Capture 1–2 RGB‑D views + masks → run RecGen → export textured meshes with 6‑DoF poses → drop-in to simulators → train/evaluate policies.
- Tools/products: ROS2 capture node; Unity/Unreal/Isaac Sim asset importers; “Scene2Sim” CLI for batch processing.
- Assumptions/dependencies: Reliable object masks per view; calibrated camera intrinsics; static scenes; access to an RGB‑D sensor; offline or near-real-time inference (50 denoising steps); domain shift may require light fine-tuning in unusual environments.
- Robotics: part-level digital twins for articulated-object tasks
- Use case: Generate part-aware assets (e.g., handles, doors, knobs) for training opening/closing skills and fine-grained manipulation policies.
- Workflow: Segment parts (or use CAD annotations), capture 1–2 views, reconstruct parts with pose, assemble into interactive assets in sim.
- Tools/products: Part-aware importers for Isaac Sim/Unreal; integration with articulation frameworks (e.g., SAPIEN-compatible rigs).
- Assumptions/dependencies: Part masks/annotations; articulation metadata still needed to make parts physically interactive; domain-specific tuning may be required.
- Manufacturing/Industry 4.0: workcell digitization and layout validation
- Use case: Quickly reconstruct cluttered workcells (fixtures, bins, jigs) from a few calibrated camera views to plan robot reachability, collision checks, and safety envelopes.
- Tools/products: “WorkcellTwin” kit for handheld captures; CAD overlay plug-ins in Unity/Unreal; ROS2 nodes for fixed multi-cam rigs.
- Assumptions/dependencies: Accurate intrinsics/extrinsics; per-instance masks; static equipment; moderate compute.
- Warehousing/Retail: shelf and bin digital twins under occlusion
- Use case: Build shelf/bin replicas from handheld scanners for planogram checks, stock analysis, and simulation of pick/placement.
- Benefit: Pose-conditioned texturing helps maintain correct label orientation on symmetric items (e.g., cylindrical bottles).
- Tools/products: “ShelfTwin” scanning booth; iPhone LiDAR + segmenter app; export to planogram analytics tools.
- Assumptions/dependencies: Good segmentation in clutter; consumer depth quality varies; lighting/texture domain shift.
- E‑commerce/Content creation: fast 3D product assets from sparse captures
- Use case: Produce high-fidelity, oriented, textured meshes from 1–2 RGB‑D views for web catalogs, AR try-ons, and ads.
- Tools/products: “Scan‑to‑Asset” pipeline with Blender plug-in; batch processing for studios/booths; glTF/USD exports.
- Assumptions/dependencies: Masks per product; consistent intrinsics; may need studio lighting presets for best textures.
- AR/VR and Games: level-dressing from real scenes
- Use case: Ingest a few depth-augmented photos of desks, shelves, rooms to populate virtual scenes with correctly posed, textured objects.
- Tools/products: Unreal/Unity importers; Gaussian Splatting-to-texture baking integrated for asset pipelines.
- Assumptions/dependencies: Static scenes; segmentation available; multi-view optional but improves fidelity.
- Insurance and Claims: room/object recon under partial views
- Use case: Adjusters reconstruct rooms or items from limited mobile captures to estimate dimensions, damage extents, and replacement models.
- Tools/products: Mobile capture app with segmentation; dimension reports (Diameter Relative Error) for triage.
- Assumptions/dependencies: Privacy/compliance; depth on mobile (e.g., LiDAR) or stereo; segmentation quality.
- Construction/Facilities/BIM: as‑built capture of equipment and parts
- Use case: Construct digital twins of equipment and fixtures from sparse on-site captures for documentation and clash detection.
- Tools/products: BIM plug-ins to match reconstructed assets to catalogs; reports on pose/scale for QA.
- Assumptions/dependencies: Calibrated capture; masking (automatic or manual); complex materials may need additional views.
- Academia and R&D: benchmarking and dataset generation under occlusion
- Use case: Use RecGen’s training recipe and occlusion-heavy synthetic data to benchmark new algorithms in joint shape–pose inference and to auto-label 6‑DoF pose in RGB‑D datasets.
- Tools/products: Scripts to convert predicted poses/shapes into dataset annotations; evaluation metrics (ADD‑SB, DRE).
- Assumptions/dependencies: Access to compute for inference/fine-tuning; adherence to licensing of included assets.
- Education: teaching 3D perception and generative reconstruction
- Use case: Classroom labs demonstrating how multi-view depth and masks improve shape completion and pose for occluded objects.
- Tools/products: Prepackaged notebooks with sample scenes; small capture rigs for labs.
- Assumptions/dependencies: One RGB‑D camera; segmentation model; GPU access recommended.
Long-Term Applications
Below are applications that are plausible extensions but depend on further research, scaling, or engineering (e.g., real-time performance, integrated detection, dynamic scenes).
- Robotics: on‑robot, real-time joint shape–pose perception for manipulation
- Vision: Replace multi-stage perception with a unified module that delivers graspable meshes and accurate poses online, robust under occlusion and symmetry.
- Needed advances: Model compression/acceleration (fewer denoising steps), integrated detection/segmentation, handling dynamics and motion, uncertainty estimates for planning.
- Dependencies/assumptions: Low-latency inference on edge GPUs; reliable, fast masks or joint instance discovery; safety certification for autonomy.
- Robotics: physics-consistent, interactive digital twins at scene scale
- Vision: Combine RecGen with physics-based post-hoc refinement to ensure inter-object contacts, stable placements, and articulated constraints for realistic sim-to-real.
- Needed advances: Joint optimization with physics losses; consistent multi-object reconstruction; articulated priors and parameter identification.
- Dependencies/assumptions: Accurate friction/material estimates; stable optimization across clutter.
- Healthcare: stereo endoscopy and surgical tool/anatomy reconstruction
- Vision: Use multi-view RGB‑D or stereo to reconstruct instruments/organs under heavy occlusion for guidance or simulation.
- Needed advances: Domain adaptation to endoscopic imagery, deformable and soft-tissue modeling, regulatory validation.
- Dependencies/assumptions: High-quality segmentation of tools/tissue; strict privacy and safety compliance.
- Automotive and Mobility: in‑cabin and trunk digital twins for packing and HMI
- Vision: Reconstruct personal items from sparse in-cabin sensors to plan storage or adapt HMIs; simulate occupant-object interactions.
- Needed advances: Real-time inference, privacy-preserving pipelines, robust operation under variable lighting.
- Dependencies/assumptions: Edge compute; policy and privacy frameworks for in-cabin sensing.
- Energy/Utilities: asset inspection and remote robotics operations
- Vision: Build accurate object/part twins in substations/plants for teleoperation and maintenance simulations, even with partial views and occlusion.
- Needed advances: Ruggedized depth sensing; integration with maintenance CMMS/BIM systems; long-range, multi-sensor fusion.
- Dependencies/assumptions: Safety-certified pipelines; segmentation for industrial components; environment-specific fine-tuning.
- City-scale and large-facility digital twin generation from sparse captures
- Vision: Aggregate multi-camera, occasional-capture visuals across time into coherent, posed, textured assets for logistics, safety, and simulation.
- Needed advances: Global scene graph building, persistent identity tracking, scalable multi-view conditioning beyond two views.
- Dependencies/assumptions: Data governance, storage, and privacy; fleet-wide calibration standards.
- Consumer AR: on-device scan-to-asset from a few phone captures without masks
- Vision: Seamless 3D asset creation for marketplaces and AR placement by integrating detection/segmentation and compressing the model for mobile.
- Needed advances: Strong on-device instance segmentation, model distillation, reduced denoising steps, improved texture fidelity across device sensors.
- Dependencies/assumptions: Mobile GPU/NPUs; battery/performance trade-offs; robust auto-calibration.
- Forensics and Public Safety: reconstruct accident/crime scenes from sparse evidence
- Vision: Build faithful, posed, textured reconstructions from a few calibrated photos for analysis and courtroom visualization.
- Needed advances: Provenance tracking and verifiable uncertainty, chain-of-custody tooling, standardized reporting.
- Dependencies/assumptions: Calibrated capture; admissibility standards; ethical and privacy safeguards.
- Finance/Insurance: automated claims valuation with volumetric/pose analytics
- Vision: Use reconstructed dimensions and textures to auto-estimate item categories, replacement costs, and damage severity at scale.
- Needed advances: Integration with pricing/catalog databases, robust category recognition atop reconstructed meshes, fairness auditing.
- Dependencies/assumptions: High-quality capture; secure processing; bias and error monitoring.
- Education at scale: cloud labs for 3D perception coursework
- Vision: Students upload sparse RGB‑D captures and receive posed, textured assets and metrics for assignments.
- Needed advances: Managed cloud services, easy-to-use UIs, cost-effective inference at scale.
- Dependencies/assumptions: Stable GPU backends; dataset licensing compliance.
- Standards and Policy: guidelines for digital twin fidelity and privacy
- Vision: Establish benchmarks and minimum fidelity metrics (e.g., ADD‑SB, DRE thresholds) for procuring digital twin services and protecting privacy when reconstructing indoor spaces.
- Needed advances: Cross-industry benchmark suites; privacy-preserving reconstruction protocols (e.g., automatic redaction).
- Dependencies/assumptions: Multi-stakeholder coordination; legal frameworks for 3D data custody.
Notes on feasibility across applications
- Core dependencies: per-object (and optionally per-part) masks; calibrated intrinsics (and extrinsics for multi-view); RGB‑D or stereo-derived depth; moderate GPU compute.
- Performance envelope: Current model uses ~50 denoising steps and a large backbone; suited to offline/batch workflows; achieving real-time will need distillation/acceleration.
- Generalization: Trained on synthetic, demonstrates strong real-world results but domain adaptation may be needed for specialized materials/sensors.
- Outputs: Textured meshes and 6‑DoF poses; can export to standard formats (e.g., glTF/USD) and simulators; Gaussian Splatting is used internally for texturing and baking.
Glossary
- 3D shape priors: Learned statistical regularities of 3D object geometry that help infer unobserved parts. "strong 3D shape priors"
- 6D continuous representation: A rotation parameterization using six continuous values to avoid discontinuities in learning. "we use the $6$D continuous representation"
- 6-DoF pose: A rigid body pose in 3D with three rotations and three translations. "accurately estimating object geometry and 6-DoF pose from limited RGB-D input"
- ADD-S: Average Distance of Model Points for Symmetric objects; a pose accuracy metric comparing transformed model points. "we use the ADD-S metric."
- ADD-SB: A bidirectional variant of ADD-S that symmetrizes distances between predicted and ground-truth posed meshes. "a bidirectional variant of ADD-S (denoted ADD-SB)"
- AdamW optimizer: An optimization algorithm with decoupled weight decay for improved generalization. "AdamW optimizer"
- Adaptive Layer Normalization (AdaLN): A conditioning mechanism that modulates layer normalization parameters based on context. "adaptive layer normalization (AdaLN)"
- Articulated object manipulation: Robotics tasks involving control of objects with movable parts (joints/links). "articulated object manipulation"
- Camera intrinsics: Internal camera parameters (e.g., focal lengths, principal point) used to map pixels to rays. "camera intrinsics "
- Chamfer Distance (CD): A symmetric distance between point sets used to evaluate 3D surface reconstruction quality. "we compute Chamfer Distance (CD)"
- Classifier-free guidance (CFG): A technique to steer generative models by mixing conditional and unconditional predictions. "We use classifier-free guidance (CFG) with a drop rate of 0.1"
- Conditional Flow Matching (CFM): A training objective for flow-based generative models that learns velocity fields under conditioning. "using the Conditional Flow Matching (CFM) objective"
- Cross-attention: An attention mechanism that conditions one sequence on another (e.g., images, depth, masks). "Conditioning is provided through cross-attention"
- Digital twin: A high-fidelity virtual replica of a physical system or environment. "digital twin replicas of real-world environments."
- DINOv2: A pretrained vision backbone providing robust image features for conditioning. "DINOv2 image features"
- Diameter Relative Error (DRE): A metric evaluating the relative error in predicted object diameter. "we introduce the Diameter Relative Error (DRE) metric."
- Euler integration: A simple numerical method to integrate differential equations over time steps. "updated via Euler integration."
- FlexiCubes: A differentiable isosurface extraction method for generating meshes from volumetric fields. "extracts geometry via FlexiCubes"
- FoundationPose: A model for unified 6D pose estimation and tracking of novel objects. "using FoundationPose~\cite{wen2024foundationpose}."
- FoundationStereo: A model for estimating depth from stereo imagery. "realistically estimated depth from FoundationStereo"
- Gaussian Splatting (GS): A 3D scene representation/rendering technique using sets of colored Gaussians. "a Gaussian Splatting (GS) decoder"
- Gram–Schmidt orthogonalization: A procedure to construct an orthonormal basis, used here to recover the third column of a rotation matrix. "Gram--Schmidt orthogonalization."
- ICP (Iterative Closest Point): An algorithm that aligns 3D shapes by iteratively minimizing point-to-point distances. "after ICP alignment"
- LPIPS: A perceptual image similarity metric based on deep features. "PSNR, SSIM, and LPIPS."
- Multi-view conditioning: Conditioning a model on multiple camera views to reduce ambiguity from occlusion and symmetry. "multi-view conditioning"
- Occupancy grid: A voxel grid marking presence/absence of geometry, used as a compact structural representation. "dense binary occupancy grid"
- Pointmap: A per-pixel 3D point representation derived from depth and intrinsics, used to inject geometric cues. "we introduce pointmap conditioning"
- Pose parameterizations: Mathematical representations of rotation/pose designed to be continuous and learning-friendly. "pose parameterizations that avoid discontinuities"
- Pose-aware appearance generation: Texture synthesis explicitly conditioned on estimated pose to maintain view consistency. "pose-aware appearance generation"
- Rectified flow: A flow-based generative modeling approach that improves training and sampling for complex distributions. "based on rectified flow"
- Similarity transformation (Sim(3)): The group of 3D transformations combining rotation, translation, and uniform scaling. "T{(v)} \in \mathrm{Sim}(3) denotes a similarity transformation"
- SO(3): The group of 3D rotations represented by orthogonal matrices with determinant 1. "rotation "
- Sparse convolutions: Convolutions operating only on non-empty spatial locations to efficiently process sparse 3D data. "using sparse convolutions"
- Variational Autoencoder (VAE): A generative model with an encoder-decoder architecture and latent variables for probabilistic modeling. "3D convolutional VAE"
- View-dependent appearance: Visual appearance that changes with viewing angle, requiring pose information for consistency. "view-dependent appearance (e.g., cylindrical containers with labels)"
- Z-score normalization: Standardization to zero mean and unit variance applied to pose components. "we apply -score normalization"
Collections
Sign up for free to add this paper to one or more collections.

