- The paper introduces a novel co-training approach (PaW) that jointly optimizes policy and world-model objectives for language agents.
- It employs action-entropy-based data selection and noise-tolerant loss functions to enhance stability in predicting environment dynamics under sparse rewards.
- Experiments across ALFWorld, WebShop, and QA domains show significant gains, with success rates increasing up to 62.2% in challenging settings.
Policy and World Modeling Co-Training for Language Agents: An Expert Summary
Motivation and Context
LLM agents have demonstrated significant progress in complex interactive environments, particularly when enhanced by Reinforcement Learning (RL). However, standard RL paradigms for LLM agents focus exclusively on maximizing extrinsic rewards derived from the environment, neglecting explicit learning about the effects of actions on environmental dynamics. This omission leads to brittle agents prone to failure in long-horizon, open-ended tasks, especially under reward sparsity or delayed feedback. Traditional approaches to world modeling (WM) in LLM agents have introduced separate simulators, auxiliary training stages, or incurred heavy inference costs, complicating deployment and scaling.
The PaW Framework: Joint Policy and World Modeling
The PaW (Policy and World-modeling co-training) framework addresses these limitations by reusing the on-policy RL rollouts for auxiliary world modeling supervision in a single, unified model, without altering the inference pipeline. At each RL update, next-observation tokens are appended to each action–observation transition, offering dense supervision on how actions alter the state of the environment. The agent’s parameters are updated to optimize both the standard RL objective (for action selection) and an auxiliary WM objective (for action-conditioned next-observation prediction).
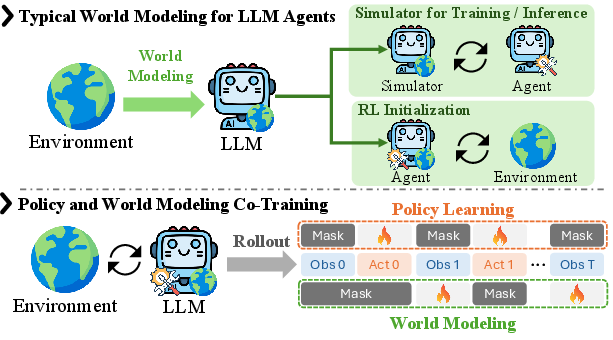
Figure 1: Comparison of world modeling paradigms—PaW eliminates the need for separate simulators or inference-time planning by co-training the policy and world model jointly.
Key to PaW are three architectural innovations to ensure robustness and stability given the noisy, unpredictable nature of text environments:
Methodological Details
Auxiliary World Modeling Objective:
Given a trajectory with observed (ht,at,ot+1) tuples, the world modeling loss is applied over the most informative transitions, as determined by the action-entropy criterion. The clipped MAE loss further mitigates the effect of meaningless or highly stochastic observation tokens. This synergy ensures WM signals remain both relevant and robust with respect to the non-determinism and surface-level noise prevalent in textual observations.
Reward-Adaptive Balancing:
To prevent domination of the RL loss by dense WM supervision, PaW dynamically attenuates the auxiliary loss weighting as group episode return approaches the environment maximum, allowing greater world-model learning when policy learning is challenged.
Efficiency:
PaW is architected so that action and observation loss computations occur within the same model and forward pass, and no modification to generation or policy-inference procedures is required at deployment; only training-time is affected.
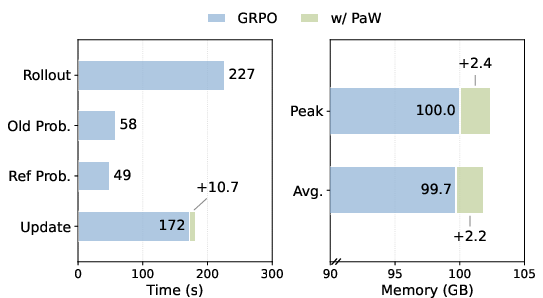
Figure 2: Training time and memory overhead—PaW incurs only modest increases (~2%) in resource usage, demonstrating practical scalability.
Experimental Results
Extensive evaluations were conducted across three domains:
- ALFWorld: Embodied household task environment
- WebShop: Open-domain web shopping with sparse reward signals
- Search-augmented QA: Tool-augmented, multi-turn question answering
PaW was tested on RL algorithms (GRPO, GIGPO, PPO, RLOO) and across model scales. The method consistently yielded improvements over strong RL-only baselines. For example, on ALFWorld and WebShop, success rates for GRPO increased by up to +8% and +9% respectively. Notably, in settings where classic RL collapses (e.g., Llama3.2-3B-Instruct on WebShop, where reward signals are extremely sparse), PaW elevated success from 4.0% to 62.2%, indicating substantial robustness benefits.
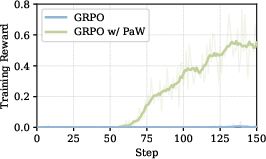
Figure 5: Training rewards on WebShop—PaW overcomes reward sparsity where vanilla RL fails, rapidly obtaining positive success signals.
Ablations confirm that each architectural component—adaptive loss balancing and noise-robust WM loss—is critical for the observed gains. PaW’s improvements manifest even when hyperparameters (clipping threshold, entropy ratio) are varied broadly, underscoring the method’s stability.
Training and Optimization Dynamics
Training monitors highlight that PaW increases cumulative reward without altering the essential loss landscape or update statistics of policy optimization, confirming that world-model supervision integrates cleanly as an auxiliary objective.
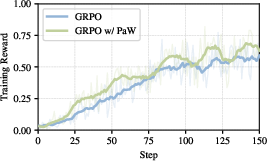
Figure 4: Policy-side training dynamics—PaW improves training reward while preserving policy gradient and clipping statistics relative to baseline RL.
WM objective utilization and attenuation over training progression follows expectations: as episodic success rates rise, adaptive down-weighting of WM loss occurs, while overall prediction error on next observations declines.
Figure 8: PaW auxiliary training dynamics—reward-adaptive world-model loss and the clipped token ratio smoothly respond to policy improvements and noise.
Theoretical and Practical Implications
PaW recasts standard RL rollouts as a dual source of both reward-based and action-conditioned dynamics supervision, leveraging information traditionally ignored. This advocates for a paradigm shift in LLM agent training: dense, local world modeling signals available in on-policy data maximize sample efficiency and enable agents to internalize environment transitions. Practically, PaW’s zero-cost inference protocol and small training overhead make it viable for deployment in real-world, resource-constrained settings.
On a theoretical level, PaW supports the premise that LLM agents benefit from local environment modeling, reminiscent of Sutton’s DYNA architecture, but without dedicated imagination or separate modeling stages. The gains in robustness—especially under reward sparsity—suggest future work in extending to multi-step or trajectory-level world modeling, alternative selection strategies for auxiliary targets, and online deduplication of supervision.
Conclusion
PaW demonstrates that policy and world-modeling co-training is an effective, efficient, and general approach for improving LLM agent performance in interactive tasks. It delivers robust gains across algorithms, agent architectures, and domains, with negligible computational overhead and no inference-time impact. The evidence suggests that action-conditioned observation modeling leverages a potent, untapped signal in existing RL pipelines, promoting more resilient and sample-efficient language agents.
Future Outlook
Incorporating longer-horizon world modeling, deduplication over sampled transitions, and further integration with imagination-based or planning reinforcement learning, are promising avenues. More sophisticated selection criteria for auxiliary targets could further improve training dynamics and generalization. These developments will be integral as LLM agents move toward autonomous operation in open-ended, dynamic environments.
