- The paper presents RAW-Dream, a framework that decouples world model dynamics from task semantics using a task-agnostic approach.
- It employs a diffusion transformer-based world model and dual-noise verification to mitigate first-frame ghosting and reward hacking during policy optimization.
- It demonstrates significant RL performance improvements in both simulation and real-world robotic manipulation with minimal task-specific data.
RAW-Dream: Reinforcement Learning of Vision-Language-Action Policies in Task-Agnostic World Models
Reinforcement learning (RL) for Vision-Language-Action (VLA) models, particularly in robotic manipulation, has frequently relied on synthesized rollouts from world models (WMs) to circumvent costly real-world interactions. Despite the reduced sample complexity, existing WM-based RL pipelines fundamentally depend on task-specific data to fine-tune both the world and reward models. This task entanglement severely limits their scalability—requiring thousands of in-domain rollouts for every new task and precluding rapid and flexible adaptation to unseen instructions, objects, or environments.
The RAW-Dream paradigm presents a decisive departure: world and reward models are strictly task-agnostic. A general-purpose WM is obtained via pre-training on diverse, task-free interaction data, thus internalizing versatile physical priors independent of downstream task semantics. A foundation Vision-LLM (VLM) delivers zero-shot reward signals, enabling data-efficient RL optimization of VLAs for novel tasks entirely within WM imagination.
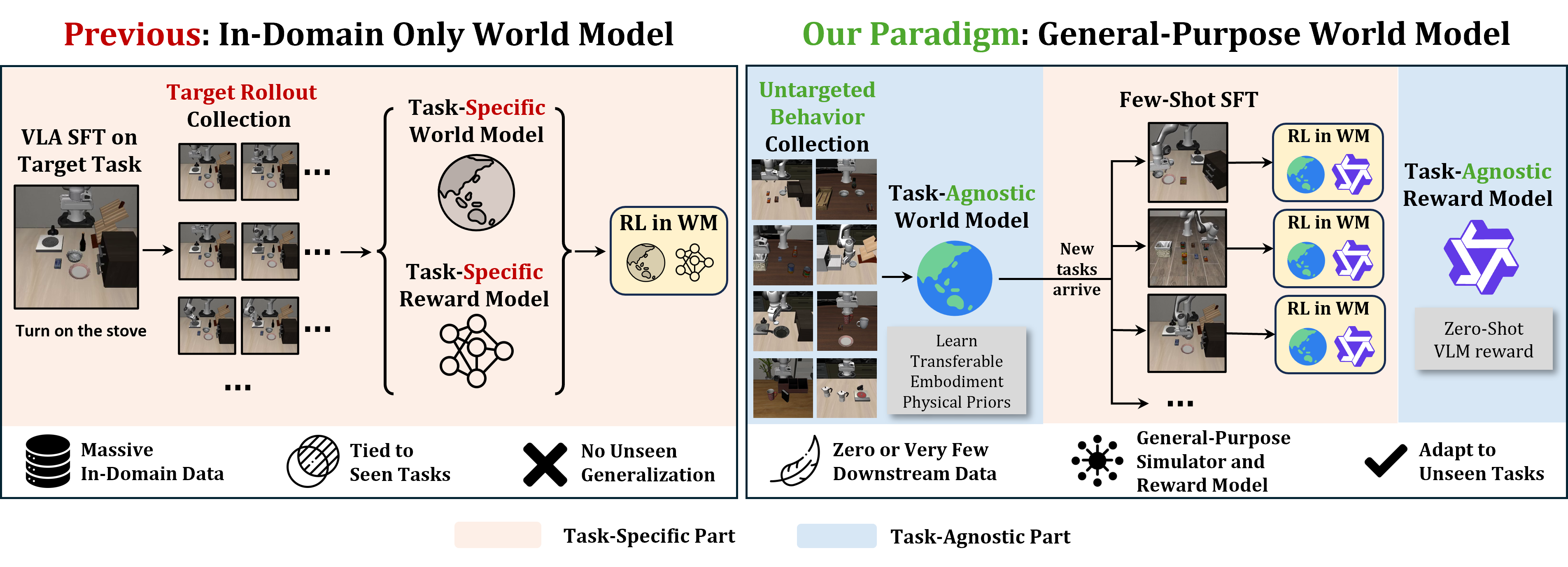
Figure 1: Prior WM-based RL pipelines tightly couple world and reward models to target tasks, whereas RAW-Dream decouples dynamics learning from task semantics via a task-agnostic WM and zero-shot reward.
Methodology: Task-Agnostic World Modelling and Reinforcement Learning
World Model Architecture and Training
RAW-Dream builds its WM upon a pre-trained WAN 2.1 Diffusion Transformer operating in VAE latent space. Task-agnostic play data—spanning broad behavioral diversity and covering myriad successes, failures, and interaction modes—is collected to serve as the foundational corpus. The WM is finetuned into an action-conditioned generator via adaptive layer normalization (AdaLN), with actions projected into module-control parameters modulating diffusion attention. Causal temporal masking ensures strict action causality, and a rectified flow matching objective supervises velocity prediction within latent space. For long-horizon autoregressive rollouts, the WM generates sequences conditioned on recent context frames, accommodating the policy's action chunking.

Figure 2: Play data captures diverse physical priors—shown by object arrangements and downstream evaluation tasks for VLA fine-tuning and RL.
A central practical challenge is "first-frame ghosting" during zero-shot transfer: the WM may over-anchor to the initial real observation, copying stale content into subsequent predictions. RAW-Dream introduces progressive anchor noise, incrementally relaxing the anchor's impact throughout the rollout to eliminate ghost artifacts and maintain scene consistency.
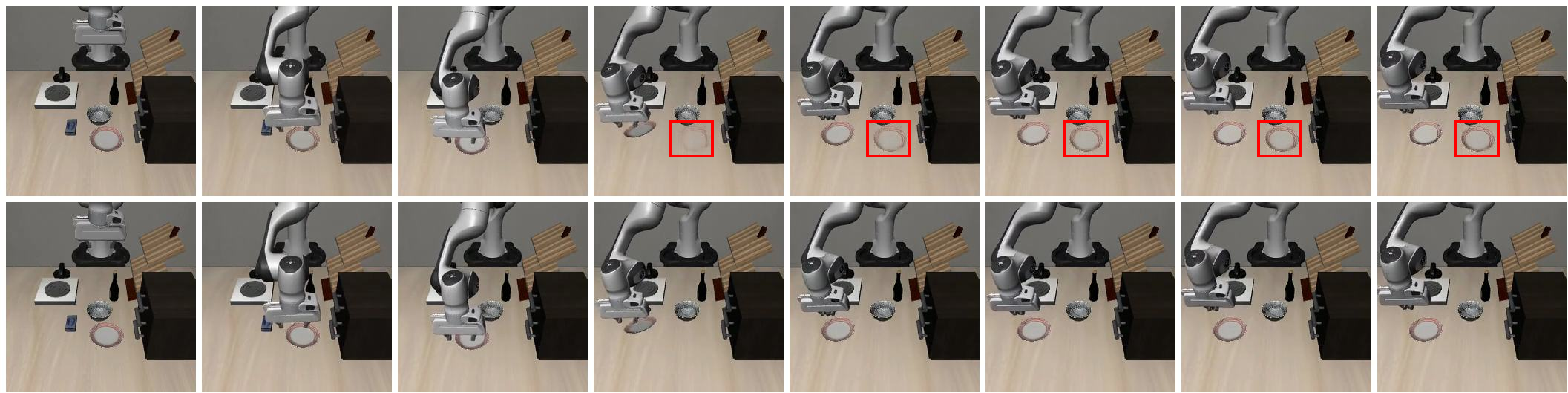


Figure 3: Progressive anchor noise mitigates first-frame ghosting—allowing faithful propagation of holistic dynamics instead of static copying.
Reinforcement Learning in Imagination with Zero-Shot Rewards
The policy (OpenVLA-OFT) is anchored to new tasks via minimal (1-shot or 3-shot) supervised fine-tuning, then post-trained via RL entirely within the frozen, task-agnostic WM using binary zero-shot rewards from a foundation VLM (Qwen3-VL). Action-conditioned rollouts are scored for task success, and the policy is updated via group-based GRPO.
WM hallucinations and reward hacking remain acute risks in unseen domains. RAW-Dream employs Dual-Noise Verification (DNV): each successful rollout is regenerated under independent diffusion noise; only those with consistent VLM success verdicts are admitted to the policy update. This semantic verification directly penalizes false-positive reward exploitation, stabilizing RL.



Figure 4: Example downstream task from LIBERO-Spatial benchmark—typifying novel spatial arrangements for evaluation.
Experiments: Simulation and Real-World Evaluation
Simulation on LIBERO Benchmarks
RAW-Dream is instantiated on LIBERO-90 for WM pre-training, then evaluated on four held-out task suites (Spatial, Object, Goal, Long) entirely unseen during WM training. WM quality and downstream RL efficacy are probed under four conditions:
- Zero-Shot WM: No target task data.
- Co-Train WM: Anchored with minimal expert demonstration mixing.
- ID-FT WM: In-domain fine-tuning using 500 target rollouts.
- WoVR WM: SOTA baseline trained from scratch on 2500 in-domain rollouts.
Strong numerical results are achieved: RL in Zero-Shot WM outperforms online RL (Short) requiring ∼50× more real-world data, and Co-Train WM matches online RL (Long). Only 500 rollouts suffice for ID-FT WM RL to surpass WoVR RL, demonstrating the superior scaling of broad physical priors over brute-force target data stacking. Notably, RAW-Dream's average RL performance improves the 1-shot SFT baseline by +8.9% and achieves pronounced gains in long-horizon tasks despite zero exposure to downstream task specifics.
Ablations: Reward Models and Dual-Noise Verification
Investigations reveal that foundation VLMs (Qwen3-VL, Robometer) drastically outperform finetuned classifiers trained with minimal data, which suffer from overfitting and misjudgment of imperfect imagined rollouts. DNV further enhances RL, accelerating early-stage improvements and stabilizing training by filtering out hallucinated successes. On long-horizon tasks, DNV delivers marked gains, confirming its efficacy in countering compounded stochasticity and uncertainty.
Real-World Robotic Manipulation
RAW-Dream is deployed on an AgileX Piper arm, with the WM trained strictly on uncurated play data (no downstream task rollouts). Policies for unseen manipulation tasks are anchored via 3-shot SFT and improved using imagination-only RL. Significant gains of +21.7% absolute average success rate are observed over SFT baselines. All improvement derives from strictly task-agnostic WM and zero-shot VLM rewards—validating the paradigm's transferability and efficiency in real-world robotic settings.





Figure 5: Task-agnostic WM predicts faithful rollouts of physical manipulation in unseen real-world scenes, enabling RL-guided policy improvement.
Implications and Theoretical Perspectives
RAW-Dream decisively demonstrates that broad, downstream-agnostic physical priors captured in a task-agnostic WM, paired with a general-purpose VLM for reward assessment, suffice for rigorous RL adaptation in both simulation and real-world contexts. Empirically, such priors outperform single-task data stacking—even with orders of magnitude less data—and the paradigm unlocks scalable RL post-training, sidestepping task-specific retraining and rollout collection. The dual-noise verification mechanism addresses longstanding generative modeling pathologies, furnishing a tractable pathway toward semantic reliability and robust policy optimization.
The theoretical implications extend to the modularization of embodied AI pipelines, decoupling dynamics from reward and semantics, and foregrounding the value of compositional foundation models. As foundational WMs and VLMs continue to scale, the data efficiency and adaptability of such paradigms can catalyze rapid advancements in open-ended embodied AI. Future directions include WM fidelity refinement via larger model capacity and richer play data, reward calibration strategies, and integration with flow-based VLA architectures.
Conclusion
RAW-Dream constitutes a paradigm shift in WM-based RL for VLA models, demonstrating that task-agnostic world models and foundation VLMs enable highly efficient and scalable RL post-training with minimal data. The method consistently delivers superior policy adaptation compared to imitation and task-specific RL, both in simulation and physical robotic manipulation. Dual-noise verification supplies semantic stability, curbing reward hacking. The approach outlines a practical, actionable roadmap for large-scale, zero-shot RL adaptation of embodied AI policies.