- The paper introduces Self-Guide, a framework that co-evolves policy and internal reward via self-generated verbal assessments to overcome sparse rewards.
- It presents a stage-wise trust schedule that phases in self-guidance for both action conditioning and reward shaping to stabilize training.
- Experimental results across benchmarks show an approximate 8% performance boost, underlining the practical impact of coupling policy with internal reward signals.
Co-Evolution of Policy and Internal Reward for Language Agents: An Expert Analysis
Language agents based on LLMs face significant challenges when deployed in interactive, long-horizon environments. A primary bottleneck is sparse and delayed task-level reward signals: agents often receive only terminal feedback after lengthy decision sequences, impeding both credit assignment and sample-efficient policy optimization. Existing techniques address this partially through post-hoc credit assignment or external reward models, which are typically employed solely for training and are decoupled from inference-time decision making. The separation creates a misalignment: guidance used to train the agent is unavailable or inconsistent when the agent is deployed in the environment.
Self-Guide: Unified Self-Generated Internal Reward
The paper introduces Self-Guide, a framework wherein the agent internally generates a verbal self-assessment—or self-guidance—at each step, serving two tightly coupled roles: (1) steering decisions at inference by conditioning the next action on the self-assessment, and (2) providing dense, step-level internal reward during training by mapping the verbal guidance to scalar rewards. Both self-guidance and policy are jointly optimized through a co-evolutionary loop, enabling richer and more consistent training signals compared to using sparse environment reward alone.
This dual-use of self-generated guidance addresses reward sparsity by injecting actionable, trajectory-aligned supervision into both training and inference. The signals are created online within the agent's current rollout distribution, mitigating distributional drift that arises when using fixed external reward models.
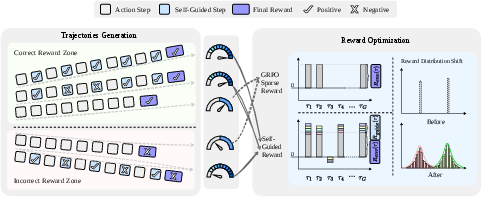
Figure 1: Using self-guided assessments during trajectory generation yields denser, more discriminative supervision relative to sparse end-of-episode rewards.
Training Architecture: Stage-Wise Trust Schedule
A central technical contribution is a stage-wise trust schedule that regulates when and how strongly self-guidance is leveraged as internal reward. The training is split into four phases:
- Guidance-only warm-up: Self-guidance is used solely to condition actions, not as reward.
- Reward activation: A linear ramp activates the internal reward, allowing guidance to inform policy gradients.
- Full internal reward: Self-guidance serves at full weight for both action selection and policy optimization.
- Late annealing: The contribution of internal reward is reduced, ensuring ultimate policy alignment with true environment returns.
This trapezoidal weighting schedule ensures the agent does not overfit to immature self-guidance early in training and prevents persistent reliance on internal rewards that might bias away from environmental objectives.
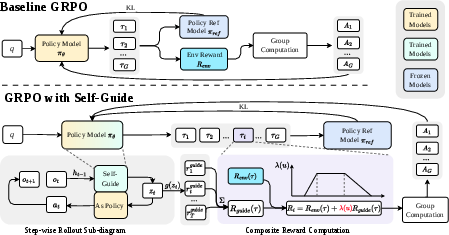
Figure 2: The Self-Guide method conditions each step on a verbal assessment, which is then repurposed as step-level internal reward and combined with sparse environment returns for joint policy optimization.
Experimental Results and Numerical Analysis
Evaluation spans three interactive LLM agent benchmarks: ALFWorld (structured text-based navigation), ScienceWorld (scientific reasoning tasks), and WebShop (unstructured web-based commerce). Agents were trained with Qwen3-1.7B, Qwen3-4B, and Qwen2.5-7B-Instruct models.
Notable findings include:
- Inference-time self-guidance alone (without reward shaping) yields substantial improvements in structured domains like ALFWorld, but offers inconsistent gains in unstructured settings such as WebShop, reflecting a dependence on domain familiarity and guidance reliability.
- Co-evolving self-guidance as reward provides consistent and significant performance boosts across all benchmarks. On ALFWorld, ScienceWorld, and WebShop, Self-Guide yields a mean improvement of ~8% over strong GRPO baselines, with improvements robust across model scales.
- The benefit is not attributable to naive reward shaping—the staged schedule and online co-evolution are both essential. Premature or static self-guidance rewards can destabilize optimization or provide unsustained gains.
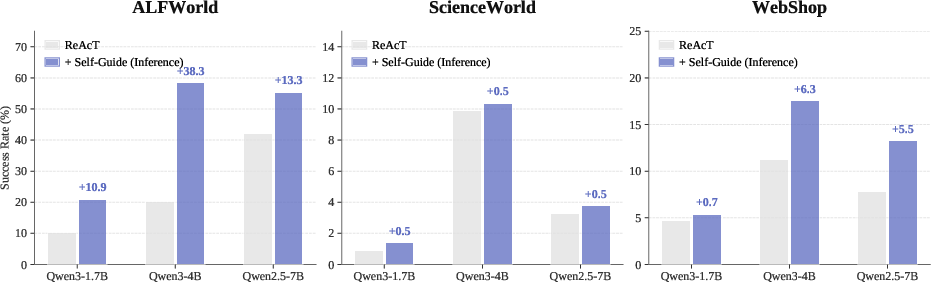
Figure 3: Self-guidance without RL training is effective in structured environments (ALFWorld), but inconsistent in complex domains such as WebShop, highlighting task-specific limitations.
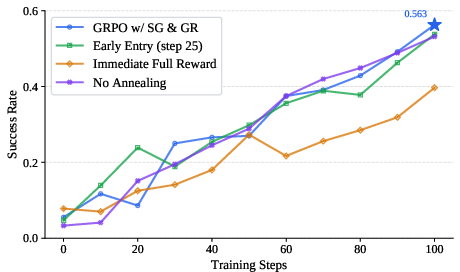
Figure 4: Ablation on phase scheduling. Early or unannounced introduction of self-guidance reward degrades final performance, validating the necessity of a trust schedule.
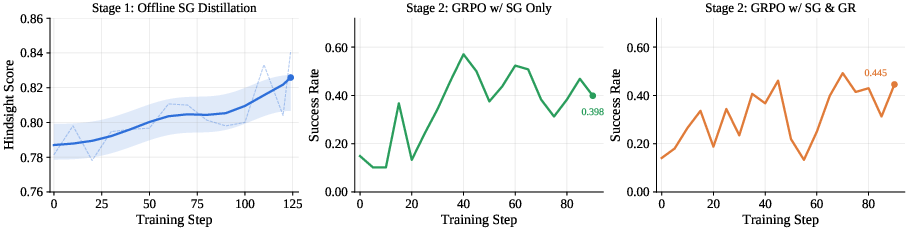
Figure 5: Offline self-guidance distillation yields weak transfer and unstable gains, highlighting the superiority of online co-evolution between policy and internal reward.
Broader Implications and Technical Directions
The results offer strong empirical and methodological support for internal co-evolution of policy and reward in LLM agents. Critically, this approach avoids the need for externally trained evaluators or static process reward models, which are both costly and susceptible to distributional mismatch.
Potential implications and directions informed by this work include:
- Unified decision-time and training-time supervision: Agents can continuously refine actionable internal evaluators as a byproduct of interaction, closing the gap between learning and deployment distributions.
- Reduction in RL dependence on sparse external signals: Particularly useful in domains where fine-grained reward annotation or environment instrumentation is impractical.
- Generalization to other RL objectives: The framework is compatible with alternative group-relative and advantage-based RL objectives beyond GRPO, as demonstrated with DAPO.
- Opportunities for meta-RL and continual learning: Agents may evolve richer meta-cognitive strategies for self-assessment, as seen in "Self-Distilled Reasoner" [31wkVZXEaJ] and "Self-Distillation Enables Continual Learning" [HlWA3V6iKF].
The main limitation is that self-guidance quality is bounded by agent capabilities and familiarity with the domain; naïvely exported guidance from large teacher models does not consistently transfer to downstream RL efficacy. This underscores the need for online adaptation and co-evolution.
Conclusion
Self-Guide represents a robust, interpretable, and sample-efficient advancement for LLM agent training under reward sparsity constraints. By explicitly coupling self-generated guidance with both inference-time decision processes and training-time reward shaping—regulated through a stage-wise trust schedule—the framework surpasses traditional RL techniques across benchmarks. The broader agenda set forth is explicit: empowering language agents to become their own evaluators and teachers, co-evolving policy and reward to unlock continual, robust skill acquisition across open-ended domains.

