Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems
Abstract: Reasoning-intensive retrieval aims to surface evidence that supports downstream reasoning rather than merely matching topical similarity. This capability is increasingly important for agentic search systems, where retrievers must provide complementary evidence across iterative search and synthesis. However, existing work remains limited on both evaluation and training: benchmarks such as BRIGHT provide narrow gold sets and evaluate retrievers in isolation, while synthetic training corpora often optimize single-passage relevance rather than evidence portfolio construction. We introduce BRIGHT-Pro, an expert-annotated benchmark that expands each query with multi-aspect gold evidence and evaluates retrievers under both static and agentic search protocols. We further construct RTriever-Synth, an aspect-decomposed synthetic corpus that generates complementary positives and positive-conditioned hard negatives, and use it to LoRA fine-tune RTriever-4B from Qwen3-Embedding-4B. Experiments across lexical, general-purpose, and reasoning-intensive retrievers show that aspect-aware and agentic evaluation expose behaviors hidden by standard metrics, while RTriever-4B substantially improves over its base model.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about making search tools smarter for hard questions that need careful thinking. Instead of just finding pages that look similar to a question, the authors want search systems to find the right mix of evidence that helps a reasoning process. They build a new test (a benchmark) to measure this, and they train a new search model to do it better.
Think of answering a tough question like building a jigsaw puzzle. Most current search tools bring you lots of pieces from the same corner of the puzzle. This paper teaches and tests search tools to bring different, complementary pieces so you can complete the whole picture faster.
The main questions the researchers asked
- How can we fairly test whether a search tool finds all the different “pieces” of information needed to reason through a complex question?
- How can we train a search tool to collect a balanced set of helpful evidence, not just one highly relevant passage?
- Do search tools that score well on standard tests also work well when plugged into a step-by-step “research agent” that plans, searches, reads, and writes an answer?
What they built and how they tested it
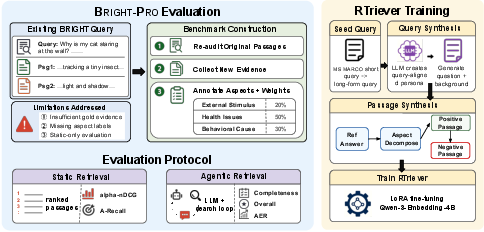
1) A new benchmark: BRIGHT-PRO
The authors upgraded an existing dataset called BRIGHT to create BRIGHT-PRO. Each question now comes with:
- Reasoning aspects: These are the key sub-questions or angles you must cover to answer the question well. For example, for “Why is my cat staring at the wall?” aspects might include “health issues,” “external stimuli,” and “behavioral causes.”
- Aspect weights: Some aspects matter more than others. Experts give each aspect an importance score so systems are rewarded for covering the most critical parts, not just many small ones.
- More and better evidence: Experts collected and cleaned more high-quality passages and labeled which aspect each passage supports.
They then evaluated search tools in two ways:
- Static retrieval: One-shot ranking of passages. The tool returns a list of passages for a single query.
- Agentic retrieval: The tool works inside a research agent (an AI that iteratively plans searches, reads results, and writes answers with citations). This is closer to how a person actually researches: search, read, think, and repeat until confident.
To judge final answers, another strong AI compares them to a trusted reference answer and scores:
- Aspect coverage (how many important aspects were addressed)
- Overall quality (clarity, correctness, usefulness)
There’s also an efficiency score that rewards good answers done in fewer search rounds.
2) A new training dataset and model: RTriever-Synth and RTriever-4B
Training search tools is tricky. Most training pairs are “query + single good document,” which teaches the tool to find one great passage, not a full set of complementary evidence. The authors fixed this by creating:
- RTriever-Synth: Synthetic training data where each analytical query comes with multiple positive passages, each covering a different aspect of the answer. It also includes “hard negatives” that look relevant but subtly miss an aspect. This teaches the search tool to choose an evidence portfolio that covers all aspects.
- RTriever-4B: A 4-billion-parameter retriever fine-tuned with a lightweight method called LoRA (like adding small plug-in adapters) on RTriever-Synth. It’s based on the Qwen3-Embedding-4B model but specialized for reasoning-heavy search.
Everyday analogy: Instead of training a librarian to grab just the single best book, they trained the librarian to build a reading list that covers all angles of the question and to avoid books that sound on-topic but don’t answer what you really need.
Key findings and why they matter
Here are the most important takeaways from the experiments, explained simply:
- Aspect-aware testing changes the leaderboard: When you score tools for covering all the needed angles, not just similarity, you get a different ranking than with standard metrics. Models trained for reasoning-focused retrieval move to the top, while general-purpose models drop.
- Best overall static performer: BGE-Reasoner was strongest on the new, aspect-aware static test.
- The new model helps: RTriever-4B, trained on complementary positives and hard negatives, clearly improves over its base model and holds its own against bigger general-purpose models.
- Static scores don’t tell the whole story: A tool that looks great in one-shot retrieval is not always the best inside an interactive research agent. In the agent loop, some tools help the agent reach complete, high-quality answers faster.
- A surprise about classic keyword search (BM25): It does poorly in one-shot tests but becomes competitive when the agent can ask follow-up searches with more precise keywords. This shows that interaction can reduce “vocabulary mismatch” and make simple methods useful again.
- Early good evidence saves time: If the retriever surfaces the right mix of evidence early, the agent needs fewer rounds, answers better, and costs less to run.
- Failure patterns are visible with aspect-aware testing: The authors found issues like “aspect tunnel vision” (retrieving many passages for one aspect while ignoring others), repetition of similar documents, or the agent “speculating” when the retriever doesn’t find solid evidence. These problems are hard to see with old metrics but pop out with aspect-aware and agentic evaluation.
What this means going forward
- For builders of research agents: Train and evaluate retrievers on full evidence portfolios (all puzzle pieces), not just single best passages. This can cut the number of search rounds, reduce cost, and boost answer quality.
- For evaluation: Benchmarks should check whether a tool covers all key aspects and should test performance inside an agent loop, not just in isolation. That’s closer to the real world.
- For model training: Synthetic data that decomposes answers into aspects and adds “hard negatives” is a practical way to teach search tools what matters for reasoning.
- For users and applications: Better retrieval means faster, more complete answers for complex tasks like medical explanations, policy analysis, climate questions, and technical troubleshooting.
In short, this paper shows that solving hard questions isn’t about finding one perfect page—it’s about assembling the right mix of evidence. By creating a better test (BRIGHT-PRO) and a better training approach (RTriever-Synth), the authors push search tools to work the way good researchers do: cover all the important angles, as efficiently as possible.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed to guide concrete follow-up work:
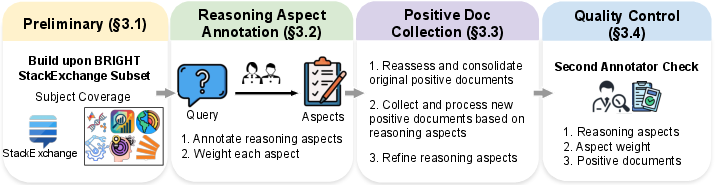
- Domain coverage limits: BRIGHT-PRO only builds on the StackExchange subset (seven domains), excluding coding/theorem tasks and other high-stakes areas (e.g., medicine, law, finance) and non-English settings; generalizability to these domains is untested.
- Gold evidence completeness: Even after re-auditing/expansion, the benchmark cannot guarantee exhaustive gold coverage per query; there is no estimate of recall ceiling or analysis of how missing-but-valid evidence affects scores.
- Aspect annotation reliability and sensitivity: Aspect weights and granularity are subjective; reliability is reported on only 50 queries. Sensitivity of rankings to (i) aspect definitions, (ii) weight normalization, and (iii) novelty penalties is not quantified.
- Closed-corpus agentic evaluation: Agentic experiments search only within the curated BRIGHT-PRO corpus, not the open web; ecological validity under web noise, domain drift, and dynamic pages is unassessed.
- Agent–retriever confounds: Results vary across two LLM agents and suggest retriever–agent “fit,” but there is no systematic methodology to decouple retriever quality from planner/query-rewriter quality or to measure compatibility.
- LLM-as-judge dependence: Final-answer evaluation relies on a single judge (GPT-5) with no human adjudication, cross-judge calibration, or significance testing; robustness to judge prompts, versions, and biases is not reported.
- Metric design choices: a-nDCG uses a fixed novelty penalty (α=0.5), A-Recall uses annotated weights; no sensitivity analysis or justification of hyperparameters is provided, and alternative diversity/coverage metrics are not benchmarked.
- Stopping and budget policies: Adaptive stopping criteria and AER’s γ=0.05 are fixed without justification or sensitivity study; top-5 per round and k per round are not varied to probe stability of findings.
- Chunking/indexing effects: Passage segmentation, merging, chunk size, and overlap policies can materially affect retrieval and aspect coverage, but ablations on these design choices are absent.
- Reranking and multi-stage retrieval: The study evaluates single-stage retrievers without rerankers; the interplay between reasoning-intensive retrievers and portfolio-aware reranking is unexplored.
- Query reformulation strategies: Agents issue follow-up queries, but there is no controlled analysis of how different reformulation strategies interact with retriever behaviors (e.g., lexicalization aiding BM25) or how to co-train for synergy.
- Portfolio diversity at inference: While evaluation rewards aspect novelty, inference uses standard top-k; no test-time diversification or portfolio-aware selection is explored, and no diversity metric is reported beyond a-nDCG.
- Quantifying failure modes: Qualitative patterns (repetition bias, aspect tunnel vision, hypothesis hopping) are described, but there is no quantitative metricization, prevalence measurement, or tested mitigation.
- Synthetic training data realism: RTriever-Synth passages are LLM-written, risking stylistic artifacts and distribution mismatch with real web text; no human audit of synthetic quality or artifact leakage analysis is provided.
- Ablations on synthesis pipeline: The contribution of each synthesis component (persona rewriting, reference-answer decomposition, positive-conditioned negatives) is not isolated via controlled ablations.
- Training objective misalignment: Despite multi-aspect positives, training uses single positive/negative per step with pairwise InfoNCE; listwise or multi-positive objectives designed to optimize portfolio coverage are not tested.
- Negative sampling curricula: Only one synthesized hard negative (plus in-batch) is used; the effects of harder negatives, multiple negatives, or curriculum scheduling on aspect coverage remain unexplored.
- Scaling laws and capacity: No study of how model size, LoRA rank, or training set size (e.g., beyond 140K bundles) affects performance; full fine-tuning vs. LoRA and architecture comparisons are missing.
- Cross-benchmark generalization: Retrievers are primarily evaluated on BRIGHT-PRO; performance on other reasoning benchmarks (e.g., BEIR tasks requiring multi-hop, RAR-B, MM-BRIGHT, IFIR) and cross-lingual settings is not reported.
- Cost and efficiency profiling: Beyond AER, there is no measurement of embedding throughput, latency, memory footprint, or index build time—key for deployment trade-offs and for assessing LLM-based retrievers’ overhead.
- Time awareness and evidence freshness: The benchmark does not model temporal validity or outdated evidence; how retrievers handle time-sensitive queries remains open.
- Data provenance and licensing: The paper does not discuss licensing/usage constraints of crawled web content or potential compliance/ethics issues in distributing BRIGHT-PRO passages.
- Release and reproducibility details: It is unclear whether BRIGHT-PRO, RTriever-Synth, and code will be released with sufficient metadata (prompts, seeds, indexes) to reproduce results and reduce evaluation variance.
- Robustness to adversarial/ambiguous queries: No evaluation under adversarial negatives, ambiguous intents, or noisy queries to test retriever stability and the agent’s calibration.
- Uncertainty and coverage signaling: Retrievers do not estimate aspect-level coverage or confidence that could inform the agent’s stopping/expansion decisions; methods to expose such signals are not investigated.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging BRIGHT-PRO’s evaluation protocols, RTriever-Synth’s data generation pipeline, and the empirical findings on agentic search behavior.
- Aspect-aware retriever evaluation in MLOps pipelines (software, enterprise search)
- Replace single-passage IR metrics with α-nDCG and weighted Aspect Recall, and add agent-in-the-loop tests using AER to select retrievers that minimize iteration cost while maximizing answer quality.
- Dependencies/assumptions: Access to an LLM-as-judge for response scoring; modest engineering to integrate aspect-weighted metrics and fixed/adaptive-round harnesses; benchmark content limited to domains akin to BRIGHT-PRO.
- Low-cost upgrade of legacy search via LLM query reformulation (customer support, finance, legal, software)
- Exploit the finding that BM25 becomes competitive in agentic loops: add an LLM “follow-up query” generator to existing BM25/keyword stacks to cut vocabulary mismatch and improve aspect coverage without replacing infrastructure.
- Dependencies/assumptions: Reliable LLM for reformulations; monitoring to avoid query drift; existing BM25/lexical index quality.
- Domain-tuned retrievers using LoRA on synthetic, aspect-decomposed data (healthcare, finance/compliance, energy, enterprise knowledge)
- Use the RTriever-Synth method to rewrite domain seed queries into analytical posts, generate complementary positives and positive-conditioned hard negatives, and LoRA-tune a 4B retriever for reasoning-ready evidence selection.
- Dependencies/assumptions: LLMs for synthesis; data governance for any web-style generations; compute for LoRA; careful curation for regulated domains.
- Evidence-portfolio search UX (due diligence dashboards, literature reviews, internal wikis)
- Present results organized by reasoning aspects with weights; enforce diversity via novelty penalties (α-nDCG) and show “coverage meters” to guide users/agents toward missing aspects.
- Dependencies/assumptions: Aspect schemas per task; UI engineering; alignment between aspect weights and user objectives.
- Agentic stop/continue policies driven by AER (all sectors operating research agents)
- Adopt the Efficiency–Quality Reward to trigger early stopping when additional rounds offer diminishing returns; budget iteration count by expected AER uplift.
- Dependencies/assumptions: Calibrated LLM-judged quality scores; organization-specific γ (decay) tuning; logging infrastructure.
- Retriever–agent compatibility testing for procurement (public sector, enterprise IT)
- Evaluate vendor retrievers in fixed and adaptive agentic protocols to detect systems that are “eventually good” but iteration-heavy; include AER and aspect completeness in RFPs.
- Dependencies/assumptions: Standardized prompts/tools during trials; reproducible corpora or snapshotting; acceptance of LLM-judging in procurement.
- Software engineering assistants with complementary evidence retrieval (software)
- In code assistants, retrieve API docs, analogous StackOverflow threads, and bug reports as distinct aspects to reduce speculative reasoning and shorten debug loops.
- Dependencies/assumptions: Access to code/documentation corpora; aspect schemas for APIs/errors; integration with IDEs/CI.
- Troubleshooting copilots for robotics and IoT (robotics, manufacturing)
- Structure retrieval around subcomponents (sensors, firmware, mechanics) and surface complementary evidence to avoid “aspect tunnel vision” in diagnosis.
- Dependencies/assumptions: Device-specific knowledge bases; safe deployment constraints; connectivity in field ops.
- Course and study guide construction with aspect-weighted readings (education)
- Instructors map learning objectives to aspects and assemble readings/evidence per aspect; students receive portfolios emphasizing higher-weighted facets.
- Dependencies/assumptions: Instructor time to define aspects; licensing for readings; simple rubric alignment.
- Personal research plugins that reduce tab overload (daily life, media)
- Browser extensions that cluster results by aspects, track covered vs. missing angles, and suggest targeted follow-up searches.
- Dependencies/assumptions: LLM API for planning; responsible scraping; lightweight local indexing or API-based retrieval.
Long-Term Applications
These opportunities require further research, scaling, or domain adaptation beyond the current paper (e.g., broader domains, safety/robustness, larger synthetic data).
- Aspect-aware public web search and consumer assistants (software, media)
- Build search engines that plan across aspects, diversify results, and provide weighted coverage explanations; reduce time-to-answer for complex queries.
- Dependencies/assumptions: Large-scale aspect induction at web scale; robust de-duplication and spam resistance; UI acceptance.
- Clinical decision support with multi-aspect evidence portfolios (healthcare)
- Retrieve guideline excerpts, trial evidence, patient-risk modifiers, and cost/feasibility aspects as complementary evidence for clinician-facing summaries.
- Dependencies/assumptions: Regulatory compliance (HIPAA/GDPR); medically verified aspect schemas; bias and safety auditing; highly reliable LLM-judging or human oversight.
- Regulatory and compliance copilots with coverage guarantees (finance, energy, legal, public policy)
- Formalize aspect sets for statutes/rules (e.g., risk, disclosure, jurisdiction) and require minimum weighted coverage before issuing recommendations.
- Dependencies/assumptions: Continual updates to regulations; auditable logs; acceptance of aspect-weighted metrics in audits; domain-expert validation.
- Agent–retriever co-optimization via RL on AER and aspect coverage (software, platforms)
- Jointly train planners and retrievers to minimize rounds while maximizing weighted completeness; auto-learn when to stop, reformulate, or pivot aspects.
- Dependencies/assumptions: Stable RL infrastructure; reliable reward shaping without Goodharting; large-scale logs.
- Scientific literature synthesis with portfolio-aware retrieval (academia, pharma R&D)
- Map survey/review sections to aspects (methods, results, limitations, mechanisms) and enforce complementary retrieval to improve coverage and attribution.
- Dependencies/assumptions: High-quality corpora and metadata; domain ontologies for aspects; citation fidelity checks.
- Multimodal, aspect-decomposed retrieval (robotics, autonomous systems, education, media)
- Extend BRIGHT-PRO and RTriever-Synth to images, diagrams, videos; retrieve complementary modalities across aspects (e.g., schematics + text).
- Dependencies/assumptions: Multimodal encoders; annotated multimodal aspects; tooling for alignment and evaluation.
- Energy project and infrastructure planning assistants (energy, sustainability)
- Retrieve complementary evidence across technical specs, environmental impact, permitting, and economics, weighted by jurisdictional priorities.
- Dependencies/assumptions: Up-to-date local regulations and datasets; explainability requirements; stakeholder-validated aspect weights.
- E-discovery and investigative search with coverage metrics (legal, journalism)
- Use aspect completeness to quantify how thoroughly a topic has been investigated (e.g., actors, timelines, financial flows), guiding additional search.
- Dependencies/assumptions: Secure handling of sensitive corpora; defensible evaluation methods in court or editorial processes.
- Standardized governance benchmarks for AI agents (policy, standards bodies)
- Incorporate AER and aspect-weighted completeness in safety/efficiency standards for agentic systems to manage compute costs and environmental impact.
- Dependencies/assumptions: Consensus on metrics and thresholds; third-party evaluation infrastructure; transparency requirements for vendors.
- On-device retrieval for field robots and edge agents (robotics)
- Deploy compact, LoRA-adapted retrievers specialized for device manuals/fault logs to provide reasoning-ready evidence without cloud dependency.
- Dependencies/assumptions: Memory/compute constraints; compressed models; offline corpora management; safety testing.
- Products and tools that may emerge
- “Aspect Planner” for agent frameworks (plans, tracks, and weights aspects); “Portfolio Retriever” library implementing α-nDCG-aware diversification and positive-conditioned negatives; “AER Analyzer” for budgeting and quality–efficiency trade-offs; “AspectBench” procurement suite to test retrievers in agentic loops.
- Dependencies/assumptions: Adoption by agent platforms; sustained maintenance; validation across diverse domains and languages.
Glossary
- A-Recall (Weighted Aspect Recall): An evaluation metric that credits each reasoning aspect once when covered, weighting aspects by importance. "We complement it with Weighted Aspect Recall (A-Recall@k), which credits each aspect once covered"
- Adaptive-Round Protocol: An agentic evaluation setting where the agent decides when to stop searching based on sufficiency of accumulated evidence. "Adaptive-Round Protocol. The agent decides when to stop searching based on whether the accumulated evidence is sufficient."
- Agentic search systems: LLM-driven pipelines that iteratively plan, search, read, and synthesize information, requiring retrievers to support multi-step reasoning. "This capability is increasingly important for agentic search systems, where retrievers must provide complementary evidence across iterative search and synthesis."
- alpha-nDCG (a-nDCG): A diversity-aware ranking metric that rewards covering new aspects and penalizes redundant results from already-covered aspects. "Our primary metric is a-nDCG@k (Clarke et al., 2008) with novelty penalty & = 0.5"
- AER (Efficiency-Quality Reward): A metric combining final answer quality with the number of search rounds to capture efficiency-quality trade-offs. "We report the number of retrieval rounds, reasoning completeness, overall quality, and the Efficiency-Quality Reward (AER):"
- bf16 mixed-precision: A reduced-precision floating-point format (bfloat16) used to speed up training and reduce memory while maintaining model quality. "bf16 mixed-precision optimization through DeepSpeed ZeRO-2;"
- BM25: A classic lexical retrieval algorithm based on term frequency and document length normalization. "Although BM25 performs poorly in static retrieval, it becomes competitive under the agentic protocol"
- BRIGHT-PRO: An expert-annotated benchmark extending BRIGHT with multi-aspect gold evidence and agent-in-the-loop evaluation. "We introduce BRIGHT-PRO, an expert-annotated benchmark that extends BRIGHT with multi-aspect evidence and evaluates retrievers under both static and agentic search settings."
- Cohen’s kappa (weighted): A reliability statistic measuring inter-annotator agreement, here using weights for importance. "the resulting weighted Cohen's K of 0.742 indicates stable importance ratings across annotators."
- Deep-Research systems: Multi-stage LLM agent pipelines for complex queries that iteratively plan, search, read, and synthesize. "Deep-research systems employ LLM-based agents that iteratively plan, search, read, and synthesize information"
- DeepSpeed ZeRO-2: A distributed training optimization technique that partitions optimizer states to reduce memory and scale training. "bf16 mixed-precision optimization through DeepSpeed ZeRO-2;"
- FireCrawl: A framework for crawling and processing web pages used to build datasets with cleaned, segmentable text. "We provide annotators with a customized interface built upon the FireCrawl framework."
- Fixed-Round Protocol: An agentic evaluation setting where the agent executes a preset number of retrieval rounds before answering. "Fixed-Round Protocol. The agent performs exactly R E {1, 2, 3} search rounds."
- In-batch negatives: Negative samples formed by other examples within the same training batch to strengthen contrastive learning. "other documents in the same batch additionally serve as in-batch negatives."
- InfoNCE objective: A contrastive learning loss that pulls matched query-document pairs together and pushes mismatches apart. "Training optimizes a contrastive INFONCE objective with temperature T=0.02 on query-document pairs"
- Likert scale: A rating scale used here by annotators to assign aspect importance from 1 to 5. "annotators assign Likert scores from 1 to 5"
- LLM-as-Judge: Using a LLM to evaluate system outputs (e.g., coverage and quality) against references. "We evaluate final answers with GPT-5 as an LLM-as-Judge, following prior work on deep-research evalua- tion"
- LoRA: A parameter-efficient fine-tuning method that adds low-rank adapters to a frozen backbone. "We use this corpus to LoRA fine-tune RTriever-4B from Qwen3-Embedding-4B"
- MS MARCO: A large-scale collection of real web queries and passages, used as seeds for synthetic data generation. "Starting from MS MARCO seeds, our pipeline rewrites short queries into realistic analytical ones"
- NDCG@k: A ranking quality metric (Normalized Discounted Cumulative Gain) that considers graded relevance and position. "and report NDCG@k and Recall@k as diagnostics."
- Novelty penalty (alpha-nDCG): A parameter in alpha-nDCG that down-weights additional results from already-covered aspects. "with novelty penalty & = 0.5"
- Positive-conditioned hard negatives: Challenging negative passages crafted to be topically similar but to omit the critical aspect covered by positives. "It then generates positive-conditioned hard negatives: passages that share topical cues but deliberately omit the needed aspect."
- Reasoning aspects: Coherent subproblems or perspectives whose combined coverage is needed for complete reasoning. "Reasoning completeness often decomposes into multiple reasoning aspects, where each aspect represents a coherent subproblem or perspective."
- Reasoning-intensive retrieval: Retrieval focused on surfacing evidence that supports multi-step reasoning rather than surface-level similarity. "Reasoning-intensive retrieval aims to surface evidence that supports downstream reasoning rather than merely matching topical similarity."
- RTriever-Synth: An aspect-decomposed synthetic corpus that generates complementary positives and matched hard negatives for training. "we construct RTriever-Synth, an aspect-decomposed synthetic corpus that teaches retrievers complementary evidence selection."
- Static Retrieval Evaluation: A setting that assesses retrieval quality with a single ranked list per query against aspect-annotated golds. "4.1. Static Retrieval Evaluation"
Collections
Sign up for free to add this paper to one or more collections.

