- The paper introduces CoSearch, a framework that jointly trains both the reasoning agent and document ranker using reinforcement learning.
- The approach employs a two-stage retrieval process combining a fixed dense retriever with a trainable generative ranker optimized via semantic grouping.
- Experimental results show significant gains, reducing retrieval errors by up to 26.8% and improving answer accuracy across seven QA benchmarks.
Joint Reinforcement Learning of Reasoning and Document Ranking in Agentic Search
Problem Motivation and Limitations of Fixed Retrieval
Recent advances in agentic search leverage LLMs to iteratively interact with retrieval systems, enabling multi-turn interaction and synthesis of retrieved knowledge for complex QA. However, in prevailing frameworks such as Search-R1, the retrieval system is static and unoptimized, with only the reasoning agent updated via RL. A systematic analysis using oracle retrieval (promoting gold-matching documents to top rank at every retrieval step) reveals substantial performance bottlenecks stemming from retrieval: the fixed retriever limits achievable F1 by up to 26.8% relative on standard QA benchmarks for smaller agents—implicating the need for optimizing both retrieval and reasoning policies jointly, rather than freezing retrieval (2604.17555).
The ablation of fixed retrieval exposes that the majority of agent errors result not from the reasoning model, but from its inability to access evidentiary documents through retrieval. This leads to redundant or misformulated search queries and ultimately suboptimal answers, a bottleneck persistent across model scale.
CoSearch Framework Overview
CoSearch is introduced to jointly train a multi-hop reasoning agent and a generative document ranker within a unified RL framework. Architecturally, at every reasoning step, the agent synthesizes a query, which is processed by a two-stage retrieval system comprising:
- Fixed dense retriever: Produces a set of top-N (here, 50) candidate passages.
- Trainable generative ranker: Reranks candidates, outputting the top-K (typically 5) for agent consumption.
Both reasoning and ranking policies are optimized simultaneously via Group Relative Policy Optimization (GRPO), utilizing shared environment returns to propagate answer correctness and ranking quality signal across agent and reranker policies.
(Figure 1)
Figure 1: Both panels share the same architecture: Main Agent → Retriever → Ranker. Top: Existing approaches train only the main agent; bottom: CoSearch jointly trains the main agent and the ranker via GRPO, decomposing retrieval into a fixed dense retriever and a trainable generative ranker.
Semantic Grouping for Stable Ranker RL
A significant technical innovation is the semantic grouping of ranker calls to enable effective group-based RL optimization (GRPO) despite highly variable input distributions. Unlike agent trajectories that are naturally grouped by initial query, ranker calls are conditioned on the evolving sub-queries, which can diverge widely over rollouts. To build valid groups without introducing intractable sample inefficiency, CoSearch clusters sub-queries by token-level F1 similarity, efficiently grouping together those with high semantic overlap.
This strategy maintains the stability of advantage estimation in GRPO for the ranker without exponential increases in rollout requirement. Empirical analyses indicate that omitting semantic grouping or choosing suboptimal thresholds leads to significant optimization instability and performance drop.
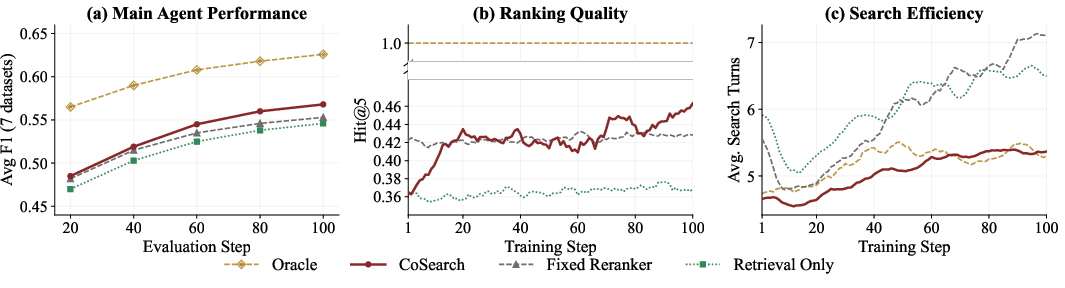
Figure 2: Training and evaluation dynamics across 100 steps. (a) Validation F1 (mean over 7 QA datasets); (b) Ranking quality (Hit@5); (c) Average number of search turns per trajectory—CoSearch improves both answer accuracy and reduces search rounds required.
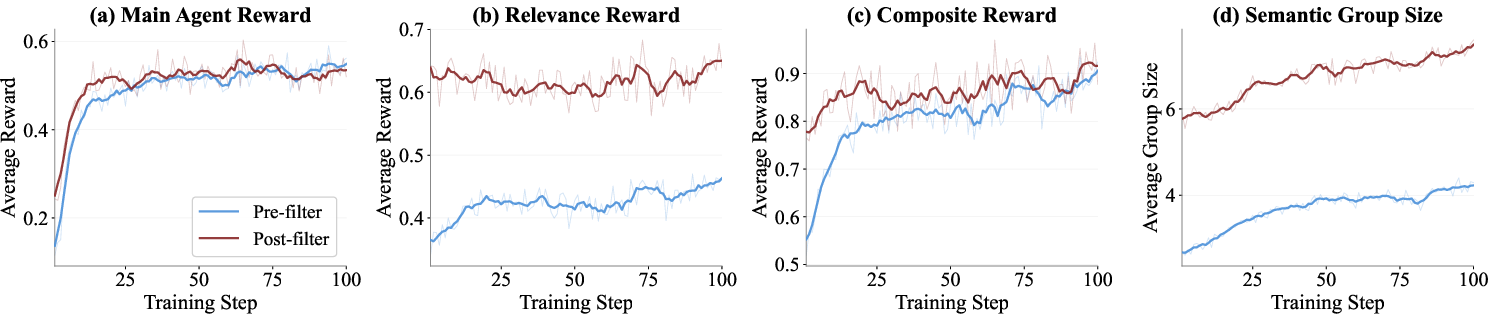
Figure 3: Ranker training dynamics: semantic grouping with minimum group size filtering yields more reliable reward estimation and stable improvement in both relevance and composite rewards as training progresses.
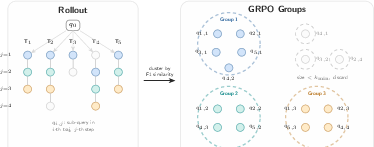
Figure 4: Illustration of semantic grouping for GRPO: sub-queries from multiple rollouts are clustered by token-level similarity, and singletons are filtered out to ensure group adequacy for effective optimization.
Composite Reward and Credit Assignment
Supervision for the ranker is provided by a composite reward:
- Relevance-based: Hit@k metrics (e.g., is a gold answer present in top-K).
- Trajectory-based: Token-level F1 on final answer.
The reward is adaptively combined: e.g., if a gold document is present but mis-ranked, the reward is dominated by relevance; when the ranking is sufficiently precise, main agent's answer correctness becomes increasingly influential. For sub-queries where no gold document exists, only answer-level reward is propagated to the ranker since there is no direct relevance signal.
This composite approach overcomes the limitations of sparse answer-level feedback, enhancing credit assignment granularity for sub-step interventions and improving both ranking and final answer accuracy.
Experimental Results
Evaluations span seven QA benchmarks (PopQA, Natural Questions, TriviaQA, HotpotQA, 2WikiMultiHopQA, Musique, Bamboogle) across both single-hop and multi-hop regimes. Summarizing the main metrics:
- CoSearch with 7B agent and 7B ranker: 0.568 average F1, outperforming Search-R1 (+6.6%) and Fixed Ranker baselines (+2.7%).
- CoSearch with 3B agent, 7B ranker: 0.471 average F1, +10.8% relative to Search-R1.
- Joint training consistently narrows the oracle retrieval gap (from up to 26.8% relative to 18.2% for 7B and 19.8% for 3B).
- CoSearch policies require fewer search calls per question, evidencing more efficient evidence gathering.
Results on reduced K reveal that performance degrades only marginally for CoSearch, indicating robust relevance modeling, whereas non-joint systems suffer greater losses from restricted retrieval.
Ablations confirm that both relevance and trajectory-level rewards are required for optimum joint training; removing semantic grouping or using a shared backbone degrades results or causes divergence.
Implications and Future Directions
This work empirically demonstrates that jointly optimizing both reasoning and data-access modules in retrieval-augmented systems delivers nontrivial accuracy gains and reduces the cost of interaction. It establishes that the search component should not be treated as a frozen facility, especially in iterative, tool-augmented QA and research agents.
The semantic grouping mechanism is directly extensible to other settings where sub-component input variability forestalls naïve group-based RL, such as complex multi-tool LLM agent systems.
Future directions include integrating full end-to-end differentiable retrievers, scaling to larger open-world corpora, and incorporating reward models bridged from demonstrated human preferences beyond answer correctness. Additionally, exploring adaptive K selection and more structured credit assignment strategies could mitigate residual gaps to oracle retrieval.
Conclusion
CoSearch provides decisive evidence that end-to-end RL optimization over both reasoning and retrieval policies is not only technically viable but essential for closing the systematic limitations imposed by static retrieval in agentic, tool-augmented QA. The semantic grouping and composite reward strategies introduced here offer a robust paradigm for stable, scalable joint RL and portend the next generation of high-performance research and web-augmented LLM agents.
Reference
"CoSearch: Joint Training of Reasoning and Document Ranking via Reinforcement Learning for Agentic Search" (2604.17555)