- The paper introduces SIRA, a one-shot expert retrieval approach that uses LLM cognition for corpus-specific lexical enrichment, improving BM25 retrieval.
- It combines offline corpus-side and online query-side enrichment stages, leveraging document-frequency statistics to inject discriminative terms into query formulation and indexing.
- Experimental results on BEIR datasets show that SIRA outperforms state-of-the-art dense and RL-based retrieval methods in recall, interpretability, and efficiency.
Superintelligent Retrieval Agent: A Corpus-Discriminative Paradigm for Expert IR
Current retrieval-augmented agents predominantly treat IR as a black-box operation: iterative querying, snippet inspection, and query reformulation are looped until satisfactory results are distilled. This exploration-centric model mirrors novice corpus navigation and is accompanied by unnecessary retrieval rounds, heightened latency, and recall limitations. Critically, modern dense embedding-based retrieval—with all its neural sophistication and in-domain tuning—offers little in the way of controllability, explicitly enforceable constraints, or interpretability. The paradigm is opaque and ultimately constrained by its inability to directly leverage domain-specific, discriminative terms or corpus-aware statistics during query formulation.
Empirical and theoretical analyses indicate that dense representational bottlenecks and static embedding approaches lack the ability to realize the full spectrum of relevance patterns required for complex, compositional, constraint-based queries characteristic of advanced multi-step or conversational search. Additionally, the efficacy of reinforcement learning (RL)-trained agentic retrieval pipelines is strongly dependent on "retrieval-context advantage”—contextual information accrued from previous rounds—leading to brittleness, inefficiency, and reliance on the imperfect long-term memory of LLMs.
SIRA Approach: Corpus-Discriminative, One-Shot Expert Search
SIRA (SuperIntelligent Retrieval Agent) redefines expert retrieval as the compression of a multi-turn search into a single, expert-level, corpus-discriminative retrieval action. The methodology pivots on a two-stage enrichment pipeline, leveraging LLM cognition to bridge vocabulary gaps and inject discriminative, corpus-grounded lexical signals into structured BM25 programs.
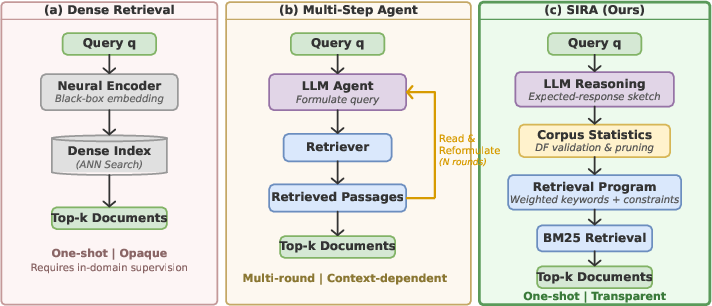
Figure 1: Comparative illustration of three retrieval paradigms: (a) dense retrieval, (b) multi-step agentic retrieval, and (c) SIRA's single-shot expert retrieval with query and document-side lexical enrichment.
- Corpus-Side Enrichment: Offline, the LLM inspects each document to hypothesize missing, discriminative search vocabulary—synonyms, aliases, domain-specific terminology—that users might employ. A strict document-frequency (DF) filter prunes candidate terms that are either absent or overly generic, ensuring every expansion increases the index's discriminative power.
- Query-Side Enrichment: Online, given a query, the LLM predicts a compact set of relevant yet query-absent terms likely to appear in supporting evidence. These are then validated by corpus index DF statistics to ensure discriminative value.
- Retrieval Programming: The original query is combined with validated expansion tokens in a single, weighted BM25 call—effectively simulating an expert's ability to anticipate corpus vocabulary and evidence structure.
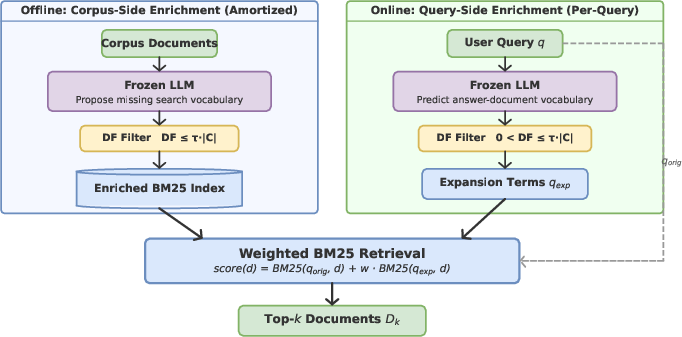
Figure 2: SIRA pipeline overview, displaying offline corpus-side enrichment and online query-side enrichment—both filtered by DF statistics—for a one-shot, weighted BM25 retrieval.
This process encapsulates retrieval superintelligence as the capacity to: (a) form domain-aware hypotheses about expected evidence, (b) ground proposals in corpus-visible statistics, and (c) produce explicit, interpretable retrieval primitives (e.g., keyword weighting, constraints) without iterative snippet reading.
Experimental Validation
SIRA is benchmarked across ten BEIR datasets representing a continuum of retrieval regimes (question answering, fact verification, argument retrieval, citation, and duplicate detection) ranging in scale from 5K to over 5M documents. Evaluation metrics include Recall@10 and NDCG@10.
- Supervised Dense and Sparse Retrievers: SIRA (Recall@10: 0.691, NDCG@10: 0.572) consistently outperforms strong dense (E5: 0.648/0.543) and learned sparse retrievers (SPLADE: 0.625/0.522), despite being entirely training-free and forgoing embedding indices.
- LLM-Based Agentic Pipelines: SIRA surpasses advanced LLM agentic frameworks, including multi-turn RL-trained search agents, HyDE, CoT, and grep-based agents (e.g., GrepRAG, ShellAgent)—even though all employ identical or comparable LLM backbones. The margin is particularly pronounced for query-document pairs with structural vocabulary gaps, where corpus-validated enrichment is critical.
Downstream Question Answering
SIRA’s retrieval advantage translates into downstream QA: on NQ and HotpotQA, its retrieval-only answer coverage at top-10 (84.7% / 77.6%) surpasses the reported full-system accuracies of six recent RL-trained agentic QA systems—even though SIRA supplies only the evidence and no answer synthesis or candidate reranking is performed.
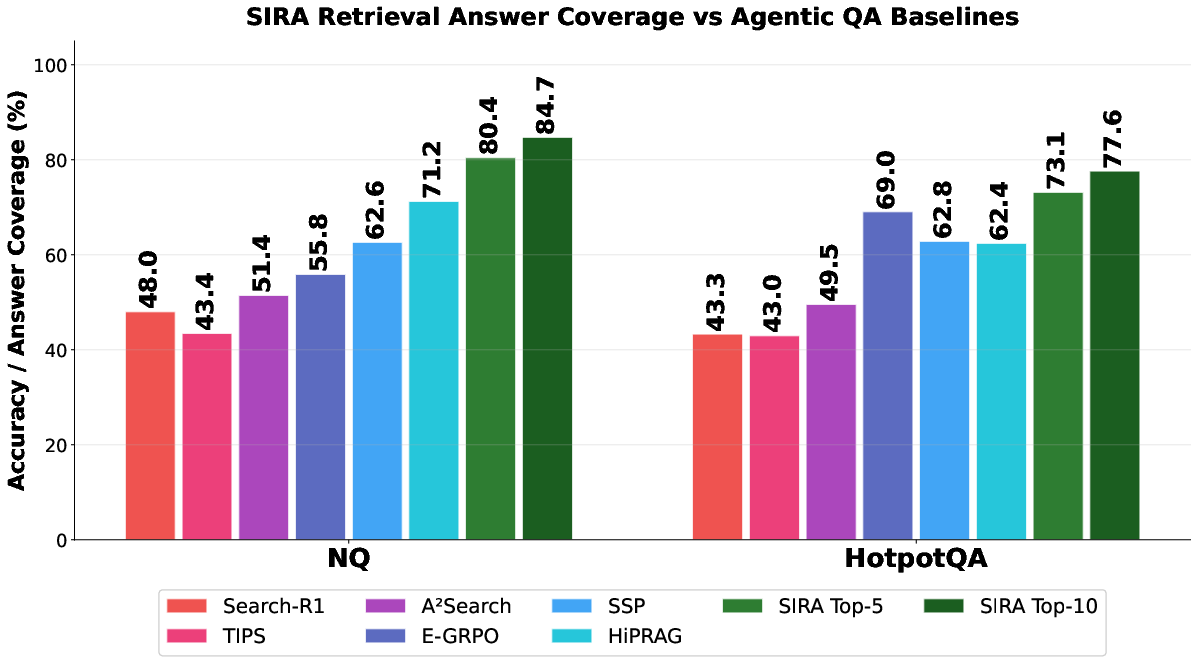
Figure 3: SIRA answer coverage on NQ and HotpotQA in comparison with six RL-trained agentic QA baselines, measured at top-5 and top-10 thresholds.
These results validate the core thesis: expert, corpus-discriminative lexical retrieval powered by LLM reasoning, grounded in corpus statistics, can render both multi-round search and sophisticated dense retrieval backends superfluous for high-recall, interpretable IR and QA.
Theoretical and Practical Implications
Theoretically, SIRA addresses corpus-discriminative retrieval hardness overlooked by black-box LLM agent frameworks. By exposing and leveraging index-visible statistics (DF, IDF), SIRA realizes document ranking policies that better conform to the probability ranking principle and learning-to-rank regime. It operationalizes classic IR strengths—control, transparency, and discriminativity—within a modern, reasoning-driven agent loop.
Practically, SIRA demonstrates that:
- LLM cognition can be repurposed not for brute-force answer synthesis, but as a control layer programmable atop efficient inverted indices.
- Large-scale supervision and domain interaction logs are not prerequisites for state-of-the-art retrieval in open-domain, heterogeneous benchmarks.
- RL-based and multi-round retrieval agents—burdened by latency, context retention issues, and noisy exploration—can be outperformed by a single well-formed, corpus-aware lexical retrieval.
Limitations and Prospects
A key assumption is that the frozen LLM—employed for enrichment—possesses adequate semantic priors regarding the target corpus. SIRA’s efficacy in highly out-of-distribution domains, or those with genuinely novel terminology not present in the LLM pretraining data, requires further exploration and may necessitate adaptive enrichment or LLM fine-tuning.
Future research will need to investigate:
- Systematic corpus adaptation: dynamically updating enrichment pipelines for domain drift or corpora with limited overlap with public LLMs.
- Further integration with structured constraints, attribute filtering, or personalized retrieval.
- Extending SIRA principles to retrieval-augmented generation in high-complexity downstream tasks, including multi-modal or non-textual corpora.
Conclusion
SIRA fundamentally reframes the role of LLMs and lexical ranking in retrieval-augmented architectures. By converting LLMs into expert retrieval programmers and maximizing the discriminative value of lexical interfaces such as BM25, it achieves marked gains in IR and downstream QA—all without reliance on dense embeddings, retrieval-context accumulation, or RL pipelines. These findings challenge established conventions, suggesting that retrieval-augmented agents can achieve superior recall, interpretability, and efficiency by compressing search interaction into an explicit, corpus-discriminative BM25 programming model, underpinned by LLM comprehension and corpus statistics (2605.06647).

