- The paper demonstrates that structured specifications significantly boost repository-level test pass rates in LLM-generated code.
- It introduces Structured Spec-Driven Engineering (SSDE), combining Gherkin specs and domain models to reduce ambiguity and enhance verifiability.
- Empirical evaluations reveal that explicit model-layer signatures improve performance, promoting a shift from prompt to specification engineering.
LLM-Assisted Repository-Level Generation with Structured Spec-Driven Engineering
Introduction
The paper "LLM-Assisted Repository-Level Generation with Structured Spec-Driven Engineering" (2605.02455) presents a systematic approach to scaling LLM code generation capabilities from individual functions to complete software repositories. The authors introduce Structured Spec-Driven Engineering (SSDE), a paradigm that employs structured artifacts—particularly Gherkin specifications and domain models—to guide LLMs in repository-level code synthesis. The motivation is to address the inherent ambiguity and lack of verifiability associated with traditional natural language prompting for large-scale code generation tasks. Through an empirical pilot study, the feasibility, strengths, and limitations of SSDE are explored, establishing a research agenda for reliable, verifiable, and automatable code generation at the repository level.
Structured Spec-Driven Engineering: Motivation and Methodology
Current LLM workflows perform well on local code generation tasks but exhibit reliability issues as system complexity increases. Ambiguity in natural language instructions undermines the effectiveness and reproducibility of repository-level synthesis. SSDE is premised on the hypothesis that structured specifications mitigate this ambiguity, serve as precise communication channels between intent and implementation, and provide verifiable benchmarks for code quality.
The study operationalizes SSDE as follows: LLMs are prompted to generate Python-based Model-View-Controller (MVC) business logic for diverse open-source systems. Input configurations systematically vary among natural language descriptions, Gherkin specifications, domain models (Umple/Ecore), and explicit model-layer signature artifacts. The distinctive contribution is the integration of structured specifications both as guidance for generation and as ground-truth for verification.
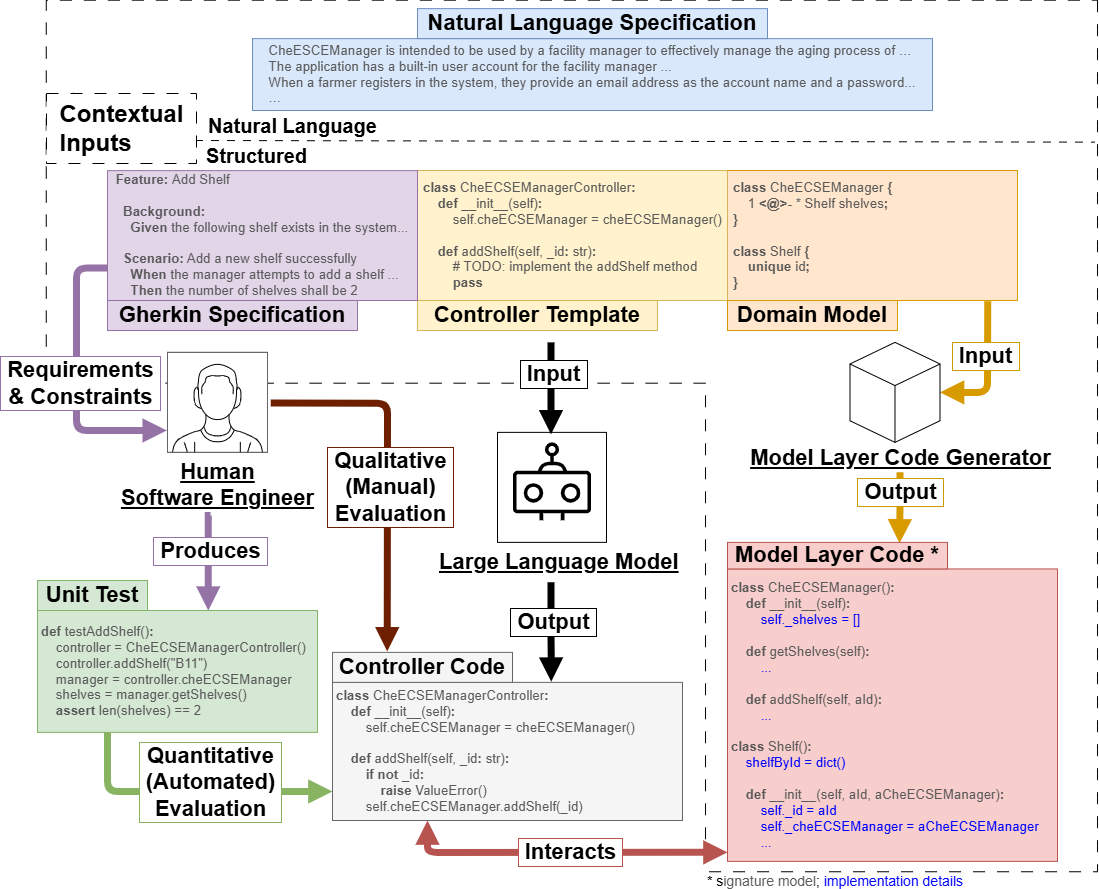
Figure 1: Overview of the SSDE workflow, showing how LLM input is structured using specifications, domain models, and signature models, and how generated code is evaluated using human-verified test suites.
Experimental Study Design
Three representative software systems were used, each selected for conformity to the MVC pattern and the availability of up-to-date domain models and Gherkin specifications. Five LLMs—including Claude Sonnet 4.5, Qwen 3 Coder, GPT 5.1/Nano, and Llama 3.2—were evaluated over multiple zero-shot prompt runs per input condition. The quantitative metric for code quality is the test pass rate (TPR) against handcrafted unit test suites mapped to Gherkin scenarios. Manual inspection supplements the analysis with qualitative categorization of error types. Systematic variation in LLM contextual input enables fine-grained assessment of the marginal impact of structured artifacts.
Results and Key Findings
A critical outcome is the substantial boost in achieved TPR when moving from unstructured (free-form) natural language inputs to any form of structured specification. The consolidation of results (Figure 2) demonstrates that structured specifications consistently yield higher and more stable TPRs than natural language alone.
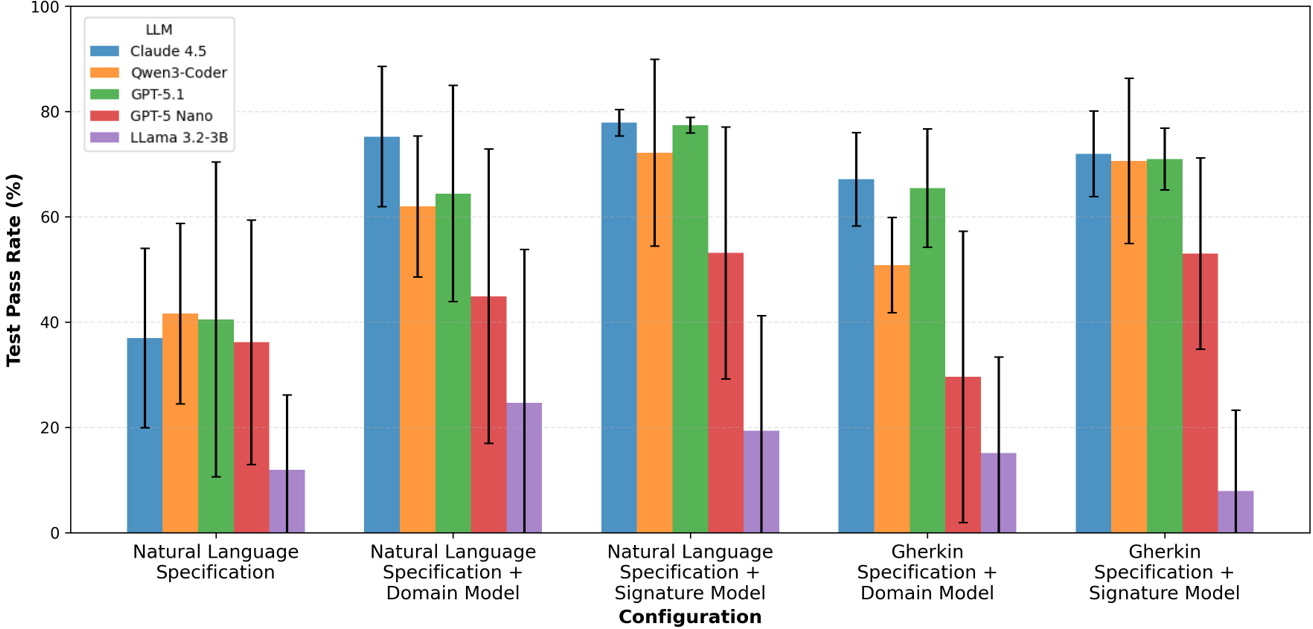
Figure 2: Distribution of average test pass rates (TPR) across LLMs and input configurations, showing superior performance when structured specifications are included.
Further, the pilot study yields several notable findings:
- Structured specifications increase verifiability and testability: Incorporating Gherkin scenarios or domain models reduces the likelihood of implementation errors, particularly those that can be statically detected.
- Model-layer signatures outperform pure domain models as contextual input: Providing explicit method and data signatures to the LLM raises both average TPR (+7.82%) and reduces output variance (−2.47%), indicating the challenge LLMs face in mapping abstract model syntax to language-specific APIs absent direct example.
- Gherkin specification + Domain Model is highly competitive: For a subset of conditions, this pairing yields the highest TPR, demonstrating that combined behavioral and structural guidance offers the LLM most effective synthesis cues.
- High standard deviations in TPR persist: This reflects output instability—LLMs, when erring, tend to generate globally incorrect controller logic, emphasizing the need for post-generation validation and correction.
- Error analysis reveals most failures are statically detectable: 49% are invocations of nonexistent APIs, 20.2% are type mismatches, and 15% relate to structural constraints—all amenable to static analysis and code feedback mechanisms.
Implications, Practical and Theoretical
The evidence positions SSDE as an actionable bridge between LLM reasoning and classic software engineering practices. By aligning code generation with verifiable structured inputs, SSDE addresses reproducibility, maintainability, and safety in the automation pipeline—a sine qua non for practical adoption in engineering.
This approach shifts the role of engineers from manual implementation to high-level specification design and curation, facilitating more effective human-AI collaboration. The robust verifiability of Gherkin and domain models enables the automatic synthesis of tests, supports the development of custom linters, and allows for the systematic construction of specification-grounded code quality agents. A significant implication for the field is that repository-level code generation can be reframed as a “specification engineering” exercise, not just program synthesis.
Roadmap: Research Opportunities and Challenges
Several lines of further inquiry emerge from the pilot study:
- Feedback and Correction Loops: Integrating static and dynamic analyses to detect and iteratively correct most failure modes can substantially increase output quality using LLM self-correction abilities [Chen et al., 2023; Hong et al., 2024].
- Specification-Driven Fine-tuning: Transfer learning or few-shot prompting targeting model-layer syntax mapping could align LLM reasoning more closely with high-level abstractions, reducing input token load and boosting robustness.
- Productivity Measurement: Net productivity gain must be empirically evaluated, considering both the reduction of manual coding and the overhead of maintaining structured specifications.
- Agentic Tools and Real-world Applicability: Benchmarking SSDE in interaction with multi-turn agentic systems (e.g., Copilot, Claude Code) is required to reflect modern software practices.
- Partial Repository Update and Maintenance: Research is needed into techniques for partial code identification and update propagation as specifications evolve, supporting continuous software evolution.
- Scalability and Data Curation: The development of open, diverse SSDE benchmarks is crucial for generalizable progress.
Conclusion
SSDE marks a paradigm shift, substantiating the move from isolated code completion to end-to-end, LLM-driven repository engineering grounded in structured specification artifacts. The pilot results establish that structured specifications can elevate the reliability, testability, and maintainability of LLM-generated repositories beyond the limits of conventional natural language prompting. While obstacles concerning LLM knowledge, specification maintenance, and integration with agentic workflows remain, the evidence presented in this study delineates a clear path towards scalable, verifiable, and semi-automatic software engineering. The field is thus positioned to transition from prompt engineering to specification engineering as foundational for trusted LLM-based automation.
References:
- "LLM-Assisted Repository-Level Generation with Structured Spec-Driven Engineering" (2605.02455)

