- The paper presents a novel benchmark that integrates natural language requirements with detailed UML designs for evaluating repository-level code generation.
- It compares holistic, incremental, and retrieval-augmented strategies using metrics like Pass@1 to reveal performance drops on larger, complex repositories.
- The study underscores limitations in current LLM outputs, advocating for hybrid approaches and enhanced design parsing to bridge the automation gap in software engineering.
RealBench: A Repository-Level Code Generation Benchmark Reflecting Real-World Software Engineering
Motivation and Benchmark Design
RealBench introduces a repository-level code generation benchmark constructed to align with actual industry software development workflows, contrasting sharply with prevailing function- and repo-level benchmarks that primarily depend on raw natural language requirements. Its central innovation lies in providing both detailed natural language requirements and full UML system designs (including package and class diagrams) reflecting how specifications are commonly delivered to developers in professional settings.
Each benchmark sample consists of:
- Natural language requirements, capturing the intended system behaviors and objectives;
- Hierarchical UML diagrams comprising package diagrams for high-level architecture and class diagrams for implementation detail;
- Comprehensive human-verified test suites with high line coverage (average 79.76%), offering a rigorous measure for functional correctness;
- Real-world repositories curated post-2024-12 to minimize data contamination, spanning 61 repositories and 20 domains, stratified across four complexity levels based on LOC.
This approach addresses gaps observed in benchmarks such as HumanEval, RepoEval, JavaBench, and EvoCodeBench, which do not reflect the typical transition from structured specification to code, potentially misrepresenting the practical automation benefit of LLM-driven code generation.
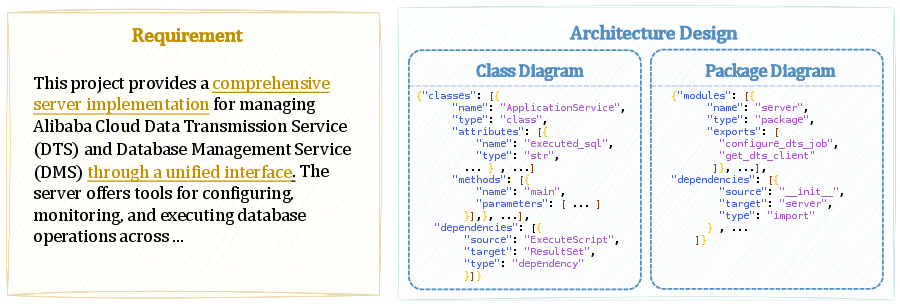
Figure 1: An example illustrating RealBench's code generation task where inputs combine natural language requirements and system design UML diagrams.
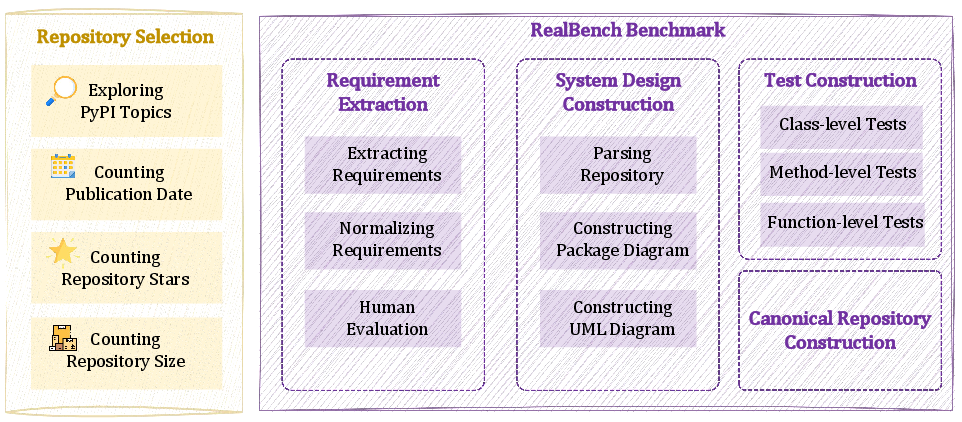
Figure 2: The RealBench construction workflow: task selection, requirement formulation, system design creation, and test suite development.
Evaluation Protocol and Metric Construction
RealBench’s evaluation system is notable for its dual-granularity framework:
- Repository-Level: Requirement@k and Architecture@k metrics, scored [0, 4], assess alignment with specified requirements and architectural fidelity using DeepWiki-assisted human comparative analysis.
- Class-Level: Completion@k, Execution@k, Pass@k metrics, quantify coverage of code element generation, executability, and functional correctness (pass rates over comprehensive test suites).
Three generation strategies are assessed:
- Holistic: All-at-once repository synthesis, leveraging full prompt.
- Incremental: Sequential module-by-module generation, aimed at mitigating long-form generation failures observed in LLMs.
- Retrieval-Augmented Generation (RAG): Iterative file-wise generation incorporating previously generated and retrieved relevant files, structured via dependency graphs.
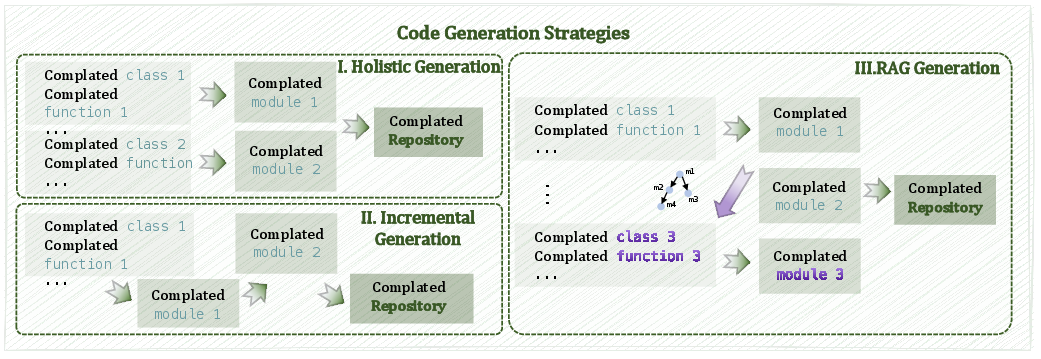
Figure 3: Schematic of the three code generation strategies for each repository: holistic, incremental, and retrieval-augmented.
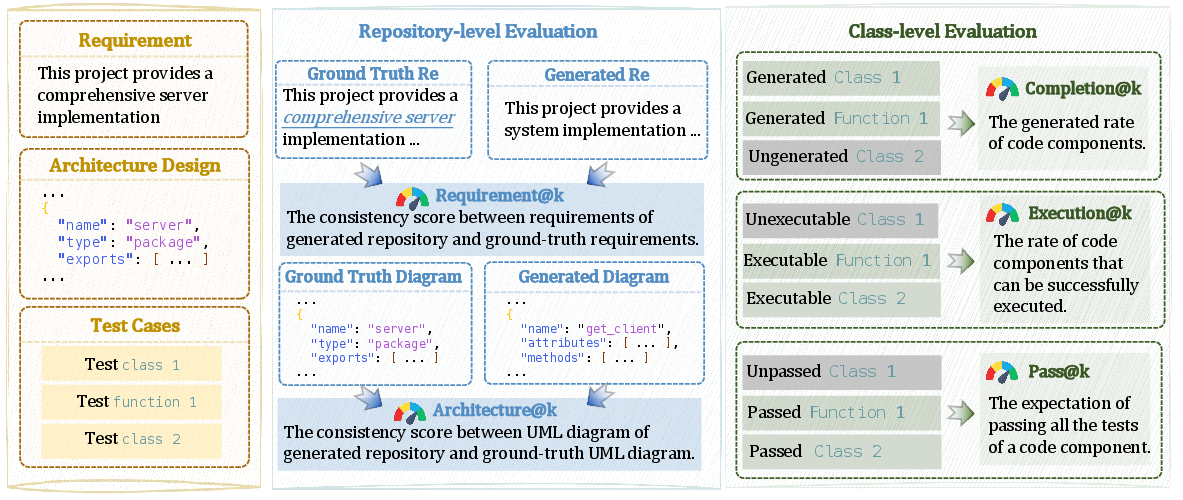
Figure 4: The evaluation design, articulating repository-level and class-level metrics for comprehensive assessment.
Experimental Results and Key Findings
Six state-of-the-art LLMs were evaluated (GPT-4o, Claude-Sonnet-4, Gemini-2.5-Flash, DeepSeek-V3, Qwen3-235B-A22B, Qwen2.5-Coder-7B-Instruct). Pass@1 scores are consistently low across models and complexity levels—best average Pass@1 is 19.39%. Performance drops sharply with increasing repository size (Pass@1 > 40% for <500 LOC, <15% for >2000 LOC). Execution and completion rates are higher, but the quality of generated modules is hampered by frequent grammar and logical errors.
Holistic generation performs best on small repositories, while incremental strategies outperform others for larger, complex repositories, corroborating limitations of LLMs in maintaining coherence over long contexts. RAG yields inferior results, likely due to input length challenges and LLM tendency to merge module boundaries erroneously.
Ablation studies establish unequivocally that class diagram detail is crucial; removing it causes dramatic drops in functionally correct synthesis and execution rates. High-level architectural guidance alone is insufficient.
The predominant runtime error types in output are AssertionError (54.3%) and TypeError (14.3%), comprising 68.6% of total failures (Figure 5), primarily symptomatic of logical and interface mismatches.


Figure 6: Examples of module deficiency and redundancy in generated outputs.

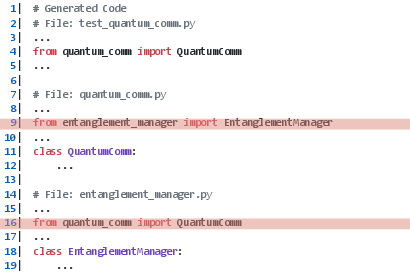
Figure 7: Instances of incorrect attribute usage—a primary source of execution failure.
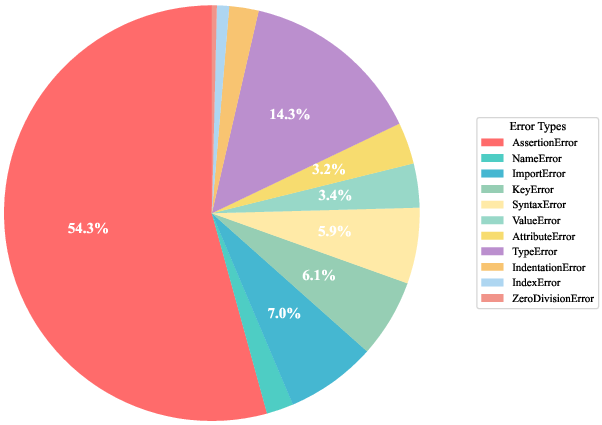
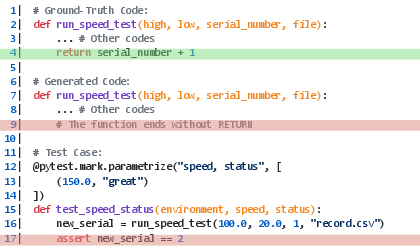
Figure 5: Distribution of error types for generated RealBench outputs evaluated by Pass@1 metrics.
Implications and Prospects
The empirical findings demonstrate that current LLMs, even top-tier ones, are fundamentally limited in producing repo-level code congruent with industry-standard design artifacts and requirements. The performance gap between function-level and repo-level tasks reaffirms that benchmarks relying solely on raw requirements overestimate LLMs’ true impact in automating enterprise software development.
Practically, RealBench provides a foundation for driving further research on LLM code synthesis, robust architectural guidance parsing, and advanced prompting strategies. Theoretical implications encompass more precise modeling of dependency relations and interface compliance, with future development likely oriented toward hybrid approaches combining structured symbolic reasoning and LLM sequence modeling.
The benchmark’s attention to data contamination and stratification by domain and size sets a precedent for future evaluation frameworks.
Conclusion
RealBench advances the state of code generation benchmarking by rigorously reflecting real-world repositories, complete system designs, and multifaceted evaluation metrics. The results indicate tangible limitations in current LLM architectures for automating repository-scale programming from structured specifications. The benchmark thus establishes a critical platform for research toward closing the practical deployment gap in AI-assisted software engineering.

