- The paper presents CodeSpecBench, a benchmark evaluating LLM performance in generating executable behavioral specifications using preconditions and postconditions.
- It distinguishes between function-level and repository-level tasks, employing execution-based metrics such as correctness, completeness, and pass rate for robust evaluation.
- The study reveals significant gaps between code generation and specification extraction, highlighting LLM limitations in semantic reasoning and cross-module dependency handling.
CodeSpecBench: A Benchmark for Evaluating LLMs on Executable Behavioral Specification Generation
Motivation and Context
Current LLMs exhibit strong code generation capabilities given natural language descriptions, but the critical question remains whether they truly understand the intended behavior of the specified tasks. Executable behavioral specifications, typically expressed through preconditions and postconditions, offer a tractable and rigorous methodology for quantifying this understanding, as they precisely delineate valid operational domains and correct output properties in an executable, verifiable format. Previous studies on specification generation have focused on static verification within limited settings―frequently restricted to function-level, formal language annotations, or deductive verification paradigms. Most notably, evaluation protocols and task scopes remain narrow, impeding the assessment of behavioral understanding at scale or within realistic codebases.
To overcome these constraints, CodeSpecBench is introduced as a comprehensive benchmark targeting the generation of executable behavioral specifications by LLMs. The benchmark embodies a dual evaluation protocol covering both function- and repository-level tasks, employs execution-based metrics evaluating both correctness and completeness, and supports the expressive formulation of specifications as Python precondition and postcondition functions.
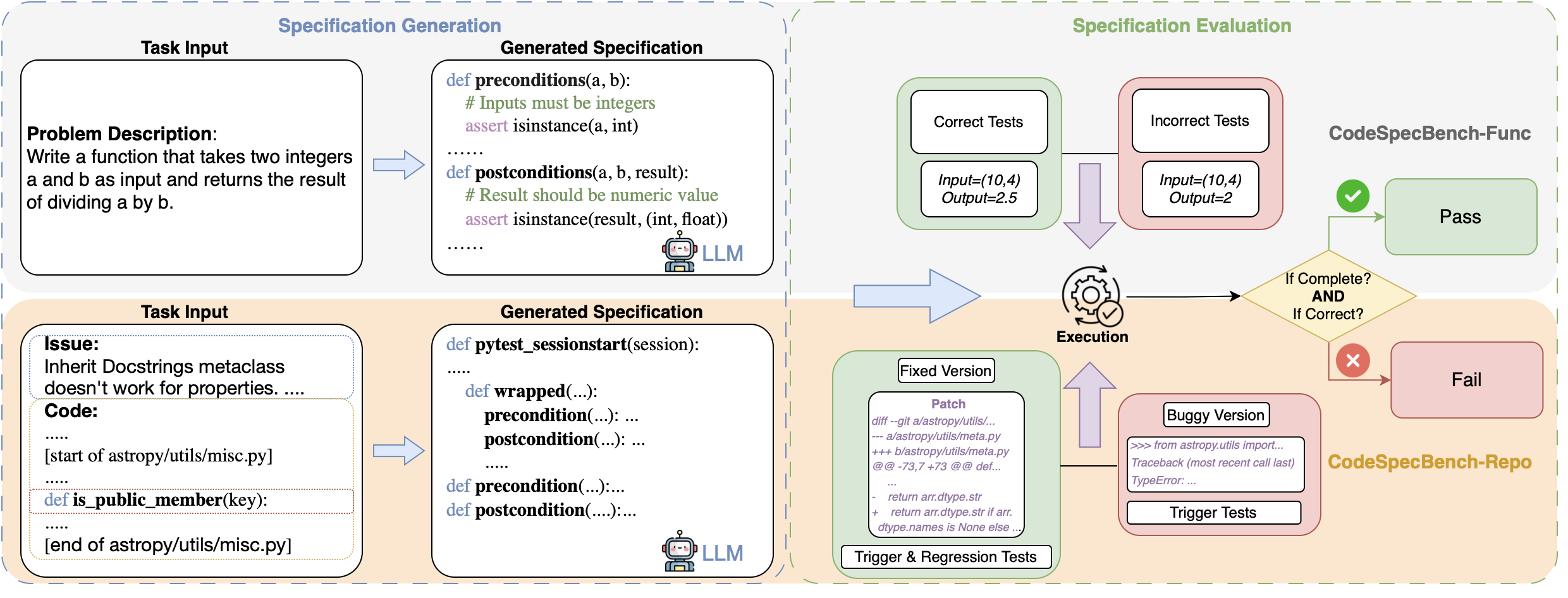
Figure 1: The CodeSpecBench pipeline enables generation and execution-based evaluation of behavioral specifications at both function (top) and repository (bottom) levels, testing correctness and completeness under realistic conditions.
Benchmark Design and Methodology
Specification Representation
Each specification must consist of:
- Preconditions: Executable Python assertions describing input validity and admissible program states.
- Postconditions: Executable Python assertions evaluating properties that must hold for outputs and resulting states post execution.
At the function-level (CodeSpecBench-Func), generation is conditioned solely on the natural language description of the problem, resulting in self-contained specifications. For the repository-level (CodeSpecBench-Repo), LLMs receive both a natural language issue and relevant code context spanning multiple files. This differentiation is crucial, as function-level problems test context-free behavioral reasoning, while repository-level issues require stateful, cross-module semantic modeling.
Test Suite Construction
A core design of CodeSpecBench is its generation of high-coverage validation suites. For function-level tasks, multiple strong LLMs generate a large set of both correct and adversarial test cases, which are subsequently validated and filtered using an external online judge (OJ) to guarantee input/output fidelity and diversity.

Figure 2: The process for constructing CodeSpecBench-Func test cases leverages multiple LLMs and OJ-based validation to produce diverse valid and invalid test suites for robust evaluation.
For repository-level tasks, the benchmark builds upon the SWE-bench Verified dataset, augmented with additional adversarial and regression test cases to counter known test coverage inadequacies. The injection of generated specifications leverages dynamic instrumentation (via conftest.py or analogous wrappers) to enforce precondition/postcondition checks around the relevant target functions during real-world test execution.
Evaluation Metrics
Three primary quantitative axes are established:
- Correctness: Does the specification accept all intended valid behaviors in the test suite?
- Completeness: Does it reject all known invalid/adversarial behaviors?
- Pass rate: The percentage of specifications meeting both criteria simultaneously (i.e., they are neither under- nor over-approximations).
Fractional credit metrics (fraction of passed test cases) supplement the strict pass/fail paradigm, offering deeper granularity in settings where partial behavioral capture may still reflect meaningful progress.
Experimental Results
Overview
A total of 15 state-of-the-art LLMs (ranging from compact open-weight to large proprietary models such as Claude-4.5-Sonnet and GPT-5) are systematically evaluated. The main findings among the models tested are as follows:
- Function-level (CodeSpecBench-Func): The leading models achieve only moderate performance. For example, GPT-5-mini reaches up to 47.0% strict pass rate, while strong open-weight models (GPT-OSS-120B) plateau near 42.5%. The gap between correctness and completeness is consistently large across models, with models tending to be overly permissive, i.e., most pass rates are much closer to completeness than correctness, signifying a reluctance to reject invalid behaviors.
- Repository-level (CodeSpecBench-Repo): Performance deteriorates dramatically. Even the top-performing closed-weight system (Claude-4.5-Sonnet) achieves only 20.2% pass rate; the best open-weight result (DeepSeek-V3.2) remains below 7%. Here, the dominant failure mode shifts towards overly restrictive specifications—models excessively reject valid behaviors, as evidenced by completeness rates consistently exceeding correctness.
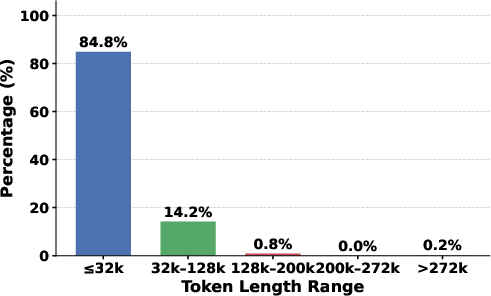
Figure 3: Distribution of prompt token lengths for CodeSpecBench-Repo, illustrating that most contexts fit within 32k-128k windows, but ultra-long contexts pose a significant challenge for models with smaller context lengths.
Error Taxonomy
A fine-grained analysis identifies the principal error clusters:
- Type/Range Violations: Incorrect specification of input domains is the most frequent failure at the function level (comprising up to 54% of all failures), with models misunderstanding or mis-expressing value constraints and type requirements.
- Dependency Resolution and Over-restrictiveness: At the repository level, failures are dominated by an inability to resolve cross-module dependencies, overfitting to implementation details, and over-restrictive postconditions that block valid outputs.
Specification vs. Solution Generation
A bold and empirically substantiated claim: executable behavioral specification generation is substantially harder than plain code generation. For all tested LLMs, performance on generating specifications trails code solution accuracy by a wide margin (often by over 60% absolute). This demonstrates the disconnect between surface-level pattern matching in code and deeper modeling of semantic intent.
Specification Utility for Code Verification
Generated specifications are also useful as semantic oracles for code candidate reranking. Empirically, incorporating them for reranking in code generation pipelines yields non-negligible improvements in pass@k metrics—demonstrating that, even when incomplete, such specifications encode informative behavioral constraints.
Practical and Theoretical Implications
Practically, CodeSpecBench exposes persistent limitations in how LLMs abstract behavioral intent from natural language, particularly when challenged with global or cross-context semantic requirements. This signals that LLMs—despite improvements in code synthesis—are not yet robust semantic reasoners or verifiers, and that pre/postcondition extraction remains an unsolved task, especially in realistic, stateful software systems.
Theoretically, the results call into question the use of raw code generation as a proxy metric for 'understanding' in LLM evaluation. Robust specification benchmarks, particularly those that disassociate code implementation from specification extraction, reveal critical weaknesses in compositional reasoning, input domain modeling, and the avoidance of overfitting to specific implementations.
Specific avenues for future work include:
- Architectures or training regimes targeting compositional symbolic reasoning and multi-granularity abstraction alignment.
- Enhanced prompting or system instructions to encourage principled input domain modeling.
- Scaling dataset construction to cover multi-language or cross-API specifications.
- Combining execution-based analysis with formal verification or symbolic checking for stronger guarantees.
Conclusion
CodeSpecBench establishes a rigorous execution-based framework for evaluating whether LLMs can generate executable behavioral specifications that reflect true understanding of program semantics. The results unambiguously show that current models, including top-tier proprietary LLMs, struggle with this task—especially at realistic repository-level granularity. These findings reinforce the need for benchmarks and modeling approaches that move beyond code synthesis to semantic fidelity and formal specification extraction. CodeSpecBench will undoubtedly serve as a cornerstone for future progress in this domain.

