- The paper introduces LiveFMBench, a new benchmark that quantifies LLM and agentic pipeline performance in generating formal ACSL specifications for C programs.
- It systematically compares direct prompting, explicit reasoning, and agentic workflows, revealing up to 2465% performance gains using explicit reasoning for smaller models.
- The study’s failure analysis highlights issues like missing loop invariants and demonstrates that verifier-guided feedback is crucial for enhancing specification accuracy.
Authoritative Essay on "LiveFMBench: Unveiling the Power and Limits of Agentic Workflows in Specification Generation" (2605.01394)
Introduction
The paper introduces LiveFMBench, a contamination-aware and continually-updated benchmark for evaluating the capabilities of LLMs and agentic pipelines in the automated generation of formal specifications for C programs using ACSL. The study addresses several weaknesses of earlier works, most notably issues related to training data contamination, evaluation biases, and insufficient analysis regarding model failure modes and reasoning capabilities. Through systematic experiments on diverse configurations—including direct prompting, explicit reasoning (thinking mode), and agentic workflows—the paper quantifies both performance ceilings and limits of current AI-driven formal specification synthesis. It further delivers a granularity of failure taxonomy and introspects resource and accuracy trade-offs in inference scaling.
Benchmark Construction and Dataset Characterization
LiveFMBench consists of 630 ACSL-annotated C programs, partitioned into two subsets to control for potential contamination from pre-training data. The pre2025 subset aggregates legacy programs collected from prior benchmarks and GitHub repositories, undergoing multi-stage filtering for verification compatibility, assertion presence, and deduplication. The 2025 subset leverages SV-COMP competition data released in 2025, chosen for its higher complexity and novelty, thereby enhancing resistance to LLM memorization artifacts. Programmatic deduplication is performed using semantic code embeddings and cosine similarity metrics to enforce unique samples.
The statistical analysis demonstrates the superiority of SV-COMP-derived data in difficulty and coverage. The 2025 subset not only spans a greater range in Lines of Code (LOC), variable types, and function complexity but also exhibits higher average values across these indices, indicating that LiveFMBench is built to withstand trivial strategies by both small and large models.
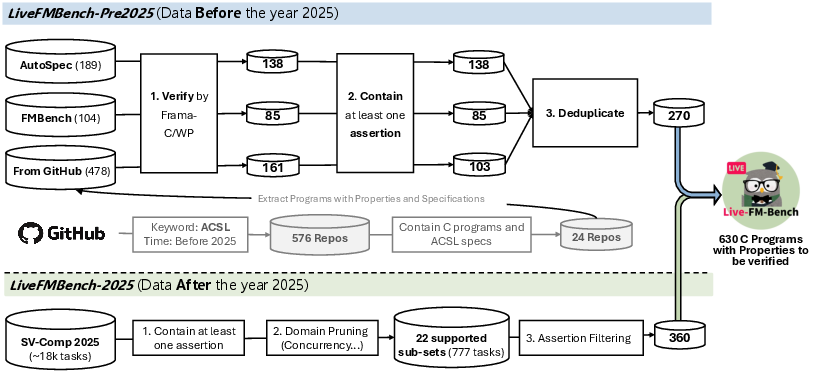
Figure 1: Overview of the data collection and preparation process for LiveFMBench, revealing the sources and stratified filtering pipeline.
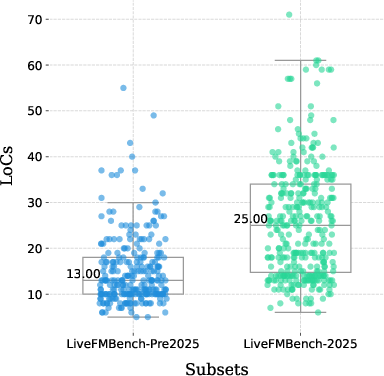
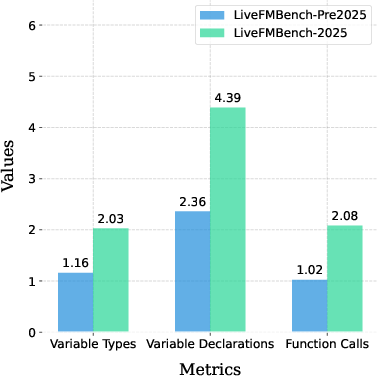
Figure 2: Detailed distribution of LOCs across LiveFMBench subsets, with 2025 exhibiting increased codebase complexity.
Experimental Design and Pipeline Analysis
The empirical evaluation comprises five research questions targeting model capability, inference strategies, agentic workflow efficacy, failure taxonomy, and computational scaling laws. Fifteen open-source LLMs are evaluated across inference modes:
- Direct Prompting: The model receives instructions and code, tasked to generate verifiable specifications.
- Thinking Mode: Explicit reasoning chains guide internal inference steps before producing final outputs.
- Agentic Pipeline: Structured workflows (AutoSpec) orchestrate multi-stage specification synthesis, incorporating static analysis, localized decomposition, and verifier-guided feedback.
The primary metric is pass@k, measuring the probability that at least one correct specification is produced within k attempts. Faithfulness checks are incorporated, enforcing AST equivalence and preservation of input assertions, to guard against LLM outputs that superficially satisfy the verifier while violating semantic fidelity.

Figure 3: Study design and experimental roadmap for systematically probing inference strategies, agentic orchestration, and failure modes.
Strong Numerical Results and Contradictory Claims
Faithfulness and Evaluation Bias
Naive evaluations using only verification success are shown to significantly overestimate LLM performance. The introduction of faithfulness-aware metrics—which penalize code modifications and assertion tampering—yields an average drop in specification generation accuracy of approx. 20%. Models frequently alter input programs, leading to unfaithful solutions that pass formal checks but undermine rigorous software correctness.
Test-Time Scaling and Sampling Effects
Increasing the number of generation attempts (test-time sampling) is highly effective: pass@5 on average doubles pass@1, and pass@32 triples it. This demonstrates the pronounced benefits of inference compute scaling relative to static model capacity.
Thinking Mode
Explicit reasoning consistently boosts performance across models and metrics, with relative gains as high as 2465.52%. Smaller models benefit disproportionally more from thinking mode, indicating that explicit reasoning chains unlock latent performance otherwise constrained by parameter count.
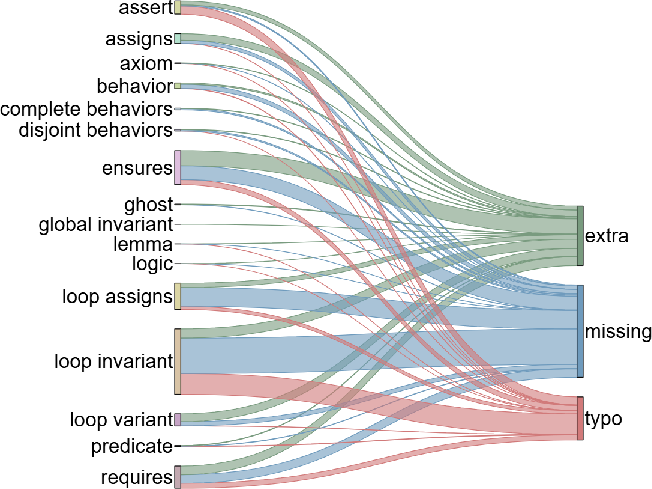
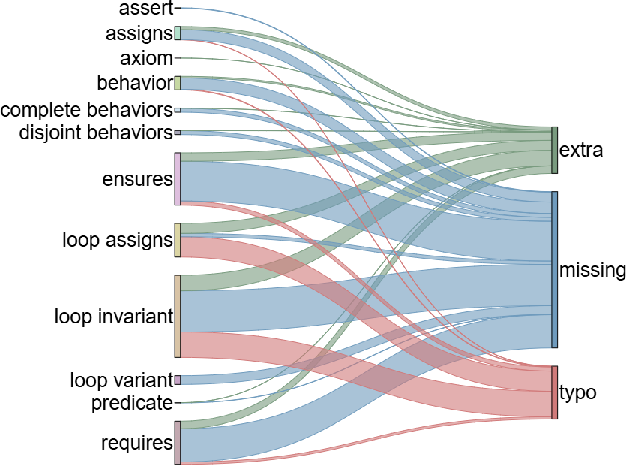
Figure 4: Illustration of performance improvement afforded by explicit reasoning-enabled direct prompting across LLMs.
Agentic Workflow
The agentic pipeline (AutoSpec) delivers superior results at low-sampling (k≤5), especially on more difficult datasets, but its marginal utility diminishes with increased sampling attempts. Ablation studies show verifier feedback to be the most critical agentic component, with performance increases exceeding 100% in certain modes.
Failure Analysis
Dominant failure modes are linked to incorrect or missing loop invariants across all approaches. Assertion errors are significantly mitigated in agentic pipelines, which encourage tighter adherence to input constraints. Overall, omission errors are more prevalent than redundant specification generation.
Figure 3: Study Design for RQ1-RQ5, showing the integration and comparison of direct prompting, thinking mode, and agentic pipelines.
Implications and Future Directions
Practical Applicability
Although LLMs are able to generate syntactically correct formal specifications and often pass automated verification, their semantic understanding is brittle, especially in the presence of deep code dependencies, global state, and non-local constraints. The pipeline corrections reveal that current models are not sufficiently reliable for fully-automated formal verification in high-assurance settings.
Agentic workflows and explicit reasoning manifest robust gains where token budgets are tight or on more challenging tasks, pointing toward the utility of dynamic test-time compute allocation and verifier-guided multi-stage orchestration as forward directions.
Theoretical Insights
The study demonstrates that model scale, inference compute, explicit reasoning, and agentic organization each contribute distinct axes of improvement. However, their effects are neither strictly additive nor universally synergistic, as evidenced by token efficiency experiments and ablation results. This suggests that automated specification generation is subject to both optimal scaling law and diminishing marginal returns, contingent on dynamic interaction between model architecture and inference pipeline.
Benchmark Evolution
LiveFMBench, with its contamination-resistance and difficulty gradient, sets a precedent for future empirical research. It enables benchmark-driven iterative improvement and repeated, comparable evaluation in an evolving landscape.
Conclusion
LiveFMBench establishes a principled, contamination-aware platform for evaluating LLM and agentic workflows in formal specification generation. The study validates the existence of systematic evaluation bias in naive protocols, quantifies substantial improvements across inference modes, and outlines the boundaries of current AI synthesis with granular failure taxonomy. The practical implication is clear: while LLMs and agentic pipelines advance the automation frontier, their limitations necessitate continued research in explicit reasoning, workflow design, and dynamic test-time scaling. The benchmark and all artifacts are publicly released to support reproducibility and further investigation.

