- The paper introduces VeriSpecGen, which systematically synthesizes formal specifications from natural language by decomposing requirements and refining them through targeted error localization.
- It employs atomic requirement decomposition and traceable test generation, integrating LLM prompts with Lean theorem proving to achieve significant performance gains.
- Empirical results show up to 86.6% Pass@1 and emphasize that process-level supervision is crucial for robust specification synthesis and improved code generation.
Introduction and Motivation
The formal verification of program correctness fundamentally depends on the availability of precise formal specifications. The absence of specifications in real-world codebases, coupled with the expertise required for authoring them, creates a critical bottleneck for deploying end-to-end verification pipelines, especially in settings where code is generated from natural language by LLMs. LLMs frequently introduce functional and security-critical errors, and attempts to retrofit them with formal verification are limited by the quality of the specifications. Existing specification synthesis methods either depend heavily on implementation-based analysis, which may reinforce bugs or misalignments, or use weak and coarse refinement heuristics that do not localize failures.
The paper "Intent-aligned Formal Specification Synthesis via Traceable Refinement" (2604.10392) proposes a systematic and scalable agentic framework, VeriSpecGen, that enables accurate, intent-aligned formal specification synthesis from natural language. The core design leverages atomic requirement decomposition, requirement-targeted test generation with explicit traceability to requirements, and an iterative refinement loop with localized repairs, all orchestrated by LLMs and automated theorem proving in Lean. This paradigm shift prioritizes natural language intent as the ground-truth interface for validation, rather than implementation artifacts.
VeriSpecGen Architecture and Workflow
VeriSpecGen decomposes the NL requirement into atomic requirements using an LLM. Each atomic requirement is defined to specify a distinct, testable behavioral property (e.g., a precondition, a specific postcondition clause, or a boundary constraint). This granularity is critical for accurate attribution of errors and for enabling targeted, minimal repairs.
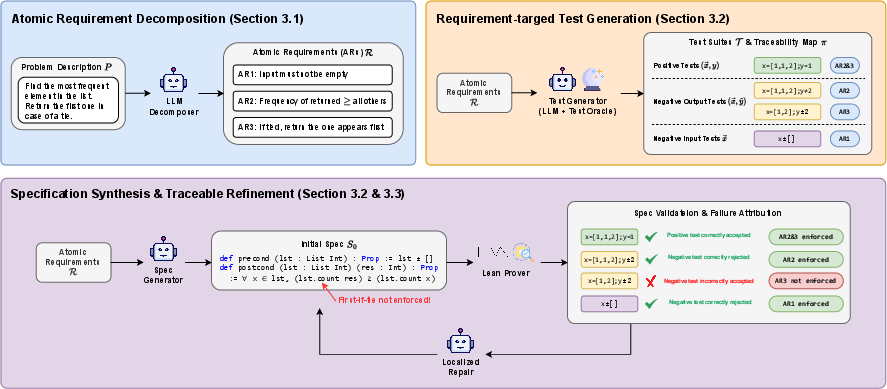
Figure 1: The VeriSpecGen traceable refinement workflow integrates requirement decomposition, targeted test generation, and Lean-based validation and repair in an iterative process.
Tests are then generated for each requirement: positive tests (valid input/output pairs), negative-in tests (inputs violating preconditions), and negative-output tests (wrong outputs for valid inputs). Each test is explicitly mapped to its validating requirements, forming a fine-grained traceability map. Reference implementations, only used as black-box oracles for test labeling, ensure validation focuses on behavioral surface alignment with the NL intent rather than code artifact artifacts.
Specification synthesis proceeds via LLM translation of atomic requirements into a structured Lean 4 contract. The Lean prover is then used to attempt validation of each test with the current specification. Failures are attributed back through the traceability map, identifying specific violated requirements. The repair phase is requirement-localized: only the implicated clause(s) are revised using targeted, context-aware LLM prompting, leading to efficient convergence and minimizing the risk of regressions in unrelated requirements.
Adversarial test generation further probes under-constrained or brittle specifications by mining additional, edge-case tests at each refinement stage. This stage significantly increases synthesis robustness over previous works that rely only on static checks or non-adversarial tests.
Empirical Results: Specification Synthesis and Data Generation
VeriSpecGen achieves state-of-the-art performance on the Verina SpecGen benchmark, obtaining 86.6% Pass@1 with Claude Opus 4.5, and improving over the strongest baseline by 27.6 points absolute (46.8% relative improvement). On open-weight models, relative gains reach up to 86.7%. The ablation study demonstrates the critical importance of requirement decomposition—removing this component produces the largest performance drop. Grounded validation and requirement-level attribution are essential for scalable improvements: approaches that only iterate with global or LLM-judged feedback underperform, especially for smaller models.
VeriSpecGen also introduces a methodology for large-scale training data construction. 343,827 supervision examples, spanning the full refinement trajectory—including requirement decomposition, mapping, validation traces, and repair feedback—are distilled from 6,842 solved problems. Training on these "process-level supervision" trajectories yields 62–106% relative improvements in specification synthesis and 54–72% in code generation across open-weight models.
Training Data Dynamics and Robustness
The analysis of training approaches demonstrates that naively training with end-to-end NL/specification pairs is ineffective and even detrimental in some settings. Multi-task, process-level supervision is necessary for robust generalization. "SFT No-Test", which excludes test construction tasks and focuses on requirement decomposition and repair traces, produces the best specification synthesis results.
Temperature sweeps and training epoch studies reinforce that deterministic decoding is optimal for specification synthesis, and that performance saturates after 3–5 epochs of exposure to trajectory supervision.
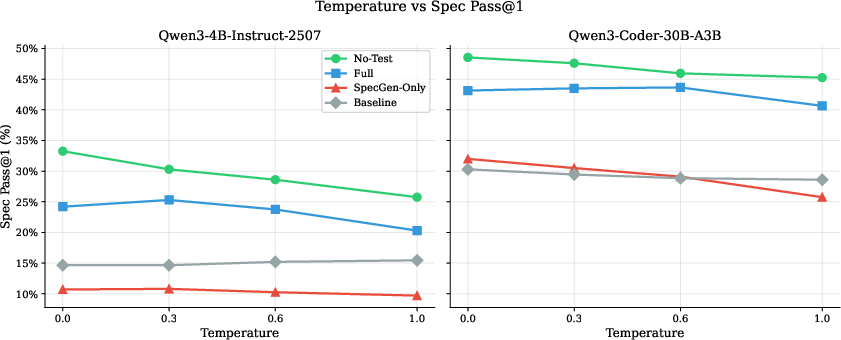
Figure 2: Lower sampling temperature consistently achieves stronger specification synthesis performance, highlighting limited gains from randomness in codegen for this task.
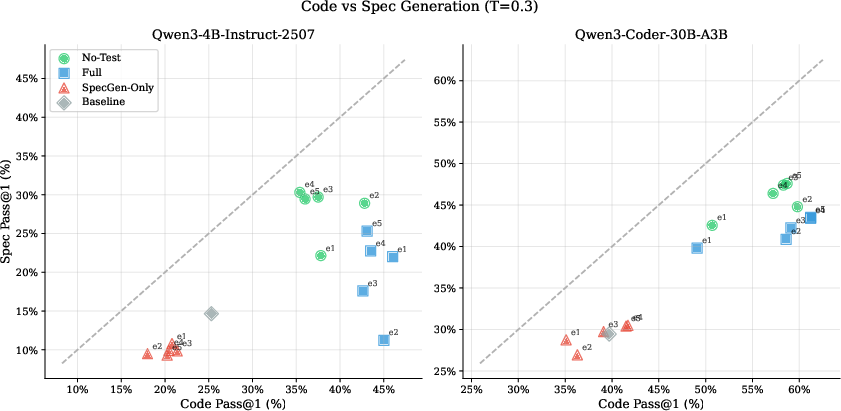
Figure 3: SFT No-Test maximizes specification performance without sacrificing code synthesis, whereas SFT Spec-Only shows simultaneous performance degradation on both axes.
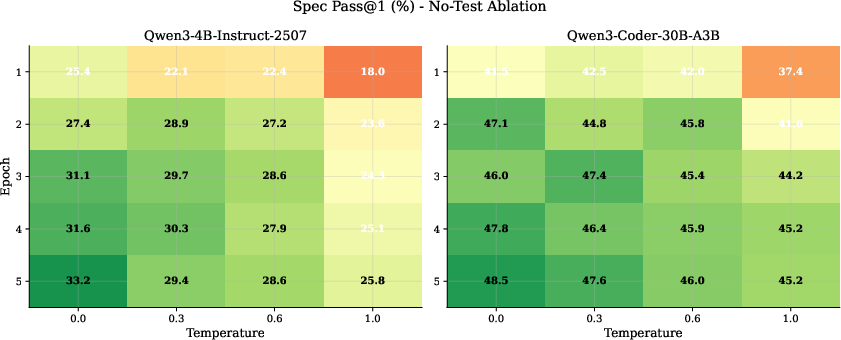
Figure 4: Specification synthesis accuracy grows with training epochs, plateauing after the fourth epoch, with large improvements over the corresponding base model.
Theoretical and Practical Implications
The introduction of traceable requirement attribution fundamentally alters the data efficiency and repair dynamics of specification synthesis. The explicit decomposition and mapping pipeline sharply contrasts with prior LLM-based refinement mechanisms that rely on unverifiable or global signals (e.g., "proof failed" or self-consistency). Practically, the approach decouples intent alignment from code artifacts, which is indispensable as LLMs begin to synthesize code in untrodden domains for which no reference implementation exists, or where implementations may be themselves buggy.
Trajectory-level supervision connects the informal intent to the formal artifact, providing a scalable template for controllable, process-driven, and interpretable synthesis in general neuro-symbolic workflows.
The exported methodology is not only domain-agnostic (Lean 4 is used here, but the logic generalizes) but provides a blueprint for new benchmarks, evaluation metrics with adversarial robustness, and foundation models for specification-centric code generation. Transfer results also demonstrate that fine-tuning on such data imparts global benefits for math reasoning and code generation.
Limitations and Future Work
While VeriSpecGen pushes the limits of scalable, intent-aligned specification synthesis, the requirement for black-box oracles for test labeling presupposes either a trusted implementation or reliable LLM-based test output generation. Improved oracle methods, stronger automated proof engines, and human-in-the-loop augmentation remain open avenues. The systematic integration with proof-producing and counterexample-producing methods (e.g., SMT-based) in domains with more complex logics would further expand applicability. Extension to autoformalization and specification synthesis in more expressive logical frameworks (Dafny, Coq, etc.) is a natural next step.
Conclusion
VeriSpecGen establishes a new rigorous framework for intent-aligned formal specification synthesis from natural language, integrating LLMs and formal methods through traceable, requirement-grounded refinement and leveraging process-level supervision at scale. The resulting gains in synthesis accuracy, sample efficiency, and out-of-domain transfer strongly suggest that fine-grained, transparent, and interpretable refinement will be a fundamental building block in the next generation of neuro-symbolic program synthesis and verification pipelines (2604.10392).