- The paper presents a two-stage self-supervised framework on 6.6M brain MRI slices to generate unified, anatomy-aware representations for various clinical tasks.
- It demonstrates significant improvements in tumor segmentation, disease classification, and survival analysis, especially under low supervision conditions.
- The approach efficiently adapts to different tasks by freezing over 99% of model parameters and training only lightweight task-specific adapters.
BrainDINO: A Brain MRI Foundation Model for Generalizable Clinical Representation Learning
Introduction and Motivation
The field of brain MRI analysis encompasses a diverse set of clinical tasks, including segmentation, disease classification, biomarker regression, survival analysis, and molecular prediction. Despite the success of deep learning, most approaches are highly specialized, requiring distinct models and substantial labeled datasets for each endpoint. The heterogeneity in acquisition, population, and disease further complicates the search for domain-generalizable representations. Self-supervised learning (SSL) has shown promise for learning robust visual features in natural images, but transferability and data efficiency remain limited for brain MRI, particularly under label scarcity and distribution shifts.
BrainDINO addresses this gap by establishing a large-scale, slice-wise self-supervised foundation model for brain MRI, pretrained on 6.6 million unlabeled slices across 20 heterogeneous datasets. The authors leverage a DINOv3-style self-distillation framework with a two-stage pretraining scheme, aiming to create a unified representation that is stable, anatomy-aware, pathology-sensitive, and supports diverse clinical tasks using only lightweight adapters on a frozen backbone.
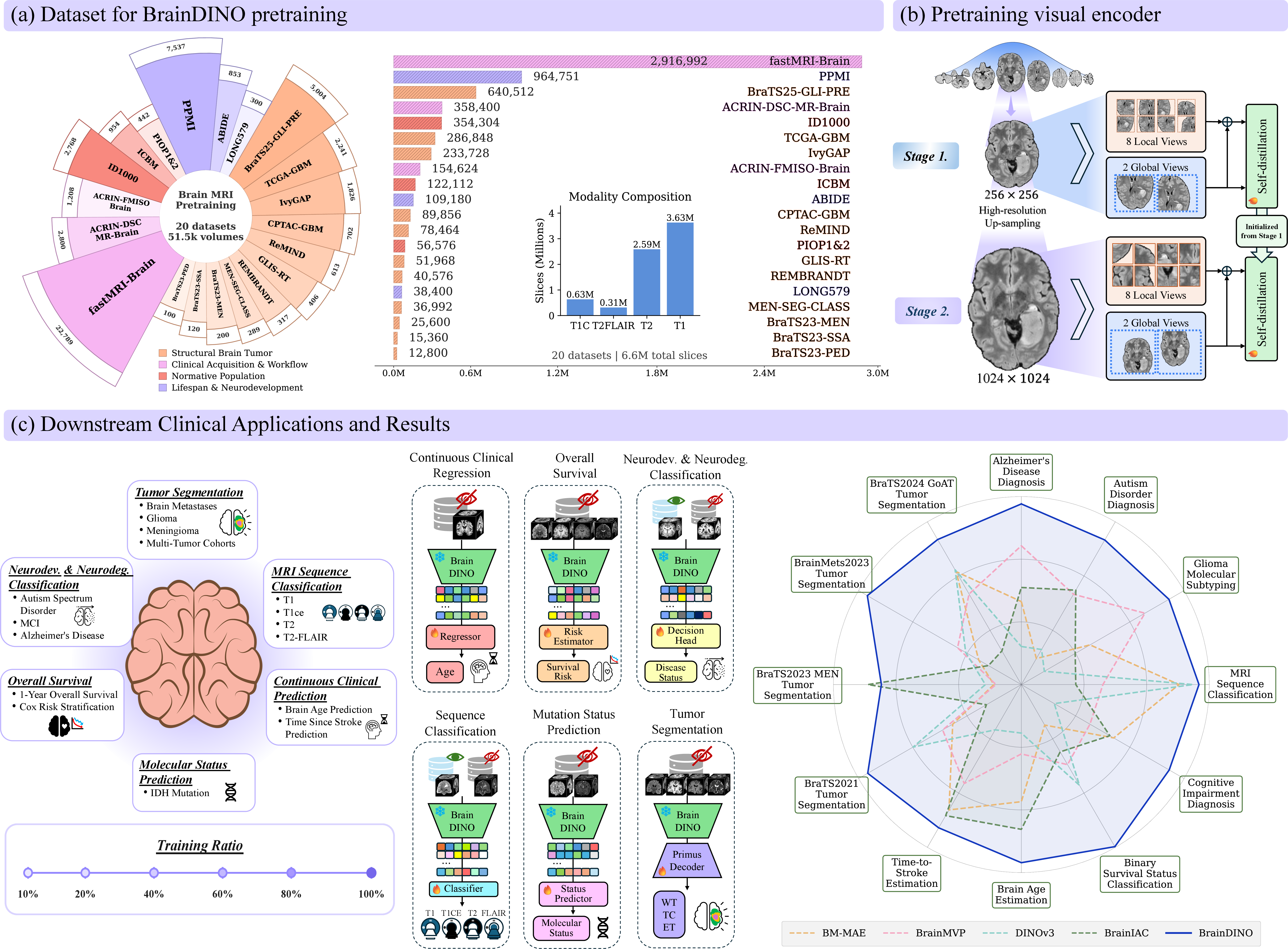
Figure 1: Overview of BrainDINO's large-scale heterogeneous pretraining corpus, two-stage DINOv3-based self-supervised learning, and evaluation pipeline utilizing a shared frozen encoder and task-specific lightweight heads across multiple clinical task families.
Methodological Overview
Pretraining Architecture and Corpus
BrainDINO utilizes a Vision Transformer (ViT-B/16) backbone with rotary positional embeddings, trained under a two-stage self-supervised pipeline. The training corpus comprises 6.6 million 2D axial slices, uniformly and adaptively sampled from collections covering normative, developmental, oncological, and clinical populations, with comprehensive preprocessing and normalization to minimize inter-dataset biases. Slice extraction prioritizes central brain regions and excludes redundancy, maximizing anatomical diversity.
The self-supervised framework consists of:
- Stage 1: Standard-resolution slice-wise pretraining using multi-crop augmentation and DINOv3’s teacher-student architecture. Losses enforce global semantic alignment via CLS-token distillation loss and local consistency via masked patch-token prediction (iBOT-style), thereby jointly capturing global and fine-grained anatomical features.
- Stage 2: High-resolution upsampling (up to 1024×1024), further refining the spatial precision of representations with tailored augmentations and multi-resolution cropping.
No task-specific or volumetric information is provided at pretraining; the model relies entirely on anatomical variation in the unlabeled data for invariance discovery. Teacher parameters are tracked as an EMA of the student, following DINOv3 best practices.
Downstream Evaluation Protocol
To rigorously assess generality, the study systematically evaluates BrainDINO across a wide spectrum of clinical tasks:
- Tumor segmentation (BraTS2021, BraTS2023-METS, BraTS2023-MEN, BraTS2024-GoAT)
- Neurodevelopmental and neurodegenerative classification (ABIDE, ADNI, OASIS)
- Biomarker and trajectory regression (brain age [IXI+LONG579+Pixar], post-stroke temporal prediction [ATLAS])
- Survival analysis (overall survival classification and time-to-event prediction, UPENN-GBM)
- Molecular status prediction (IDH mutation, UCSF-PDGM)
- MRI sequence classification
Lightweight task-specific heads are trained atop a frozen BrainDINO encoder. Data efficiency and robustness are evaluated across variable labeled-data regimes (10–100%) and under clinically relevant test-time perturbations (contrast shifts, Gibbs artifacts, bias fields). Models are compared against representative baselines: natural-image DINOv3, and three MRI-specific SSL models (BrainMVP, BrainIAC, BM-MAE).
Empirical Results and Representation Analysis
Tumor Segmentation
Across all segmentation benchmarks and data regimes, BrainDINO consistently outperforms DINOv3 and matches or exceeds MRI-specific baselines in Dice accuracy, with the strongest margins under severe label scarcity conditions. On the challenging BraTS2023-METS, BrainDINO improved low-supervision Dice by 0.13–0.17 over all baselines for key tumor subregions. Performance gains remained significant even as supervision increased, demonstrating both data efficiency and high capacity for boundary-sensitive representation.
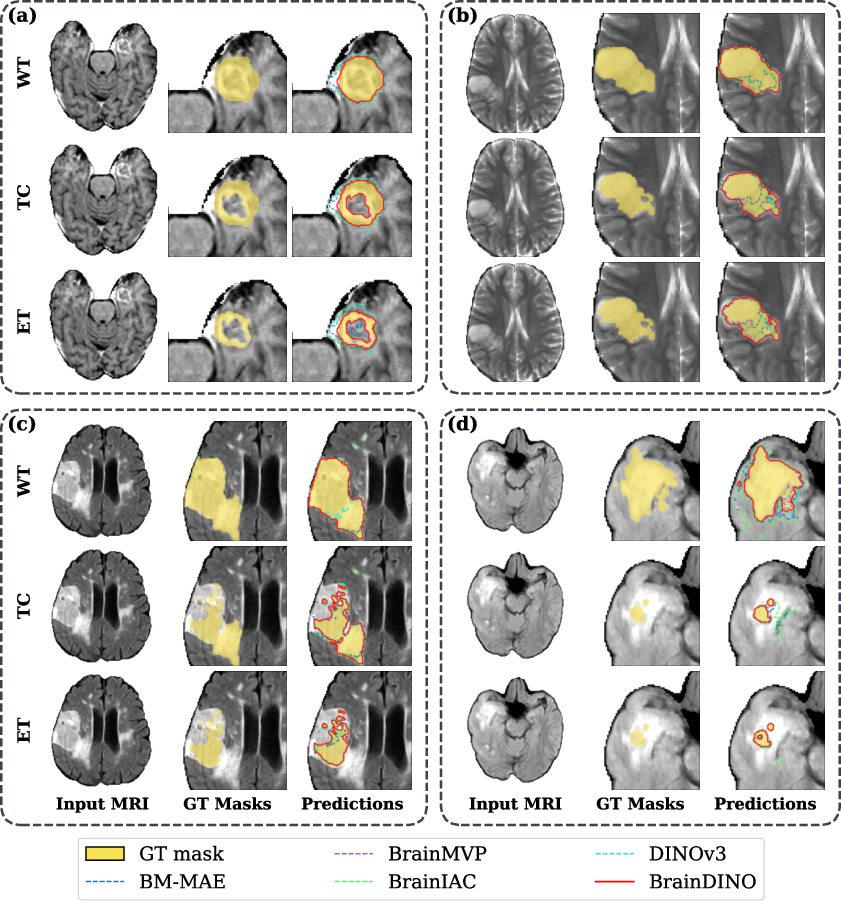
Figure 2: Cross-dataset tumor segmentation comparison (BraTS-METS 2023, BraTS 2021) under full supervision; BrainDINO demonstrates improved spatial precision and boundary conformity versus baseline backbones.
Clinical Classification and Regression
For neurodegenerative staging (ADNI), BrainDINO exhibited the highest macro-AUC (0.954 at 100% supervision), outperforming BrainMVP by +8 AUC points and showing statistically significant improvement across all data regimes. In ABIDE (ASD detection) and OASIS (dementia), moderate-to-strong advantages were recorded in both low-data and fully-supervised settings.
Brain age estimation yielded the lowest MAE (5.54 years at 100% supervision). Under extreme label limitation, BrainDINO surpassed all baselines by 5–8 years, with gains most pronounced in extreme age groups—supporting the claim of anatomically meaningful invariance learning. In post-stroke temporal prediction, performance gains over natural-image pretraining persisted across all supervision levels.
Survival Modeling and Molecular Prediction
For survival stratification (UPENN-GBM), BrainDINO's risk scores achieved statistically significant Kaplan-Meier separation across all data ratios, while only partial or no significance was observed for competing models.
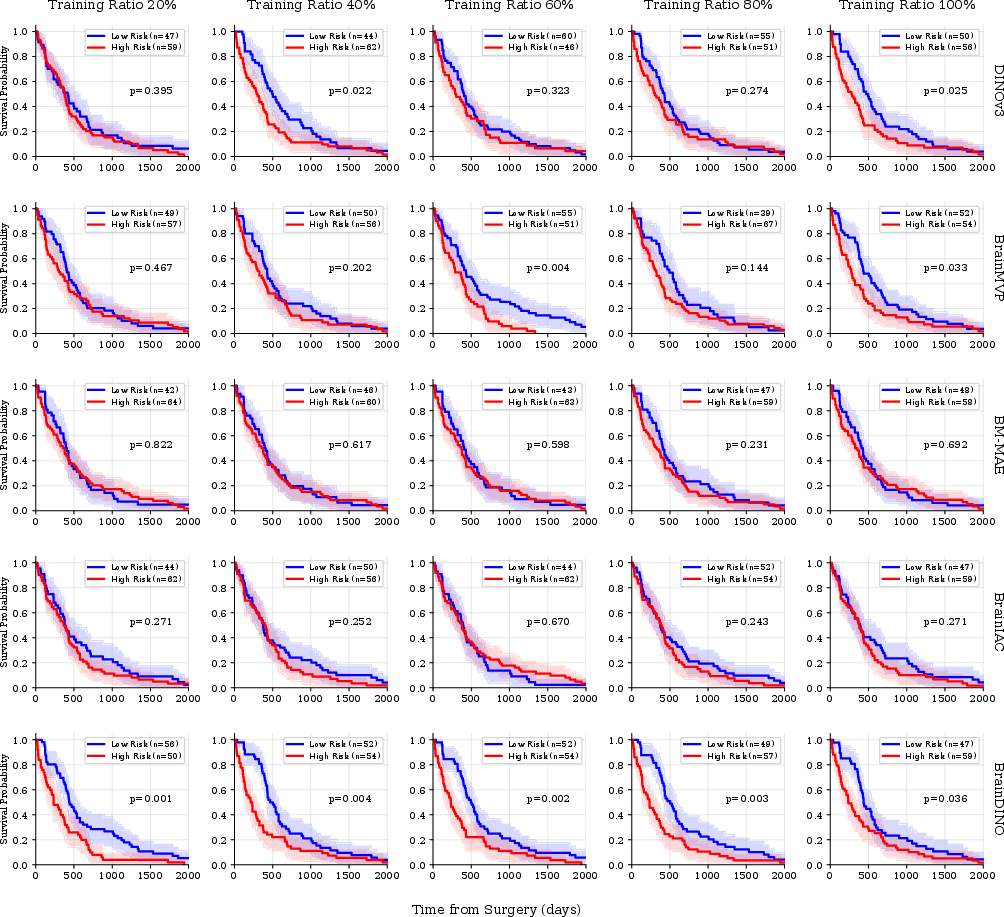
Figure 3: Survival analysis: BrainDINO assigns robust, well-separated risk stratification for glioblastoma patients, with consistent high-/low-risk group divergence across supervision regimes.
IDH mutation detection experiments demonstrated consistently higher AUC for BrainDINO (up to 0.901), with significant gaps to all but BrainMVP, where differences did not reach significance at high supervision. MRI sequence classification was nearly perfect (macro-AUC ≈1.0) across all settings.
Robustness Under Perturbation and Feature Structure
Test-time perturbation analysis indicated that BrainDINO maintains the best absolute performance under intensity, artifact, and bias disturbances, suggesting strong distributional robustness. Absolute degradation was notable for segmentation under Gibbs artifacts, but relative ranking remained stable.
Feature space analysis via frozen kNN classification and reference-point patch-similarity mapping established that BrainDINO’s representation is more spatially selective, anatomically discriminative, and class-separable compared to all baselines—including both MRI-specific and natural-image models.
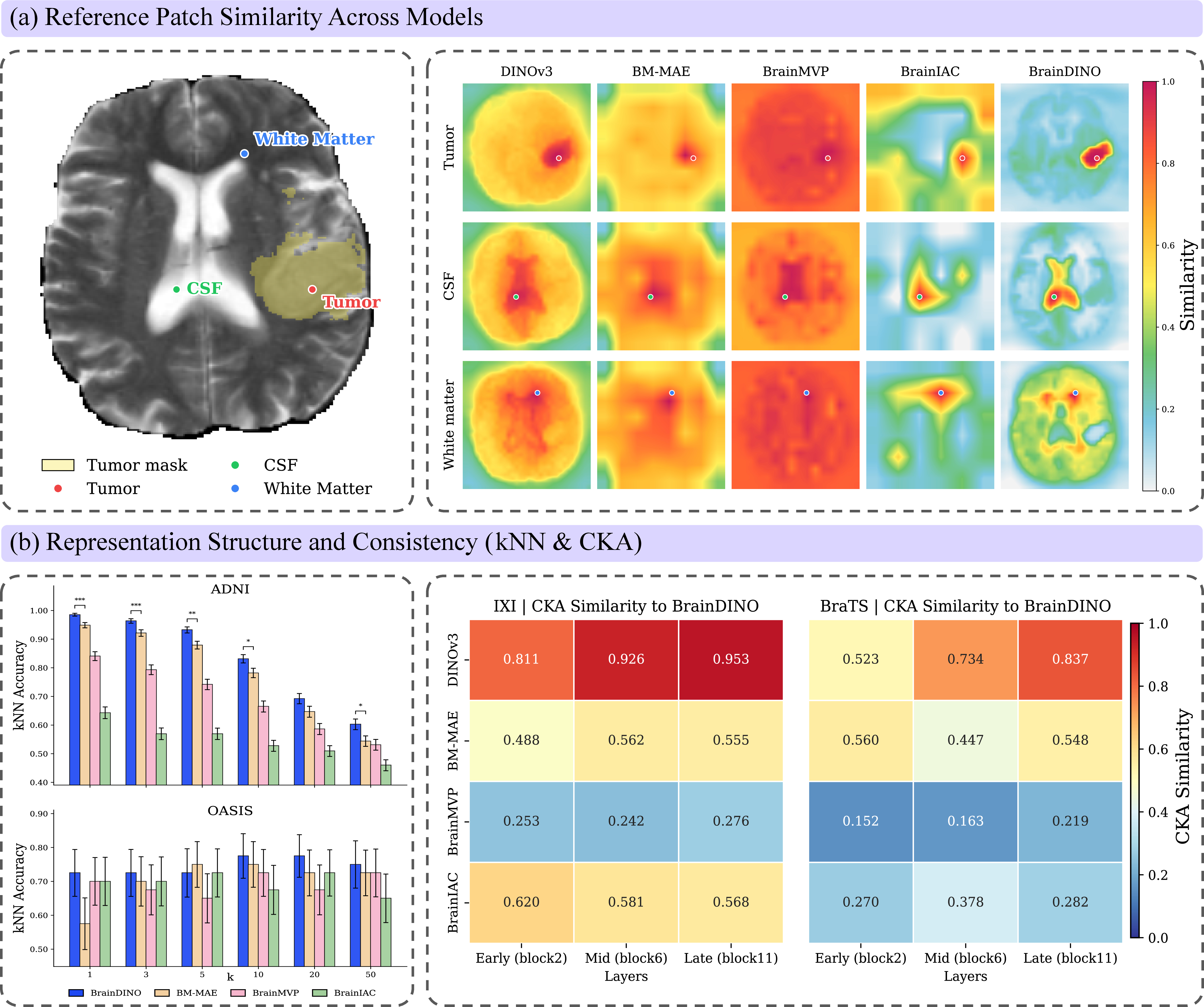
Figure 4: Feature structure analysis: BrainDINO achieves anatomically specific patch similarity and the highest intrinsic class separability on frozen features, with distinctive representational geometry versus other backbones.
Theoretical and Practical Implications
The results demonstrate that large-scale, heterogeneous, slice-wise self-supervised pretraining can yield a domain-specific foundation model for brain MRI with substantial downstream generality. Notably, BrainDINO achieves its strong transfer performance with a highly parameter-efficient protocol: over 99% of model parameters are frozen for most downstream tasks, and even segmentation trains only task-specific adapters and decoders.
Practically, this reduces computational burden for clinical adaptation, increases safety under distribution shifts, and supports rapid re-use across new tasks and institutions. The pronounced data efficiency is particularly salient for rare or small-cohort applications ubiquitous in clinical neuroimaging. The anatomical coherence of BrainDINO’s feature space (as evidenced by patch similarity and CKA) suggests future potential for zero-shot transfer, cross-modal learning, and foundation modeling in other modalities such as fMRI and DTI.
Limitations include the absence of inter-slice volumetric context, which may cap performance in settings where 3D continuity is essential, and the underrepresentation of certain clinical trajectories (e.g., ASD, post-stroke). Further, the reliance on 2D slices precludes exploitation of volume-resolved data, and future work could investigate hybrid 2D/3D or fully volumetric approaches.
Conclusion
BrainDINO establishes that slice-wise self-supervised pretraining on large, heterogeneous brain MRI corpora supports a unified, transferable representation suitable for a wide spectrum of clinical tasks. The approach yields high data and parameter efficiency, robust performance under distribution shift, and anatomical feature organization beneficial for downstream adaptation. These results support the feasibility of anatomy-aware, disease-agnostic foundation models for neuroimaging and motivate investigation into hybrid architectures, multimodal integration, and further scaling.

