- The paper introduces an unrolled MRI reconstruction architecture that replaces conventional convolutional priors with frozen vision transformer-based denoisers.
- The method achieves competitive SSIM/PSNR scores and improved robustness in cross-domain settings versus task-specific models, especially under high acceleration.
- Results demonstrate that natural-domain pretrained models like CLIP and BiomedCLIP effectively mitigate domain shifts in severely undersampled MRI reconstructions.
Evaluation of Natural-Domain Foundation Models as Priors for Accelerated Cardiac MRI Reconstruction
Introduction
The study systematically investigates the viability of leveraging frozen large-scale vision foundation models—specifically, models pretrained on natural images—as priors in the context of accelerated cardiac MRI reconstruction. The central question addressed is whether representations learned from natural images can generalize sufficiently for ill-posed, domain-critical, physics-guided inverse problems typical in medical imaging, and how these models compare against domain-specific alternatives such as BiomedCLIP. The work proposes an unrolled architecture incorporating pretrained encoder-based denoisers, and empirically benchmarks generalization, robustness, and transferability across in-distribution and severe cross-domain scenarios.
Methodology
The MRI reconstruction problem is approached as an inverse problem constrained by acquisition physics and challenged by undersampled k-space measurements. The proposed architecture follows an unrolled optimization paradigm, comprising T cascades, each defined by a data-consistency step in k-space and an image-domain refinement module. The core innovation lies in substituting the conventional task-specific convolutional priors within these cascades with frozen transformer-based foundation models.
The denoiser module integrates intermediate features extracted from the first six layers of the vision transformer encoder (CLIP, DINOv2, or BiomedCLIP) via learnable layer fusion. These features are spatially aligned with hierarchical skip connections and decoded through a lightweight, multi-stage, parameter-efficient convolutional decoder.
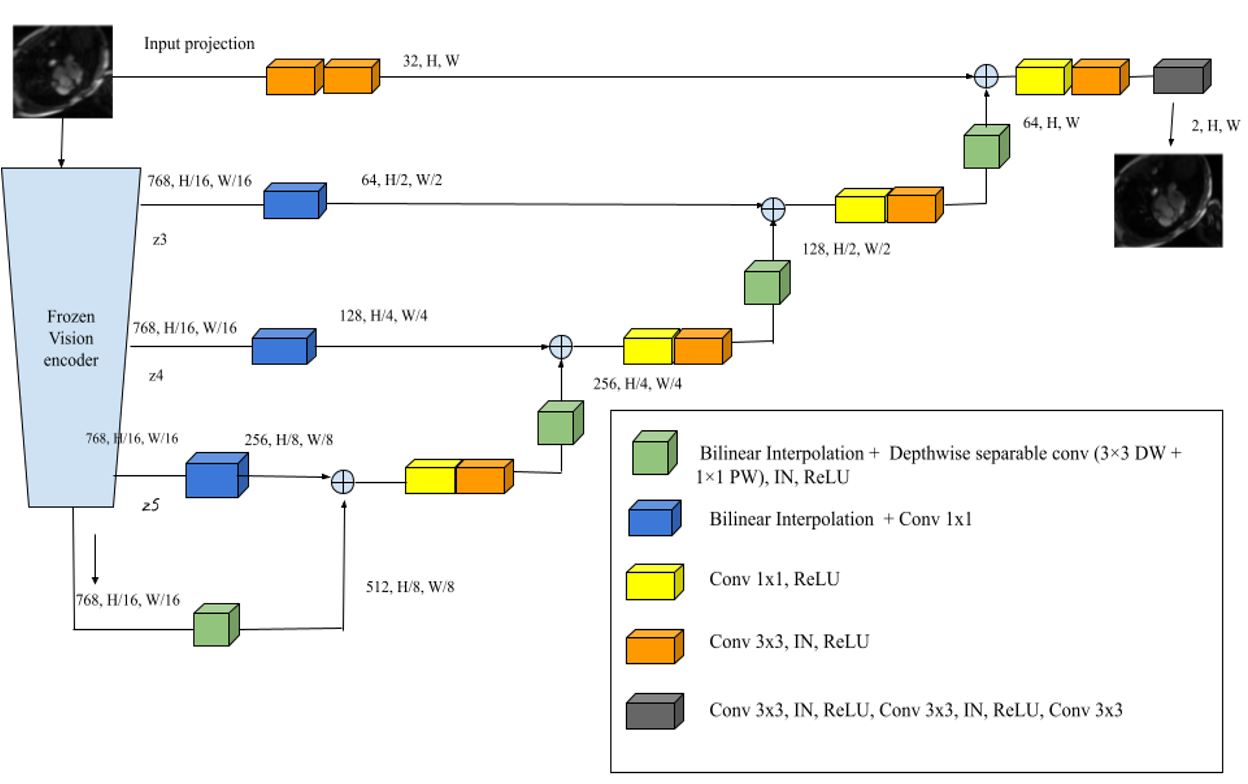
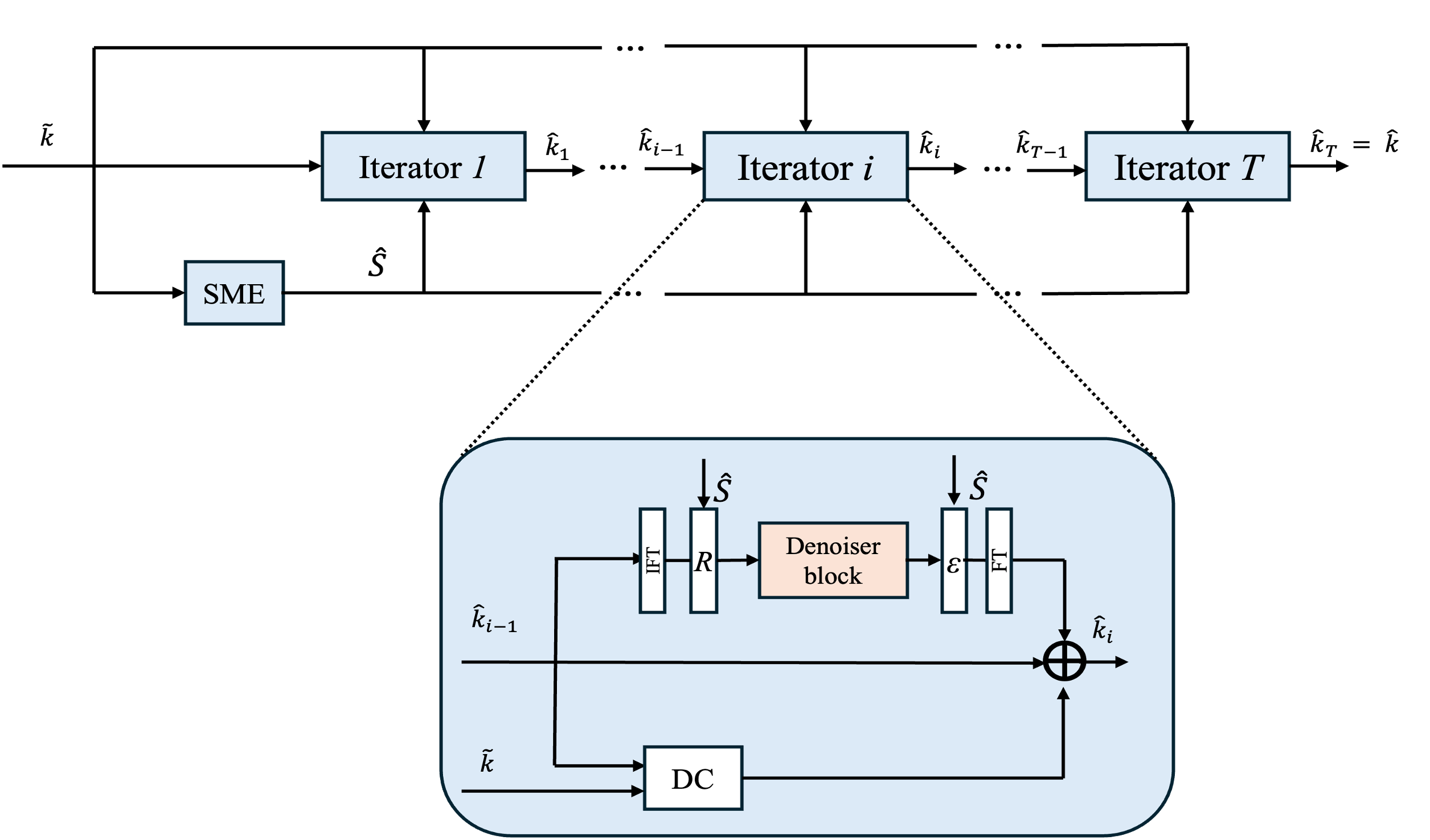
Figure 1: Schematic of the multi-level denoiser integrating multi-scale frozen transformer features, spatial skip connections, and progressive refinement via a hierarchical decoder.
This denoiser is embedded within the iterative unrolled framework, ensuring each cascade retains fidelity to the acquired k-space data while injecting strong, transferable image priors from the frozen encoder. All pretrained encoders are leveraged using a standardized ViT-B backbone, and all model inputs are normalized and resized to match the encoder requirements.
Experimental Design
Comprehensive experiments are conducted on the CMRxRecon cardiac MRI dataset, simulating variable acceleration factors (×4, ×8, ×10), and key metrics (SSIM, PSNR, NMSE) are used to quantify reconstruction fidelity. To rigorously assess robustness, the cross-domain generalization is evaluated by testing models, trained on the cardiac dataset, on anatomically and contrast-wise distinct fastMRI knee and brain datasets, with controlled reductions in center k-space fractions and increased acceleration.
Results
In standard in-distribution settings, the task-specific E2E-VarNet baseline achieves superior reconstruction accuracy across all acceleration regimes. However, foundation-model-based methods, notably CMR-CLIP and CMR-BiomedCLIP, yield competitive SSIM/PSNR scores with surprisingly narrow performance gaps, particularly at moderate acceleration. For instance, at ×4 acceleration, CMR-CLIP achieves SSIM=0.9585 versus E2E-VarNet's $0.9676$.
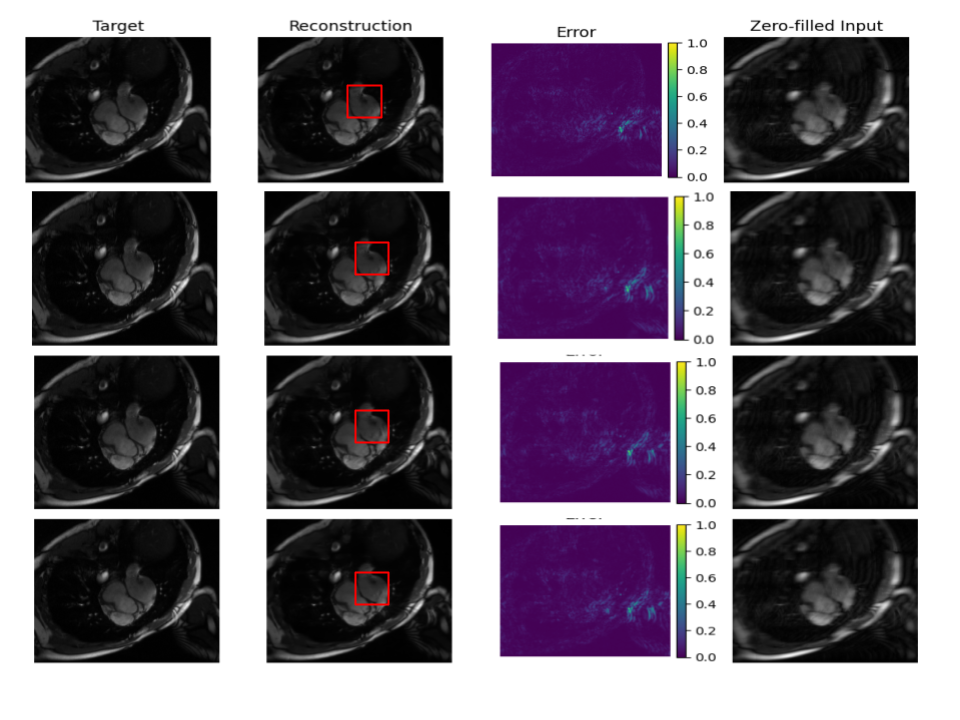
Figure 2: Qualitative reconstruction results at ×8 acceleration comparing target, reconstruction, error map, and zero-filled inputs for E2E-VarNet, CMR-CLIP, CMR-DINOv2, and CMR-BiomedCLIP.
The gap widens as the problem becomes more ill-posed (i.e., higher acceleration factors), with domain-specific BiomedCLIP overtaking natural-domain models at the ×10 regime. Nevertheless, the frozen, natural-image-pretrained models demonstrate robust performance despite zero MRI-specific fine-tuning.
Cross-Domain Generalization
When subjected to strong domain shifts, the qualitative and quantitative trends notably invert. Whereas task-specific models, fully optimized on training-distribution cardiac MRIs, degrade precipitously under cross-domain evaluation on the knee and brain datasets—particularly at high undersampling and low center fraction—foundation-model-based models demonstrate marked robustness and transferability.
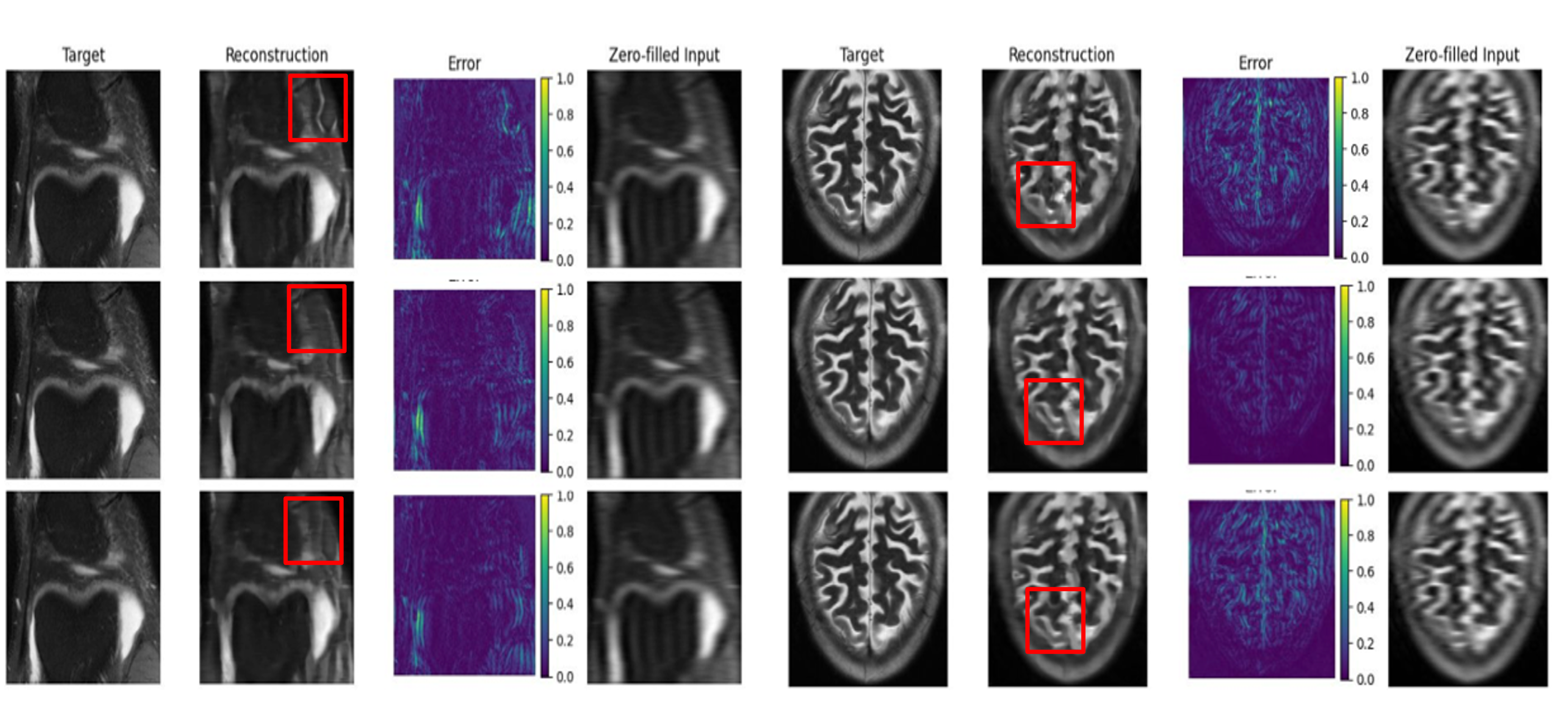
Figure 3: Out-of-distribution results on fastMRI knee and brain (×10 acceleration, center fraction 0.08) highlighting improved structural fidelity of CLIP/BiomedCLIP-based reconstructions over E2E-VarNet.
At ×40 and ×41 acceleration, and under reduced center fractions, both CMR-CLIP and CMR-BiomedCLIP not only close the SSIM gap but often surpass E2E-VarNet. For example, on fastMRI brain (center fraction 0.04, ×42), CMR-BiomedCLIP achieves higher SSIM and lower NMSE than all competitors, highlighting the adaptability of representations learned from large-scale data. Among foundation models, natural-domain CLIP performs best at moderate undersampling, while BiomedCLIP demonstrates clear gains in severely ill-posed regimes, indicating added utility of domain-adaptive representation in challenging settings. DINOv2 consistently underperforms, suggesting that cross-modal alignment and semantic context in pretraining objectives confer meaningful advantages for medical inverse problem transferability.
Implications and Discussion
The empirical evidence establishes that pretrained vision foundation models encode transferrable structural priors that are directly applicable to MRI reconstruction, obviating the need for extensive retraining under realistic domain shifts. These models exhibit a regime-dependent utility: task-driven models dominate when in-distribution and with sufficient data, but foundation models provide essential robustness, mitigating failure under out-of-distribution and high-acceleration conditions. This exposes a practical path toward unified generalizable MRI reconstruction pipelines, particularly critical in clinical scenarios with domain shift, scanner/institution heterogeneity, or limited annotated data.
The modest but consistent incremental improvement from domain-specific pretraining (BiomedCLIP) in the most challenging regimes advocates for hybrid pretraining strategies, where large-scale data from both natural and biomedical domains are leveraged to maximize transfer.
Future Directions
This paradigm suggests reorienting model design in medical imaging toward transfer learning from massive, diverse sources. The findings advocate for the incorporation of frozen or lightly adapted vision transformers, ideally benefiting from both general natural domain and limited, privacy-constrained medical data. Future research should investigate adaptive fine-tuning protocols, multimodal alignment mechanisms, and efficient cross-domain fusion strategies, with a focus on quantifying robustness and safety for deployment in new clinical settings and rare-disease scenarios.
Conclusion
Frozen, natural-domain vision foundation models, when integrated into unrolled MRI reconstruction pipelines, present a strong, robust, and efficient alternative to classical task-specific architectures. Their strengths manifest acutely in out-of-distribution and highly ill-posed regimes, enabling consistent, high-quality reconstruction—even in the presence of substantial anatomical, contrast, and protocol shifts. These results underscore the dual value of both large-scale and domain-adaptive pretraining, substantially informing future directions in robust, generalizable medical image reconstruction methodologies.