- The paper demonstrates that self-supervised pretraining improves clinical generalization by outperforming supervised models on out-of-domain MRI tasks.
- The results reveal that local pretext objectives favor segmentation while hybrid objectives enhance classification performance.
- The study finds that careful model selection, objective alignment, and tuning outweigh brute-force scaling in optimizing clinical MRI analysis.
Towards Practical Foundation Models for Brain MRI: Insights from FOMO25
Motivation and Challenge Design
Automated analysis of brain MRI in clinical scenarios faces fundamental obstacles stemming from the domain heterogeneity of clinical imaging and the prohibitive costs of large-scale expert annotation. Existing supervised methods display severe performance degradation in out-of-domain scenarios—a limitation exacerbated by tight coupling between model development and curated, homogeneous research data. The FOMO25 challenge, organized in coordination with MICCAI 2025 (2604.11679), systematically benchmarks the emergent class of brain MRI foundation models utilizing self-supervised learning (SSL) on a scale and with a clinical focus not previously addressed.
Distinctively, FOMO25 introduces FOMO60K, a highly heterogeneous unlabeled MRI dataset with over 60,000 scans sourced from real-world clinical workflows, and designs evaluations around low-shot adaptation and explicit domain shift. Two tracks are defined: a methods track restricted to FOMO60K and an open track permitting arbitrary pretraining data. Downstream evaluations span three tasks—binary infarct classification, meningioma segmentation, and brain-age regression—using private, small, few-shot datasets sourced from real clinical distributions, intentionally distinct from the pretraining data.
Key Results: Generalization and Transfer
FOMO25 catalyzes the first substantive community benchmarking of MRI foundation models under realistic clinical constraints. The central technical claim, robustly substantiated by challenge outcomes, is that self-supervised pretraining confers substantial gains in clinical generalization. Foundation models not only outperform fully supervised models trained from scratch on the same (out-of-domain) finetuned data, but the best out-of-domain SSL-based models also statistically significantly surpass specialist supervised models trained in-domain on larger labeled clinical datasets—a result exemplified in Figure 1.
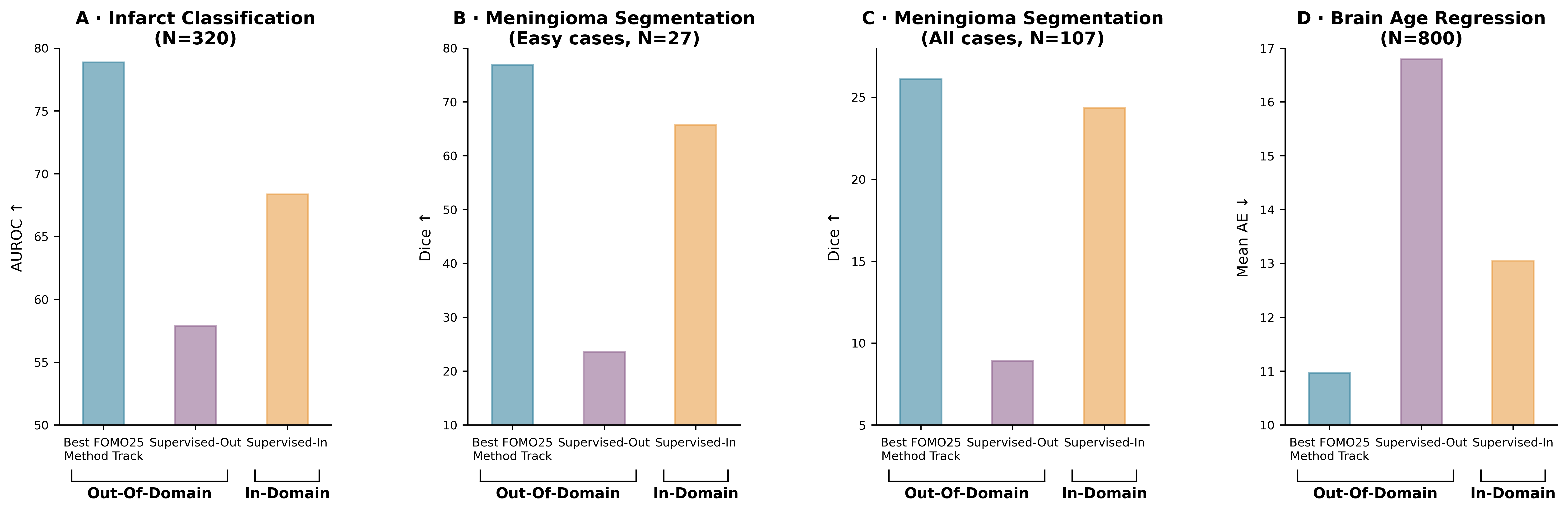
Figure 1: Self-supervised pretraining boosts generalization: outperforming both out-of-domain and in-domain supervised baselines on all downstream tasks.
These results are quantitatively nontrivial: the top pretraining-based model improves classification AUROC by up to $10.51$ points over the in-domain supervised baseline, increases segmentation Dice by $1.75$ points, and reduces brain-age regression mean absolute error by over $2$ years. This establishes a baseline for clinically oriented foundation models that is not matched by purely supervised approaches, especially under domain shift and extreme label scarcity.
Task-Specific Effects and Pretraining Design
A salient finding is the absence of a universally optimal SSL pretraining objective across task families. As detailed in Figure 2, local objectives (MAE) predominantly benefit segmentation; hybrid objectives (MAE + contrastive, e.g., DINO variants) favor classification; and no consistent differentiation emerges for regression, with all objective types yielding comparable outcomes. These cross-task inconsistencies highlight the coupling between pretext objective alignment and transfer efficacy, directly motivating future work in universal or multi-task-optimized objectives for neuroimaging.
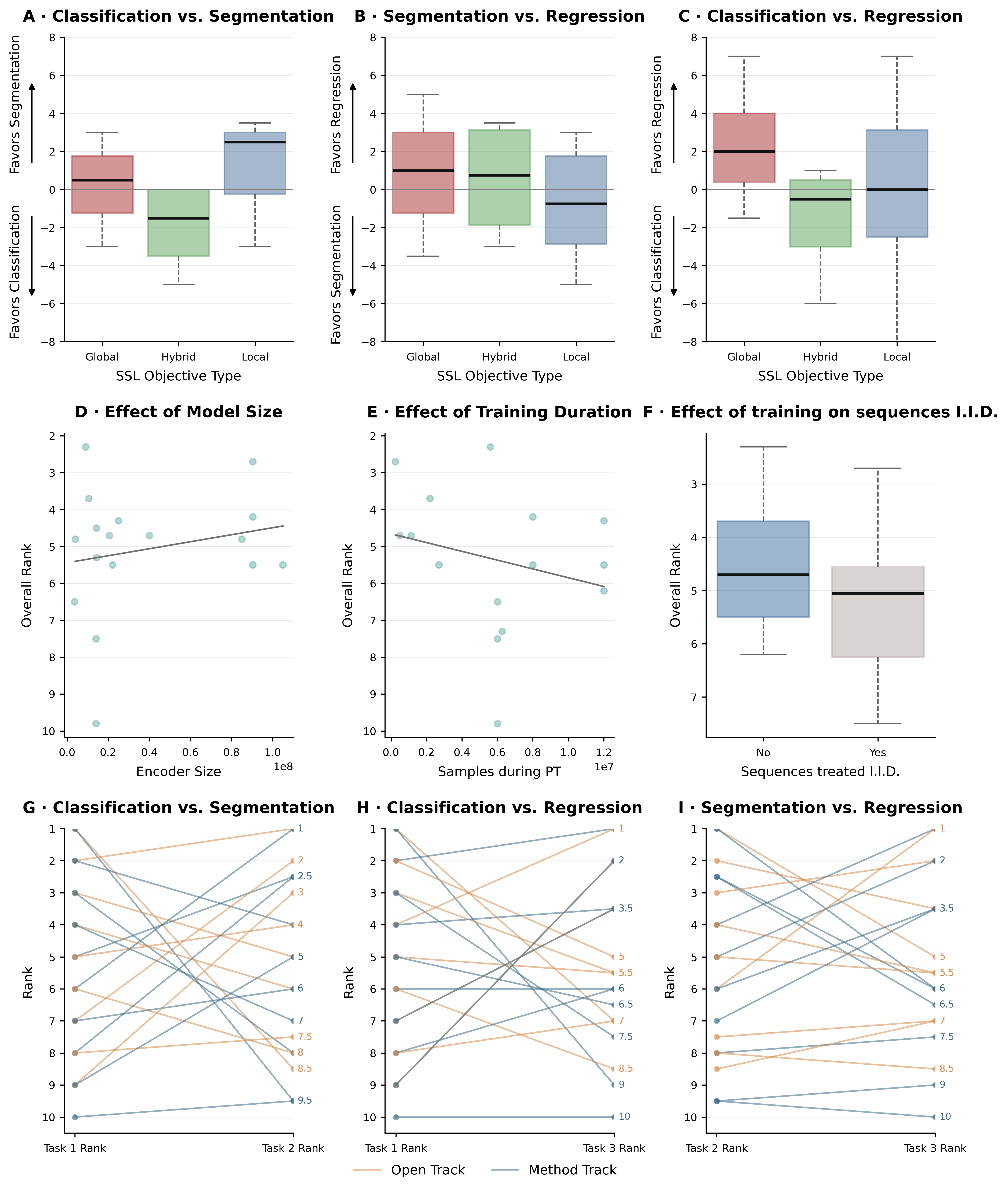
Figure 2: Downstream performance depends on pretraining objective: local (MAE) for segmentation, hybrid for classification, with weak effect of model size or pretraining duration.
Another strong and somewhat contradictory outcome relative to recent computer vision literature is that model scaling and prolonged pretraining do not reliably yield transfer performance improvements in this setting. Small encoder architectures (sub-20M parameters) frequently match or outperform larger models, and increasing pretraining dataset scale beyond tens of thousands of scans or epochs does not guarantee improved downstream results. Model selection, pretext-task/data alignment, and hyperparameter tuning exert a far greater effect on clinical adaptation than brute-force scaling (also illustrated in Figure 2).
Augmentation and Tuning
Augmentation policies and hyperparameter optimization materially impact task-specific downstream results. As shown in Figure 3, extensive spatial augmentations improve segmentation transfer, but excessive total augmentation breadth can degrade classification and regression—likely due to mismatched signal-to-noise ratios and representational drift undesirable outside of dense-pixel prediction. Hyperparameter tuning regimes further exhibit non-monotonic influence: minimal tuning suffices for few-shot classification, while segmentation benefits from more intensive search.
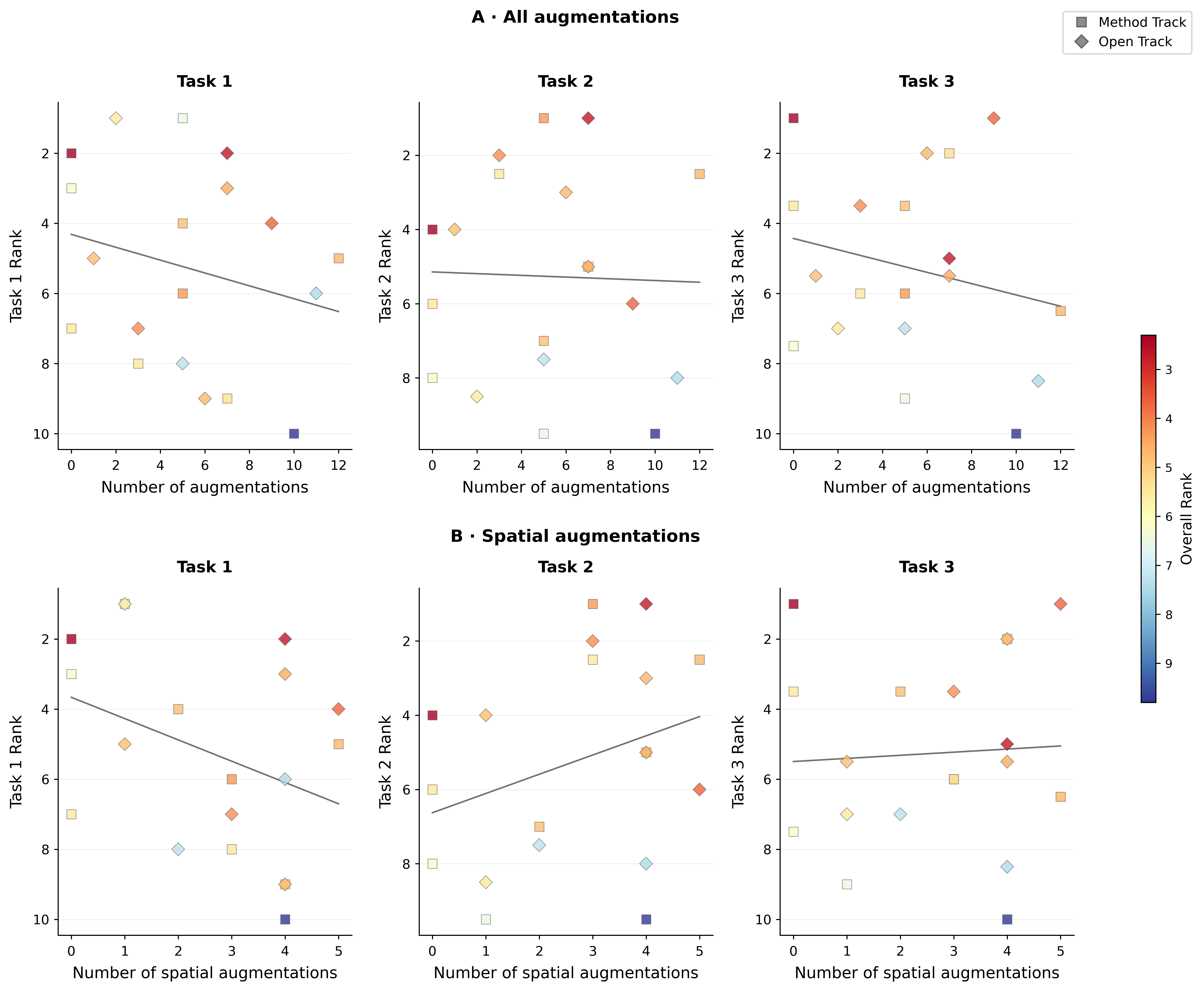
Figure 3: Spatial augmentations aid segmentation, while excessive overall augmentation harms classification and regression.
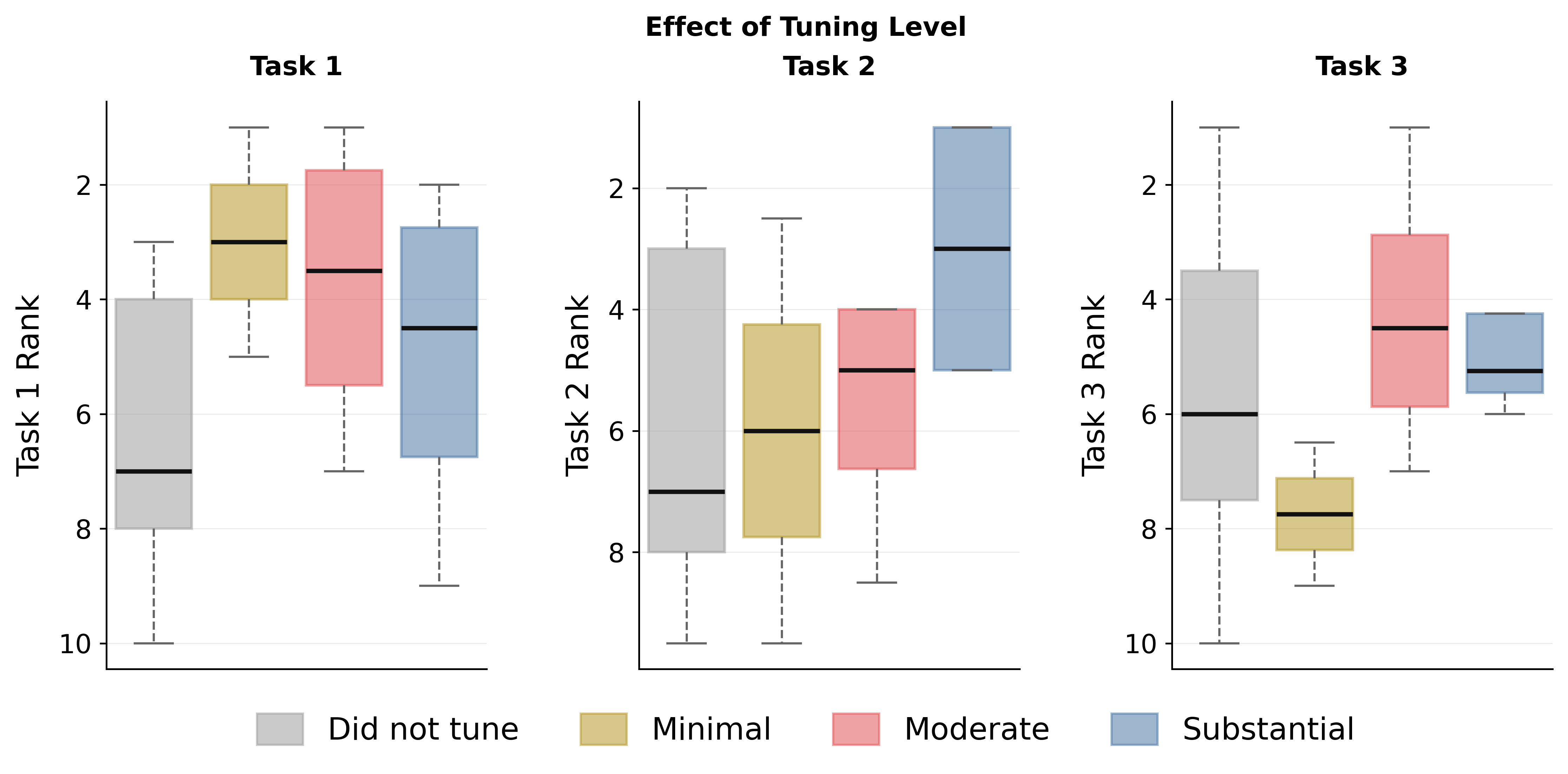
Figure 4: Moderate to substantial hyperparameter tuning proves crucial for robust segmentation adaptation, with differing trends across tasks.
Track Comparison and Methodological Diversity
Analysis of open versus method track submissions (Figure 5) reveals that, despite large teams leveraging massive proprietary datasets and large-scale computation (>1M scans, 100M+ param models), no open track submission substantially outperforms the best method track entrants. CNN-based encoders continue to dominate, especially in the open track, with sparse adoption of transformer or hybrid backbones. Diverse pretext objective choices, from classic contrastive learning to advanced hybrid self-distillation strategies (cf. DINOv2/CVA), are evident across submissions. Notably, systematic pretraining on 3D volumes and the use of 3D-specific self-distillation objectives remain nascent, marking clear directions for the field's maturation.
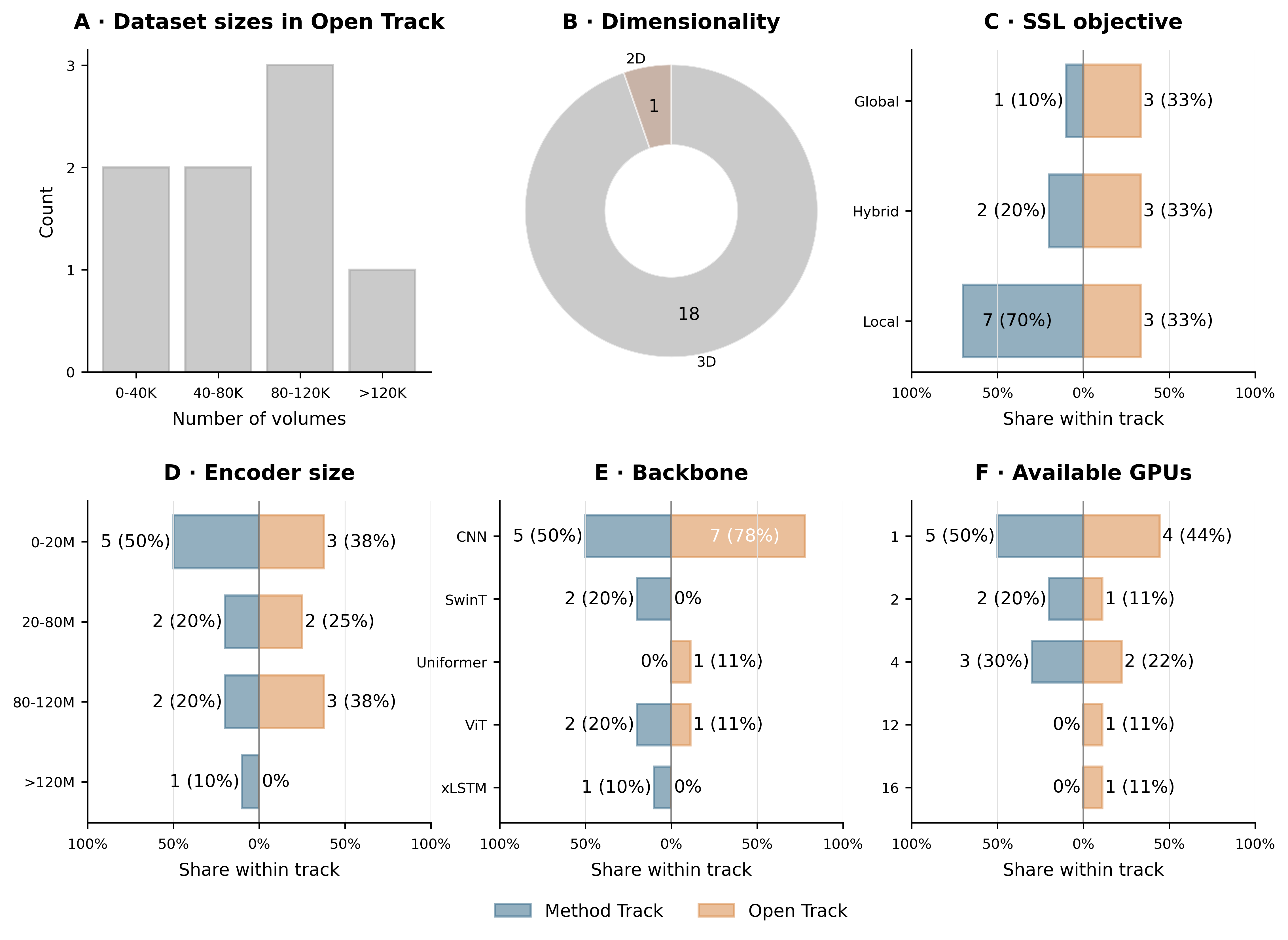
Figure 5: Open-track submissions employ larger datasets, GPU counts, and models, but do not universally surpass the controlled method track.
Statistical Rigor and Downstream Evaluation
A substantial contribution of FOMO25 is the adoption of statistically rigorous analysis (bootstrap ranking, permutation testing, tiered leaderboard metrics; see Figure 6). Task-level performance is not saturated in any domain or model family, reinforcing the stringency of the benchmarks. Detailed ablations clarify that improvements derive from representation quality and transfer robustness, not finetuning recipes or resource scaling alone.
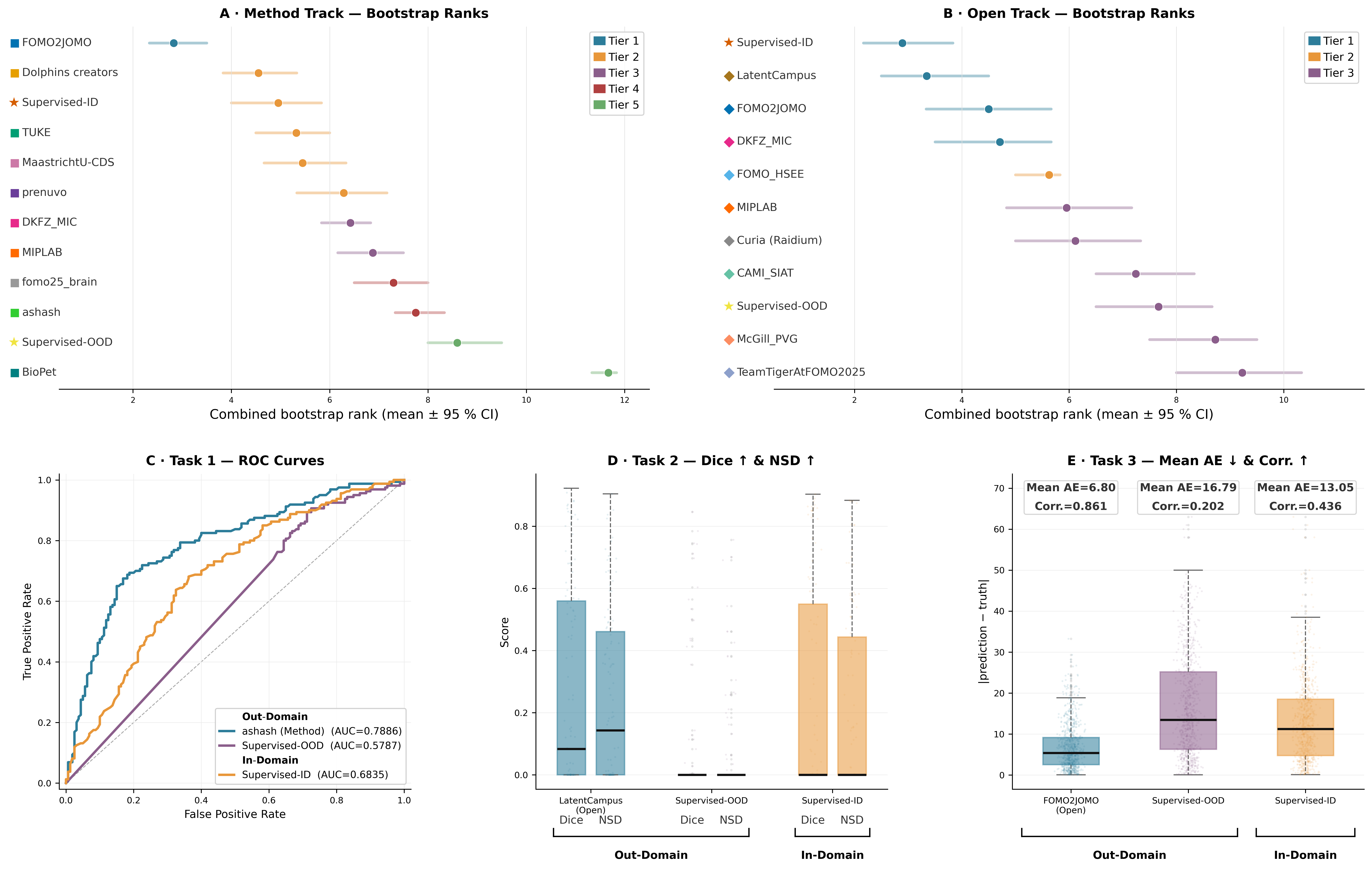
Figure 6: Statistical rank distributions and task-level metrics with supervised baselines, highlighting robust superiority of foundation models under realistic constraints.
Implications and Future Directions
These findings have direct implications for both deployment and future research in medical imaging foundation models:
- SSL-pretrained foundation models, when appropriately aligned in pretext objective and backbone design, now constitute a viable baseline for clinical adaptation in MRI, outperforming traditional supervised learning under label and domain shift constraints.
- The design choice of SSL objective is critical—bespoke objectives for each task family may currently be necessary, and universal objectives (as in DINOv3 for natural images) should be validated in the brain MRI context.
- Model scaling and compute increases show diminishing returns under present clinical data distributions, challenging assumptions imported from mainstream vision pretraining.
- 3D transformer architectures and 3D self-distillation remain underexplored in MRI foundation models, representing technically promising avenues.
- FOMO25's evaluation framework—centered on few-shot, out-of-domain, and multi-task robustness—enables a sharper assessment of clinical transfer readiness than prior research-grade, single-task benchmarks.
Broader theoretical implications touch on the field's understanding of cross-domain self-supervision, the limitations of current pretext objectives in encoding anatomical nuance, and the open problem of designing benchmarks that do not artificially inflate the performance of either supervised or foundation models.
Conclusion
FOMO25 articulates a rigorous, multi-institutional evidence base supporting the utility of self-supervised MRI foundation models in practical clinical settings. By demonstrating statistically significant gains in few-shot, out-of-domain adaptation over supervised baselines, while revealing the nuanced interaction between SSL strategy and downstream task, the challenge sets a modern standard for the evaluation of neuroimaging foundation models. Methodological lessons regarding objective selection, augmentation, and finetuning, as well as the identification of architectural underexploration, will structure future research and deployment. The field now demands both (a) methodological consolidation towards best practices, and (b) systematic expansion into larger, more heterogeneous clinical datasets and advanced model classes.