- The paper introduces a single-model early-stopping method for arbitrary K queries, significantly reducing preprocessing time compared to per-K models.
- It employs iterative top-1 refinement with novel trajectory features that robustly generalize over masked search sets to maintain high recall.
- The approach achieves substantial latency and cost savings in real-world deployments, cutting CPU usage by up to 24% while improving tail latencies.
Efficient K-Generalizable Learned Vector Search: One Model for Multi-K Queries
Introduction and Problem Context
The paper addresses the inefficiency of learned early-stopping methods for approximate nearest neighbor search (ANNS) in large-scale vector databases, focusing on real-world workloads with highly diverse and dynamic top-K search requirements. State-of-the-art systems such as DARTH and LAET, while performant for single-K workloads, require training and maintaining dedicated models for each distinct K value, resulting in non-trivial preprocessing costs and impracticalities at scale. The authors analyze production workloads from Alibaba, highlighting that more than half of all collections serve multi-K query workloads and that preprocessing—including model training and index compaction—already accounts for a significant share of computational resources (Figure 1).
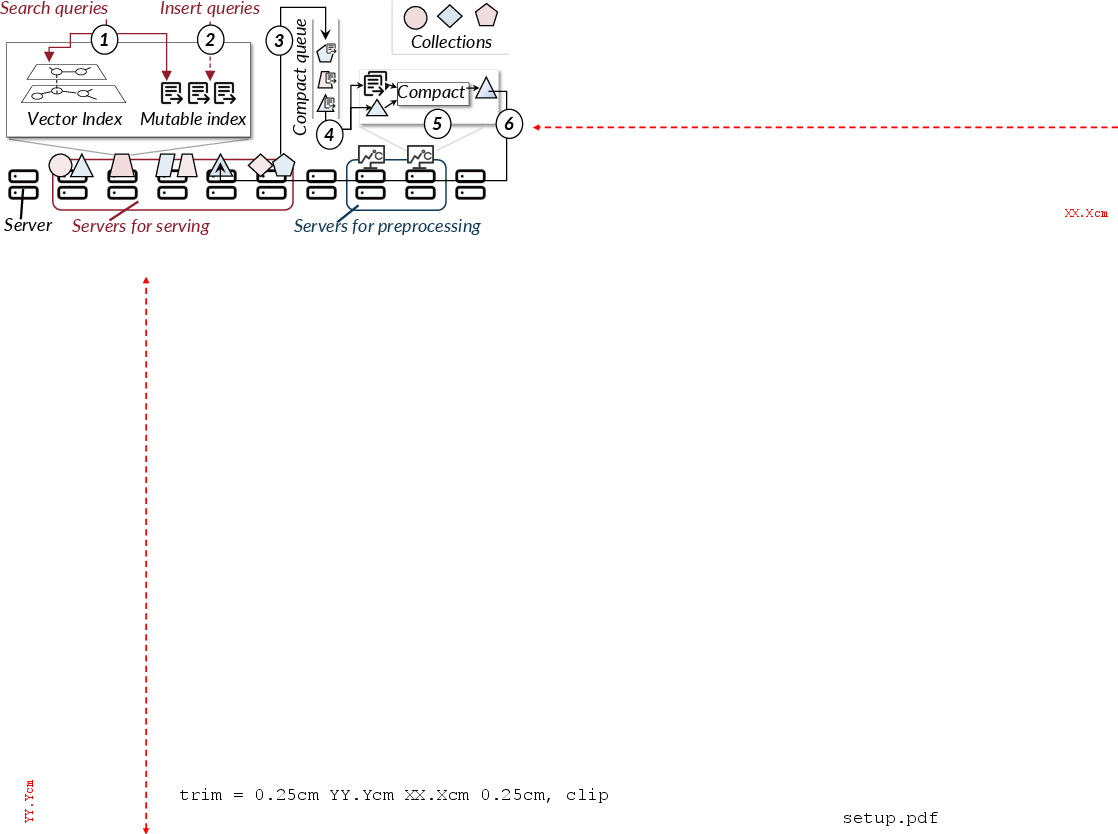
Figure 2: Serving vector queries in cloud environments, illustrating the interaction between query serving, dynamic collections, and background index compaction.
Realistic deployments—including Alibaba's—operate in settings where (1) collections evolve over time, demanding frequent retraining, and (2) users require queries with varied K (Figure 3, Figure 4). The pursuit of per-K models scales poorly, with evidence that supporting 39% of the most common K-values nearly doubles preprocessing costs. Thus, a method capable of efficiently supporting arbitrary K with a single learned model is required.

Figure 3: Empirical workload statistics showing many collections serve highly dynamic, multi-K access patterns.
Limitations of Existing Methods
Graph-based ANNS indices (e.g., HNSW, NSG) are widely adopted due to their efficiency-recall trade-offs. Conventional systems use static, heuristic-driven hyperparameters (e.g., search depth), which fundamentally trade recall against latency, as search set sizes—and hence, the number of graph traversals—vary unpredictably with query difficulty (Figure 5). Learned early stopping methods such as LAET and DARTH attempt to optimize this, but their models are tied to specific K values: a model trained for a particular K generalizes poorly to other K, resulting in either under-search (decreased recall for K\textgreater K∗) or over-search (increased latency for K\textless K∗) as illustrated in Figure 6.
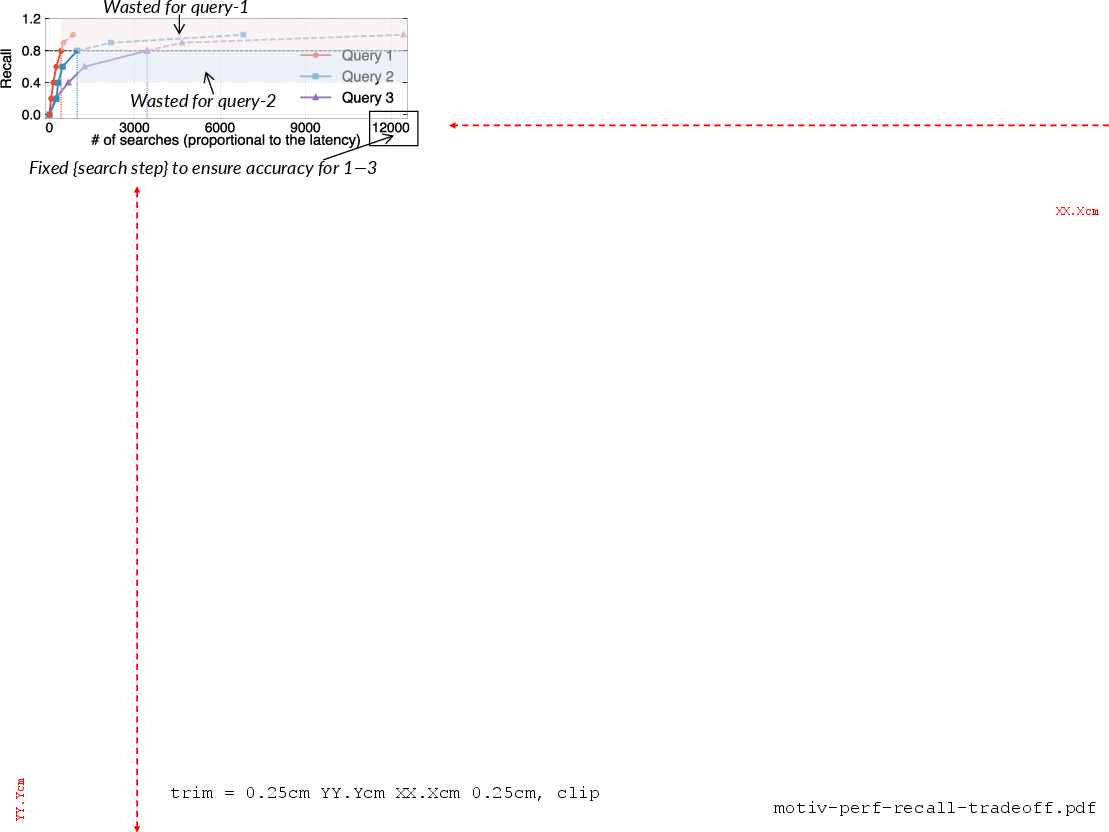
Figure 5: Performance-accuracy trade-off: fixed-budget search parameters cannot simultaneously provide low latency and high recall across queries of diverse difficulty.
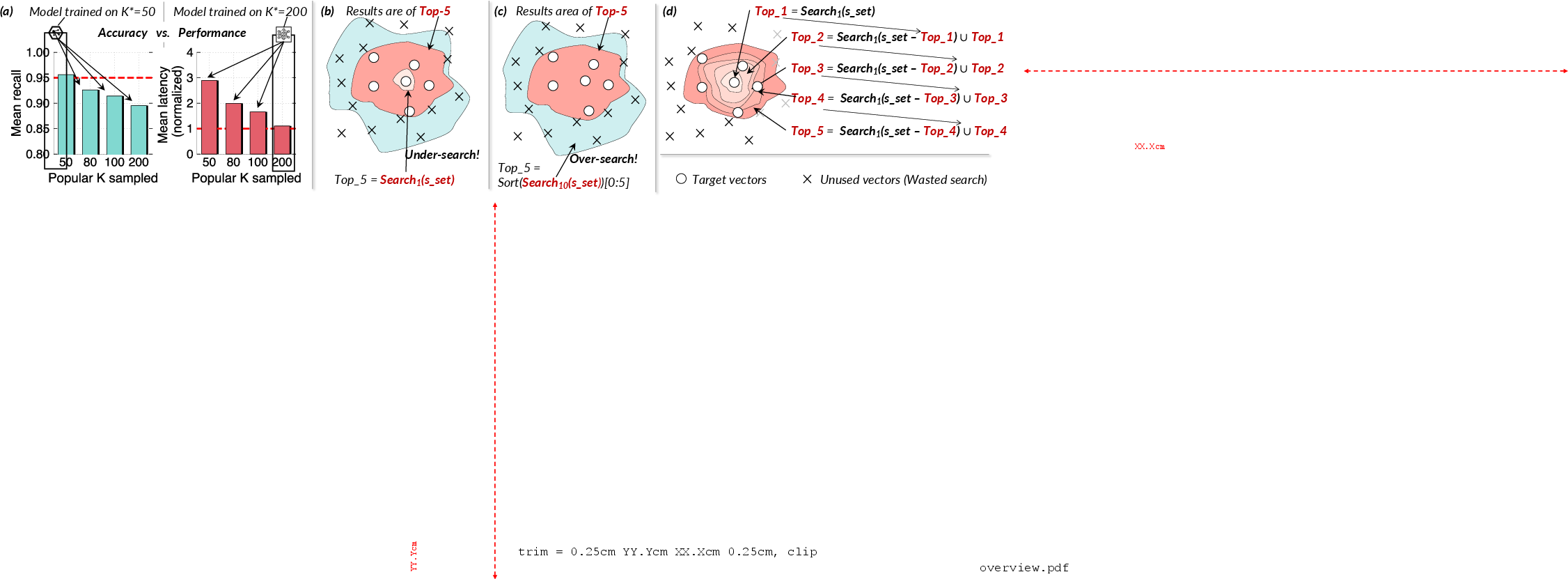
Figure 6: (a) Standard models fail to generalize across K; (b) small-K generalization under-searches for larger K; (c) large-K generalization over-searches for small K; (d) proposed iterative top-1 scheme generalizes using a single model.
Training models to generalize across multiple K values—with either holistic "one-model" approaches or per-K models—greatly increases preprocessing costs (Figure 7), which is operationally prohibitive for in-the-wild deployments.
K-Generalizable Search via Iterative Top-1 Refinement
The paper proposes K-generalizable learned search, denoted as Ω, which requires training only a single early-stopping model for K=1. Arbitrary top-K queries are decomposed into K sequential top-1 queries, leveraging iterative masking to exclude previously found neighbors. With each mask, the same model is repeatedly invoked, searching for the next nearest neighbor.
A central insight is that this reduction from top-K to K top-1 queries is only effective if the model is robust to masked search sets—a non-trivial challenge, as demonstrated by the failure of the standard minimal-distance feature (used in DARTH) to generalize across masked contexts (Figure 8). The proposed solution engineers a distance-trajectory feature, capturing the local trend in search set distances across recent expansions (sliding window extraction), which empirically generalizes well over masked iterations (Figure 9, Figure 10).
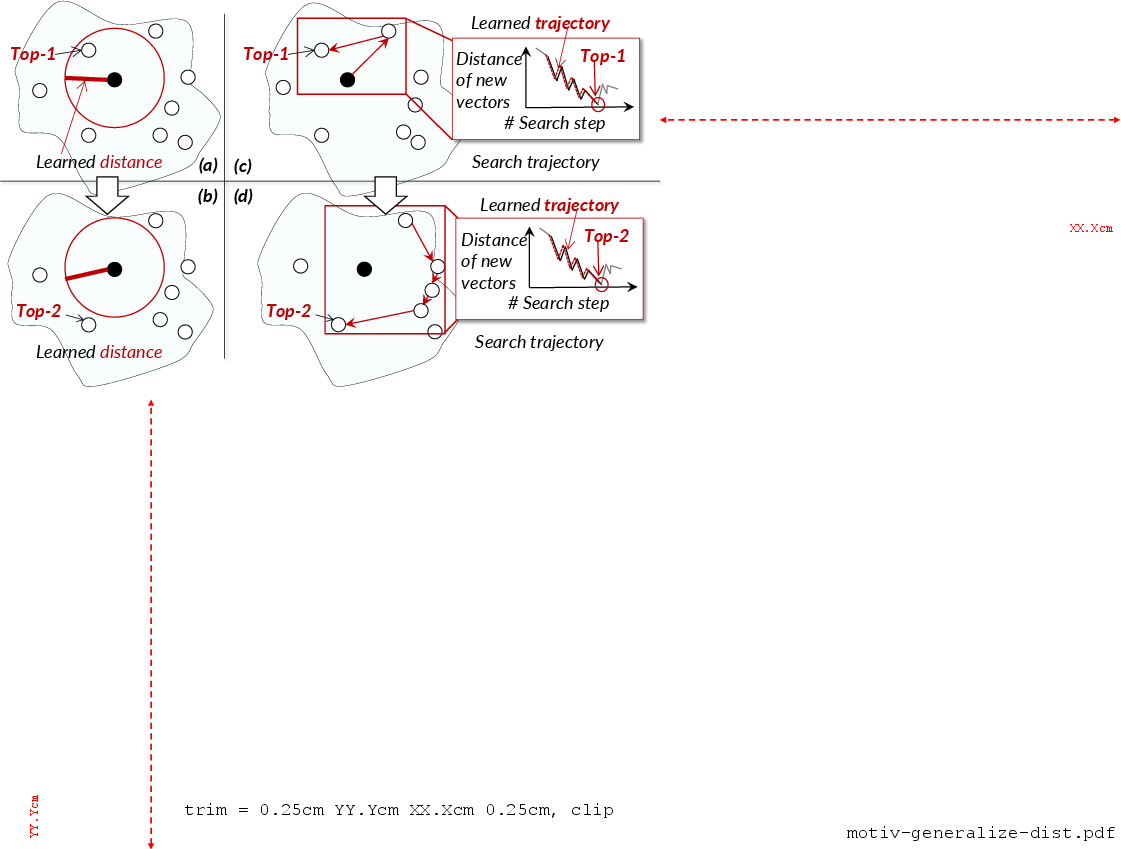
Figure 8: Classical distance-based features (as in DARTH) do not adapt well under masking during iterative top-1 refinement.
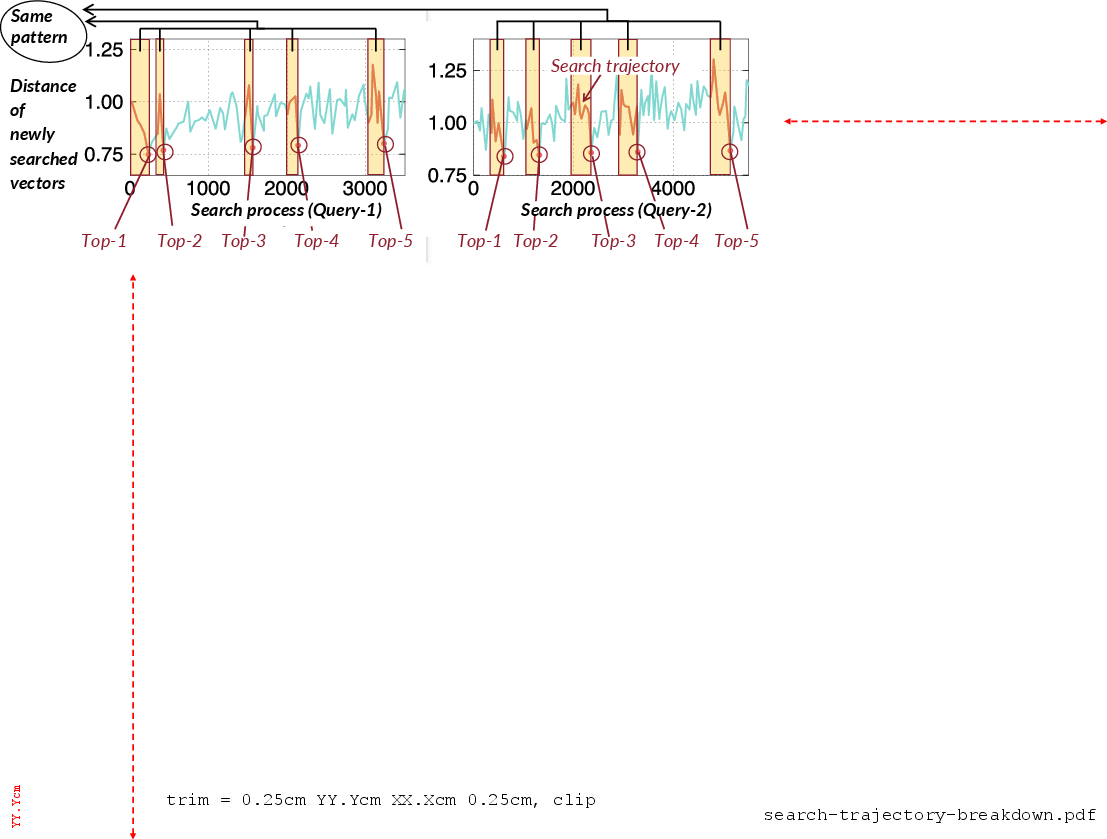
Figure 9: Characteristic distance trajectory patterns in HNSW traversals, showing robust, generalizable signals irrespective of masking.
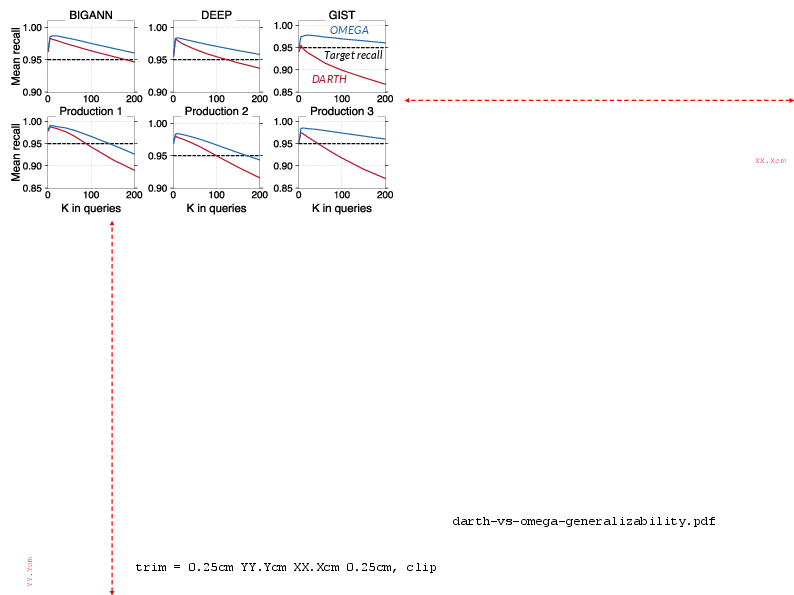
Figure 10: Demonstrating that trajectory-based features enable strong generalization across arbitrary K for the same model.
The core model is trained on top-1 queries, using gradient-boosted decision trees (GBDT/LightGBM), with a trajectory window size set empirically (Figure 11, Figure 12). Statistical analysis confirms recall and latency robustness across window sizes as long as w≳50.
Optimizations: Statistical Forecasting for Model Skipping
A naive iterative masking search would require invoking the trained model K times per query. However, the authors exploit an empirically observed conditional probability distribution: once N<K ground-truth neighbors are found, the probability that additional ground-truth neighbors reside in the search set is predictable and quickly decays (Figure 13). By offline profiling this distribution and maintaining a lookup table, the system can, during search, forecast whether the recall target is met without further model invocations, enabling early stopping.
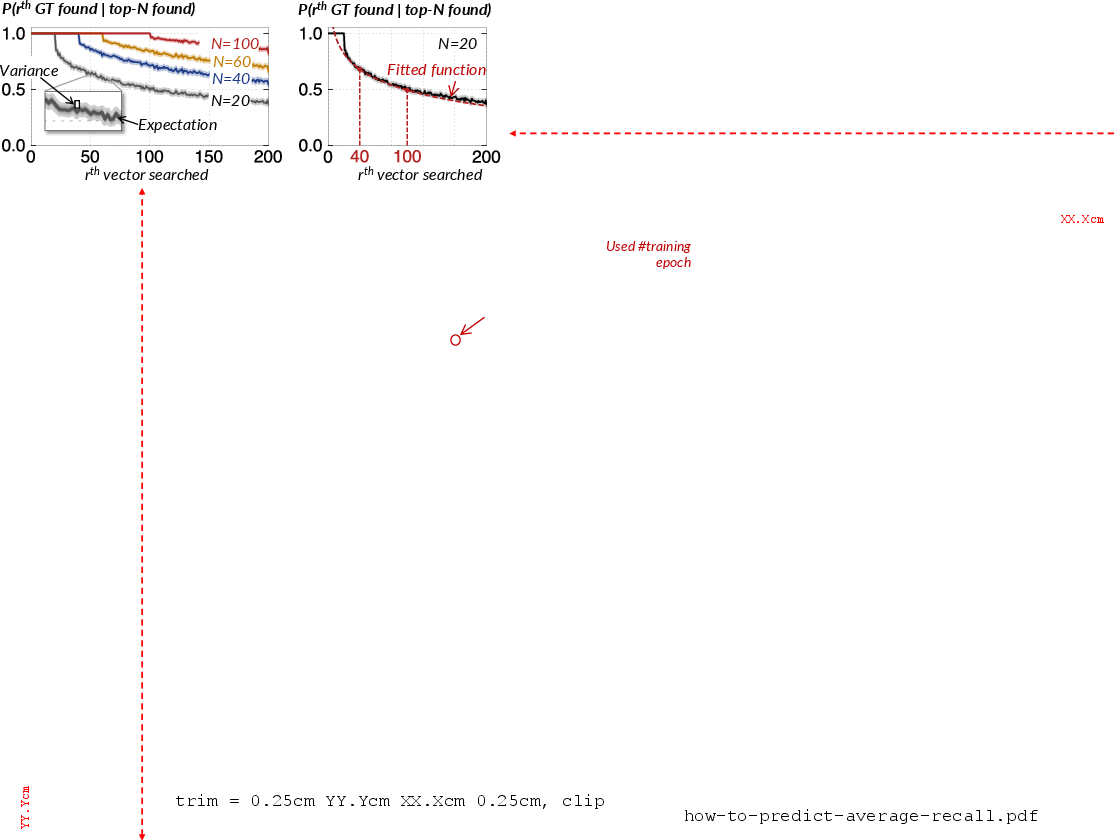
Figure 13: Conditional probability of the r-th ground-truth neighbor being contained, given N previously found neighbors—basis for model-skipping statistical forecast.
This mechanism is essential for amortizing model invocation overheads in large-K queries and is integrated with adaptive model invocation frequency heuristics.
Experimental Evaluation
The paper presents extensive experiments on both large-scale public datasets (BIGANN, DEEP, GIST) and real production datasets from Alibaba, with real multi-K traces. The proposed method is benchmarked against FIXED, LAET, and DARTH, reporting on overall recall, latency, CPU consumption, and preprocessing costs. All methods are tuned for competitive performance, with only one model per method (where appropriate).
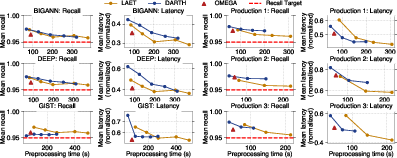
Figure 14: Recall and latency across methods/datasets for multiple preprocessing time budgets. Latency is normalized to the slowest, conservative baseline.
Key results:
- With identical preprocessing cost (i.e., one-train per collection), Ω reduces average search latency by 6–33% compared to DARTH and maintains the desired recall in all regimes.
- At optimal points ($1.01$–1.28× optimal latency of baselines), Ω achieves this using only 16–30% of the preprocessing time.
- Aggregate CPU core-hours (preprocessing + serving) over one day of production traces show up to 24% cost savings over the best baseline (Figure 15).
- Per-query tail latency (P90/P99) is significantly reduced—5–39% P90, 12–42% P99 improvements.
- The trajectory feature is essential for robust generalization: without it (i.e., using traditional distance-based features), recall collapses for larger K (Figure 10).
Ablation studies (Figure 16) confirm that both optimized model invocation strategies and statistical forecasting are crucial for achieving these results, with the latter contributing up to 49% further latency reductions.
Implications and Future Directions
Practically, the work enables real-world ANNS deployments (e.g., Alibaba) to:
- Drastically reduce model training and maintenance costs. A single model per collection suffices, regardless of K diversity.
- Provide adaptive, declarative recall for arbitrary query K without user involvement or hyperparameter tuning.
- Support evolving, mutable indices with minimal retraining and no operational burden.
Theoretically, this establishes that early-stopping for ANNS can be robustly decoupled from the fixed-K assumption, if feature engineering captures the invariant search trajectory signals. It also illustrates the power of statistical proxying in amortizing iterative inference costs for complex, compositional search requirements.
Future developments may include adaptation to cluster-based/non-graph indices, further scaling and parallelization for heterogeneous hardware, and composability with storage-centric graph ANNS. Integrating these principles with learned index construction or routing policies can yield more substantial end-to-end system improvements.
Conclusion
This work introduces a practically deployable, K-generalizable learned top-K search algorithm for graph-based ANNS, achieving both high recall and low latency with one compact model per collection. By engineering robust, trajectory-based features and combining statistical forecasting, it substantially reduces both online serving costs and offline preprocessing time, outperforming prior methods in diverse, production-scale multi-K settings. The system is open source and is actively being adopted in Alibaba's vector database infrastructure, establishing a new operational baseline for production ANNS search in dynamic, multi-K environments.

