Filtered Approximate Nearest Neighbor Search Cost Estimation
Abstract: Hybrid queries combining high-dimensional vector similarity with structured attribute filtering have garnered significant attention across both academia and industry. A critical instance of this paradigm is filtered Approximate k Nearest Neighbor (AKNN) search, where embeddings (e.g., image or text) are queried alongside constraints such as labels or numerical range. While essential for rich retrieval, optimizing these queries remains challenging due to the highly variable search cost induced by combined filters. In this paper, we propose a novel cost estimation framework, E2E, for filtered AKNN search and demonstrate its utility in downstream optimization tasks, specifically early termination. Unlike existing approaches, our model explicitly captures the correlation between the query vector distribution and attribute-value selectivity, yielding significantly higher estimation accuracy. By leveraging these estimates to refine search termination conditions, we achieve substantial performance gains. Experimental results on real-world datasets demonstrate that our approach improves retrieval efficiency by 2x-3x over state-of-the-art baselines while maintaining high search accuracy.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
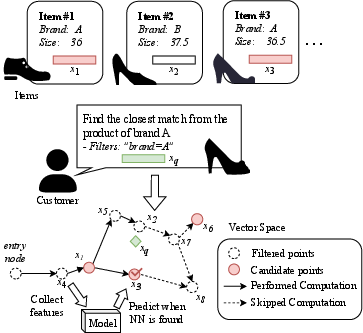
Imagine you’re searching for similar items using an image or a piece of text, like finding shoes that look like a photo you upload. Often, you also add filters, like “brand = A” or “price under $50.” Finding the closest matches that also pass your filters is much harder and can be slow.
This paper builds a smart way to predict how much work a filtered search will take and then stop the search early once it’s “good enough.” The trick is to notice how the filter and the query are related around the query, not just across the whole dataset, so the system can avoid wasting time.
What questions does it try to answer?
- How can we estimate, quickly and accurately, how long a filtered search will take for a specific query?
- How do the query’s nearby items (by similarity) line up with the filter (like brand or price)? Are nearby items likely to pass the filter or not?
- Can we use this estimate to stop the search early and still get high-quality results?
How did the researchers approach the problem?
Think of all items (images, texts, etc.) as points in a big space, where “distance” means how different they are. Searching similar items often uses a graph: each item is a “node” connected to nearby items, like roads connecting nearby houses in a city.
The paper focuses on “filtered approximate k-nearest neighbor” (filtered AKNN) search:
- “Nearest neighbor” means find the closest items to your query.
- “Approximate” means it’s fast but may miss a few perfect matches.
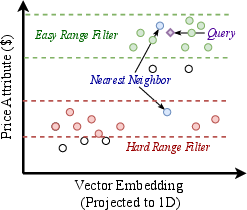
- “Filtered” means results must also pass conditions like labels (brand, category) or numeric ranges (price, date).
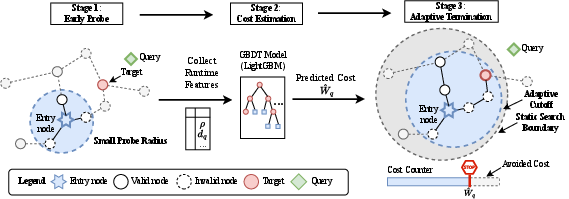
Key idea: Early probing
Before committing to a full search, the system takes a short “peek” nearby:
- It walks a few steps in the graph from the starting point, measuring how many nearby items actually pass the filter.
- This quick peek is reused in the full search, so it doesn’t waste work.
Analogy: If you’re looking for a specific brand in a mall, you first glance at the nearby stores. If none sell that brand, you know you’ll need to walk farther; if many do, you can stop sooner.
What features do they look at?
From this early peek, the system collects simple signals that tell how hard the search will be:
- Local valid ratio: Of the nearby items you checked, what fraction matched the filter? If this ratio is high, you likely need less searching.
- Queue valid ratio: Among the candidates you’re about to explore next, how many look promising and match the filter?
They also look at distance patterns (how close current candidates are), similar to earlier research, but the new twist is tying these signals to the filter.
The prediction model
They use a fast, lightweight machine learning model (LightGBM, a type of boosted decision trees) to predict the “search budget,” which is the amount of work needed. Here, “work” is measured as the number of distance calculations — that’s basically how many comparisons the search makes.
LightGBM is chosen because it’s quick to run (about 0.025 milliseconds per prediction), so it won’t slow the search down.
Using the prediction to stop early
With the predicted budget, the search continues and counts how many comparisons it makes. Once it hits the predicted limit, it stops and returns the current best filtered results. This “adaptive termination” cuts off wasted effort on easy queries and avoids spending too little on hard ones.
What did they find?
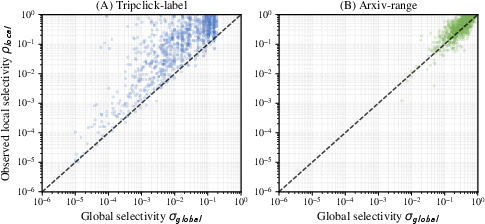
- Their estimator captures the real difficulty of filtered searches better than existing methods because it looks at the local match between the query and the filter, not just global averages.
- Using the estimates to stop early, they achieved about 2x–3x faster search while keeping high accuracy (good recall).
- It’s especially strong on “hard” queries where the filter clashes with the query’s nearby items. Example: a photo of a luxury watch plus a filter “price < $20.” Nearby items might be similar watches but not in that price range; the system correctly predicts this will take longer and plans accordingly.
- It reduces latency spikes (random slow queries) and makes search times more predictable.
Why does it matter?
- Faster searches: Helpful for e-commerce (“find similar products with brand/price filters”), recommendations (music, videos), and AI systems that look up related documents (RAG for LLMs).
- Better resource use: Fewer wasted computations means lower costs and energy use.
- Smoother experiences: More stable and predictable response times for users.
- Practical and general: Works with common graph-based indexes and typical filters (labels and ranges), and the quick estimation is fast enough for real-time systems.
Overall, the paper shows that a small, smart “peek” plus a fast prediction can make filtered similarity search both efficient and reliable, without sacrificing quality.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to guide actionable future research.
- Generalization beyond graph-based ANN: How to adapt early-probe features and the estimator to non-graph backends (e.g., IVF/IVF-PQ, ScaNN, PQ/HNSW hybrids, DiskANN) where traversal dynamics and cost drivers differ.
- Disk-based and memory-hierarchy costs: The model predicts number of distance computations (NDC) but ignores I/O, cache, SIMD/vectorization, and memory access patterns that dominate latency in disk or compressed indexes; methods to incorporate these costs remain open.
- PRE-filter and hybrid filtering support: The framework targets POST filtering; it is unclear how to handle PRE filtering (risking graph disconnections) or PRE/POST hybrids and how early-probe signals should be modified in these regimes.
- Unsatisfiable filters and zero-result detection: The method does not describe how to detect contradictory filters that yield |S(q)| = 0 (or < k) early, nor how to terminate gracefully without wasting budget.
- Extreme sparsity edge cases: When early probes see no valid nodes (ρ_pilot = 0 and ρ_queue = 0), what robust fallback strategies, conservative budgets, or escalation policies prevent severe underestimation?
- Sensitivity to early-probe length f: There is no analysis of how to set or adapt f per query (e.g., based on online signals), the trade-off between probe cost and estimator accuracy, or how mis-specified f affects recall/latency.
- Uncertainty-aware termination: The estimator returns a point prediction; there is no confidence/uncertainty modeling (e.g., quantile regression, prediction intervals) to protect recall by adjusting budgets under uncertainty.
- Recall guarantees and failure modes: Early termination uses a budget threshold without theoretical recall guarantees; a formal characterization of when/why recall can drop and protective mechanisms (e.g., adaptive backoff) is missing.
- Scaling to large k and varying recall targets: The evaluation focuses on Recall@10; it remains unknown how feature distributions and budgets scale for k ≫ 10 or for different target recall (e.g., 95% vs 99.9%).
- Multi-attribute and complex predicates: Only single label/range filters are evaluated; behavior under conjunctions/disjunctions, correlated attributes, and heterogeneous predicates (e.g., geo + category + range) is untested, and feature design for joint selectivity remains open.
- Model transferability and domain shift: The estimator is trained per dataset/index; open questions include how well it transfers across datasets, embeddings, index configurations, or filter distributions, and how to detect/mitigate drift.
- Online/continual learning: No mechanism is provided for updating the model under data/index updates, changing query workloads, or new filter values; criteria and pipelines for safe incremental retraining are needed.
- Ground-truth target generation: Training uses “100% recall” via extended search, but the paper does not clarify if exact neighbors (via brute force) are used; biases from approximate ground truth and their impact on training are unresolved.
- Robustness to index topology: The effect of graph structure (e.g., degree distribution, connectivity, hierarchical layers in HNSW) on feature reliability and prediction accuracy is not analyzed; topology-aware features may be needed.
- Interaction with index parameters: How per-query budgets interplay with HNSW’s efSearch, beam width, or other tunables is not studied; joint optimization of index parameters and learned budgets remains open.
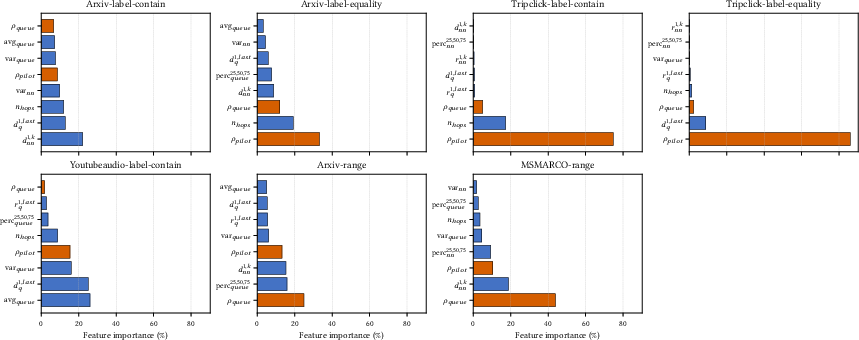
- Feature sufficiency and alternatives: The two filter-aware features (ρ_pilot, ρ_queue) may be insufficient for complex correlations; exploring richer signals (e.g., neighborhood degree features, attribute-conditioned neighbor stats, graph embeddings) is an open avenue.
- Feature extraction overheads: Although deemed “negligible,” the actual costs of computing features (queue scans, valid-counting, predicate checks) under different workloads and filter complexities are not quantified.
- API/integration constraints: Many production libraries do not expose internal queues or visited sets; engineering patterns for integrating the estimator without modifying low-level search loops are not addressed.
- Dynamic distance metrics and embedding shifts: Generality to cosine vs. L2 vs. learned metrics and to evolving embedding models (e.g., refreshed encoders) is not evaluated; how to maintain accuracy across metric/model changes is unclear.
- Handling highly selective vs. highly unselective filters: The estimator’s calibration at the extremes of selectivity (very high or very low) is not characterized; techniques for per-regime calibration or regime detection are needed.
- Coupling with other accelerations: The interaction between this termination policy and other optimizations (e.g., re-ranking, product quantization asymmetry, pruning heuristics, label-aware shortcuts) has not been explored.
- NDC-to-latency linearity assumption: The mapping from NDC to wall-clock latency is assumed linear; quantifying when this breaks (e.g., due to branch misprediction, cache misses, SIMD saturation) and how to correct it is an open issue.
- Billion-scale and multi-threaded/GPU settings: Experiments are single-threaded and ≤ 1.7M points; behavior at billion-scale, with multi-threading or GPUs, and under shared-resource contention is untested.
- Cold-start for rare or unseen filters: How the model performs for rare labels/ranges or entirely new filter values unseen in training is unknown; strategies for zero-shot or few-shot adaptation are needed.
- Fairness and bias implications: Exploiting correlations between vectors and attributes may amplify unwanted biases; there is no discussion of fairness-aware cost estimation or safeguards.
Practical Applications
Immediate Applications
Below are deployable use cases that can be implemented with existing vector databases and ANN graph indexes by adding the proposed cost estimator and early-termination logic.
- Sector: Software/Vector Databases
- What: Correlation-aware early termination for filtered HNSW/graph ANN
- Tools/Workflows: Integrate the E2E predictor into HNSW (efSearch tuner), Milvus/OpenSearch/Vespa/Faiss wrappers; expose per-query predicted budget; add telemetry for ρ_pilot and ρ_queue
- Assumptions/Dependencies: Graph-based ANN available; ability to instrument queue/visited sets; small GBDT inference latency; offline training on representative query logs; stable target recall
- Sector: Search & E-commerce
- What: Faster product image/text search with attribute filters (brand, price, seller, category)
- Tools/Workflows: E2E as a microservice in the retrieval tier; dynamic per-query budget to cap tail latency; A/B test against static efSearch
- Assumptions/Dependencies: Post-filter traversal; accurate predicate evaluation; filter distributions not drastically drifting
- Sector: Recommender Systems (Media/Streaming)
- What: Efficient “similar item” retrieval with tag/genre/region/maturity filters
- Tools/Workflows: Replace static search budgets in candidate generation with E2E; per-profile SLA tiers (kids vs general audience)
- Assumptions/Dependencies: Embedding space exhibits label/range correlations; enough logs to train per-market models
- Sector: Enterprise RAG and Search
- What: Low-latency retrieval under access-control, source, date-range, department filters
- Tools/Workflows: Plug-in to vector store in RAG stack (e.g., Milvus/Weaviate/OpenSearch) to predict per-query compute budget; guardrail for P95/P99
- Assumptions/Dependencies: Access-control predicates evaluated during traversal; instrumentation safe with multi-tenant workloads
- Sector: Finance
- What: Similar document/event retrieval constrained by time window, instrument sector, risk level
- Tools/Workflows: Use E2E in retrieval microservices that power alerting/due diligence; dynamic budget allocation to respect market open-hour SLAs
- Assumptions/Dependencies: Strict latency budgets; retraining when market regimes shift
- Sector: Healthcare/Clinical IR
- What: Query medical notes or imaging embeddings with ICD/department/date filters
- Tools/Workflows: Deploy E2E in on-prem vector search with audit logging; per-query budgets tuned for clinician-facing tools
- Assumptions/Dependencies: PHI-safe logging; privacy review of feature collection; stable embeddings across model updates
- Sector: Cybersecurity/Threat Intel
- What: Fast retrieval of similar indicators with label/time/source trust filters
- Tools/Workflows: Correlation-aware budgeter to cap worst-case hunts; SLA-aware routing of “hard” queries to bigger budget pools
- Assumptions/Dependencies: Streaming updates require periodic model refresh; robust fallback for incident spikes
- Sector: Developer Productivity (Code Search)
- What: Code snippet search with language/framework/version filters
- Tools/Workflows: Integrate E2E into internal code search services (Sourcegraph-like) to reduce tail latency on large monorepos
- Assumptions/Dependencies: Adequate training coverage across languages; consistent attribute schemas
- Sector: Education/EdTech
- What: Content retrieval with grade level, topic, difficulty, date filters
- Tools/Workflows: E2E in curriculum-aligned search; per-school SLA tuning
- Assumptions/Dependencies: Label quality sufficient to learn local correlations
- Sector: Operations/SRE
- What: SLA guardrails and autoscaling signals from predicted per-query cost
- Tools/Workflows: Use E2E predictions in queueing/scheduling; preemptively scale when predicted budgets surge
- Assumptions/Dependencies: Telemetry pipeline to export predicted cost; policy to override budget on business-critical queries
- Sector: Energy/Green Computing (cross-cutting)
- What: Reduce compute and power for filtered ANN workloads by 2–3× at same recall
- Tools/Workflows: Track NDCs and power per query; report energy savings for sustainability KPIs
- Assumptions/Dependencies: Distance computations dominate energy; minimal estimator overhead
Long-Term Applications
These require further research, system support, or scaling beyond the paper’s scope.
- Sector: Database Systems
- What: Cost-based optimizer for hybrid vector + relational queries (joins, group-by, multi-attribute filters) using local correlation
- Tools/Workflows: Extend E2E features into full query plans; integrate with CBOs in Postgres/ClickHouse extensions
- Assumptions/Dependencies: Cardinality estimation across vector proximity; calibrated multi-operator cost models
- Sector: Index Design
- What: Correlation-aware index construction (filter-friendly graph rewiring, per-attribute subgraphs)
- Tools/Workflows: Build auxiliary edges for underrepresented filter regions; switch dynamically between POST and PRE in safe regions
- Assumptions/Dependencies: Offline analysis of attribute–vector correlations; safeguards to avoid graph disconnectivity
- Sector: Multi-Index/Federated Retrieval
- What: Router that predicts which shard/index/filter combination yields minimal cost for each query
- Tools/Workflows: Shard-level ρ_local predictors; learned federation strategies
- Assumptions/Dependencies: Consistent telemetry across shards; cross-shard drift handling
- Sector: Adaptive SLAs and Pricing
- What: Per-query pricing or priority based on predicted cost; fairness across tenants
- Tools/Workflows: Tokens/credits charged per predicted NDC; dynamic queues classed by cost
- Assumptions/Dependencies: Predictive accuracy acceptable for billing; governance around fairness and bias
- Sector: Privacy-Preserving Retrieval
- What: Early-probe–based cost estimation under encryption or access-control (e.g., searchable encryption, ABAC)
- Tools/Workflows: Design privacy-safe proxies of ρ_pilot/ρ_queue; secure MPC or TEEs for feature extraction
- Assumptions/Dependencies: Acceptable overhead of crypto/TEE; no leakage via correlation signals
- Sector: On-device/Edge Vector Search
- What: Battery-aware early termination for mobile camera search and personal photo retrieval with date/location filters
- Tools/Workflows: TinyGBDT or distilled models; hardware counters for energy per query; dynamic budgets per power state
- Assumptions/Dependencies: Memory-constrained indexes; intermittent connectivity for model refresh
- Sector: Robotics/Autonomy
- What: Retrieval of similar scenes/keyframes with task/time filters for navigation and manipulation memory systems
- Tools/Workflows: Integrate E2E into perception-memory modules to bound retrieval latency under safety constraints
- Assumptions/Dependencies: Real-time guarantees; embeddings stable under domain shift
- Sector: Continual/Streaming Learning
- What: Drift-aware cost predictor that retrains online as attribute distributions change
- Tools/Workflows: Lightweight online GBDT updates; drift detectors monitoring ρ_pilot residuals
- Assumptions/Dependencies: Safe and explainable hot-reloads; rollback mechanisms
- Sector: AutoML for Cost Models
- What: Automated feature selection and model selection for new datasets/filters
- Tools/Workflows: Pipelines that evaluate additional features (queue entropy, gradient of distances) and select best model class (GBDT vs shallow NN)
- Assumptions/Dependencies: Sufficient labeled queries; reproducible training environment
- Sector: Benchmarks and Standardization (Academia/Industry)
- What: Standard tasks and datasets that stress local correlation vs global selectivity for filtered ANN
- Tools/Workflows: Extend ANN-Benchmarks with filtered tracks; publish feature–cost ground truth; leaderboard for early termination
- Assumptions/Dependencies: Community consensus on metrics (NDCs, P95 latency at fixed recall)
- Sector: Responsible/Policy
- What: Governance around attribute–embedding correlations (fairness, leakage) in retrieval systems
- Tools/Workflows: Policy requiring tests for sensitive correlations; disclosure of estimator behavior; energy-efficiency reporting
- Assumptions/Dependencies: Organizational maturity for ML governance; access to audit datasets
Cross-cutting assumptions and dependencies to consider
- Training data: Needs representative query–filter distributions; periodic refresh for drift.
- Index type: Benefits are clearest for graph-based ANN with POST filtering; other indexes (IVF, PQ) require adaptation of runtime features.
- Target recall and SLAs: Predictions must be calibrated to the recall target; provide safe fallback (e.g., cap minimum budget).
- Telemetry and overhead: Must collect queue/visited statistics with negligible overhead; preserve privacy in logs.
- Portability: Models are dataset/index-specific; expect per-corpus calibration and A/B validation.
- Robustness: Provide guardrails for worst-case anti-correlated filters; enable overrides for mission-critical queries.
- Compliance: Ensure access-control predicates are enforced before adding to result sets; audit feature usage for privacy.
Glossary
- Adaptive Early Termination: A technique that ends the search early based on predicted convergence to reduce computation and latency. Example: "To address this, prior work has proposed adaptive early termination."
- AKNN (Approximate k Nearest Neighbor): A class of algorithms that retrieve near neighbors efficiently by trading exactness for speed. Example: "A critical instance of this paradigm is filtered Approximate Nearest Neighbor (AKNN) search"
- Attributed Vector Dataset: A dataset where each vector is paired with attribute(s) used for filtering during search. Example: "A data item in an attributed vector dataset is defined as "
- Beam Search: A search strategy that maintains a fixed-size set of the best candidates while exploring neighbors. Example: "For AKNN search, beam search is used to acquire more than one result."
- Beam Width: The fixed size of the candidate set maintained during beam search. Example: "It maintains a queue containing the top- closest candidates during traversal, where is the beam width."
- Coefficient of Determination (R2): A regression metric measuring the proportion of variance explained by a model. Example: "we use the Coefficient of Determination () to measure regression quality"
- Curse of Dimensionality: The phenomenon where high-dimensional spaces make exact search methods computationally infeasible. Example: "Exact Nearest Neighbor search often suffers from the curse of dimensionality"
- DARTH: A learned, runtime-signal-based method for adaptive early termination in ANN graph search. Example: "State-of-the-art techniques such as LAET~\cite{LAET-SIGMOD-2020} and DARTH~\cite{DARTH-SIGMOD-2026} employ lightweight machine learning models"
- Early Probe: An initial, short traversal designed to collect local, filter-aware features with negligible overhead. Example: "Our early probe is simply the first steps of the actual query execution."
- efsearch: A HNSW parameter controlling the search queue size (effort) during traversal. Example: "setting a large global search queue size parameter such as efsearch~\cite{HNSW-PAMI-2020}"
- Feature-Filter Misalignment: A condition where vector proximity is poorly aligned with filter validity, misleading convergence signals and increasing cost. Example: "we formally define the Feature-Filter Misalignment problem"
- Filter Predicate: A boolean function that determines whether a data item satisfies the query’s filter constraint. Example: "To determine whether a data item satisfies a query, we formally define the concept of a Filter Predicate."
- GBDT (Gradient Boosting Decision Tree): An ensemble learning method that builds additive decision trees to model complex relationships. Example: "For our cost estimator model, we choose a Gradient Boosting Decision Tree (GBDT)"
- Global Selectivity: The probability that a random item in the entire dataset satisfies the filter condition. Example: "Global Selectivity (): When (the entire dataset), represents the overall probability that a random object satisfies the filter."
- Greedy Routing: The initial ANN graph-search phase that iteratively moves to closer neighbors to find an approximate top-1. Example: "The complexity of this greedy routing phase is generally logarithmic with respect to the dataset size"
- HNSW (Hierarchical Navigable Small World): A high-performance graph-based index for ANN with hierarchical layers. Example: "Advanced structures like HNSW~\cite{HNSW-PAMI-2020} and HVS~\cite{HVS-VLDB-2021-kejing-lu} further optimize this phase"
- HVS: A sparse navigational graph structure that optimizes greedy descent in ANN search. Example: "Advanced structures like HNSW~\cite{HNSW-PAMI-2020} and HVS~\cite{HVS-VLDB-2021-kejing-lu} further optimize this phase"
- IVF (Inverted File Index): A partitioned vector index where the nprobes parameter controls the number of partitions scanned. Example: "efsearch of HNSW, nprobes of IVF"
- LAET: A lightweight learning-based estimator that predicts convergence for early termination using runtime features. Example: "State-of-the-art techniques such as LAET~\cite{LAET-SIGMOD-2020} and DARTH~\cite{DARTH-SIGMOD-2026} employ lightweight machine learning models"
- LightGBM: A fast, optimized GBDT framework used for low-latency cost estimation. Example: "We specifically implement our estimator using LightGBM"
- Local Correlation: The selectivity of valid items within the query’s local neighborhood, capturing filter-vector dependence. Example: "Local Correlation (): When corresponds to a proximity neighborhood of (e.g., the top- nearest neighbors based on vector distance), represents the local query-filter correlation."
- Mean Squared Error (MSE): A loss function minimized during regression to fit predictions to targets (here, in log-space). Example: "The model is trained to predict by minimizing the Mean Squared Error (MSE) in the log-space"
- Mean Squared Logarithmic Error (MSLE): A loss emphasizing relative error, equivalent to MSE in log-space. Example: "minimizing MSE in the log-space is mathematically equivalent to minimizing the Mean Squared Logarithmic Error (MSLE) in the original space."
- Number of Distance Computations (NDC): A hardware-agnostic metric counting distance evaluations performed during search. Example: "We quantify the total computational cost, denoted as , by the Number of Distance Computation (NDC) performed during the filtered search for ."
- POST Filtering Strategy: A filtered search approach that traverses all candidates but only keeps those matching the filter. Example: "The $\POST$ strategy, widely adopted in industry~\cite{hnswlib,Diskann-NIPS-2019,HNSW-PAMI-2020}, traverses the full graph but only adds candidates satisfying the filter to the result queue."
- PRE Filtering Strategy: A filtered search approach that prunes traversal by skipping nodes failing the filter constraint. Example: "Conversely, $\PRE$ strategies restrict the search space by logically removing filtered nodes or edges during traversal."
- RAG (Retrieval-Augmented Generation): Systems that augment LLM generation with retrieved nearest neighbors or documents. Example: "retrieval-augmented generation (RAG) systems for LLMs"
- Recall@: A quality metric measuring the fraction of ground-truth top-k neighbors retrieved. Example: "Quality is measured by Recall@, defined as the proportion of the true top- ground-truth neighbors retrieved."
- Search Budget: The configured or predicted amount of computation allocated to a query’s search. Example: "The naive method sets a relatively large search budget for the filtered AKNN query to guarantee both accuracy and sufficient results."
- Selectivity: The proportion of items satisfying a filter within a given data scope. Example: "the selectivity measures the proportion of items in that satisfy the filter condition"
- Selectivity Estimation: Techniques for predicting filter selectivity to guide query optimization. Example: "While selectivity estimation~\cite{SE-probalistic-SIGMOD-2001,SE-range-predicae-VLDB-2019} has been studied for decades, directly adapting traditional techniques to filtered AKNN search presents fundamental challenges:"
Collections
Sign up for free to add this paper to one or more collections.

