- The paper introduces a GPU-native, codebook-free quantization method integrated with IVF clustering to accelerate ANN search while reducing storage needs.
- It employs a two-stage pipeline with coarse and refinement phases, achieving up to 2.2× higher QPS and 7.7× faster index build times compared to state-of-the-art methods.
- Innovative GPU kernel fusion and optimized data layouts minimize global memory traffic, enabling scalable, high-recall retrieval in high-dimensional vector search.
IVF-RaBitQ (GPU): GPU-Native Cluster-Based ANN Search with RaBitQ Quantization
Introduction and Problem Context
Approximate Nearest Neighbor Search (ANNS) is foundational for high-dimensional vector search in domains such as retrieval-augmented generation, recommender systems, and semantic retrieval. Traditional approaches bifurcate into graph-based and cluster-based paradigms. On GPUs, graph-based methods (e.g., HNSW, CAGRA) deliver high recall but at the expense of storage and build efficiency. Cluster-based approaches, notably IVF-PQ, offer efficient index build and adaptability, but often necessitate reranking and incur bandwidth bottlenecks at high recall, especially when using product quantization.
IVF-RaBitQ (GPU) (2602.23999) presents a GPU-native cluster-based ANN indexing and search solution tightly integrating IVF partitioning with RaBitQ vector quantization. The system achieves improvements in throughput, build time, storage footprint, and recall, leveraging architectural and algorithmic innovations tailored for GPU compute and memory hierarchies.
System Design and Algorithmic Innovations
IVF-RaBitQ is architected as a two-stage pipeline: a highly parallelized index build phase and a batched, pipelined search phase.
Index Build: GPU-Optimized RaBitQ Quantization
Following standard Balanced K-means, database vectors are assigned to IVF clusters, normalized, and rotated via a shared orthogonal matrix. Key to RaBitQ is the absence of codebook training. Instead, quantization involves searching over rescaling factors and identifying the nearest code in an analytic codebook defined by per-dimension bit budgets. Recognizing the inefficiency of CPU-optimized, warp-divergent quantization routines, the authors implement a two-phase parallel grid search:
- Coarse phase: parallel evaluation of grid-sampled rescaling factors across dimensions.
- Refinement phase: narrowed search around the optimal candidate from the coarse phase.
This block-per-vector mapping strategy maximizes GPU parallelism and memory coalescing, enabling quantization of over one million 960-dimensional vectors/s at 8-bit precision.
Search Pipeline: Fused Cluster-Local Kernels
Given a query batch, each vector is rotated, and the nearest clusters are selected by fast centroid distance computation. Search is then scheduled as a set of (query, cluster) pairs, enabling fine-grained parallelism. Each search proceeds via a two-stage estimator:
- Stage 1 (Filter): compute lower bounds using 1-bit RaBitQ codes, implemented using two alternative GPU-native inner-product methods.
- Stage 2 (Refinement): apply ex-codes only to survivors from the filter stage for full-precision distance estimation.
This logical flow is fused into a single CUDA kernel, minimizing global memory traffic and kernel launch overhead. Careful shared memory reuse is orchestrated across pipeline stages, minimizing SM residency bottlenecks.

Figure 1: Bitwise inner-product computation between 1-bit RaBitQ codes and B-bit quantized queries via bitwise and POPCNT operations.
GPU-Native Inner Product Computation
The innermost kernel operation is the asymmetric inner product between a floating-point (or quantized) query and compressed 1-bit codes. IVF-RaBitQ implements two alternatives:
- Lookup Table (LUT) Strategy: Inner products are recast as lookups from 2U-entry tables, trading arithmetic for shared-memory bandwidth. Optimal for moderate dimensions.
- Bitwise Decomposition: Queries are quantized. Inner products reduce to combinations of AND and POPCNT instructions across register-packed data, allowing efficient SIMD execution and high parallelism on wide registers, essential for high dimensions.
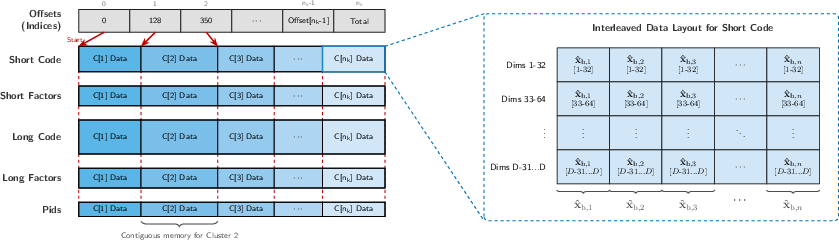
Index Layout and Data Organization
To maximize global memory bandwidth, IVF-RaBitQ employs a CSR-inspired, cluster-major format. Data is decomposed into contiguous arrays:
This layout is tightly coupled to the fused kernel's access patterns, ensuring high L1/L2 cache hit rates and maximizing parallel memory throughput.
Empirical Evaluation
Experiments span diverse datasets (ImageNet, CodeSearchNet, GIST, OpenAI/text, Wiki-all) and contrast IVF-RaBitQ against IVF-Flat, IVF-PQ, and CAGRA.
Time–Accuracy Trade-off
IVF-RaBitQ consistently defines the Pareto frontier, attaining up to 2.2× the QPS of CAGRA and up to 31.4× IVF-PQ (without refinement) throughput at Recall ≈ 0.95, without reranking or storing RAW vectors.
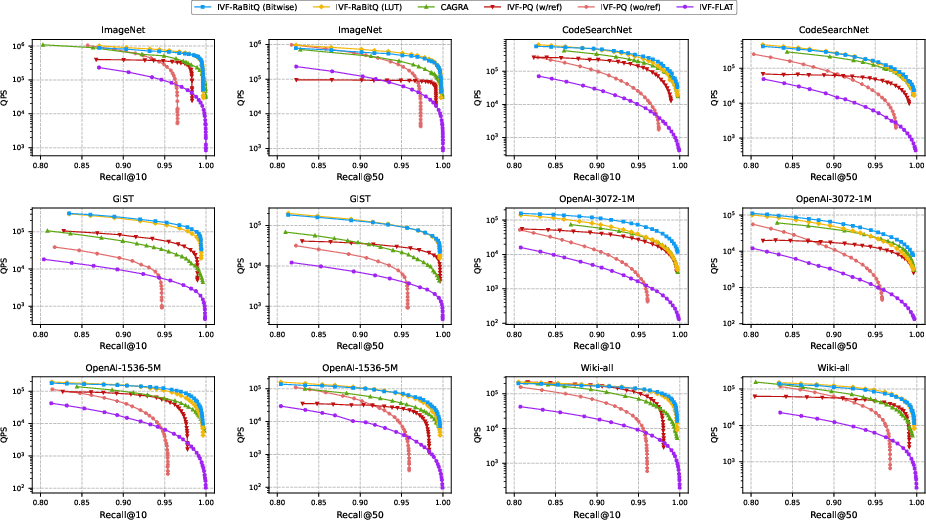
Figure 3: IVF-RaBitQ surpasses cluster- and graph-based competitors in QPS at high recall across datasets and quantization strategies.
Bitwise and LUT modes achieve comparable speed; bitwise scales more effectively with dimensionality (see OpenAI-3072 results for pronounced divergence).
Index Build Time
Thanks to codebook-free RaBitQ and an O(1)-round parallel quantization routine, build time for IVF-RaBitQ is on average 7.7× faster than CAGRA and 4.4× faster than IVF-PQ.

Figure 4: Indexing times show significant build acceleration for IVF-RaBitQ compared to IVF-PQ and CAGRA.
By obviating the need for storing and reranking raw vectors, IVF-RaBitQ indexes consume <25% of the storage of CAGRA or IVF-PQ with refinement at equivalent recall. For 10M-vectors (768d Wiki-all), IVF-RaBitQ requires only 7.5GB compared to >30GB for graph-based or reranking methods.

Figure 5: Storage requirement comparisons among indexing techniques. IVF-RaBitQ achieves strong efficiency due to fully quantized search.
IVF-RaBitQ exposes a flexible knob (bit-depth per dimension) for trading off recall against storage and throughput. 5 bits/dimension suffices for Recall>0.95 in standard setups; 1-bit mode suffices for sub-0.6 recall with maximal QPS.
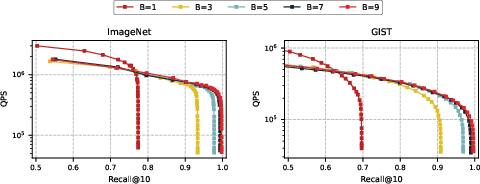
Figure 6: IVF-RaBitQ recall and throughput as a function of quantization bits, enabling adaptive deployment under diverse memory/accuracy constraints.
GPU vs. CPU
Direct comparison against RaBitQLib (a high-efficiency CPU system) reveals 12.5–13.0× QPS speedups on comparable hardware at matching accuracy.
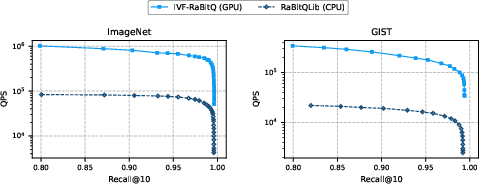
Figure 7: IVF-RaBitQ (GPU) vs. RaBitQLib (CPU): order-of-magnitude QPS gains from optimized GPU-native implementation.
Implications and Future Directions
IVF-RaBitQ (GPU) demonstrates that codebook-free quantization can be effectively adapted to highly parallel architectures, rectifying the historical limitations of cluster-based GPU ANN search at high recall and constrained memory. The combination of analytic quantization, index/data layout co-design, and kernel fusion provides a compelling alternative to graph-based methods, especially when rapid index construction and small memory footprints are priorities. Eliminating RAW vector storage and search reranking pipeline dramatically simplifies deployment in production ANN serving.
Theoretically, the work underscores the continued relevance of analytic quantization with strong error guarantees for high-dimensional search. Practically, it paves the way for RaBitQ-based quantization or similar methods to become a mainstay in vector database backends, particularly as embedding dimensionality and dataset sizes continue to scale in modern AI workflows.
Future extensions may explore hybrid index structures combining IVF-RaBitQ with compact proximity graphs for adversarial queries, advanced fusion of code-based and learned quantization, or tight integration with attribute-filtered search and multimodal deployments.
Conclusion
IVF-RaBitQ (GPU) leverages GPU-native algorithm and data layout co-design to enable cluster-based ANN search that is competitive in recall and throughput with state-of-the-art graph-based methods, while being superior in index build time and storage efficiency. The core contribution is showing that analytic, codebook-free quantization (RaBitQ) can be implemented efficiently and scalably for GPU architectures, delivering practical performance advantages across regimes relevant to industry-scale vector search and retrieval systems.