Retrieve and Segment: Are a Few Examples Enough to Bridge the Supervision Gap in Open-Vocabulary Segmentation?
Abstract: Open-vocabulary segmentation (OVS) extends the zero-shot recognition capabilities of vision-LLMs (VLMs) to pixel-level prediction, enabling segmentation of arbitrary categories specified by text prompts. Despite recent progress, OVS lags behind fully supervised approaches due to two challenges: the coarse image-level supervision used to train VLMs and the semantic ambiguity of natural language. We address these limitations by introducing a few-shot setting that augments textual prompts with a support set of pixel-annotated images. Building on this, we propose a retrieval-augmented test-time adapter that learns a lightweight, per-image classifier by fusing textual and visual support features. Unlike prior methods relying on late, hand-crafted fusion, our approach performs learned, per-query fusion, achieving stronger synergy between modalities. The method supports continually expanding support sets, and applies to fine-grained tasks such as personalized segmentation. Experiments show that we significantly narrow the gap between zero-shot and supervised segmentation while preserving open-vocabulary ability.


































































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Imagine you’re trying to color every pixel in a photo so that each part is labeled correctly: sky, tree, bike, person, etc. That job is called semantic segmentation. Most current systems do this well only for a fixed list of classes they were trained on and need tons of detailed, hand-drawn labels.
This paper wants something more flexible: a system that can segment anything you ask for with words, like “motorcycle” or even a new, unusual object. That’s called open-vocabulary segmentation (OVS). The authors introduce a method called FreeDom that combines the power of language (class names or short descriptions) with a tiny number of labeled picture examples to make much better pixel-level predictions, even when not everything is fully labeled.
What questions the paper asks
Here are the main questions they explore:
- Can adding just a few example images with pixel-level labels per class help close the performance gap between “zero-shot” systems (that use only words) and fully supervised systems (that use lots of labels)?
- How can we mix both types of information—words and pictures—so they help each other instead of getting in the way?
- Can the system still work well when some classes are missing picture examples or even missing names?
- Can we keep adding new examples over time and get better without retraining everything from scratch?
How their method works (with everyday analogies)
Think of three ingredients:
- Strong general knowledge They start with a big vision–LLM (like CLIP or DINOv3.txt). This is like a student who’s read millions of image–caption pairs and learned a shared “language” where pictures and words live in the same space. That lets the model compare an image patch to a word directly.
- Two kinds of support (hints)
- Textual support: class names or short descriptions (like “motorcycle”).
- Visual support: a small set of example images where the correct pixels are already colored in (labeled).
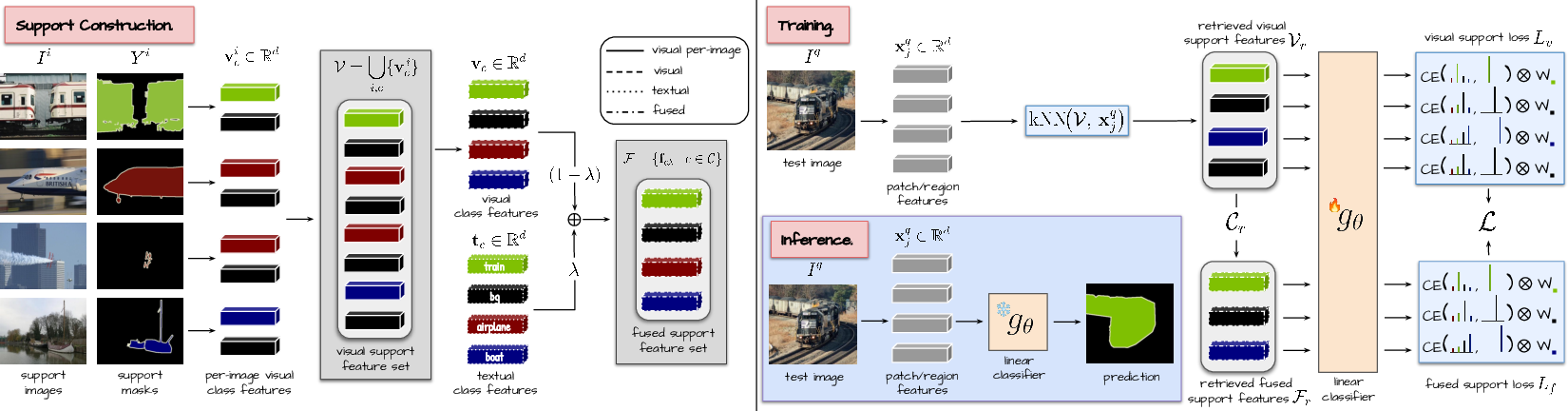
- A quick “mini-learner” trained at test time Right before making predictions on a new photo, FreeDom trains a tiny classifier just for that photo. It does this fast (under a second on a big GPU) and doesn’t change the backbone model.
Here’s the step-by-step idea:
- Step A: Retrieve helpful examples For the new photo, FreeDom looks up which stored visual examples are most similar (like asking a librarian to fetch flashcards that look like your current photo). These “nearest neighbors” are compact features extracted from the few labeled images you have.
- Step B: Fuse words and pictures smartly Words are great for naming things but can be vague; pictures are precise but you might have only a few. FreeDom blends the text features with the visual features for each class using a learned mix, creating “fused” class features that capture the best of both.
- Step C: Train a tiny classifier for this one photo Using the retrieved examples (visual) and the fused features (text+visual), FreeDom trains a simple linear classifier that maps the image’s patches to class labels. It also downweights classes that are unlikely to appear in the photo, based on how well the class name matches the whole image.
- Step D: Make predictions on patches or regions
- Patch-level: small square chunks from the vision model, or
- Region-level: bigger, cleaner shapes suggested by a tool like SAM (Segment Anything), which often improves accuracy.
- Handling missing pieces:
- If some classes have no visual examples yet, FreeDom can guess which classes are present using the text-only model, create “pseudo” features from the current photo, and still do its fusion step.
- If some classes don’t even have names (hard domains like medical images), it uses a neutral text placeholder so those classes aren’t ignored.
- Keep growing over time When new labeled examples arrive, FreeDom just adds their features to its small memory and gets better, without a full retrain.
What they found and why it matters
- Big gains with few examples: With only 1 labeled image per class, FreeDom improves mean Intersection-over-Union (mIoU, a standard overlap score for segmentation) by about 7–18 percentage points over using text alone, depending on the backbone model. In short, a tiny bit of visual support goes a long way.
- Better than other retrieval-based methods: FreeDom beats competing approaches that either use hand-crafted ways to combine text and visuals or rely only on nearest neighbors. Learned fusion and per-image adapting make the difference.
- Works even when support is incomplete: If some classes don’t have visual examples yet, FreeDom’s performance drops gracefully, not suddenly. Its pseudo-label trick helps it still use text and the current image to fill in the gaps.
- Scales with stronger encoders and region proposals: Using more modern visual features (like DINOv3.txt) and region proposals from SAM further boosts accuracy. Region-based predictions usually beat raw patch-based ones.
- Efficient and memory-light: It stores compact features, adapts at test-time quickly, and doesn’t retrain the big model.
Why this matters: It narrows the gap between “fully supervised” systems (very expensive to label) and “zero-shot” systems (flexible but less accurate). You get the flexibility of open vocabulary with accuracy that approaches fully supervised models—using only a few examples.
What this could change in the real world
- Less labeling, more flexibility: Teams can start with text-only segmentation and steadily add a few labeled examples for tricky classes to quickly improve results—no huge training runs needed.
- Adapts to new classes on the fly: As new categories appear in the wild, you can add them with a name, then a few labeled images, and FreeDom will incorporate them without forgetting old ones.
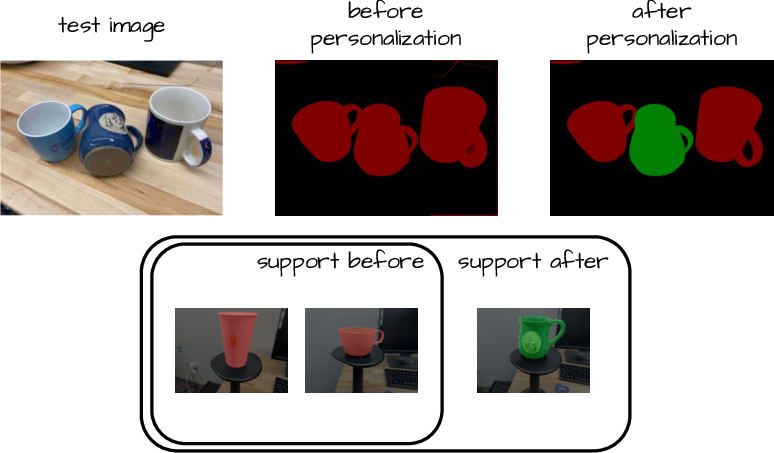
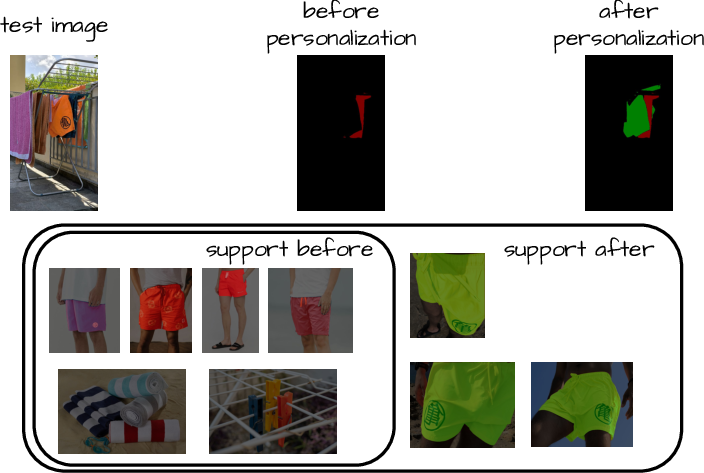
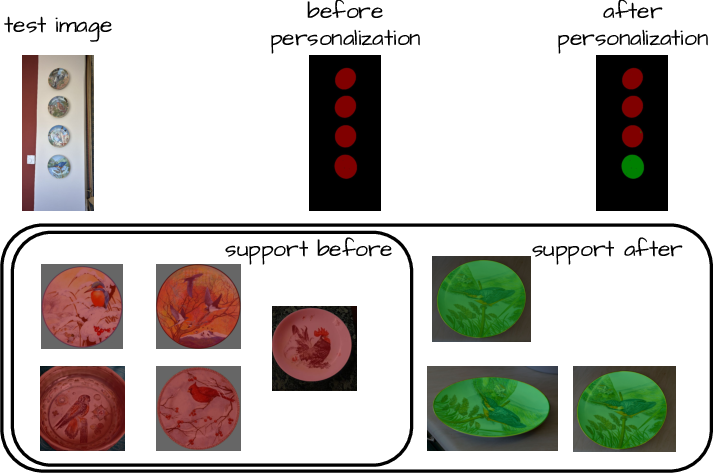
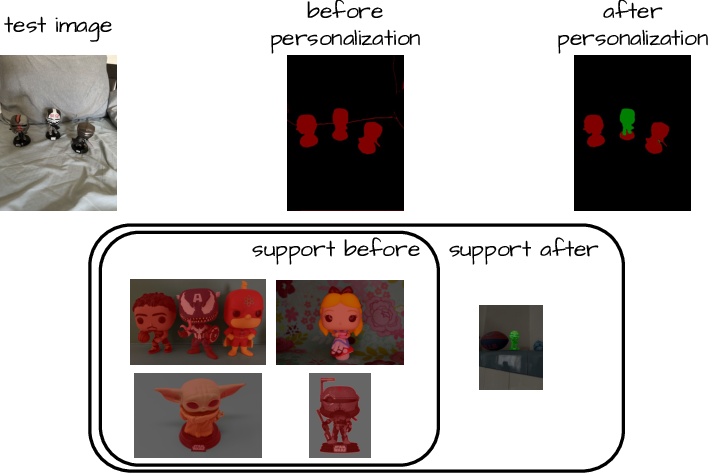
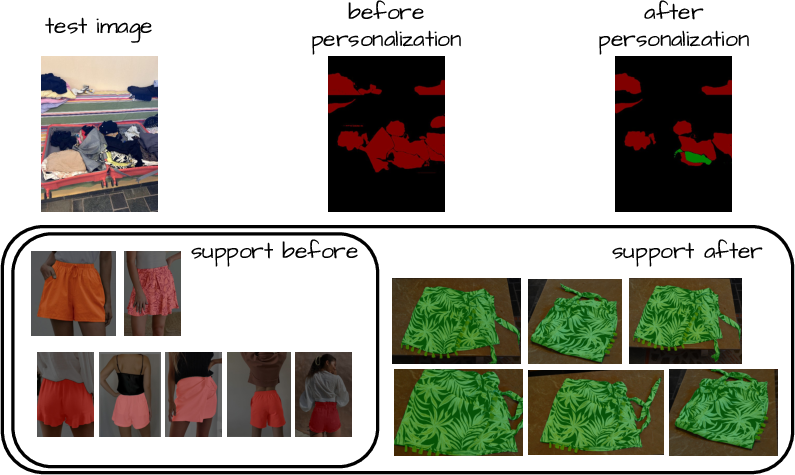
- Personalized segmentation: You can teach the system to find very specific things (your bike, your pet) with only a handful of examples.
- Applicable to specialized domains: In fields where names or examples are hard to get (like medical imaging), FreeDom’s ability to work with partial support and pseudo-labeling can still help.
In short, this paper shows that smartly retrieving a few good examples and learning a tiny, per-image adapter—while blending text and visuals—can make open-vocabulary segmentation both practical and powerful.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a focused list of what remains uncertain or unexplored in the paper and would benefit from targeted future work:
- Scaling and retrieval efficiency: The method relies on per-query kNN over a growing repository of per-image class features, but there is no analysis of retrieval indexing (e.g., approximate nearest neighbor), update cost under continual expansion, memory footprint at scale (classes × shots × datasets), or latency on commodity hardware versus A100.
- Hyperparameter sensitivity and autotuning: The impact and selection procedures for k (neighbors), the mixing set Λ, and loss weights (β_f, β_p) are not systematically explored; no guidelines are given for cross-dataset or per-image adaptive tuning.
- Robustness to noisy or imperfect support annotations: The approach assumes accurate pixel-level support; effects of label noise, coarse masks, class-imbalance in support, or heterogeneous annotation styles are not studied.
- Reliability of pseudo-labeling for unsupported classes: Pseudo-labels are derived from zero-shot predictions, but the method does not analyze error propagation, confidence calibration, or mechanisms (thresholds, filtering) to prevent reinforcing incorrect pseudo-labels.
- Weak handling of missing textual support: Replacing absent textual features with the mean text embedding is a crude surrogate; the paper does not explore stronger alternatives (auto-generated descriptions, retrieval of synonyms, captioning, or cross-modal bootstrapping) or quantify the degradation across varied text-missing regimes.
- Open-world discovery beyond the provided class set: While the approach preserves open-vocabulary input, it still requires a predefined class list per image; there is no mechanism for discovering, naming, or segmenting completely unknown classes beyond the supplied set C.
- Dependence on SAM-based proposals: Region-level gains rely on SAM 2.1; sensitivity to proposal quality, mask density, overlapping proposals, and failure cases (small objects, thin structures, rare textures) is not quantified, nor is the added computational budget vs. patch-only predictions characterized.
- Generalization across backbones and training corpora: Experiments use OpenCLIP ViT-B/16 and DINOv3.txt; behavior with stronger or different VLMs (e.g., SigLIP, EVA-CLIP, CLIP-L/14, Florence-2) and the interaction with their localization biases remains untested.
- Domain and modality shifts: Claims of applicability to specialized domains (e.g., medical, remote sensing) are not validated; cross-domain transfer, cross-lingual prompts, and robustness to domain shift or long-tail class distributions are unaddressed.
- Continual support management policies: Although support is “dynamically expandable,” the work lacks strategies for prototype pruning, deduplication, or reweighting under drift; the effect of ever-growing memory on precision/recall and retrieval noise is unknown.
- Class relevance weighting (w_c) limitations: The image-level similarity used for class weighting may be dominated by large/frequent classes or co-occurring context; no study examines alternative weighting schemes (e.g., region-aware, entropy-based) or multi-label calibration.
- Fusion mechanism capacity: Fusion is a fixed linear blend between visual and textual features with a hand-picked set Λ; learning λ per class/image, non-linear fusion, or attention-based fusion is not explored, nor is the theoretical justification for the current choice.
- Instance- and fine-grained segmentation: Although the paper claims applicability to personalized segmentation, dedicated evaluations (e.g., per-instance IDs, user-specific objects across scenes) and analyses of intra-class fine-grained distinctions remain limited or absent.
- Small object and boundary quality: The method reports mIoU but does not analyze boundary accuracy, small-object performance, or structured error patterns (e.g., per-class confusion matrices), leaving fine localization behavior unclear.
- Failure mode characterization: There is no systematic study of when retrieval harms performance (e.g., visually similar but semantically different neighbors, background prototypes), how often negative transfer occurs, or how to mitigate it.
- Closed-set “offline” comparisons: While offline baselines are provided, the exact gap to strong fully supervised decoders on each dataset and the number of support examples needed to match them are not quantified, leaving unanswered how far few-shot support can realistically close the gap.
- Resource and deployment considerations: Beyond a single runtime claim on an A100, there is no profiling of memory/latency trade-offs, energy use, or feasibility on edge devices; the impact of support size on inference cost is not measured.
- Privacy and security: Storing visual prototypes from pixel-annotated images may raise privacy concerns (e.g., personalized data); methods for anonymization, compression, or federated/secure retrieval are not discussed.
- Retrieval granularity and prototype construction: The paper pools patch features to per-image class features; alternative constructions (e.g., region-level prototypes, multi-scale pooling, attention-weighted prototypes) and their effect on retrieval quality are not investigated.
- Prompt engineering and ambiguity: The influence of prompt phrasing, longer descriptions, disambiguation tokens, or cross-lingual prompts is not studied, despite the method’s reliance on text features for weighting and fusion.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s FreeDom method (retrieval-augmented, per-image test-time adapter for open-vocabulary segmentation that fuses textual and few-shot visual support). Each item includes sectors, potential tools/workflows, and feasibility dependencies.
- Rapid personalization in photo/video editing (e.g., segment “my dog,” “brand logo,” “custom prop” across assets)
- Sectors: media/creative software
- Tools/Workflows: plugin for Adobe/DaVinci/Resolve; pipeline that stores compact visual prototypes from a few annotated images, retrieves relevant support for each new frame/image, trains a per-image linear classifier (<1 s on A100), applies SAM-based region proposals for quality
- Assumptions/Dependencies: availability of CLIP/DINOv3-like features; SAM proposals for best accuracy; a few pixel-annotated frames; server/GPU or optimized inference stack
- E-commerce product asset pipelines (background removal and attribute-level segmentation for new categories)
- Sectors: retail/e-commerce, advertising tech
- Tools/Workflows: centralized “support feature store” fed by 1–5 labeled images per product attribute (e.g., “mesh panel,” “strap,” “ruffled sleeve”); API that returns masks per arbitrary text prompt; dynamic support expansion as new SKUs arrive
- Assumptions/Dependencies: consistent product imagery; minimal pixel-level annotation effort per new attribute; quality of textual prompts; compute for retrieval and per-image adaptation
- Manufacturing/quality control: few-shot segmentation of new defects/components
- Sectors: manufacturing, industrial inspection
- Tools/Workflows: on-line support update using small annotated batches from new defect types; retrieval from prototype memory; per-image classifier training for each inspected item; escalation to human-in-the-loop when confidence is low
- Assumptions/Dependencies: foundation model representation aligns with factory imagery; small set of pixel-level labels per defect; controlled lighting and capture; compute availability at the edge or server
- Warehouse automation and robotics: teach robots to segment new boxes/SKUs/bins with few examples
- Sectors: robotics, logistics
- Tools/Workflows: robot vision stack integrates a support feature index; operators add a handful of annotated images; textual prompts provide class names; per-frame adaptation to scene
- Assumptions/Dependencies: reliable feature extraction on robot hardware or offloaded compute; SAM proposals optional; latency budget for per-frame adaptation
- Retail shelf analytics and planogram compliance
- Sectors: retail analytics
- Tools/Workflows: store 1–5 labeled exemplars per brand/packaging; segment shelves at scale with open-vocabulary prompts (e.g., “juice carton with green cap”); continuous support expansion for new products
- Assumptions/Dependencies: decent product image quality; minimal shots per product; compute for retrieval and per-image training; plan for ambiguous class names
- Construction and asset monitoring (new equipment types, PPE variants)
- Sectors: construction tech, safety/compliance
- Tools/Workflows: upload a few annotated images per new equipment; segment across site footage; alerts for missing PPE using textual + visual support
- Assumptions/Dependencies: variable conditions and occlusions; foundation model robustness; policy compliance (privacy) when storing prototypes
- Wildlife and conservation: individualized/personalized segmentation of animals with few labeled frames
- Sectors: environmental monitoring, ecology
- Tools/Workflows: support store per individual/species; few annotated frames per camera trap; segment across footage for behavior/occupancy studies
- Assumptions/Dependencies: domain shift relative to web pretraining; quality of region proposals; sufficient variability in few examples
- Dataset bootstrapping and active learning for annotation
- Sectors: academia, data services, ML ops
- Tools/Workflows: start from text-only zero-shot; add 1–3 pixel-labeled examples; run FreeDom to generate masks; curate with humans; iterate; store prototypes for new classes
- Assumptions/Dependencies: active learning loop; annotation tooling; quality control to avoid propagation of early errors
- Privacy-conscious deployments via prototype storage (instead of raw images)
- Sectors: enterprise IT, regulated industries
- Tools/Workflows: maintain only compact per-class visual prototypes and fused features; delete raw support images after extraction; audit prototype bank updates
- Assumptions/Dependencies: internal privacy policies; acceptable risk of re-identifiability from feature vectors; secure retrieval service
- Cloud microservice for few-shot open-vocabulary segmentation
- Sectors: software/platforms
- Tools/Workflows: REST/gRPC API: “POST class name + 1–5 annotated images; GET masks for new images”; internal index for feature retrieval + SAM-based region-level inference; autoscaling
- Assumptions/Dependencies: GPUs for per-image training; storage for feature indices; SLAs on latency; prompt library for canonical class names
- Research prototyping and benchmarking in open-world segmentation
- Sectors: academia, R&D labs
- Tools/Workflows: use the released code to study retrieval augmentation, per-image TTA, partial-support settings; integrate with new VLMs/SAM variants; experiment with personalized segmentation
- Assumptions/Dependencies: familiarity with PyTorch/VLMs; compute; dataset licensing
Long-Term Applications
These opportunities require further research, scaling, or engineering (e.g., stronger domain-aligned backbones, on-device acceleration, regulatory validation).
- Real-time on-device personalized segmentation for AR glasses and smartphones
- Sectors: AR/VR, mobile
- Tools/Workflows: optimized per-frame retrieval and adaptation on-device; lightweight proposal generation without SAM or with distilled proposals; streaming support set updates
- Assumptions/Dependencies: efficient on-device VLMs; energy/latency constraints; compact feature indices; privacy-preserving local learning
- Open-world segmentation for autonomous vehicles with safety certification
- Sectors: automotive, robotics
- Tools/Workflows: continual support expansion for new hazards (temporary signs, construction cones); validated fallback when classes lack support; redundancy across sensors
- Assumptions/Dependencies: certifiable behavior; robustness under severe domain shift and weather; real-time guarantees; safety and regulatory approval
- Medical imaging for rare pathologies or device artifacts (few pixel-labeled scans)
- Sectors: healthcare
- Tools/Workflows: clinician-in-the-loop curation of a small support set per pathology; per-scan adaptation; pseudo-labels where names are ambiguous; integration with PACS
- Assumptions/Dependencies: domain-aligned foundation models for medical data (not generic CLIP); strict privacy; clinical validation; regulatory clearance
- Remote sensing and GIS: open-vocabulary land-use/land-cover segmentation across geographies
- Sectors: mapping/GIS, climate, agriculture
- Tools/Workflows: few-shot support per region-specific class (e.g., “terraced fields,” “solar farm type X”); cross-sensor fusion; prototype banks per geography
- Assumptions/Dependencies: VLMs tailored to satellite/aerial imagery; alignment between text and domain semantics; varying sensor resolutions
- Consumer home robots that continuously learn new objects/tasks from few examples
- Sectors: consumer robotics, smart home
- Tools/Workflows: user adds a few labeled images (“my mug,” “recycling bin”); robot segments and manipulates objects; shared household prototype bank
- Assumptions/Dependencies: reliable perception under clutter; safe learning; efficient adaptation on embedded hardware; UX for labeling
- Federated or privacy-preserving “prototype banks” across organizations
- Sectors: enterprise/consortia, public sector
- Tools/Workflows: encrypted/federated exchange of visual/textual prototypes rather than raw images; shared open-world vocabularies with local adaptation
- Assumptions/Dependencies: homomorphic encryption or secure aggregation; interoperable feature standards; legal agreements and governance
- Standardized evaluation and policy frameworks for open-world, few-shot segmentation
- Sectors: policy, standards bodies, public procurement
- Tools/Workflows: benchmarks that include partial-support scenarios, continual support expansion, and retrieval latency constraints; data minimization (prototype-only retention) as a best practice
- Assumptions/Dependencies: stakeholder consensus; reproducible metrics; alignment with privacy regulations (e.g., GDPR)
- Energy-efficient, edge-first deployments (industrial IoT, drones)
- Sectors: energy, IoT, defense, agriculture
- Tools/Workflows: distill region proposals and VLM features; ANN indices tailored to low-power hardware; opportunistic/cloud-assisted adaptation
- Assumptions/Dependencies: model compression; approximate retrieval with accuracy guarantees; intermittent connectivity
- Cross-modal extensions (e.g., video-temporal or 3D instance segmentation with few-shot support)
- Sectors: film/VFX, robotics, autonomous systems
- Tools/Workflows: propagate fused support over time; integrate depth/LiDAR points; per-frame adaptation with temporal consistency constraints
- Assumptions/Dependencies: additional modalities; temporal stability mechanisms; extended training objectives
- Robustness auditing and monitoring for open-world systems
- Sectors: MLOps, compliance
- Tools/Workflows: monitor support coverage (which classes have text/visual support), retrieval quality, and drift; trigger human review when support is sparse or ambiguous
- Assumptions/Dependencies: observability tooling; thresholds for intervention; governance processes
Cross-cutting assumptions and dependencies
- Foundation model quality and domain match: Performance depends heavily on strong visual-language backbones (e.g., CLIP, DINOv3.txt) and, optionally, SAM proposals; significant domain shifts (e.g., medical, satellite) require domain-aligned models.
- Minimal pixel-level annotations: Even 1–5 examples per class yield strong gains, but some human labeling remains necessary.
- Compute and latency: The paper reports <1 s per-image training on an A100; edge/mobile deployments need optimization, caching, or cloud offload.
- Retrieval infrastructure: Requires building/maintaining a support feature index and class metadata; retrieval quality strongly affects outcomes.
- Text ambiguity: Text prompts can be ambiguous; FreeDom’s fusion helps, but careful prompt engineering or class descriptions may be needed.
- Privacy and governance: Storing compact prototypes reduces data retention versus raw images but still necessitates privacy assessment and secure handling.
Glossary
- ADE20K: A large-scale benchmark dataset for semantic segmentation of diverse scenes. "ADE20K~\cite{zhou2017ade20k} (ADE)"
- argmax: An operation that selects the index of the maximum value in a vector. "and segmentation is obtained by the of over classes."
- backbone: The core feature extractor network in a model, typically a pretrained encoder. "avoid retraining the backbone"
- Cityscapes: An urban-scene semantic segmentation dataset focused on street scenes. "Cityscapes~\cite{cordts2016cityscapes} (City)"
- closed world: An assumption that all test classes are known during training. "typically assuming a closed world."
- COCO Object: A subset of COCO focusing on object categories for segmentation. "COCO Object (Object)"
- COCO-Stuff: A dataset augmenting COCO with “stuff” labels (background classes). "COCO-Stuff~\cite{caesar2018cocostuff} (Stuff)"
- contrastive training: A learning paradigm that brings matched pairs (e.g., image–text) closer in embedding space and pushes mismatches apart. "contrastively trained visionâLLMs (VLMs)"
- cross-entropy loss: A standard classification loss measuring the divergence between predicted and true distributions. "using cross-entropy loss."
- CUB: A fine-grained bird classification/segmentation dataset (Caltech-UCSD Birds). "CUB~\cite{welinder2010cub}"
- DINOv3.txt: A text-aligned variant of DINOv3 that produces patch features aligned with text embeddings. "DINOv3.txt (ViT-L/16)"
- dense pixel-level annotations: Ground-truth labels for every pixel in an image. "trained on dense pixel-level annotations"
- few-shot: A setting where only a few labeled examples per class are available. "introducing a few-shot setting"
- fine-grained: Tasks requiring subtle distinctions between similar categories. "fine-grained tasks such as personalized segmentation."
- finetuning: Updating model weights on a target dataset after pretraining. "Offline finetuning on images and pixel-level annotations."
- FoodSeg103: A segmentation dataset focusing on food categories. "FoodSeg103 (Food)"
- foundation models: Large pretrained models serving as general-purpose backbones for downstream tasks. "frozen foundation models"
- fused class feature: A representation that blends textual and visual class features. "we create a fused class feature"
- global average pooling: Aggregating spatial features by averaging across spatial dimensions. "global average pooling"
- hand-crafted fusion: Heuristic, non-learned rules for combining modalities. "relying on late, hand-crafted fusion"
- i.i.d. streams: Data streams where samples are independently and identically distributed. "i.i.d. streams"
- in-context: Prompting a model with examples (images or text) at inference to guide predictions. "open-vocabulary (text-prompted) and in-context (image-prompted) segmentation"
- k-nearest neighbors: A non-parametric method using the closest k examples in feature space for classification. "the nearest neighbors"
- Kullback-Leibler divergence: A measure of how one probability distribution diverges from another. "Kullback-Leibler divergence."
- LAION: A large-scale image–text dataset used to train vision–LLMs. "LAION~\cite{schuhmann2022laion}"
- L1-normalized: Scaling vectors so that the sum of absolute values equals one. "-normalized per class (column)"
- lightweight classifier: A small-capacity model (e.g., linear layer) trained quickly for adaptation. "a lightweight classifier per test image."
- MaskCLIP trick: A technique to adapt CLIP features for segmentation by masking or spatializing features. "apply the MaskCLIP trick"
- mIoU: Mean Intersection over Union, a standard metric for segmentation accuracy. "We report the average mIoU"
- modality gap: The distributional mismatch between different data modalities (e.g., text vs. images). "due to the modality gap between visual and textual features in VLMs"
- non-maximum suppression: A post-processing step to remove redundant, overlapping detections or masks. "and non-maximum suppression to ensure non-overlap."
- non-overlap: A constraint ensuring predicted regions/masks do not spatially overlap. "to ensure non-overlap."
- non-parametric visual classifier: A classifier that uses stored exemplars without learning parameters (e.g., kNN). "forming a non-parametric visual classifier"
- open-vocabulary generalization: The ability to predict labels for classes not seen during training. "maintaining open-vocabulary generalization."
- open-vocabulary segmentation (OVS): Segmenting images into categories specified at test time via text, not fixed training labels. "Open-vocabulary segmentation (OVS)"
- open-world scenario: A setting where new classes and examples can appear over time. "a continually expanding open-world scenario."
- OpenCLIP: An open-source implementation of CLIP for vision–language pretraining and inference. "OpenCLIP ViT-B/16~\cite{cherti2023reproducible}"
- PASCAL Context: A semantic segmentation dataset extending PASCAL VOC with more labels. "PASCAL Context~\cite{mottaghi2014context} (Context)"
- PASCAL Context-59: A 59-class subset of PASCAL Context used for benchmarking. "PASCAL Context-59 (C-59)"
- PASCAL VOC: A classic object recognition and segmentation dataset. "PASCAL VOC~\cite{everingham2010pascal} (VOC)"
- patch-level feature: A feature vector extracted per image patch (token) from a transformer encoder. "patch-level feature matrix "
- per-image classifier: A model trained specifically for each test image rather than globally. "a lightweight, per-image classifier"
- personalized segmentation: Segmenting particular, user-specific objects or instances. "the so called personalized segmentation"
- pixel-level annotations: Labels provided at the pixel granularity for training or evaluation. "pixel-level annotations"
- prototypical methods: Few-shot techniques that classify by comparing to per-class prototype embeddings. "Meta-learning and prototypical methods"
- region-level features: Features pooled over proposed regions (masks) rather than individual patches/pixels. "region-level features"
- region proposals: Candidate mask regions hypothesized by a proposal method to guide segmentation. "When region proposals ... are available"
- retrieval-augmented: Incorporating retrieved examples or features at inference to improve prediction. "a retrieval-augmented test-time adapter"
- SAM 2.1: A version of the Segment Anything Model used to produce region proposals. "SAM 2.1~\cite{ravi2024sam2segmentimages}"
- self-supervised objectives: Learning signals without manual labels, such as consistency or reconstruction losses. "single-image TTA is explored with self-supervised objectives"
- shared embedding space: A space where different modalities (image, text) are mapped for direct comparison. "learn a shared embedding space"
- softmax: A function converting scores to probabilities that sum to one across classes. "where is the softmax over class set ."
- support set: A small collection of labeled examples provided for novel classes at test time. "a support set of pixel-annotated images."
- test-time adaptation (TTA): Adapting model parameters or heads at inference time using the test input (and possibly support). "Test-time adaptation (TTA) for VLMs has grown rapidly"
- test-time adapter: A module trained or adjusted at inference to steer predictions on a per-sample basis. "a retrieval-augmented test-time adapter"
- text prompts: Natural language inputs (class names/descriptions) guiding the model’s predictions. "augments textual prompts with a support set"
- transductive: An adaptation setting using the entire test batch distribution (as opposed to per-sample). "operate in batch/transductive or streaming modes"
- Vision Transformer (ViT): A transformer-based architecture for images that processes them as patch tokens. "vision transformer (ViT)"
- visual prototypes: Compact representative feature vectors per class derived from support images. "store only a compact set of visual prototypes"
- visual support: Labeled images (with masks) provided as examples for classes at test time. "visual support: a small set of pixel-annotated images"
- vision–LLMs (VLMs): Models jointly trained on images and text to align their representations. "visionâLLMs (VLMs)"
- zero-shot: Predicting labels for classes not seen during training using language or other priors. "zero-shot segmentation"
Collections
Sign up for free to add this paper to one or more collections.