- The paper introduces ConInfer, a training-free inference engine that integrates patch-wise VLM predictions with global context extracted by VFMs for coherent remote sensing segmentation.
- It employs an iterative joint KL minimization and Gaussian mixture modeling to align semantic and spatial cues without any additional training.
- Extensive experiments demonstrate that ConInfer significantly improves mIoU and IoU across multiple datasets compared to existing patch-wise and context-refined methods.
ConInfer: Context-Aware Inference for Training-Free Open-Vocabulary Remote Sensing Segmentation
Introduction
Open-vocabulary remote sensing semantic segmentation (OVRSS) has shifted the paradigm for land cover understanding by leveraging vision-LLMs (VLMs) to facilitate category-agnostic segmentation under zero-shot settings. However, most OVRSS frameworks operating in a training-free regime are constrained by independent patch-wise inference mechanisms, which fundamentally neglect the spatial structure and semantic dependencies characteristic of remote sensing imagery. This limitation translates to noisy and fragmented predictions, impeding the faithful extraction of large-scale, heterogeneous objects.
The paper "ConInfer: Context-Aware Inference for Training-Free Open-Vocabulary Remote Sensing Segmentation" (2603.29271) directly addresses this deficiency by proposing ConInfer, a context-aware inference engine that integrates global structural information extracted via self-supervised vision foundation models (VFMs, e.g., DINOv3) with the open-vocabulary reasoning capacity of VLMs (e.g., CLIP) to enable spatially coherent label assignment across large images. Notably, the approach is entirely training-free and operates as a plug-and-play module atop any VLM-based OVRSS framework.
Motivation and Limitations of Prior Work
Traditional training-free OVRSS methods focus on boosting discriminative visual token quality or enhancing cross-modal fusion. However, the core aspect of context—namely, intra-scene spatial dependencies and global semantic regularity—is generally overlooked. Remote sensing data differ greatly from natural images, exhibiting massive spatial extents with objects (e.g., buildings, roads, vegetation) organized in highly correlated, repetitive patterns. Local patch predictions, when made in isolation, suffer from class confusion (e.g., roads/runways) and severe fragmentation, as demonstrated by the direct predictions of MaskCLIP versus those derived by clustering patch features of CLIP or DINOv3.

Figure 1: Compared with the direct predictions of MaskCLIP, the segmentation maps generated by clustering patch features from CLIP or DINOv3 exhibit superior spatial consistency.
The ConInfer Framework
ConInfer suggests a new paradigm, repositioning context modeling from the training stage to the inference stage and leveraging strong priors present in large pre-trained models. The method is predicated on the joint exploitation of two complementary sources:
- Semantic alignment: Patch-wise open-vocabulary scores from a VLM such as CLIP.
- Spatial context: High-level visual patterns (structural regularities) from a VFM such as DINOv3.
The essential workflow unfolds as follows:
- Patch-wise VLM Prediction: Given a remote sensing scene partitioned into fixed-size tiles, features are extracted via the vision backbone of a pre-trained VLM (e.g., CLIP), and open-vocabulary scores are obtained via cosine similarity between visual tokens and text prototypes.
- Context Extraction using VFMs: DINOv3 (ViT-based) features are computed for every patch. A Gaussian Mixture Model (GMM) with ∣C∣ components (where C is the set of candidate categories) is fitted over these features to model spatial groupings, capturing context without reliance on semantic supervision.
- Joint Latent Distribution Optimization: For each patch i, a latent categorical consensus distribution zi is iteratively refined by minimizing the sum of KL divergences to both the VLM score pi and GMM posterior qi, enabling mutual semantic-contextual alignment.
- Iterative Consensus: The unified distribution is updated in closed form in an alternating algorithm, ensuring rapid and stable convergence across a minimal number of iterations.
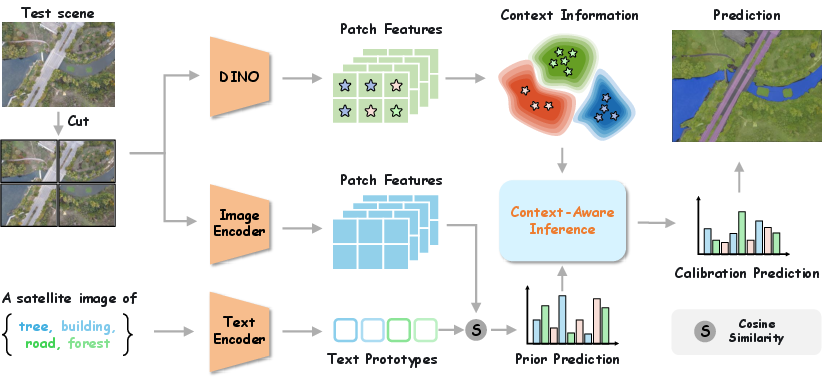
Figure 2: Overview of the proposed ConInfer framework. ConInfer performs joint, training-free inference by integrating semantic priors from CLIP with structural regularization from DINO, enabling globally consistent open-vocabulary segmentation without any retraining.
This modular architecture does not involve any training or fine-tuning; it operates solely at inference by postprocessing prediction scores, supporting seamless integration with any scoring VLM.
Experimental Evaluation
Multi-class Segmentation
ConInfer is systematically benchmarked on eight multi-class segmentation datasets, including OpenEarthMap, LoveDA, iSAID, Potsdam, Vaihingen, UAVid, UDD5, and VDD. It consistently outperforms both patch-wise approaches (MaskCLIP, SCLIP, ClearCLIP) and the current best context-refined baseline (SegEarth-OV), achieving a mean improvement of 2.80% mIoU over SegEarth-OV. Key gains emerge due to enhanced consistency and semantic grouping, attributable to context incorporation.
For building, road, and water extraction across nine standard datasets, ConInfer achieves an average improvement of 6.13% IoU over SegEarth-OV, most notably on datasets with pronounced structural regularity (e.g., WHU-Sat.II, CHN6-CUG, WBS-SI). These results underscore the impact of context-aware modeling: spatially contiguous targets are segmented more completely and with fewer false positives than when using only patch-independent inference.
Plug-and-Play Effectiveness
When ConInfer is directly coupled to alternative scoring frontends (e.g., SCLIP, MaskCLIP), it yields substantial additive boosts, confirming modularity and universality. For example, adding ConInfer on top of MaskCLIP on the WHU-Aerial dataset raises IoU by nearly 23%.
Qualitative Results
Visualizations demonstrate that ConInfer significantly suppresses fragmentation and class confusion, producing segmentation maps with sharper and more semantically consistent boundaries compared to alternative methods.
Figure 3: Qualitative comparison of different OVSS methods on several remote sensing datasets, highlighting the enhanced spatial and semantic coherence delivered by ConInfer.
Convergence Analysis
ConInfer’s iterative procedure empirically converges in fewer than 10 iterations, with the objective loss stably decreasing and plateauing rapidly.
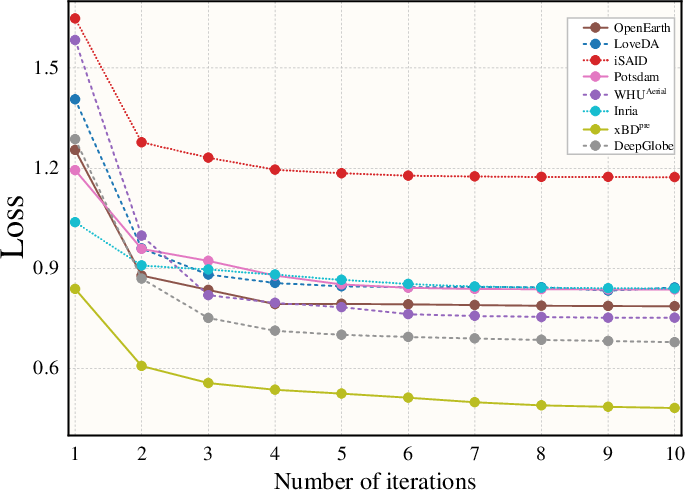
Figure 4: Convergence analysis of ConInfer demonstrates rapid and stable decline in the objective function; optimization typically stabilizes within 10 steps.
Failure Modes
Analysis on UDD5 (low-altitude UAV data) reveals remaining limitations, especially regarding boundary sensitivity for minute objects (e.g., vehicles) and confusion in distinguishing among semantically similar roof tiles. Such cases motivate further research into finer-grained contextual integration.

Figure 5: Examples showing typical failure cases on UDD5, including weak boundaries and class confusion for subtle categories.
Ablation Studies
- Context source: Using DINOv3 for context yields more robust gains than CLIP, given its ability to capture intricate structural detail.
- Joint optimization: Full joint optimization outperforms decoupled workflows, confirming that mutual semantic-context interplay is beneficial; consensus inference not only aligns but also refines both semantic and structural components across iterations.
- Attention fusion: Composing attention maps from multiple transformer layers further boosts effectiveness.
Implications and Future Directions
The central contribution of ConInfer lies in transferring context modeling to the inference phase using pre-trained, non-semantic visual backbones—circumventing the rigidity and training cost of conventional context modules. Practically, this paradigm enables zero-shot, globally consistent semantic segmentation across unseen or dynamically evolving vocabularies in remote sensing.
From a theoretical standpoint, ConInfer reveals that direct score-space fusion of semantic and contextual priors, when sufficiently expressive, closes a large part of the remaining performance gap for training-free segmentation, especially for highly structured, spatially coherent modalities.
Potential future work includes:
- Extending context modeling from patch-level to pixel-level for even finer boundary recovery.
- Exploring more powerful or hybrid visual context models for improved robustness in highly heterogeneous or low-altitude UAV imagery.
- Incorporating temporal context in sequential (video) remote sensing applications.
Conclusion
ConInfer establishes context-aware inference as a vital missing piece within training-free open-vocabulary segmentation for remote sensing. By fusing semantic priors from VLMs with the spatial structure learned by state-of-the-art VFMs via a training-free, iterative joint KL-minimization, ConInfer consistently exceeds the performance of all existing training-free OVRSS baselines across remote sensing benchmarks—without the need for re-training, additional supervision, or architectural coupling. This work delineates a new modular, flexible, and highly effective route for advancing open-vocabulary segmentation under practical, dynamic, and label-scarce conditions.