- The paper introduces a decoupled architecture that separates object discovery from semantic retrieval to reduce pseudo-label noise and improve boundary precision.
- It employs semantic boundary purification and soft-masked feature aggregation for robust prototype extraction, delivering superior mIoU on VOC and COCO benchmarks.
- Using a training-free, non-parametric retrieval approach, ModuSeg achieves remarkable computational efficiency and performance gains in weakly supervised segmentation.
ModuSeg: Decoupling Object Discovery and Semantic Retrieval for Training-Free Weakly Supervised Segmentation
Introduction and Motivation
ModuSeg presents a paradigm shift for weakly supervised semantic segmentation (WSSS) by explicitly decoupling the two fundamental subproblems: object discovery (localization) and semantic assignment (classification). Unlike conventional coupled approaches that jointly optimize recognition and localization—often leading to overfitting on sparse discriminative regions and complex multi-stage retraining—ModuSeg separates these processes. It leverages advances in class-agnostic mask proposers for geometry and retrieval-based pipelines built atop semantic foundation models, creating a modular and fully training-free system.
This approach directly targets the spatial imprecision and pseudo-label noise prevalent in prior work, particularly when relying on Class Activation Maps (CAMs) or end-to-end fine-tuning of large models. The decoupling enables ModuSeg to preserve precise object boundaries, facilitate seamless integration of evolving visual backbones, and maintain high efficiency.
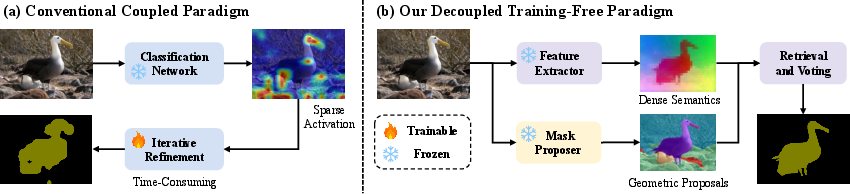
Figure 1: Comparison of ModuSeg’s decoupled architecture to conventional coupled methods, illustrating the direct assignment of semantics to geometric proposals without iterative optimization.
Method Overview
Two-Stage Modular Pipeline
The pipeline consists of two distinct stages:
- Offline Feature Bank Construction: Semantic boundaries are refined using semantic boundary purification (SBP) and discriminative category prototypes are extracted via soft-masked feature aggregation (SMFA). Pseudo-masks are generated and then purified through erosion-based removal of ambiguous edges, followed by soft region-weighted encoding into high-quality feature vectors. Subsequent prototype-based outlier filtering further enhances intra-class compactness.
- Online Retrieval-based Inference: Object proposals are extracted from test images via a general mask proposer (e.g., EntitySeg). Semantics are assigned to each proposal through a non-parametric K-nearest-neighbor retrieval over the offline feature bank; results undergo hierarchical voting and confidence-based rasterization for final prediction.
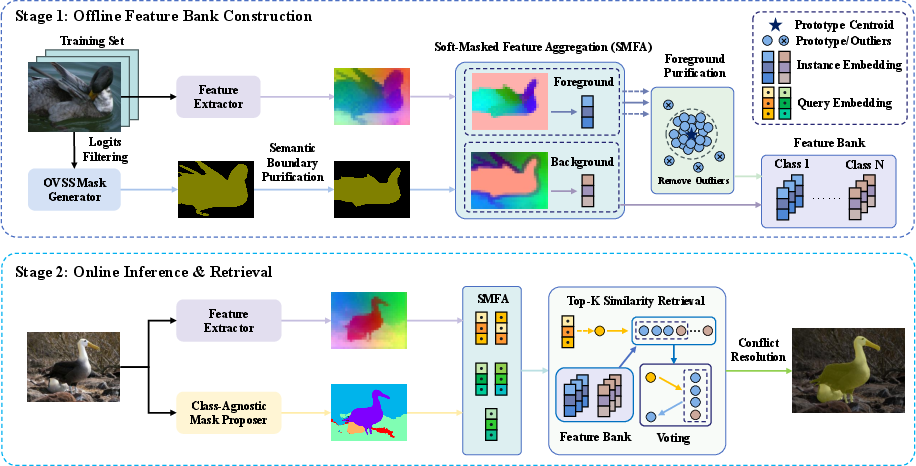
Figure 2: Overview of ModuSeg, illustrating offline feature bank construction with boundary purification and prototype aggregation, followed by online inference using retrieval-based semantic assignment.
Technical Contributions
Explicitly Decoupled Architecture
Unlike previous approaches which entangle mask generation and semantic assignment, ModuSeg delegates geometric proposal to specialized class-agnostic segmentation models (e.g., EntitySeg), then addresses label attribution via feature-level non-parametric K-NN retrieval. This architectural split is central to its improved performance and efficiency.
Semantic Boundary Purification (SBP)
To combat patch-pixel alignment issues and pseudo-label noise, the SBP module performs morphological erosion on initial segmentation masks, removing ambiguous edges and extracting only the “semantic core” regions. This significantly reduces boundary mixing during feature encoding and prototype extraction.
Soft-Masked Feature Aggregation (SMFA) and Prototype Filtering
Instead of binary region pooling, SMFA employs area-based interpolation for spatial weighting, producing prototype vectors that reflect the contribution of partially covered patches. Subsequently, instance-wise prototypes are filtered by their proximity to a class centroid, discarding the most distant (i.e., likely noisy) exemplars—for all foreground classes only, preserving negative context diversity for the background.
Training-Free and Backpropagation-Free Retrieval Assignment
During inference, proposals are rapidly encoded and compared against the offline bank using cosine similarity, with a hierarchical voting process handling noise and label uncertainty. Overlapping proposals are resolved via priority rasterization based on computed confidence.
Empirical Results
Strong Numerical Results
On VOC and COCO, ModuSeg achieves 86.3% and 86.6% mIoU (validation/test) for VOC and 56.7% for COCO, outperforming previous best methods (WeCLIP, SSR, ExCEL, S2C, etc.) by a wide margin (absolute increase of 6–7 mIoU on VOC, 6.1 on COCO), with no fine-tuning or additional training. Ablations confirm that both SBP and SMFA independently and jointly provide measurable performance gains. Notably, the pseudo-mask generation pipeline itself sets new quality benchmarks (78.8% mIoU on VOC train).
Comparative qualitative evaluation demonstrates that ModuSeg produces more complete object masks and sharper boundaries, with fewer false positives and fragmentation artifacts compared to WeCLIP and ExCEL.

Figure 3: ModuSeg achieves superior object completeness and adherence to boundaries versus recent WSSS baselines in VOC and COCO, with improved segmentation integrity and semantics.
Analysis and Ablations
- Component Ablation: SMFA and SBP provide cumulative gains, underscoring their critical role in robust feature bank construction.
- Feature Bank Quality: Logits-based class filtering during pseudo-mask generation increases bank quality by over 10 mIoU.
- Mask Proposer Comparison: EntitySeg yields better segmentation proposals than SAM2 within the retrieval paradigm, enhancing instance consistency.
- Scalability: Performance scales efficiently with backbone strength; DINOv2/v3 and C-RADIOv4 yield strong gains as feature extractors.
- Efficiency: ModuSeg is an order of magnitude more efficient than coupled optimization baselines—only 5.3 GB GPU memory and 84 minutes to process VOC, vs. over 1000 minutes for MCTformer+.
- Upper Bound and Data Requirements: Oracle experiments reveal remaining limitations stem mainly from the mask proposer, not feature bank or retrieval, with human-annotated segment proposals enabling >95% mIoU. The framework is highly data-efficient, reaching >93% of full-data performance with only 50 images per class.
Implications and Future Directions
This work suggests a new direction for WSSS: transforming segmentation from a learnable mapping into a modular retrieval system, wherein recent advances in foundation models can be rapidly adopted without re-optimization. The success of a training-free, decoupled system highlights the potential of non-parametric methods when provided with strong geometric and semantic priors.
Practical implications include rapid adaptation to new categories and datasets with minimal supervision, and efficient deployment scenarios where resources or labels are limited. In theory, the results motivate deeper investigation into modular architectures for dense prediction, with plug-and-play integration of evolving segmentation and representation backbones.
Future research may address further closing the “semantic gap” via improved mask proposers, robust retrieval under open-set shifts, and integration with self-supervised objectives or additional modalities.
Conclusion
ModuSeg introduces a principled decoupling of object discovery and semantic retrieval for weakly supervised semantic segmentation, realized in a modular, training-free framework. The combination of boundary purification, soft aggregation, and retrieval-based inference delivers state-of-the-art segmentation quality accompanied by high computational efficiency and data-efficiency. This framework not only establishes new performance standards for WSSS, but also foregrounds retrieval-augmented pipelines as a promising foundation for next-generation segmentation systems (2604.07021).

