Learning Cross-View Object Correspondence via Cycle-Consistent Mask Prediction
Abstract: We study the task of establishing object-level visual correspondence across different viewpoints in videos, focusing on the challenging egocentric-to-exocentric and exocentric-to-egocentric scenarios. We propose a simple yet effective framework based on conditional binary segmentation, where an object query mask is encoded into a latent representation to guide the localization of the corresponding object in a target video. To encourage robust, view-invariant representations, we introduce a cycle-consistency training objective: the predicted mask in the target view is projected back to the source view to reconstruct the original query mask. This bidirectional constraint provides a strong self-supervisory signal without requiring ground-truth annotations and enables test-time training (TTT) at inference. Experiments on the Ego-Exo4D and HANDAL-X benchmarks demonstrate the effectiveness of our optimization objective and TTT strategy, achieving state-of-the-art performance. The code is available at https://github.com/shannany0606/CCMP.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper teaches a computer to find the same object when it appears in two very different videos: one from a person’s point of view (egocentric, like a GoPro on your head) and one from an outside camera (exocentric, like a camcorder across the room). The goal is to say, “this water bottle in the head‑cam video is the same water bottle in the room‑cam video,” and draw its outline in both views.
What are the main questions?
The authors focus on three simple questions:
- How can a model recognize the same object across very different viewpoints and lighting, even when the object looks quite different?
- Can we do this without needing lots of human annotations for every camera view?
- Can the model improve itself a little bit during testing, on the fly, for each new video pair?
How did they do it? (In everyday language)
Think of this like a “find the object” game played between two cameras.
- The “mask” is like a sticker that covers the object you care about in the first image. It’s a black‑and‑white cutout: white where the object is, black everywhere else.
- The model’s job is to put that sticker on the matching object in the second image.
Here are the key ideas, with simple analogies:
- Binary mask prediction (object vs. not‑object)
- “Binary segmentation” just means the model colors each pixel as either “object” (1) or “background” (0). Think of it as a coloring book where the model fills in only the shape of the object.
- Using a “hint token” to guide the search
- The model looks at the first image and the sticker (mask) to make a compact summary of the object. You can think of this like writing a quick “object note” that says, “I’m round, blue, and shiny.”
- This note is passed into a Transformer (a powerful vision model) as a special “conditioning token,” which tells the model what to look for in the second image.
- Cycle consistency: a round‑trip check
- After the model finds the object in the second image, it does a clever self-check: it tries to project that found mask back onto the first image to see if it can reconstruct the original sticker.
- If the round trip returns the same sticker, the model is probably right. If not, it learns to improve. Think of throwing a boomerang: if it returns to your hand, the throw was good; if not, you adjust.
- Test-time training (quick warm‑up during testing)
- Because the round‑trip check doesn’t need human labels, the model can “practice” a little on each new image pair at test time. It updates just a few layers with tiny steps, like a quick warm‑up before a game, to adapt to that specific scene.
- Under the hood (kept simple)
- They build on a strong vision backbone (DINOv3) and add minimal parts: the “hint token” and a small head that predicts the mask. This keeps the system simple and fast while using powerful pre‑trained features.
What did they find, and why is it important?
- Better accuracy than previous methods:
- On the big Ego-Exo4D benchmark (lots of paired first‑person/third‑person videos), their method achieves state‑of‑the‑art results, slightly beating the previous best overall.
- On the HANDAL-X benchmark (lots of cross‑view object pairs), their method performs much better than earlier approaches, even without extra training on that dataset, and stays strong after fine‑tuning.
- Works both ways:
- It handles both Egocentric→Exocentric and Exocentric→Egocentric matching. That means it can find your object whether you start from the head‑cam or the room‑cam.
- Test-time training helps:
- Letting the model do a tiny “practice” round at test time consistently makes results better, especially when scenes look different from the training data.
- Simple design, strong results:
- With a small, clean architecture and the round‑trip check, the model learns view‑invariant features—basically, what makes an object itself, no matter where the camera is.
Why this matters:
- Real robots and AR systems need to match what you see with what they see from another angle. This helps with:
- Robots following your instructions from a head‑mounted camera and then finding the item from their own view.
- Sports or classroom analysis, where multiple cameras capture the same scene from different angles.
- Assistive tech that helps locate objects quickly in busy environments.
What’s the bigger impact?
This research shows that:
- We can learn to match objects across very different views using self-checks (cycle consistency) rather than relying on tons of hand labels.
- Simple, well‑designed training strategies and small test‑time tweaks can make models more reliable in the real world.
- It brings us closer to smarter robots, better multi‑camera systems, and more helpful AR tools that understand “this is the same object,” even when it looks very different from another angle.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
- Unspecified “projection back” operator: The paper does not detail how the predicted target-view mask is mapped back to the source view for cycle consistency without camera geometry; clarify the projection mechanism, its assumptions, and failure modes under large parallax or nonrigid motion.
- Cycle loss under invisibility: The method ignores cases where the object is invisible in either view; explore visibility-conditioned cycle losses, occlusion modeling, and gating strategies to avoid penalizing correct “no-visibility” predictions.
- Loss of spatial structure in conditioning: The condition token is a global pooled feature weighted by the source mask; investigate spatially structured conditioning (e.g., masked patch tokens, cross-attention with source patches, shape descriptors, multi-scale features) to preserve fine-grained geometry.
- No explicit temporal modeling: Despite operating on videos, the approach uses single-frame correspondence; evaluate leveraging motion cues, optical flow, temporal memory, or sequence-level cycle consistency.
- Ambiguity with multiple similar instances: The method does not explicitly disambiguate repeated or symmetric objects; add instance-level constraints, negative sampling, or context cues to avoid distractors.
- Binary segmentation only: The framework does not handle multi-object or panoptic settings or identity tracking across time; extend to instance-level multi-object correspondence and long-term identity maintenance.
- Decoupled visibility training: The CLS (visibility) head is trained post hoc and frozen; study joint training with the segmentation head, multi-task optimization, and integrating visibility predictions into cycle consistency.
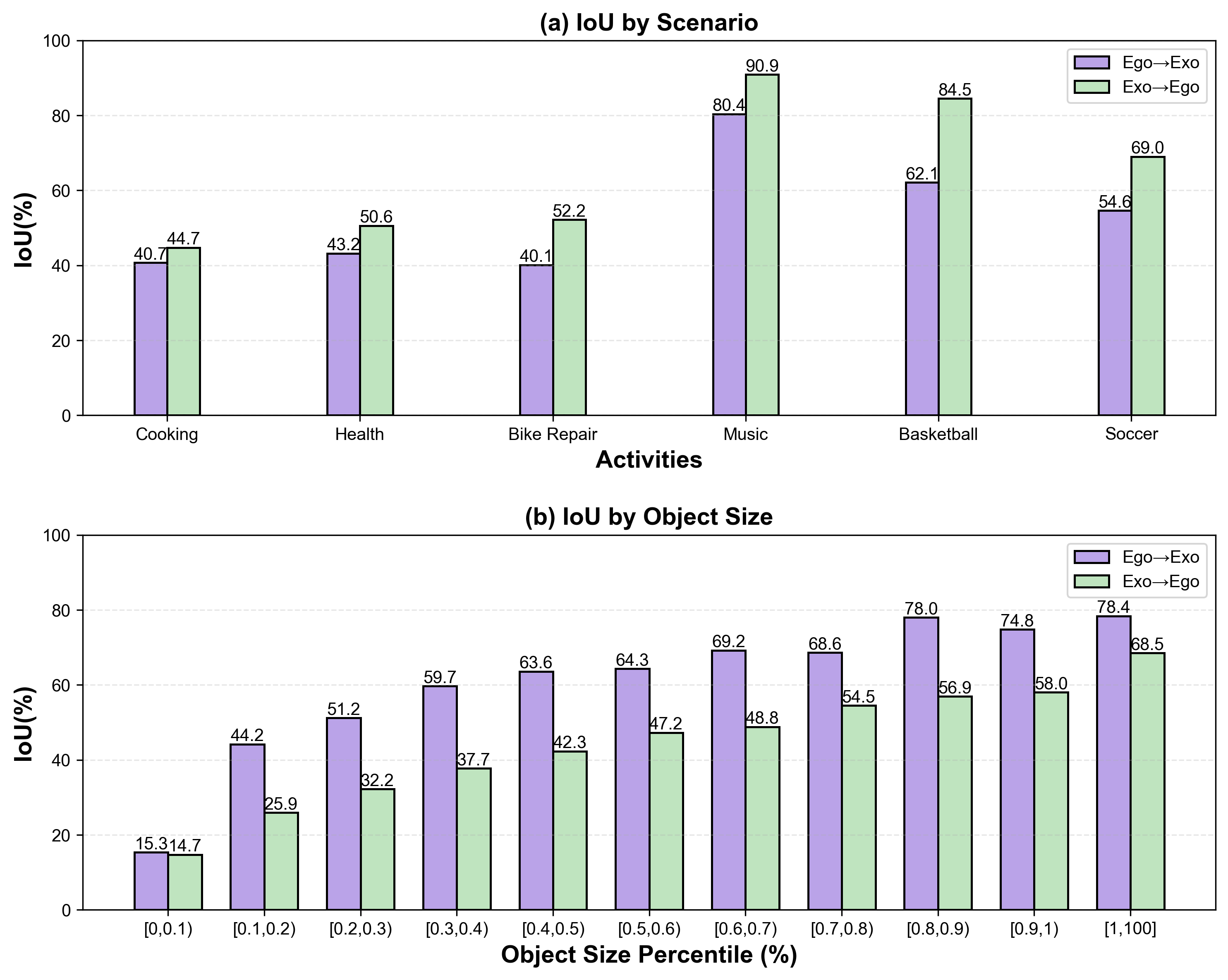
- Small-object performance: Objects under ~0.1% image area remain challenging; test multi-scale decoders, zoom-in cropping, super-resolution guidance, focal losses, and curriculum learning specific to tiny objects.
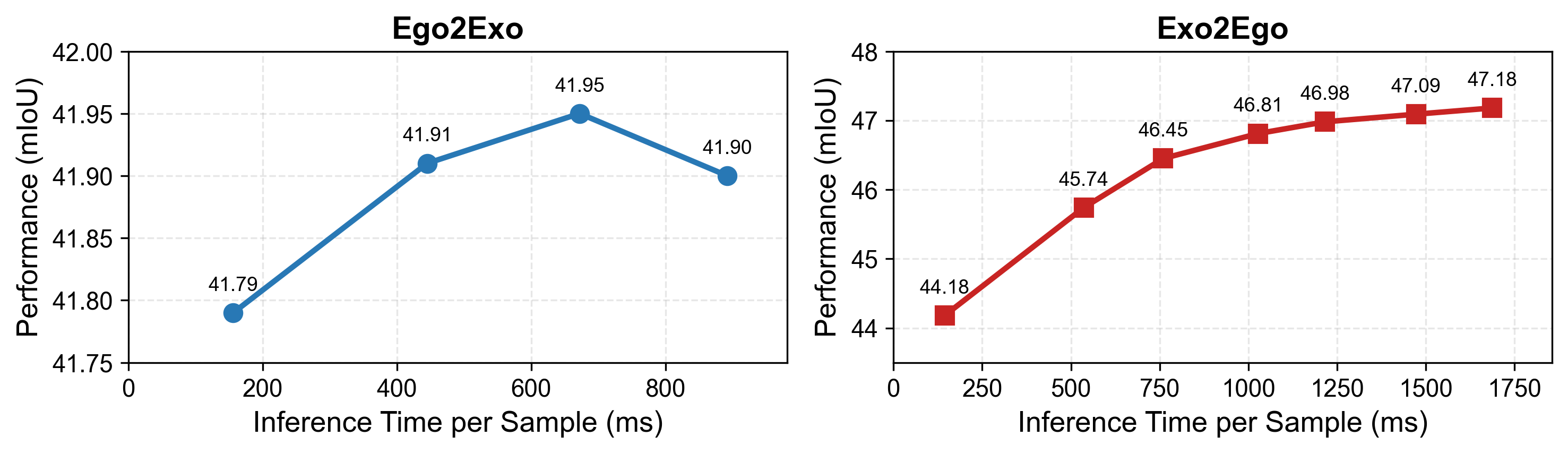
- TTT hyperparameter selection: K (layers), T (steps), and lr for test-time training are chosen ad hoc; develop adaptive schedules, confidence/uncertainty-driven stopping criteria, and meta-learning for per-pair TTT.
- TTT stability and drift: Analyze how cycle-based TTT can reinforce incorrect correspondences; add safeguards such as entropy regularization, agreement across augmentations, or consistency checks across views and time.
- Computational and real-time constraints: Training is compute-heavy and TTT adds per-pair adaptation overhead; quantify inference latency, memory footprint, and assess feasibility for on-device or real-time robotic deployment.
- No use of camera geometry: The method ignores camera intrinsics/extrinsics; evaluate benefits of estimated calibration, homographies, learned 3D features (e.g., NeRFs), or geometry-informed attention to improve cross-view mapping.
- Domain generalization breadth: Results cover Ego-Exo4D and HANDAL-X; assess generalization to other cross-view domains (aerial–ground, indoor multi-camera, surveillance) and to varying camera intrinsics (fisheye, wide-angle).
- Robustness to occlusion/illumination: Claims of robustness are not systematically quantified; create controlled tests for motion blur, glare, shadows, low-light, and occlusion patterns, with targeted augmentations or modules.
- Auxiliary loss placement: Deep supervision is only applied at the second-to-last transformer layer; explore optimal layers, weights, and interactions between auxiliary and cycle losses for stability and performance.
- Backbone choices and sharing: Source uses ConvNeXt-based DINOv3-L, target uses ViT-based DINOv3-L with no analysis of weight sharing or architectural mismatch; compare shared/backbone variants and other foundation models (e.g., CLIP, SigLIP).
- Scalability to multiple queries: The pipeline’s behavior with multiple simultaneous queries and TTT is unclear; study batching strategies, interference between queries, and memory constraints.
- Handling nonrigid deformation: The binary mask and single token may be insufficient for deformable objects; incorporate deformation-aware features or shape priors to capture articulation.
- Temporal relaxation strategy: The “relaxed temporal alignment” (RTA) is used but not characterized; quantify the impact of temporal offset magnitude on accuracy and develop principled pairing strategies.
- Metric coverage: Evaluation lacks downstream or sequence-level metrics (e.g., success in robot manipulation, long-term identity consistency); add task-driven measures and temporal consistency metrics.
- Failure-mode taxonomy: Beyond small objects, failure cases (symmetric distractors, reflective/transparent surfaces, heavy occlusions) are not analyzed; curate a taxonomy and targeted remedies.
- Reproducibility details: Key implementation specifics (projection operator, CDT construction, token dimensions, optimizer schedules) are under-specified; provide precise documentation and sensitivity analyses.
- Safety and privacy in TTT: Online adaptation risks catastrophic forgetting, privacy leakage, or adversarial drift; design guardrails (rollback, bounded updates, data handling policies) for deployment.
Practical Applications
Immediate Applications
Below is a concise list of deployable use cases that can be implemented with the paper’s current method (cycle-consistent conditional binary segmentation with test-time training), along with sectors, emergent tools/workflows, and feasibility notes.
- Multi-camera object handoff in service and warehouse robots (robotics)
- Tools/workflows: ROS node exposing a “Cross-View Object Finder” API; operator or wearable (ego) provides a source mask (via SAM/FastSAM or a click), robot camera (exo) segments the same object; optional TTT per pair to adapt to lighting or camera shift.
- Assumptions/dependencies: Access to at least two camera views; basic time pairing; source mask availability; compute headroom for TTT; performance drops for very small objects (<0.1% image area).
- Bodycam-to-CCTV object linking for security operations (security, public safety)
- Tools/workflows: Video Management System (VMS) plugin that transfers an officer’s bodycam object mask into fixed CCTV feeds to rapidly locate the same item/person; optional offline TTT.
- Assumptions/dependencies: Legal/privacy compliance (consent, retention, minimization); approximate time alignment; adequate resolution; on-premise compute.
- Sports analytics: multi-angle tracking of balls/equipment across broadcast and POV cams (media/sports tech)
- Tools/workflows: Broadcast analysis module that propagates masks across camera angles to automate highlights, ball trajectories, and player-equipment interactions.
- Assumptions/dependencies: Sufficient resolution and frame rates; object visibility across views; throughput constraints for TTT in near-real time.
- Surgical and clinical training: tool/instrument tracking between surgeon headcam and room camera (healthcare)
- Tools/workflows: OR video suite plugin that links point-of-view masks to exo cameras to analyze technique, instrument usage, and ergonomics.
- Assumptions/dependencies: Strict privacy/compliance (HIPAA/region-specific); stable multi-cam setup; compute availability; robustness to occlusions.
- Manufacturing QA and assisted assembly with multi-view cameras (manufacturing)
- Tools/workflows: Plant vision system integration where an operator’s POV mask is transferred to overhead inspection cams to verify part placement or tool usage; TTT for domain adaptation to new lines.
- Assumptions/dependencies: Multi-cam coverage; consistent lighting; small object handling may require higher-resolution feeds or model fine-tuning.
- Multi-cam video editing and post-production mask transfer (software/media)
- Tools/workflows: Adobe Premiere/After Effects plugin “Cross-View Mask Transfer” to propagate object selections across angles; batch processing; optional offline TTT for challenging shots.
- Assumptions/dependencies: Offline workflows; source mask creation; GPU/CPU resources; content rights and privacy.
- AR-assisted picking and inventory localization in warehouses (logistics)
- Tools/workflows: AR SDK module where worker’s headset (ego) labels target item; ceiling cams (exo) segment and direct pick path; TTT to adapt to aisle lighting/shelf changes.
- Assumptions/dependencies: Reliable Wi-Fi/camera network; latency constraints; shelf-level visibility; user training for mask prompting.
- Academic data curation: label propagation via cycle consistency (academia)
- Tools/workflows: Semi-automatic ground-truth generation where source masks seed target masks; cycle-consistent reconstruction validates/filters pseudo-labels; reduces annotation cost on cross-view datasets.
- Assumptions/dependencies: Quality control for pseudo-labels; protocol for handling invisibility; storage and compute for batch runs.
- Multi-view drone-ground search (public safety, industrial inspection)
- Tools/workflows: Mission control plugin—operator handheld camera provides the source mask; drone feed (exo/aerial) segments the same object (e.g., a backpack, tool) to assist search or inspection.
- Assumptions/dependencies: Large viewpoint shift; object size/resolution at altitude; intermittent visibility; regulatory flight constraints.
- Smart home “find my object” across indoor cameras (consumer/daily life)
- Tools/workflows: Mobile app where a user marks an item in a phone clip (ego); system segments it in home IP cameras (exo) to locate last seen position.
- Assumptions/dependencies: Home camera coverage; privacy controls; small household items may be at the challenging end of current performance.
- Software/API offering for cross-view correspondence (software)
- Tools/workflows: Packaged CCMP service with simple inputs (source image+mask, target image/video) and outputs (mask, visibility, centroid/LE); optional TTT toggle; SDK for Python/C++.
- Assumptions/dependencies: DINOv2/v3 backbone licensing and model weights; GPU availability for TTT; monitoring for failure cases (distractors, occlusion).
Long-Term Applications
These use cases benefit from further research, scaling, optimization, or regulatory development before broad deployment.
- Real-time, on-device cross-view correspondence (software, robotics, edge AI)
- Tools/workflows: Quantized/optimized CCMP variants (e.g., MobileViT backbones), low-overhead adaptation replacing gradient-based TTT, hardware-aware compilers (TensorRT, CoreML).
- Assumptions/dependencies: Model compression without significant accuracy loss; alternative self-supervision for live adaptation.
- Language-grounded multi-view instruction-following robots (robotics, AI)
- Tools/workflows: Integrating CCMP with VLMs/LMMs to map referring expressions (“the red screwdriver you just picked up”) across ego-exo views, enabling robust object grounding for manipulation.
- Assumptions/dependencies: Datasets with aligned language, ego-exo video, and masks; robust disambiguation under distractors.
- Cross-camera entity registry for digital twins and multi-view 3D scene graphs (industrial IoT, smart buildings)
- Tools/workflows: “Cross-View Entity Registry” that reliably associates the same physical object across a building’s camera network, feeding BIM/digital twin platforms and automation.
- Assumptions/dependencies: Camera calibration and time sync improve stability; persistent identity handling beyond masks; privacy-by-design architectures.
- Cooperative perception: vehicle cameras linked to roadside infrastructure cameras (autonomous driving)
- Tools/workflows: Cross-infrastructure fusion where CCMP binds detections across moving and fixed viewpoints to improve occlusion handling, situational awareness, and safety.
- Assumptions/dependencies: V2X connectivity; standardized data-sharing policies; calibration; rigorous validation and liability frameworks.
- Healthcare-grade cross-view tracking systems (healthcare, regulation)
- Tools/workflows: Validated, compliant pipelines for surgical/clinical environments (audited cycle-consistency logs, on-prem adaptation), integrated with training and quality boards.
- Assumptions/dependencies: Regulatory approvals (HIPAA, MDR); robustness under occlusion/blood/lighting; human factors and safety studies.
- Retail loss prevention and shelf analytics via cross-view linking (retail)
- Tools/workflows: “Cross-View SKU Tracker” that associates shelf cams and staff wearables to monitor misplaced items, restocking, and anomalies with minimal manual labeling.
- Assumptions/dependencies: Privacy and customer consent; reliable shelf coverage; domain-specific fine-tuning for small items.
- Standards, policy, and governance for cross-view tracking (policy)
- Tools/workflows: Consent protocols, audit trails for TTT updates, privacy-preserving on-device adaptation, retention policies, and fairness/accuracy reporting for cross-view association.
- Assumptions/dependencies: Multi-stakeholder alignment (public safety, civil liberties, vendors); clear metrics and benchmarks for accountability.
- Robust handling of invisibility, extreme occlusions, and tiny objects (research, software)
- Tools/workflows: Enhanced visibility heads, uncertainty quantification, curriculum learning for <0.1% area objects, multi-scale backbones, and training with synthetic occlusions.
- Assumptions/dependencies: Expanded datasets and augmentation strategies; research on loss functions beyond BCE for cycle consistency.
- Asynchronous multi-stream association with relaxed temporal alignment (software, research)
- Tools/workflows: Generalized “Temporal Relaxed Alignment” algorithms that exploit motion cues and object priors to match views even when time synchronization is poor.
- Assumptions/dependencies: Temporal modeling improvements; lightweight temporal context without heavy memory modules.
- Education and skill transfer platforms linking POV training to third-person demos (education)
- Tools/workflows: Skill-learning systems that automatically align steps and objects across views for feedback, assessment, and personalized coaching; analytics on contour accuracy/IoU trends.
- Assumptions/dependencies: Curated multi-view training datasets; UI for mask prompting and review; instructor oversight for edge cases.
Glossary
- Auxiliary loss: An additional supervision applied to intermediate predictions to improve training stability and gradient flow. "the auxiliary loss is computed between the ground-truth target mask and the intermediate predicted masks"
- Binary Cross-Entropy (BCE) loss: A standard loss for binary classification that measures cross-entropy between predicted probabilities and binary labels. "we adopt a combination of Binary Cross-Entropy (BCE) loss and Dice loss"
- Bidirectional constraint: A consistency enforcement in both source-to-target and target-to-source directions to improve alignment. "This bidirectional constraint provides a strong self-supervisory signal without requiring ground-truth annotations and enables test-time training (TTT) at inference."
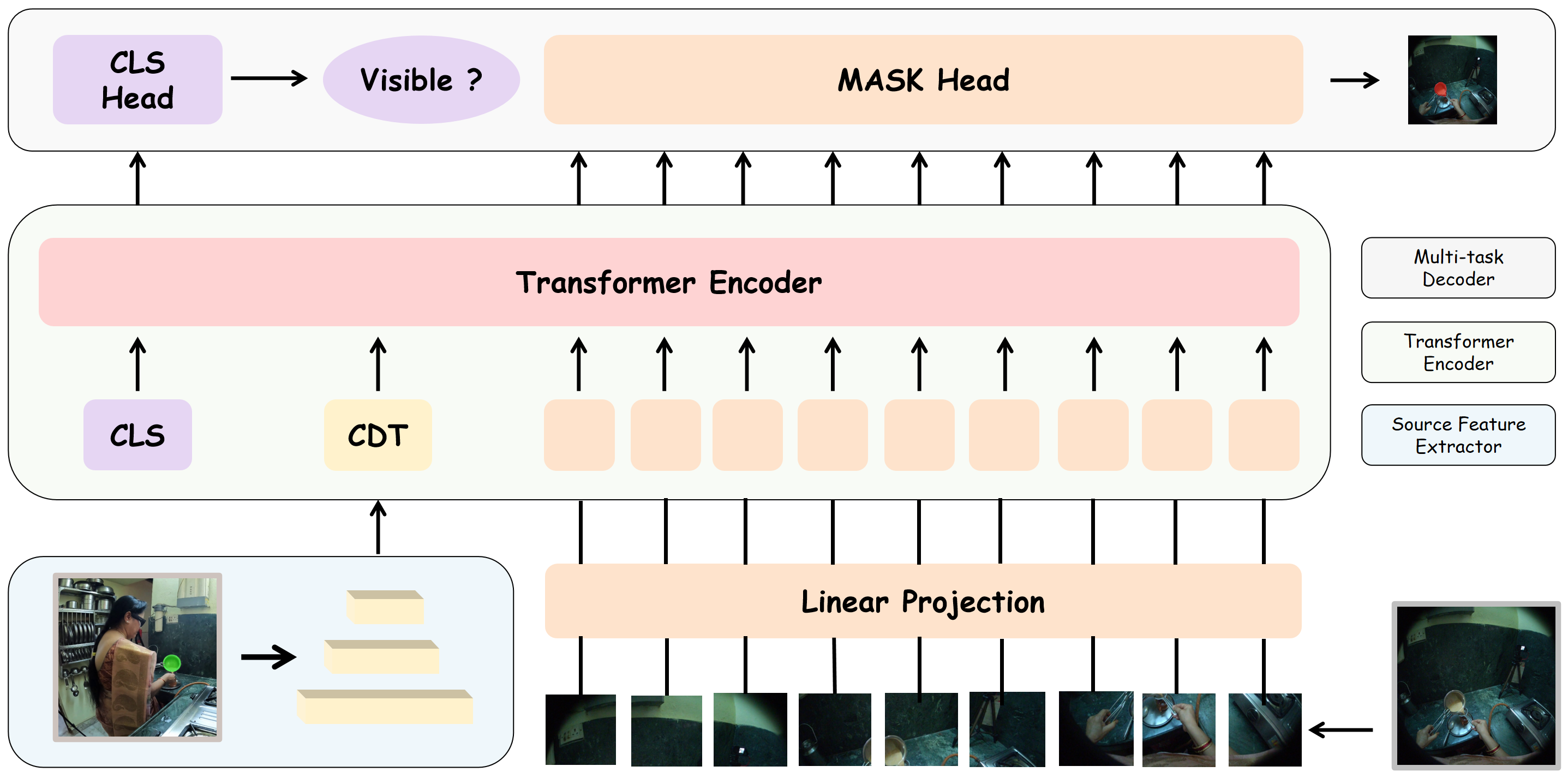
- Class token (CLS): A special transformer token aggregating global instance-level information, used for classification tasks. "Along with the condition token and the class token , the final input to the transformer encoder is"
- CLS Head: A classification head attached to the CLS token that predicts instance-level visibility. "the CLS Head, which, with an additional classification token , predicts whether the object in is visible in "
- Conditional binary segmentation: A segmentation approach that uses a source object query to condition the prediction of a binary mask in the target view. "we propose a simple yet effective framework based on conditional binary segmentation"
- Condition token (CDT): A learned token encoding source object features to condition transformer processing of the target image. "Along with the condition token and the class token "
- ConvNeXt: A convolutional neural network architecture employed as the backbone variant within DINOv3. "We adopt the ConvNeXt-based pretrained DINOv3-L model"
- Cycle-consistency loss: A loss that enforces reconstructing the source mask after mapping to the target and back, encouraging robust correspondences. "Formally, the cycle-consistency loss is defined as:"
- DINOv3: A vision foundation model providing strong pretrained visual representations for the framework. "leverages the powerful vision foundation model DINOv3 as backbone"
- Dice loss: An overlap-based segmentation loss that is effective under class imbalance by maximizing the dice coefficient. "Binary Cross-Entropy (BCE) loss and Dice loss"
- Ego-Exo4D: A large-scale dataset for egocentric–exocentric visual correspondence with object-level annotations. "We validate our approach on the challenging Ego-Exo4D~\cite{grauman2024ego} dataset"
- Ego2Exo: The task setting where the egocentric view is the query and the exocentric view is the target. "we define Ego2Exo as the task where the ego-centric view (circular field of view) serves as the query and the exo-centric view as the target"
- Exo2Ego: The reverse task setting where the exocentric view is the query and the egocentric view is the target. "and Exo2Ego as the reverse setting."
- FastSAM: A proposal-based segmentation method used to generate candidate masks for matching. "integrating FastSAM~\cite{zhao2023fast} to generate candidate masks in advance."
- Gradient accumulation: A training technique that accumulates gradients over multiple steps before updating weights to simulate larger batch sizes. "we adopt gradient accumulation with a step size of 16"
- HANDAL-X: A cross-view object segmentation benchmark consisting of multi-view image pairs and object-centric masks. "HANDAL-X contains multi-view image pairs that capture objects from complete 360° viewpoints with corresponding object-centric masks."
- Intersection over Union (IoU): A metric measuring the overlap ratio between predicted and ground-truth masks. "Intersection over Union (IoU): Measures the overlap between the predicted and ground-truth masks."
- Latent representation: A compact vector encoding of the query mask used to guide target localization. "an object query mask is encoded into a latent representation to guide the localization of the corresponding object in a target video."
- Linear probing: A training stage in which pretrained backbones are frozen and only newly added layers are trained. "In the first stage (linear probing), we freeze the two DINOv3 backbones and train the remaining modules for 64K iterations."
- Location Error (LE): A metric defined as the normalized distance between the centroids of predicted and ground-truth masks. "Location Error (LE): Defined as the normalized distance between the centroids of the predicted and ground-truth masks."
- Mask head: A decoder component that produces per-token features used to predict the segmentation mask. "the Mask Head, which generates the feature for each visual token ;"
- Mask-guided attention mechanism: An attention process conditioned on the source mask to focus feature processing on relevant regions. "leverages conditional features and a mask-guided attention mechanism to establish robust visual correspondences."
- Mean Intersection-over-Union (mIoU): The average IoU across both Ego2Exo and Exo2Ego settings, used as the primary metric. "We refer to this metric as mIoU."
- Multi-task Decoder: A decoder with parallel heads for segmentation and visibility classification. "Multi-task Decoder."
- Relaxed temporal alignment (RTA): A strategy that pairs query and target frames with temporal offsets to increase robustness to timing discrepancies. "Third, for cross-view pairs, we relax temporal alignment by pairing query frames with temporally offset target frames"
- Self-supervisory signal: A training signal derived from data structure without explicit labels, used to guide learning. "This bidirectional constraint provides a strong self-supervisory signal"
- Test-time training (TTT): Adapting the model during inference using self-supervised objectives to handle distribution shifts. "making it applicable during inference for test-time training (TTT)."
- Transformer encoder: A multi-layer self-attention model that processes token sequences representing image patches and special tokens. "These tokens are fed into a standard transformer encoder"
- Vision Transformer (ViT): A transformer-based architecture for image recognition using patch embeddings. "Vision Transformer (ViT) introduced a transformer-based approach for image recognition"
- Visibility Accuracy (VA): A metric evaluating the correctness of object visibility predictions in the target view. "Visibility Accuracy (VA): Evaluates the model’s ability to predict object visibility in the target view"
- Visibility prediction: The task of determining whether the queried object is visible in the target view at the instance level. "Visibility Prediction."
- XSegTx: A transformer-based baseline for per-frame spatial correspondence estimation. "XSegTx: A Transformer-based spatial model adapted from SegSwap~\cite{shen2022learning} that independently estimates correspondences at each time step."
- XView-XMem: A spatio-temporal baseline adapted from XMem that leverages temporal context for cross-view tracking. "XView-XMem: A spatio-temporal model adapted from XMem~\cite{cheng2022xmem} that leverages temporal context to generalize object tracking across views using ground-truth masks from one view per frame."
Collections
Sign up for free to add this paper to one or more collections.

