- The paper introduces a two-stage framework that uses weak clinical priors for gland-mask-free adaptation and tackles cross-device domain shifts.
- It employs topology-preserving, resolution-equivariant, and morphometric consistency losses to achieve state-of-the-art Dice scores (up to 0.726).
- Self-distillation from complementary teacher models refines segmentation, reducing annotation costs and enhancing clinical applicability.
TopoPult-SSL: Gland-Mask-Free Cross-Device Meibomian Gland Segmentation via Self-Distilled Weak Clinical Priors
Introduction and Motivation
This paper introduces TopoPult-SSL, a two-stage semi-supervised and weakly supervised framework designed to address the challenge of cross-device meibomian gland segmentation without relying on dense gland annotations in the target domain (2606.05347). Segmentation models for meibography tend to experience significant accuracy drop when deployed on images captured by new clinical devices due to severe domain shifts. Given that gland masks are expensive and time-consuming to annotate (requiring approximately 30 minutes per image), the work proposes leveraging readily available weak clinical signals such as eyelid masks, Pult grading, and morphometric ratios for adaptation.
The authors claim that TopoPult-SSL enables gland-mask-free adaptation, with competitive or superior precision compared to foundation models like SAM and MedSAM, and, when target gland masks become available, can achieve state-of-the-art (SOTA) segmentation via a self-distillation stage that outperforms both individual strong baselines and ensemble teachers.
Methodology
Stage 1: Weak-Prior Self-Supervised Adaptation
The first stage of TopoPult-SSL adapts a model pre-trained on a source dataset (MGD-1k) to a distinct target device (CAMG) using only weak clinical priors and auxiliary annotations, entirely omitting target gland masks from the loss. The strategy is instantiated through four carefully selected self-supervised "anchors":
- Topology-Preserving Distillation (Ltopo): Utilizes center-line Dice (clDice) to preserve gland topology.
- Resolution-Equivariance (Lres): Enforces consistency of predictions across image scales and geometric perturbations to address device-dependent resolution artifacts.
- Morphometric Consistency (Lmorph): Relates the predicted gland region to expert-provided gland-to-eyelid coverage ratios, ensuring population-level consistency.
- Eyelid-Anatomy Conditioning (Lana): Penalizes gland predictions falling outside expert eyelid masks, exploiting the anatomic region constraint.
After source-domain supervised pretraining, the adaptation is performed by an EMA teacher-student configuration over the unlabeled target set, where the prior anchors regularize the student model in lieu of explicit gland labels.
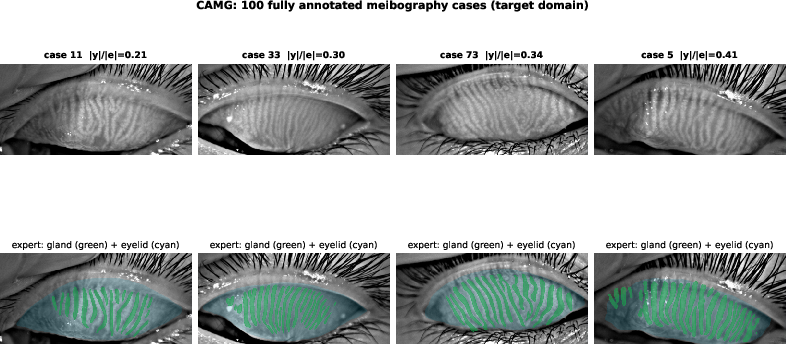
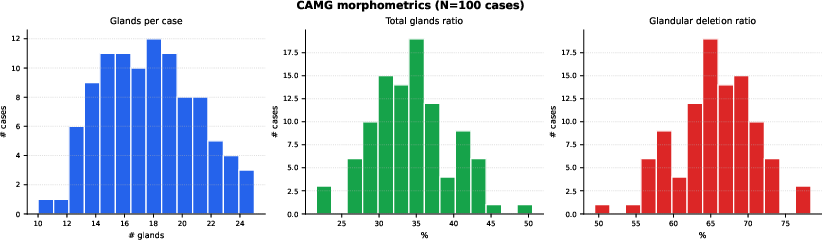
Figure 2: CAMG cases ranked by gland-to-eyelid ratio with morphological distributions, illustrating the diversity of gland coverage and validating morphometric consistency anchors.
Stage 2: Supervised Self-Distillation
Upon availability of a small labeled target set, complementary stage-1 teacher models (a resolution-equivariant anchor-driven model and a standard supervised finetuning model) are distilled into a single compact student. The student is trained on both real ground-truth masks and teacher-generated pseudo-labels, exploiting their complementary error profiles for improved generalization. A calibrated threshold is selected to maximize Dice, yielding strong performance with only a single inference pass at test time.
Experimental Setup
Datasets
- MGD-1k: 1,000 images acquired with LipiView II.
- CAMG: 100 images (children/adolescents), smaller field of view, substantial acquisition differences.
- VISIA/Topcon datasets: Reserved for future and commercial deployment.
All splits are case-disjoint and the test set is strictly held out for final evaluation.
Metrics
Primary metrics include Dice, IoU, Precision, Recall, and topology-aware clDice. Robustness is assessed via bootstrap CIs and permutation tests.
Baselines
Benchmarks span strong supervised and SSL variants (UA-MT, Mean Teacher, FixMatch, CPS), prompt-based foundation models (SAM, MedSAM), four backbone architectures, and ablation of individual anchors.
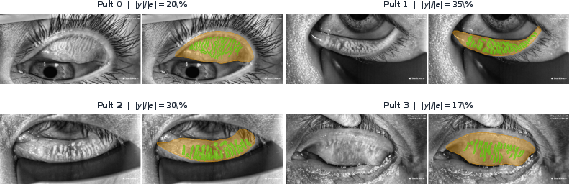
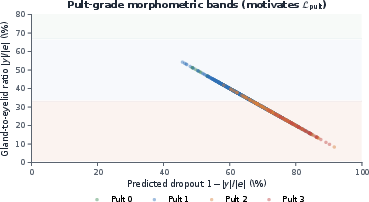
Figure 1: Distribution of expert annotations and monotonic separation between Pult grades and gland-to-eyelid ratios, providing justification for the morphometric anchors used during adaptation.
Results
- Source-Target Shift: Direct transfer incurs a $15$--$24$ point Dice drop.
- Weak-Prior Mask-Free Adaptation: The gland-mask-free TopoPult-SSL variant achieves Dice 0.645 and Precision 0.694, substantially outperforming SAM/MedSAM (Precision $0.30$--$0.34$). The gain is statistically significant (p<0.001).
- Supervised Finetuning: Supervised finetuning with 60 target images yields Dice around $0.707$.
- Self-Distilled Model: The distilled student achieves SOTA Dice Lres0 (best Lres1), surpassing UA-MT (Lres2), CPS (Lres3), and even the ensemble teacher (Lres4) with a single inference pass.
- Calibrated Thresholding: Optimal threshold selection provides an additional Lres5--Lres6 Dice points over naïve binarization.
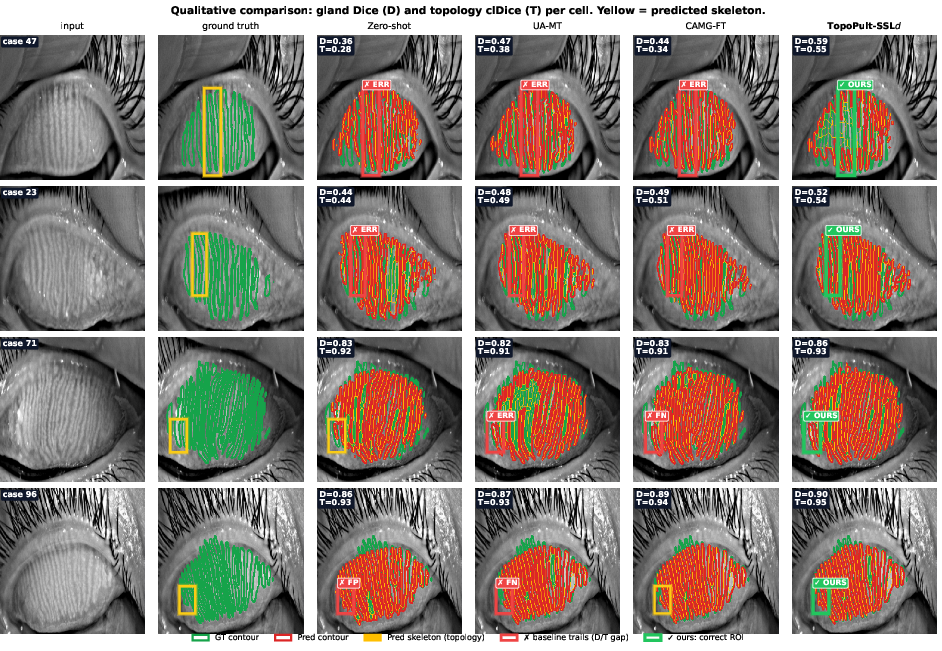
Figure 3: Monotonic relationship between gland-to-eyelid ratio and Pult grade, supporting the clinical prior used in the method.
Figure 4: Qualitative prediction comparison on CAMG test images demonstrates superior margin and topology preservation of TopoPult-SSL compared to other baselines.
Ablations and Analysis
Excluding the topology anchor (Lres7) improves Dice slightly at low target data sizes due to noisy skeleton supervision, but degrades skeleton precision, which is clinically important for gland counting. The resolution-equivariant anchor (Lres8) is identified as the most robust contributor for smooth probability calibration, which in turn improves the reliability of distilled pseudo-labels.
Practical Impact and Implications
TopoPult-SSL substantially reduces the annotation burden required for deploying segmentation models on new clinical imaging devices. By relying solely on cheap auxiliary signals (eyelid masks, morphometrics) for adaptation, it democratizes the deployment process in real-world settings where extensive re-annotation is prohibitive. The demonstrated superiority of self-distillation from complementary weak-prior models further motivates meta-ensembling and mixed-supervision approaches in medical segmentation, especially under domain shift. The framework's design is architecture-agnostic and generalizable to segmentation of other elongated biological structures with routine clinical scoring (e.g., corneal nerves).
From a theoretical standpoint, this study demonstrates the synergistic benefit of integrating weak clinical priors, topology-preserving losses, and self-distillation, highlighting that careful exploitation of inexpensive clinical metadata can replace or augment manual dense labeling.
Limitations and Future Directions
The primary limitations include a modestly sized target set (CAMG, Lres9 for test), single-device target validation, and mild non-zero cost of obtaining eyelid masks and morphometrics. The method’s generalizability should be evaluated on multi-institutional and multi-device cohorts. Additionally, the mask-free variant still relies on validation gland masks for model selection, pointing to a residual annotation requirement.
Future work could extend the anchor set, consider multi-task learning with related clinical predictors, and further reduce the labeling requirement through zero-annotation meta-selection or active learning. Broader deployment in other organ systems remains an attractive avenue.
Conclusion
TopoPult-SSL provides an effective, clinically aligned blueprint for cross-device, annotation-efficient medical image segmentation via weak clinical priors and self-distillation. Its empirical results establish new SOTA on public meibography benchmarks while sharply reducing annotation overhead. This approach has immediate application vectors in medical AI productization and signals the practical utility of integrating topology, morphometric metadata, and self-ensembling for robust segmentation under domain shift.

