VGGT-Segmentor: Geometry-Enhanced Cross-View Segmentation
Abstract: Instance-level object segmentation across disparate egocentric and exocentric views is a fundamental challenge in visual understanding, critical for applications in embodied AI and remote collaboration. This task is exceptionally difficult due to severe changes in scale, perspective, and occlusion, which destabilize direct pixel-level matching. While recent geometry-aware models like VGGT provide a strong foundation for feature alignment, we find they often fail at dense prediction tasks due to significant pixel-level projection drift, even when their internal object-level attention remains consistent. To bridge this gap, we introduce VGGT-Segmentor (VGGT-S), a framework that unifies robust geometric modeling with pixel-accurate semantic segmentation. VGGT-S leverages VGGT's powerful cross-view feature representation and introduces a novel Union Segmentation Head. This head operates in three stages: mask prompt fusion, point-guided prediction, and iterative mask refinement, effectively translating high-level feature alignment into a precise segmentation mask. Furthermore, we propose a single-image self-supervised training strategy that eliminates the need for paired annotations and enables strong generalization. On the Ego-Exo4D benchmark, VGGT-S sets a new state-of-the-art, achieving 67.7% and 68.0% average IoU for Ego to Exo and Exo to Ego tasks, respectively, significantly outperforming prior methods. Notably, our correspondence-free pretrained model surpasses most fully-supervised baselines, demonstrating the effectiveness and scalability of our approach. Code is publicly available at: https://github.com/buaa-colalab/VGGT-S.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
VGGT-Segmentor: A Simple Explanation
What is this paper about?
This paper is about teaching a computer to find and precisely outline the same object in two very different camera views. Imagine one camera is on a person’s head (first-person or “ego” view) and another is across the room (third-person or “exo” view). The object might look bigger in one view, smaller in the other, or partly hidden. The paper introduces a method called VGGT-Segmentor (VGGT-S) that uses both 3D geometry and smart image features to do this accurately.
What questions are the researchers asking?
- How can we match and outline the same object seen from two very different angles and distances?
- Can we turn rough cross-view matching into a precise “mask” (the exact outline of the object) in the target view?
- Is it possible to train a strong model for this task without needing pairs of labeled images from both views?
How do they approach the problem?
First, here’s the challenge: The same object can look very different between ego and exo cameras because of:
- Scale changes (big up close, small far away)
- Perspective changes (different angles)
- Occlusions (hands or tools blocking part of the object)
To handle this, the authors build on a geometry-aware model called VGGT. Think of VGGT as a “view-bridging” tool: it learns about 3D structure (like depth and camera positions) and creates features that line up across different views. But while VGGT is good at understanding which regions correspond, it can be off by a bit at the exact pixel level (like placing points slightly shifted). VGGT-Segmentor fixes that.
Here’s the simple plan:
- Use VGGT to connect information across views (it knows the “where” in 3D).
- Add a new, lightweight module called the Union Segmentation Head to turn that cross-view knowledge into a sharp, pixel-accurate mask.
The Union Segmentation Head (three steps)
To make this easy to imagine, think of outlining an object in one picture and asking a friend to outline the same object in a second picture taken from somewhere else. Your friend uses three tricks:
- Mask Prompt Fusion
- The model takes the source image and its object mask (the outline you already have) and mixes that information into both the source and target image features.
- This is like telling the model, “Focus on this object’s shape and identity,” then sharing that hint with both views so they “talk” to each other.
- Point-Guided Prediction
- The model picks a few representative dots on the object in the source image (using a simple clustering method, like picking centers of different parts).
- VGGT tracks where those dots likely land in the target image.
- These tracked dots guide the model to the right area in the target view, even if the exact pixel positions are a bit off. It’s like placing a few pins on the object to say, “Look around here.”
- Mask Refinement
- Starting from a rough prediction, the model iteratively sharpens the mask: tightening edges and filling in parts that might be hidden.
- This step cleans up small errors and makes the outline crisp and accurate.
Training without paired labels: Single-Image Self-Supervised Training
Usually, you need pairs of labeled images (object outlined in both views) to train such systems. That’s expensive. The authors propose a clever shortcut:
- Take a single image and create a modified version (like scaling, rotating, or flipping it).
- Use a strong off-the-shelf segmenter to get a “pseudo” mask on the original image.
- Ask the model to find the same object in the modified image.
- They mix easy changes (where VGGT’s tracking still works) and hard changes (where tracking breaks), so the model learns to handle both mild and big viewpoint differences. This makes the model generalize well, even without true paired labels from two cameras.
What did they find?
On the Ego–Exo4D benchmark (a large dataset of matched first-person and third-person videos):
- VGGT-S sets a new state-of-the-art.
- It achieves about 67.7% IoU for Ego→Exo and 68.0% IoU for Exo→Ego. IoU (Intersection over Union) measures how well the predicted mask overlaps the true mask—the higher, the better.
- It beats previous top methods by big margins (for example, +18.0 and +12.8 percentage points over a strong baseline).
- Even when trained without explicit correspondence pairs (“zero-shot” style), VGGT-S still outperforms many fully supervised methods.
- It also transfers well to other datasets, showing strong generalization.
Why this matters:
- The method turns high-level “this region matches that region” knowledge into pixel-accurate outlines, which is exactly what robots, AR assistants, or remote collaborators need to interact with objects reliably.
Why is this important?
- For robots and AR: A robot assistant or an AR app might see from different angles than you do. Recognizing and outlining the same object across views lets them guide you (“Pick up that pot”) or learn from you (“Watch how I use this tool”) more accurately.
- For remote help: A remote expert can see a third-person camera and highlight an object, and your headset can precisely show you that same object in your view.
- Scalable training: Their self-supervised strategy lowers the need for expensive labeled data, making it easier to train on huge datasets and new environments.
In short
VGGT-Segmentor combines the best of both worlds: 3D-aware cross-view understanding (to know where to look) and a smart segmentation head (to get the exact outline). It works well even with tough viewpoint changes, needs fewer labeled pairs, and sets a new performance bar on a challenging real-world benchmark.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future research:
- Joint optimization of geometry and segmentation: The VGGT encoder is frozen; it is unclear whether fine-tuning VGGT (or adding adapters) jointly with the Union Segmentation Head could reduce point-projection drift and further improve dense mask accuracy.
- Explicit use of VGGT’s 3D outputs: The Union Segmentation Head does not explicitly leverage VGGT-predicted depth, camera parameters, or point maps (e.g., via epipolar constraints, differentiable warping, or 3D consistency losses). The impact of incorporating these signals is unstudied.
- Sensitivity to point-tracking errors: The method relies on VGGT’s tracked point prompts, yet no quantitative analysis connects mask IoU to the magnitude/distribution of projection drift, missed tracks, or outliers. Robust prompt weighting or uncertainty-aware gating for erroneous points is not explored.
- Point sampling strategy: Only K-Means over foreground coordinates is evaluated. Alternatives (e.g., boundary-aware sampling, Poisson disk, part-aware sampling, saliency- or feature-driven sampling, adaptive number of points by object scale/shape) and their impact on challenging objects (thin, multi-part, deformable) are not studied.
- Self-supervised training reliance on pseudo masks: The single-image training uses SAM/SA-1B pseudo masks, but the effect of pseudo-label noise, class bias, and mask quality on cross-view transfer is not quantified. Strategies for noise-robust training (mask denoising, confidence filtering, teacher–student bootstrapping) remain unexplored.
- Non-adaptive augmentation prompts: In VGGT-non-adaptive augmentations that break alignment, the paper mentions perturbing “target ground-truth points” to synthesize prompts; it is unclear how these points are derived in a correspondence-free setting. Alternative prompt synthesis without any target points (e.g., homography-based synthetic correspondences, 3D proxy transforms) should be clarified and evaluated.
- Lack of temporal modeling: Despite using video datasets, the method operates on image pairs and does not exploit temporal consistency, motion cues, or memory (unlike XView-XMem). The gains from incorporating spatiotemporal modules for occlusion handling and long-range consistency are unknown.
- Generalization to non-rigid/articulated objects: Performance under object deformation, articulation (e.g., tools in use, body parts), and state changes is not characterized. A per-category and per-motion-type breakdown would reveal limitations and guide model adaptations.
- Detecting absence and uncertainty calibration: The paper does not address cases where the queried object is fully occluded or absent in the target frame, nor provide uncertainty/confidence estimates. Designing abstention mechanisms and calibrated confidence scores is an open need for practical deployment.
- Multi-view scaling: The framework is pairwise. It is unclear how performance and complexity scale when aggregating information from multiple exocentric cameras or multi-ego/exo views, or how to fuse N-view prompts efficiently.
- Domain robustness: Beyond qualitative mentions (e.g., MAVREC in the supplement), quantitative evaluation across domains (outdoor, low light, motion blur, lens distortion, different camera intrinsics) is missing. The model’s sensitivity to VGGT failure modes under domain shift is unquantified.
- End-to-end latency and deployment metrics: Inference time excludes the remapping step and uses high-end GPUs. Real-time, end-to-end latency (including remapping/cropping) on commodity or embedded hardware, memory footprint, and energy are not reported.
- Memory-efficient fusion: Bottleneck Fusion at higher resolutions leads to OOM. Exploration of memory-efficient attention (linear/low-rank/Nyström), sparse or hierarchical fusion, and multi-scale feature coupling to improve accuracy without OOM is left open.
- Data scaling laws and sample efficiency: The effect of scaling self-supervised data beyond 1/20 SA-1B, varying epochs, or curriculum schedules, as well as the trade-offs in freezing vs fine-tuning the backbone, is not studied.
- Language-conditioned disambiguation: The method purposely avoids language cues; it remains unclear how integrating text prompts or lightweight language features (without LLM-heavy pipelines) could help in scenes with near-duplicate distractors.
- Error analysis and per-category breakdown: Results are reported as mean IoU without analyses by object type, size, visibility/occlusion level, viewpoint change magnitude, or distractor density. Such breakdowns would expose systematic weaknesses.
- Camera calibration errors: VGGT infers camera parameters; the segmentation head’s sensitivity to calibration inaccuracies and the potential benefits of calibration-aware training or test-time correction are unexplored.
- Training dynamics of Mask Refinement: Only the final iteration is backpropagated, and half of samples undergo refinement. The impact of alternative training schemes (deep supervision at all iterations, learned stopping criteria, or reinforcement of iteration count) is not assessed.
- Interactive correction: The system does not support human-in-the-loop prompts (clicks, strokes) to correct failure cases. Investigating how to incorporate interactive cues without retraining is an open avenue.
- Backbone modularity: Although related models (DUSt3R/MASt3R/SegMASt3R) are discussed, swapping VGGT with other geometry backbones and quantifying the impact on drift and segmentation accuracy is not evaluated.
- Distractor robustness metrics: While qualitative examples show improved distractor rejection, a quantitative metric (e.g., error rates under controlled numbers of visually similar distractors) is missing.
- Evaluation at native video rates: Ego-Exo4D masks are sampled at 1 FPS; performance at higher frame rates—or under rapid motion—remains unknown.
- Small/thin/transparent objects: The method’s behavior on small, thin, or low-contrast/transparent objects is not characterized; specialized point sampling and loss designs may be needed.
- Cropping/remapping strategies: The paper uses a cropping and remapping strategy but omits details and time in measurements. Ablations on crop policies (scale, context retention) and their effects on accuracy/latency are needed.
- Confidence-aware point–image attention: Cross-attention treats all prompts similarly. Learning prompt confidences (e.g., via uncertainty from the tracker) or robust weighting in attention could mitigate drift, but remains untested.
Practical Applications
Below is a distilled set of practical, real-world applications that follow from the paper’s core capability: robustly transferring an object mask between egocentric and exocentric views using geometry-aware cross-view segmentation with minimal correspondence supervision. Each item includes sector links, concrete tool/workflow ideas, and feasibility assumptions.
Immediate Applications
- Remote collaboration and AR assistance for field service and manufacturing
- Sectors: manufacturing, industrial maintenance, utilities, construction
- Tools/products/workflows: “Cross-view Object Spotlight” overlay for AR headsets and fixed workcell cameras; technician selects a tool/part in the headcam view (via a click or SAM mask), VGGT-S segments it in the overhead/third-person camera for remote expert guidance and QA checklists
- Assumptions/dependencies: two cameras with overlapping coverage; moderate latency acceptable (~160 ms per pair at 518×518 on a high-end GPU); source mask provided by user clicks or a promptable segmentor (e.g., SAM); deployment GPU at edge or on-prem
- Human-robot collaboration and teleoperation object handoff
- Sectors: robotics, warehousing, assembly
- Tools/products/workflows: robot controller uses a fixed camera; operator indicates the target object in headcam, VGGT-S transfers the mask to the robot’s view for grasp planning and collision-aware approach; integrated as a ROS node/SDK
- Assumptions/dependencies: overlapping FOV between human headcam and robot camera; sufficient lighting; pre- or on-the-fly camera alignment not strictly required but overlap is; GPU inference
- Multi-camera video editing, post-production, and VFX consistency
- Sectors: media/entertainment, sports production
- Tools/products/workflows: NLE/DCC plugin to propagate a rotoscoped mask from a POV clip to studio/broadcast cameras for object replacement, stylization, or privacy redaction across angles
- Assumptions/dependencies: offline batch processing acceptable; user-provided source mask; consistent object appearance across shots; GPU farm or local workstation
- Sports broadcasting and coaching analysis
- Sectors: sports analytics, broadcast
- Tools/products/workflows: real-time highlight of a player’s equipment (e.g., racket, bat) or the ball, selected in a POV training cam and transferred to broadcast cameras; augmented replay tools
- Assumptions/dependencies: sufficient frame overlap and similar time; latency budgets compatible with live enhancement; reliable masks or quick user prompts
- Retail and warehouse pick/pack verification
- Sectors: retail operations, logistics
- Tools/products/workflows: picker points to an SKU in headcam; system segments the same item in aisle/fixed cameras to confirm location, picking action, and shelf slotting; audit trails generated automatically
- Assumptions/dependencies: overlapping headcam–CCTV views; object-level masks can be generated quickly; controlled environments reduce occlusions
- Medical tele-mentoring and training
- Sectors: healthcare, medical education
- Tools/products/workflows: in a training OR/lab, mentor highlights an instrument in a surgeon’s headcam; VGGT-S segments it in room cameras for large-screen teaching feeds and archived annotations
- Assumptions/dependencies: non-diagnostic use; regulatory confines; properly de‑identified streams; overlapping views and stable lighting
- Security/forensics linkage between bodycams and fixed CCTV
- Sectors: public safety, corporate security
- Tools/products/workflows: forensic tool to transfer an object-of-interest mask from bodycam footage to relevant CCTV angles; speeds up evidence triage and timeline reconstruction
- Assumptions/dependencies: overlapping coverage in time/space; chain-of-custody logging; offline compute acceptable; clear visibility of target object
- Privacy-preserving redaction across views
- Sectors: policy/compliance, legal, media
- Tools/products/workflows: once a face/badge is masked in one view, VGGT-S propagates the mask to other concurrent cameras to ensure consistent redaction
- Assumptions/dependencies: consistent appearance; some overlapping views; alignment tolerance to occlusions; QA pass to catch edge cases
- Cross-view dataset annotation acceleration
- Sectors: academia, ML ops, dataset companies
- Tools/products/workflows: labeling tool that lets annotators draw a single mask in one view, then auto-propagates to other views; integrates with COCO-style or panoptic pipelines; triage UI to accept/refine predictions
- Assumptions/dependencies: training-free usage possible; correspondence-free pretraining is strong; annotator review loop remains necessary
- Research backbone for multi-view understanding
- Sectors: academia, R&D labs
- Tools/products/workflows: plug-in head for VGGT to study occlusion, viewpoint change, and instance correspondence; baselines for Ego→Exo challenges; ablation-friendly code
- Assumptions/dependencies: availability of the public repo; compatible PyTorch stack; GPU resources
- Drone/asset inspection cross-view focus
- Sectors: infrastructure, energy, telecom
- Tools/products/workflows: field tech marks a component on a handheld or helmet camera; VGGT-S highlights the same component in drone footage for targeted inspection and report generation
- Assumptions/dependencies: temporal proximity; sufficient overlap and scale; domain shift (outdoor, weather) manageable with light finetuning
Long-Term Applications
- Fully automated cross-view object retrieval without explicit masks
- Sectors: software, robotics, public safety
- Tools/products/workflows: natural-language or click-free selection (e.g., “find the exact mug from my POV in the building cameras”); combines VGGT-S with vision-LLMs to generate source masks and filter distractors
- Assumptions/dependencies: robust open-vocabulary instance identification; improved distractor handling; additional training on instance-level identity cues
- Real-time AR telepresence with sub-50 ms end-to-end latency
- Sectors: collaboration, enterprise productivity
- Tools/products/workflows: edge-deployed, quantized VGGT-S variants; pipeline-level optimizations (tiling, mixed precision, caching); 5G MEC integration
- Assumptions/dependencies: hardware acceleration (mobile NPUs/edge GPUs), model compression and distillation; network QoS guarantees
- Large-scale multi-camera facilities with persistent cross-view multi-object tracking
- Sectors: warehousing, retail, smart factories
- Tools/products/workflows: persistent identity and segmentation for many objects across dozens–hundreds of cameras, merged into 3D scene graphs and digital twins
- Assumptions/dependencies: scalable orchestration; multi-view scheduling; data association beyond pairwise masks; storage and privacy controls
- Safety-critical deployment in surgery and autonomous systems
- Sectors: healthcare, autonomous robotics
- Tools/products/workflows: certified modules for instrument/part segmentation across views used for safety checks, handoffs, and fail-safes
- Assumptions/dependencies: rigorous validation, formal verification, bias audits, and regulatory approvals; robust OOD handling and explainability
- Seamless integration with SLAM/NeRF for view-consistent scene editing and simulation
- Sectors: robotics simulation, digital content creation, digital twins
- Tools/products/workflows: fuse VGGT-S masks with 3D reconstructions to enable geometry-consistent object insertion/removal and synthetic data generation
- Assumptions/dependencies: tight coupling with real-time mapping; stable pose/depth priors; tooling for 2D–3D mask lifting
- Cross-modal and adverse-condition extensions (thermal, depth, radar)
- Sectors: defense, autonomous driving, industrial inspection
- Tools/products/workflows: cross-view segmentation from mixed modalities to handle low light, fog, or glare; modality-agnostic prompt fusion
- Assumptions/dependencies: multimodal pretraining corpora; sensor synchronization; domain adaptation techniques
- On-device/mobile deployment for consumer AR and smart home
- Sectors: consumer electronics, smart homes
- Tools/products/workflows: user points at an object with a phone; system finds it on home cameras to locate lost items or validate deliveries
- Assumptions/dependencies: efficient model variants (pruning/quantization); home camera interoperability; privacy/security-by-design
- Standardization and policy frameworks for cross-view datasets and privacy
- Sectors: policy, standards bodies, public sector
- Tools/products/workflows: protocols for consent-aware multi-view capture; benchmarks for cross-view redaction quality; guidance on data retention and auditability for cross-camera inference
- Assumptions/dependencies: multi-stakeholder collaboration; clear legal/regulatory mandates; public datasets with privacy scaffolding
- Automated multi-object, open-world correspondence under extreme domain shift
- Sectors: logistics, outdoor robotics, agriculture
- Tools/products/workflows: track many deformable and look-alike objects across moving cameras with large baselines; integrate self-supervised continual learning
- Assumptions/dependencies: stronger geometry-semantic fusion; curriculum for hard negatives; scalable self-supervision with domain-aware augmentations
- Creative tools for cross-view storytelling and education
- Sectors: education, media/arts
- Tools/products/workflows: lesson capture that toggles between POV and classroom cameras while preserving object-of-interest overlays; interactive textbooks linking multiple views
- Assumptions/dependencies: content-authoring pipelines; easy author prompts; robust handling of occlusions in dynamic classrooms
Notes on practical deployment and configuration derived from the paper
- Recommended setup for strong accuracy/latency trade-off: 518×518 input resolution, 5 point prompts, 2 refinement iterations, 2 decoder blocks; average per-pair inference ~160 ms on an RTX 4090.
- Source mask creation: promptable segmentation (SAM/SAM2) or a single click; this can be user-driven or automated from text via a vision-language front-end.
- Training/finetuning pathways:
- Immediate: use the public VGGT-S code and weights; optionally apply the single-image self-supervised strategy on in-domain unlabeled footage to adapt without paired annotations.
- Long-term: domain-specific finetuning with multimodal data, quantization-aware training for edge devices, and integration with tracking/SLAM stacks.
- Key dependencies/assumptions across use cases: overlapping camera views (temporal and spatial), at least moderate object visibility, access to a capable GPU/edge accelerator, and data governance for multi-camera processing.
Glossary
- AdamW: An optimizer that combines Adam with decoupled weight decay to improve generalization. "For optimization, we use AdamW~\cite{loshchilov2017decoupled}, with an initial learning rate of and a weight decay of ."
- Average Precision (AP): An evaluation metric summarizing precision–recall across thresholds. "the resulting AP reaches 80.7\%."
- attention map: A visualization of where a model attends in an image. "the corresponding attention map on the target image"
- Bottleneck Fusion: A module that fuses source and target features at a reduced spatial resolution via attention and MLPs. "we introduce a Bottleneck Fusion module that integrates self-attention (SelfAttn), feed-forward network (FFN) as well as downsampling and upsampling "
- contrastive similarity learning: Training strategy that pulls matched instances together and pushes mismatched ones apart in embedding space. "for contrastive similarity learning, enabling robust zero-shot tracking"
- cross-attention: An attention mechanism that lets one set of tokens attend to another (e.g., points to image features). "point-to-image and image-to-point cross-attention (CrossAttn):"
- cross-view segmentation: Segmenting the same object across different camera views. "a geometry-enhanced cross-view segmentation framework"
- dense prediction: Tasks producing per-pixel outputs like depth or masks. "fail at dense prediction tasks"
- DINO-style stem: A ViT-based patch embedding front-end used to tokenize images. "each image is patchified by a DINO-style~\cite{caron2021emerging} stem"
- Dice loss: A segmentation loss based on overlap (Dice coefficient) between predicted and ground-truth masks. "a linear combination of focal and dice losses"
- downsampling: Reducing the spatial resolution of features to lower compute and fuse information. "downsampling and upsampling (ratio ):"
- DPT-style head: A decoder that upsamples and fuses tokens into spatial feature maps for dense prediction. "A DPT-style~\cite{ranftl2021vision} head, which is a decoder for dense prediction that upsamples and fuses tokens into spatial feature maps"
- egocentric: First-person camera viewpoint. "egocentric and exocentric views"
- Ego–Exo4D: A large-scale dataset of synchronized first- and third-person videos for ego–exo correspondence. "With the release of the large-scale EgoâExo4D dataset~\cite{grauman2024ego}"
- exocentric: Third-person camera viewpoint. "egocentric and exocentric views"
- feed-forward network (FFN): The MLP sub-layer within transformer blocks. "feed-forward network (FFN)"
- feature map: A spatial grid of learned features produced by a network. "source feature map "
- focal loss: A loss that down-weights easy examples to focus on hard ones, used in segmentation/detection. "a linear combination of focal and dice losses"
- geometry-aware: Incorporating 3D geometric information into a model’s representations. "geometry-aware models like VGGT"
- Intersection over Union (IoU): Overlap metric between predicted and ground-truth masks. "the evaluation metric is the mean Intersection over Union (IoU)"
- Instance-level correspondence: Matching and segmenting the same object instance across views. "Instance-level correspondence aims to establish matches for object instances across different views"
- K-Means algorithm: A clustering method used here to pick representative mask points. "using K-Means algorithm~\cite{lloyd1982least}"
- keypoint correspondence: Matching distinctive points across images to establish geometric relationships. "scene geometry and keypoint correspondence"
- large baselines: Significant camera viewpoint differences that make matching difficult. "struggle with non-rigid motion and large baselines"
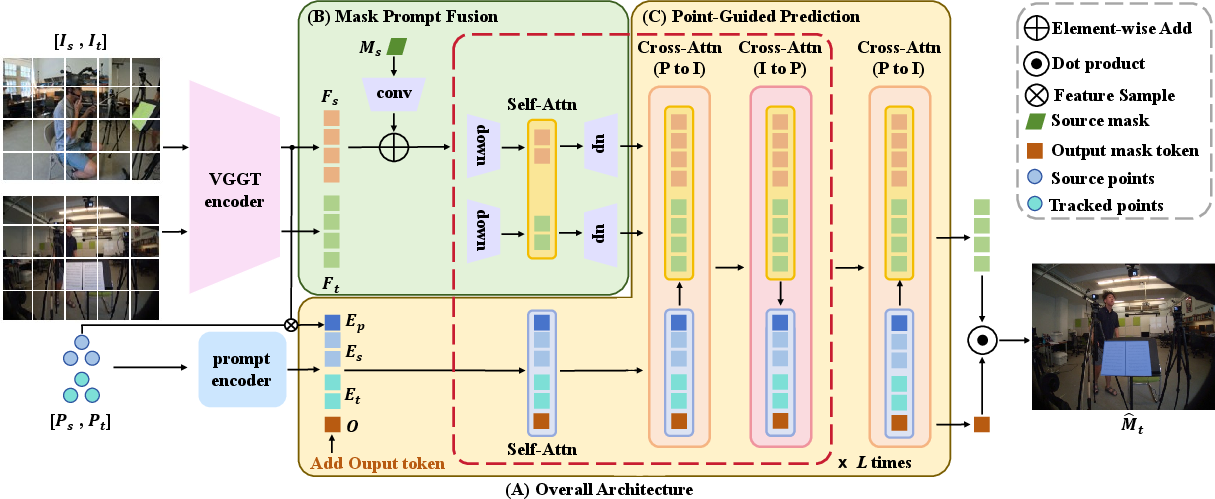
- Mask Prompt Fusion: Stage that injects the source mask signal into source/target features to guide segmentation. "Mask Prompt Fusion, where two-view images are encoded by VGGT and then fused with the source-view object mask feature."
- Mask Refinement: Iterative procedure to sharpen boundaries and handle occlusions in predicted masks. "Mask Refinement, which refines the predicted mask by iteratively optimizing object boundaries and filling occluded regions."
- multi-view geometric consistency: Ensuring features/estimates agree across multiple views given 3D geometry. "VGGT \cite{wang2025vggt} is a vision model for multi-view geometric consistency"
- multi-view stereo: Reconstructing 3D structure from multiple images by matching pixels across views. "multi-view stereo~\cite{seitz1999photorealistic,furukawa2015multi,huang2018deepmvs}"
- non-rigid motion: Deformations where object shape changes over time, complicating matching/reconstruction. "struggle with non-rigid motion and large baselines"
- out-of-memory (OOM): Failure due to exceeding available GPU memory. "causes out-of-memory (OOM) issues during training"
- panoptic segmentation: Unified task combining instance and semantic segmentation. "panoptic segmentation~\cite{kirillov2019panoptic}"
- patchified: Converting an image into non-overlapping patches for ViT processing. "each image is patchified"
- Point-Guided Prediction: Stage that uses tracked sparse points to guide target mask prediction. "Point-Guided Prediction, where VGGT tracks points from the source mask and outputs a set of coarsely projected points in the target view"
- point maps: 2D–3D or inter-view point correspondences predicted by a model. "camera parameters, and point maps across multiple views"
- pixel-level projection drift: Misalignment when projected points deviate from their correct pixel locations. "significant pixel-level projection drift"
- prompt encoder: Module that embeds guidance prompts (e.g., points) into latent vectors. "A prompt encoder maps points to embeddings"
- self-attention: Mechanism where tokens attend to each other to aggregate contextual information. "integrates self-attention (SelfAttn)"
- Single-Image Self-Supervised Training: Training paradigm using augmentations of a single image and pseudo-masks without paired annotations. "Single-Image Self-Supervised Training"
- sigmoid function: Activation mapping logits to probabilities for per-pixel mask prediction. "and is the sigmoid function."
- spatio-temporal modeling: Methods that use both spatial and temporal information. "âType STâ denotes spatio-temporal modeling."
- State-of-the-art (SOTA): Best reported performance on a task. "VGGT-S sets a new SOTA"
- structure-from-motion: Reconstructing 3D structure and camera motion from image sequences. "structure-from-motion~\cite{lowe2004distinctive, calonder2010brief, agarwal2011building, schonberger2016structure, yi2016lift, wei2020deepsfm, shi2022clustergnn, wang2024vggsfm}"
- track head: Network component that predicts point correspondences across frames/views. "VGGT's track head provides point prompts on the target view."
- transformer: Attention-based neural architecture used for sequence and vision tasks. "As a large transformer driven by visual geometry"
- Union Segmentation Head: The proposed multi-stage head that fuses prompts, points, and features for cross-view masks. "introduces a novel Union Segmentation Head."
- upsampling: Increasing spatial resolution of feature maps to recover details. "upsampling "
- ViT-based patch embedding: Converting image patches into tokens for a Vision Transformer. "a ViT-based patch embedding approach"
- weight decay: Regularization term that penalizes large weights during optimization. "a weight decay of "
- zero-shot learning: Setting where a model is evaluated without task-specific supervised training data. "âZSLâ denotes the zero-shot learning results."
Collections
Sign up for free to add this paper to one or more collections.