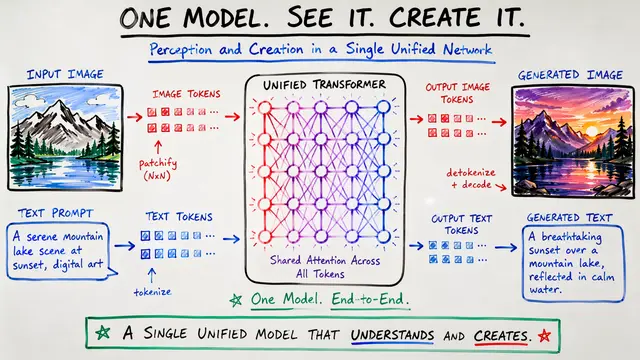
UniFork: Y-Shaped Transformers for Multimodal AI
This presentation explores UniFork, a novel Y-shaped Transformer architecture that addresses the core challenge of building unified models for both image understanding and generation. By sharing shallow layers for semantic grounding while splitting into task-specific branches for deep processing, UniFork overcomes representational conflicts that plague traditional unified approaches, demonstrating superior performance on both visual comprehension and image synthesis tasks.Script
Imagine trying to build a single AI model that can both understand images like a critic and create them like an artist. These two tasks seem to pull the model in opposite directions, creating a fundamental tension that has puzzled researchers building unified multimodal systems.
Let's start by understanding why this problem is so difficult to solve.
Building these unified models promises elegant simplicity, where one architecture learns to excel at multiple visual tasks simultaneously. However, sharing the same backbone creates devastating task interference that undermines this vision.
The authors discovered that understanding and generation have fundamentally different alignment needs at various network depths. When forced to share representations, the model creates a compromise that satisfies neither task effectively.
Enter UniFork, which takes a share-then-split approach to resolve this conflict.
UniFork implements a clever Y-shaped design where early layers build shared semantic understanding, then the network branches into specialized pathways. This architecture allows each task to develop its optimal internal representations without interference.
The key insight comes from analyzing modality alignment patterns using mutual k-nearest neighbors. Understanding tasks benefit from ever-stronger text-image alignment, while generation needs early semantic grounding followed by representational independence to reconstruct fine visual details.
Now let's examine how the researchers built this architecture in practice.
The implementation uses standard components assembled in a novel way. They chose VILA-U tokenization over VAE approaches due to training efficiency, and maintain the simplicity of autoregressive next-token prediction throughout.
Training progresses through careful stages, starting with visual feature alignment, then joint optimization, and finally independent fine-tuning of each branch. This staged approach eliminates the need for delicate cross-task data balancing that plagues other unified models.
The modular design allows researchers to explore the spectrum from fully shared to fully split architectures. At inference time, only the relevant branch activates, keeping computational costs reasonable while maintaining the benefits of shared early learning.
Let's see how well this approach works in practice.
On understanding benchmarks, UniFork delivers impressive results that rival specialized models. The branched architecture successfully preserves visual question answering and reasoning capabilities while enabling generation functionality.
Generation results validate the core hypothesis about representational needs. The specialized generation branch successfully recovers fine-grained visual details that would be lost in a fully shared architecture.
Most importantly, the alignment analysis confirms that UniFork successfully recovers the desired task-specific patterns. Each branch develops exactly the modality alignment behavior that theory predicts for optimal performance.
The authors are transparent about current limitations that constrain performance.
The researchers acknowledge several bottlenecks, particularly around visual tokenization quality and scale limitations. The tokenizer was trained at 256 resolution while UniFork operates at 384, creating potential spatial mismatches.
These findings open several promising research directions.
Future work promises to scale these insights across modalities and model sizes. The shared-then-split principle could revolutionize how we build truly general multimodal AI systems that excel at both understanding and creation.
This work fundamentally changes how we think about unified multimodal models. Instead of fighting task interference through careful data balancing, UniFork shows that smart architectural choices can eliminate the conflict entirely while preserving the benefits of shared learning.
UniFork demonstrates that the key to unified multimodal AI isn't forcing tasks to share everything, but knowing exactly when and how to let them diverge. Visit EmergentMind.com to explore more cutting-edge research that's reshaping how we build intelligent systems.