Best of Both Worlds: Multimodal Reasoning and Generation via Unified Discrete Flow Matching
This presentation explores UniDFlow, a breakthrough unified multimodal framework that seamlessly integrates language model reasoning with diffusion-based visual generation. The talk demonstrates how discrete flow matching enables a single model to excel at both understanding and creating images, overcoming the traditional separation between comprehension and generation tasks while achieving state-of-the-art performance across multimodal benchmarks.Script
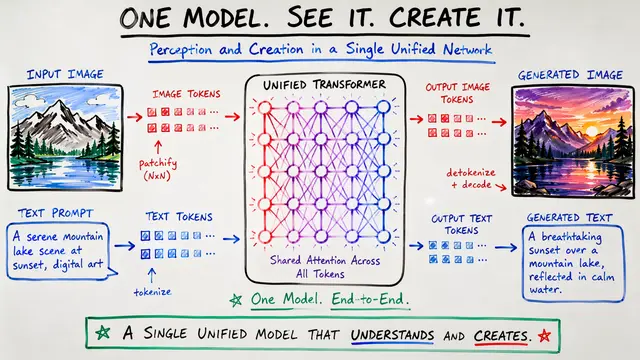
Imagine if a single AI could both understand your creative vision and bring it to life visually. The researchers behind UniDFlow have bridged this gap, creating a unified framework that combines language model reasoning with diffusion-based image generation.
Building on that vision, let's examine the fundamental problem they set out to solve.
Continuing from this challenge, the authors identified a critical limitation in current AI systems. While language models understand complex instructions and diffusion models create stunning images, these capabilities remain isolated in separate architectures, preventing truly integrated multimodal intelligence.
The breakthrough comes through an elegant technique called discrete flow matching.
Building on discrete flow matching, the authors designed a three-stage training process that keeps language understanding and visual generation separate until the final integration. This decoupling prevents the models from interfering with each other while learning their specialized tasks.
Looking at the training pipeline more closely, the first two stages independently optimize language and vision capabilities using specialized adapters. The third stage then brings these together with a sophisticated router that dynamically blends the models based on the task at hand, achieving seamless multimodal performance.
A key technical insight here is the Time-Step Guided RMSNorm, which maintains the stability of pretrained features during the challenging process of aligning different modalities. This innovation prevents the catastrophic forgetting that often plagues multimodal training.
This figure showcases the remarkable versatility of UniDFlow in handling complex reasoning tasks that require both deep comprehension and creative generation. Notice how the model seamlessly transitions between understanding nuanced instructions and producing contextually appropriate visual outputs, something that required separate systems before.
Moving to the results, UniDFlow doesn't just match existing systems, it surpasses them. The authors demonstrate that their unified approach outperforms even larger specialized models across multiple benchmarks, proving that integration and efficiency can beat raw parameter counts.
The implications extend far beyond benchmark numbers. By proving that reasoning and generation can coexist in a unified architecture, this work fundamentally changes how we think about building multimodal AI systems for real-world applications.
UniDFlow demonstrates that the future of AI isn't about choosing between understanding and creation, but harmonizing both in a single, elegant framework. Visit EmergentMind.com to explore the full paper and discover more cutting-edge research.