- The paper introduces a dual-role framework where a single LLM alternates as agent and environment to dynamically bootstrap performance.
- Methodologies include World-In-Agent for predictive reward assignment and Agent-In-World for failure-driven curriculum generation.
- Empirical results show significant gains over baseline methods on ALFWorld, WebShop, and search-augmented QA benchmarks.
Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
Introduction
Role-Agent addresses the limitations of current LLM agents constrained by sparse feedback and static, non-adaptive environments, which hinder effective generalization in multi-step, dynamic tasks. The central innovation is the dual-role methodology, employing a single LLM that alternates between agent and environment roles to enable closed-loop, bootstrapped co-evolution. The framework is instantiated through two synergistic mechanisms: World-In-Agent (WIA), which modulates reward and credit assignment by integrating predictive state alignment, and Agent-In-World (AIW), which systematically analyzes failure trajectories for targeted data redistribution.
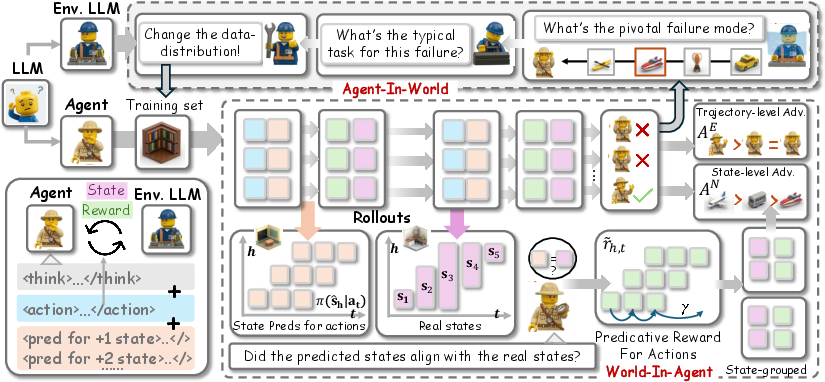
Figure 1: Architecture of Role-Agent, detailing the cyclical role-switching LLM, predictive reward flow, and closed-loop task curriculum adaptation.
Role-Agent is positioned at the intersection of agentic RL for LLMs and recent efforts in self-evolving agent systems. While agentic RL such as PPO, GRPO, and GiGPO leverages rollout-based policy optimization and grouped advantage estimation, previous pipelines leave the environment fixed. Recent works on agent memory, process-based rewards, and tool-use (e.g., (Liu et al., 2023, Wang et al., 21 May 2025)) emphasize agent-side improvements, but do not enable true environment adaptation.
Role-Agent's approach contrasts with multi-role systems (e.g., MAE (Chen et al., 27 Oct 2025))—here the same LLM interprets both agentic and environmental feedback, supporting adaptive task redistribution and reward reshaping without reliance on auxiliary models or human-supplied schedules.
Methodology
World-In-Agent (WIA): Predictive Credit Assignment
WIA extends conventional outcome-based RL by requiring the agent to predict environment states for H steps ahead after every action, instantiating a lightweight world model within the agent’s policy update. The alignment between predicted and realized states is used to produce a predictive reward matrix via the Longest Matching Subsequence metric. This matrix is used as a multiplicative modulator on top of standard task returns, so credit is reliability-aware—reward is amplified only when action consequences are genuinely anticipated by the agent.
(Trajectories and predictions are grouped via hash mapping and grouped-state similarity; advantage assignment thus incorporates both trajectory-level return (outcome) and state-level prediction quality, weighted via hyperparameter α.)
Agent-In-World (AIW): Failure-Driven Curriculum Generation
AIW supplies dynamic, self-diagnosed environmental adaptation. The LLM, when assuming the environment role, analyzes failed rollouts to extract structured failure modes—recording the dominant error category, irremediable mistake step, core lesson for generalization, and a retrieval query signature. These signatures are then used for hard-negative mining: the environment role retrieves and foregrounds tasks that share analogous failure causes, focusing further optimization directly on persistent deficiencies.
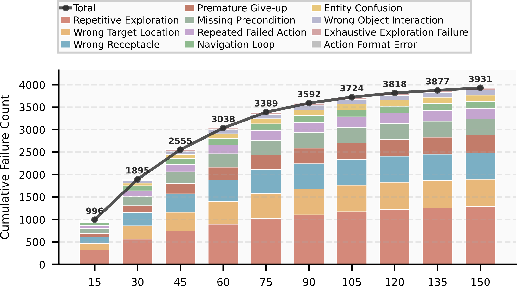
Figure 2: Temporal evolution of failure mode accumulation in ALFWorld via the AIW module, demonstrating emergence and saturation of exploitable agent weaknesses.
This cyclical feedback introduces a dynamic curriculum, continuously reshaping the sampling distribution within the training set.
(Figure 1 shown earlier captures the full agent-environment interaction loop.)
Experimental Results
Benchmarks and Baselines
Role-Agent is evaluated on ALFWorld (text-based embodied tasks), WebShop (web interaction), and several search-augmented QA benchmarks (NQ, TriviaQA, HotpotQA, 2WikiMultiHopQA, MuSiQue, Bamboogle). RL and non-RL baseline methods include PPO, GRPO, GiGPO, RLOO, prompting-based pipelines (ReAct, Reflexion), and closed-source APIs (GPT-4o, Gemini-2.5-Pro).
Implementation Notes: All methods use Qwen2.5-1.5/3/7B-Instruct backbones, maintaining controlled hyperparameters. GiGPO is taken as the most competitive RL baseline, utilizing state-grouped advantage.
Role-Agent consistently improves average performance over all competitive baselines, with the most pronounced gains observed against GiGPO:
- ALFWorld: +4.2%–4.8% success rate uplift over GiGPO for 1.5B/7B backbones.
- WebShop: +6.9% improvement on main metrics.
- Search-augmented QA: +3.7% average improvement, most obviously on chain-of-reasoning datasets (8.2% gain on 2Wiki, 5.2% on MuSiQue).
Improvements concentrate on complex tasks demanding robust state tracking, memory, and compositional reasoning.
Ablation, Efficiency, and Sensitivity
Ablations indicate both WIA and AIW are necessary for optimal performance; removing dynamic failure-driven curriculum (AIW) causes a larger degradation than removing predictive reward. The two components are strictly complementary, and even ablated Role-Agent variants outperform GiGPO.
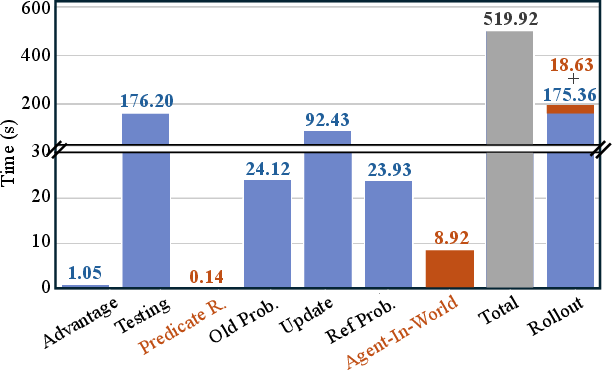
Figure 3: Runtime analysis: Role-Agent induces approximately 5.2% overhead per step compared to GiGPO, with negligible cost for predictive rollouts and failure analysis steps.
Sensitivity analysis demonstrates that moderate values for the predictive horizon (H=5%⋅Tmax) and balancing coefficient (α=1) are optimal; excessive predictive prompting causes in-context budget waste and performance dilution.
Running curves show Role-Agent converges faster and achieves higher asymptotic performance, and importantly, reduces train-inference mismatch—measured by diminished difference in rollout policies between training and evaluation phases.
Case Studies
Qualitative analyses of failure trajectories reveal that Agent-In-World triggers curriculum adaptation via semantically grouped failure causality, e.g., MISSING_PRECONDITION or WRONG_TARGET_LOCATION (see appended case studies). Retrieval by underlying error pattern instead of surface details enables efficient remediation of deep weaknesses.
Discussion and Implications
Role-Agent validates the principle that LLM-based agents in open, interactive tasks benefit fundamentally from agent-environment co-evolution—achieved here with a single, multiplexed model. The closed-loop, reliability-aware optimization path increases generalization, reduces reward hacking, and explicitly surfaces inductive biases in reasoning, planning, and semantic grounding.
By eschewing manual reward function engineering and static data distributions, Role-Agent opens the door to fully automated agent development pipelines, with long-term significance for multi-agent, multi-modal, and lifelong learning scenarios.
Limitations include the reliance on text-encoded state representations (limiting easy adaptation to non-linguistic or high-dimensional observation spaces), and fixed thresholds in state similarity grouping that may inhibit cross-task transfer. Extensions to vision-language agents, richer world models, or truly open-ended environments are warranted.
Conclusion
Role-Agent introduces a formalism for single-LLM bootstrapped agent-environment co-evolution, demonstrating strong empirical gains over state-of-the-art RL and curriculum learning advances. By integrating internal world modeling and dynamic, failure-driven task redistribution, Role-Agent achieves notable improvements in compositional reasoning, long-horizon planning, and robustness to distributional shift. The approach provides a scalable blueprint for future LLM agent systems in open, feedback-sparse, and dynamic domains.
Figure 2: Visualization of accumulated failure mode-driven tasks during Role-Agent training, emphasizing the increased coverage of agent failure patterns.
Figure 3: Step-wise runtime breakdown benchmarking overheads of Role-Agent versus GiGPO during rollouts.
References
For full technical details, dataset definitions, and ablations, see "Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution" (2606.10917).