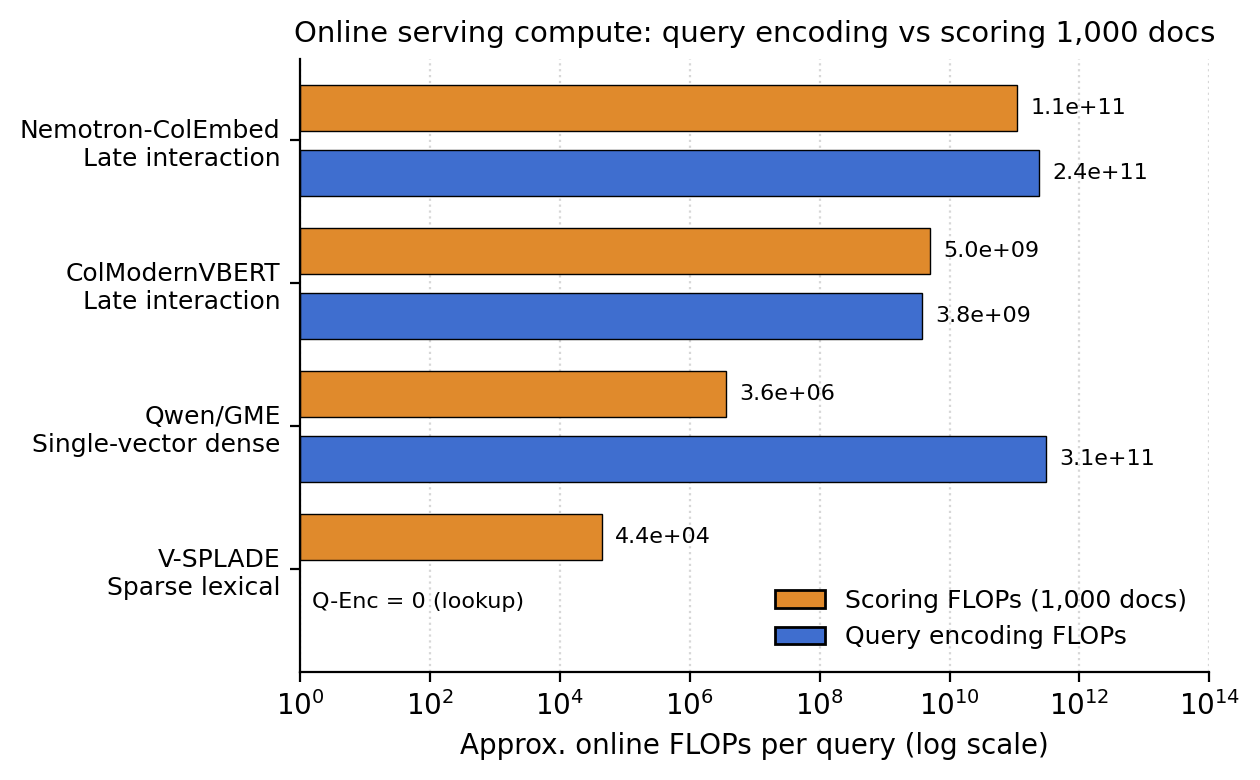
- The paper introduces V-SPLADE, a novel sparse lexical retriever that indexes visual documents without runtime neural query encoding through caption-gated token supervision.
- It adapts a compact vision-language model to project image inputs into a vocabulary-indexed sparse space, achieving up to +13.8 NDCG@5 improvement over dense alternatives.
- Empirical results demonstrate scalability with 20× faster encoding and robust recall on an 18.7M-document corpus, underpinning its production-scale deployment.
Inference-Free Multimodal Learned Sparse Retrieval for Production-Scale Visual Document Search
Introduction and Motivation
The proliferation of large-scale visual-document corpora, such as arXiv and enterprise PDFs, has created acute demands for scalable and efficient visual-document retrieval. Traditional pipelines center on neural dense or multi-vector representation with vision-LLMs (VLMs), excelling in retrieval quality but incurring prohibitive costs at serving time due to runtime neural encoding. Alternatively, OCR- or caption-based pipelines enable query-encoding-free lexical retrieval (e.g., with BM25), albeit with the drawback of expensive and slow upstream text extraction or caption generation.
"Inference-Free Multimodal Learned Sparse Retrieval for Production-Scale Visual Document Search" (2605.30917) presents V-SPLADE, a novel sparse lexical retriever directly indexing visual documents and fulfilling a critical, previously unmet serving regime: production-scale, query-encoding-free retrieval without neural query overhead or reliance on costly upstream pipelines. Central to this advance is the diagnosis and resolution of a lexical grounding problem: existing sparse encoders struggle to reliably activate relevant lexical dimensions from image inputs, impeding retrieval performance under high sparsity.
Lexical Grounding Problem in Visual-Document Sparse Retrieval
Text-based learned sparse retrieval models (e.g., SPLADE) achieve robust lexical matching as the token inputs directly map to vocabulary indices. In contrast, images of documents lack explicit token anchors—lexical information must be inferred from visual cues rather than explicit word tokens, resulting in only partial coverage of actual lexical content in the output sparse representation. The diagnostic study demonstrates a large gap in overlap with source BoW between text and image representations (e.g., at top-30: 0.974 for text vs. 0.560 for rendered image). This lexical grounding deficit constrains the effectiveness of sparse retrieval in visual domains.
Caption-Gated Token Supervision
To remediate this grounding deficit, the authors propose caption-gated token supervision as a training-only signal, leveraging VLM-generated captions as lexical cues. During training, both the rendered document image and its offline-generated caption are encoded into the same vocabulary-indexed sparse space. The caption sparse vector "gates" the image vector—only dimensions corroborated by both views are reinforced, while others are suppressed. This intersection expands recall of lexical dimensions actually present in the underlying document, even when the image encoder alone would miss them.
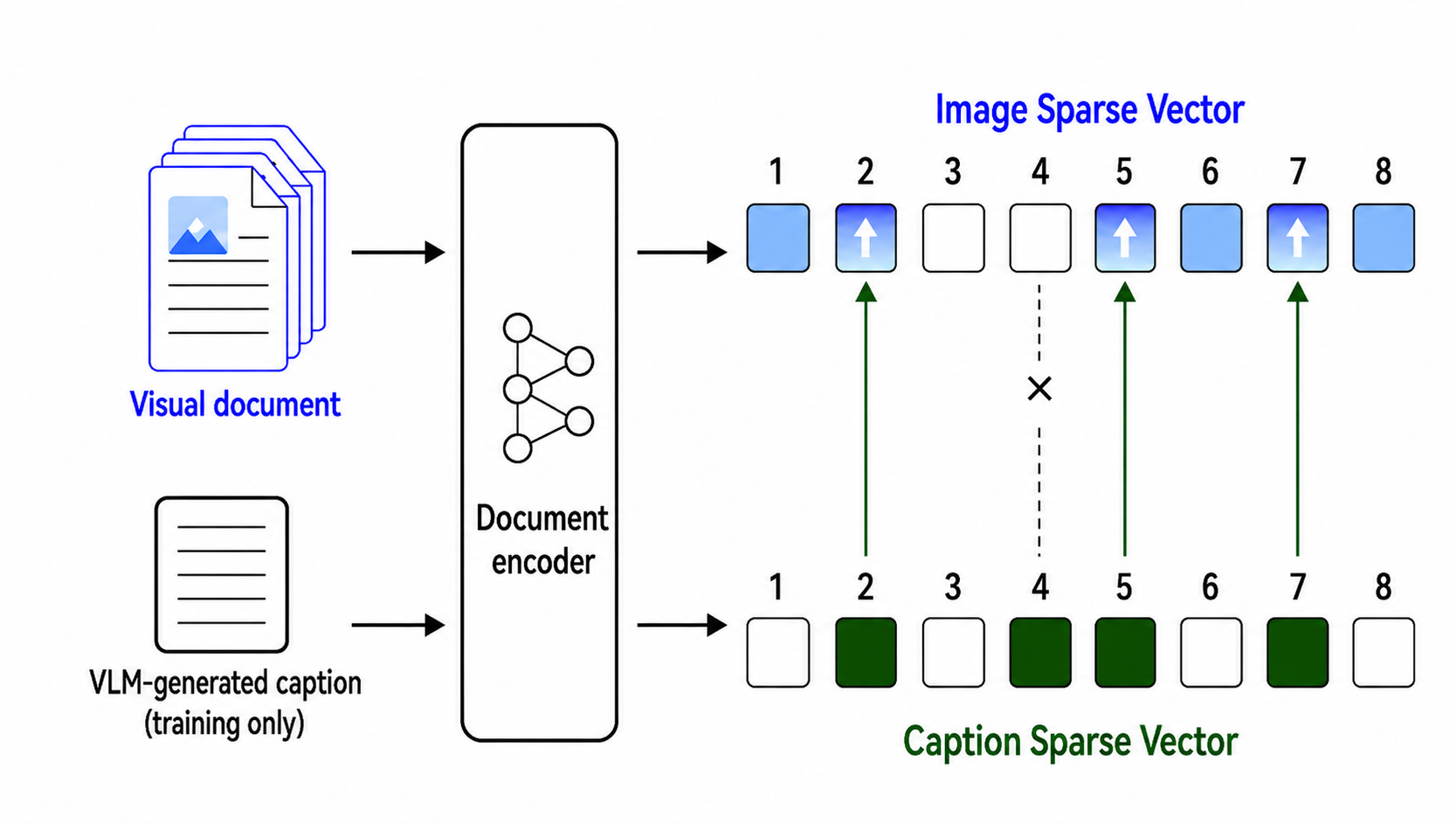
Figure 1: Caption-gated token supervision overview.
At inference, only the image encoder is used, ensuring efficient, inference-free deployment.
V-SPLADE Architecture
V-SPLADE adapts SPLADE for visual-document retrieval by employing a compact vision-language backbone (ModernVBERT, ~250M parameters) with an LM head for projecting visual hidden states into a vocabulary-indexed sparse representation. Query representation is handled using Li-LSR–style inference-free, learned token lookup, further optimized for stability by adopting softplus activation (instead of ReLU) for visual sparse regimes.
Key scoring and ranking mechanisms:
- Retrieval is based on sparse lexical dot product between query and document sparse vectors.
- Training employs an InfoNCE batchwise loss, a separate ranking loss on captions, and a Flops regularizer to enforce sparsity.
Empirical Results
Retrieval Quality:
On six public visual-document retrieval benchmarks, V-SPLADE (quality variant):
- Outperforms BiModernVBERT (same ~250M parameter, state-of-the-art dense retriever) by +13.8 NDCG@5 points.
- Surpasses OCR- and caption-based BM25 approaches by up to +6.3 NDCG@5 points.
Scalability:
On an 18.7M-document corpus:
- V-SPLADE achieves R@5 of 0.228 (vs. 0.090 for dense baseline).
- Encoding is 20× faster than state-of-the-art caption or OCR pipelines.
- Sparse retrieval retains recall more robustly under corpus scaling relative to dense alternatives.
Latency:
Corpus Scaling Robustness:
Dense R@5 drops to 35% of its 500K-corpus performance at 18.7M scale; V-SPLADE retains 54%, showing greater scalability.
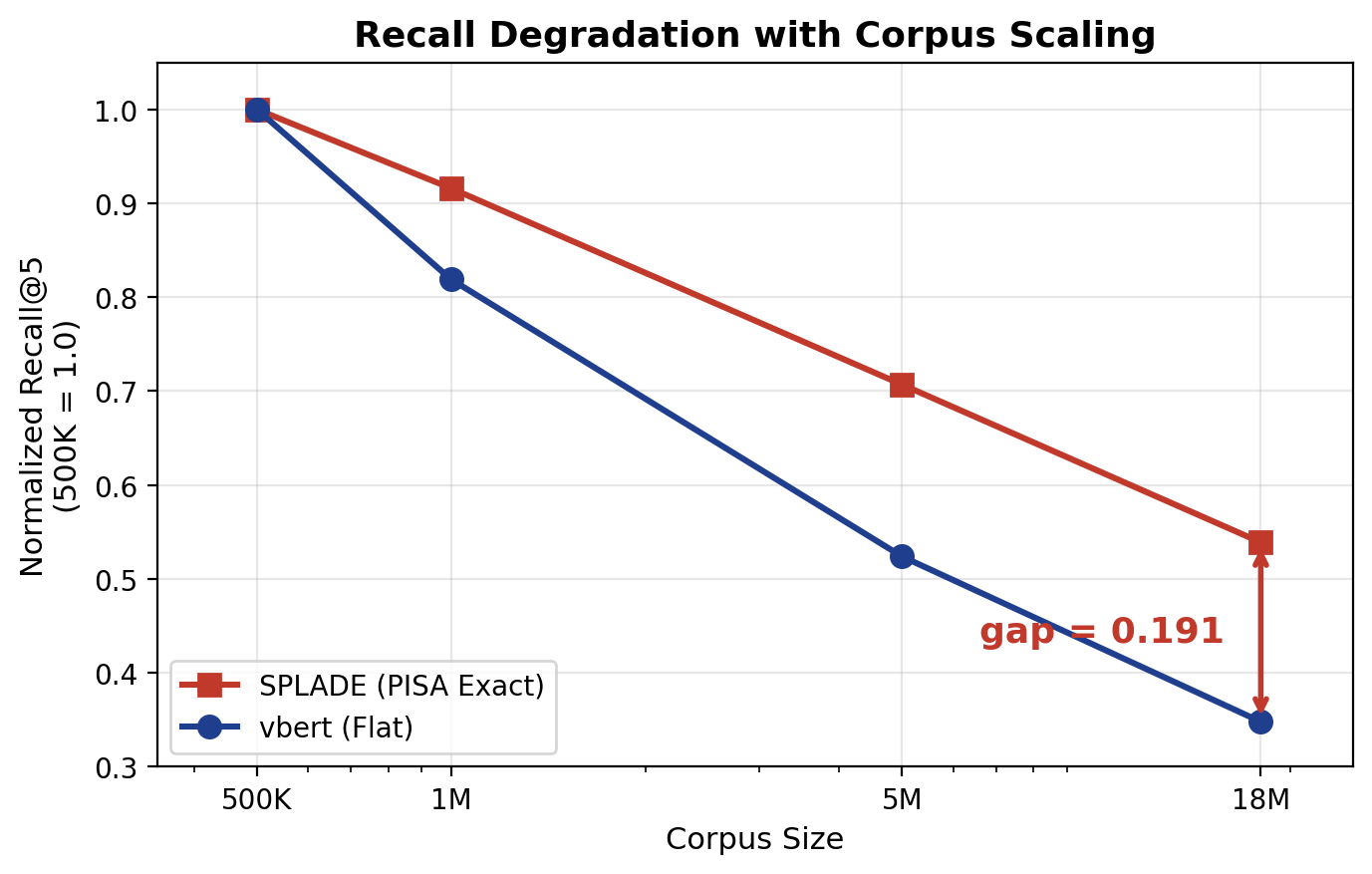
Figure 3: Normalized recall degradation with corpus scaling (R@5, normalized to 500K = 1.0).
Complementarity with Neural Retrieval:
Score fusion with neural retrievers (e.g., BiModernVBERT, Qwen3-VL-Embedding-2B) yields up to +2.4pp R@5 improvement; V-SPLADE also serves as a strong first-stage retriever for multi-vector reranking, improving downstream recall ceiling.
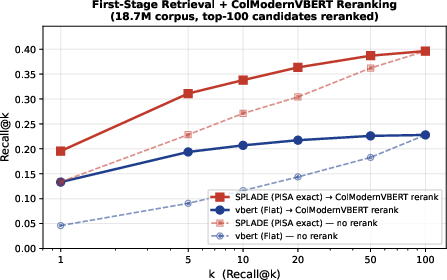
Figure 4: Two-stage retrieval with ColModernVBERT reranking.
Precision on Lexically Specific Queries:
Largest gains observed on queries involving numerals or capitalized tokens (proper nouns), with R@5 increases up to +0.228 absolute points relative to dense baselines.
Token-Level Analysis:
Caption-gated supervision increases contentful token activation, reduces reliance on stopwords, and improves ranking margins. The mechanism induces complementary token sets between passage and caption sparse representations, providing distinct and synergistic lexical evidence for retrieval.
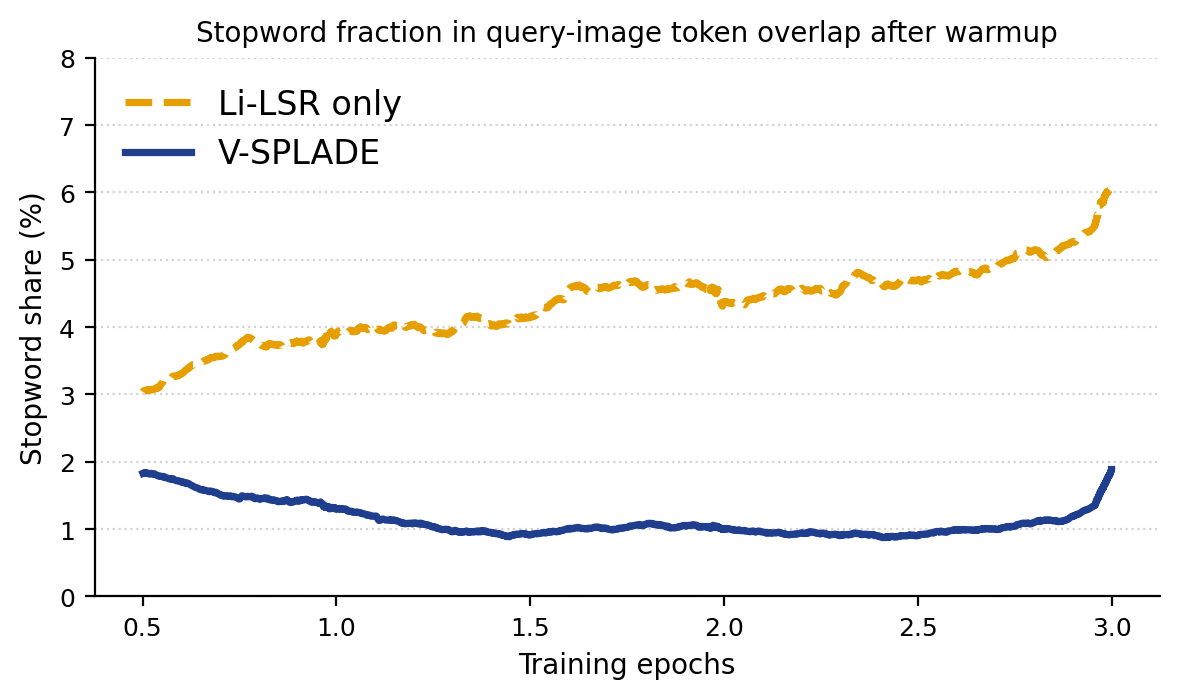
Figure 5: Stopword fraction among query--image overlap.
Theoretical and Practical Implications
The work sets a new standard for scalable, production-grade visual-document retrieval in environments where neural query encoding is cost-prohibitive. The lexical grounding bottleneck is a fundamental limitation in vision-based sparse models; the caption-gated supervision strategy improves sparse retriever performance for document images without runtime overhead or reliance on slow, upstream text extraction.
Practically, V-SPLADE enables:
- Deployment for massive-scale, low-latency retrieval scenarios (e.g., search over tens of millions of scientific papers or business documents).
- Seamless integration as a complementary lexical layer to dense and multi-vector systems, facilitating hybrid pipelines.
- Significant latency and throughput improvements over pipeline-based lexical alternatives (OCR, caption generation).
Theoretically, the findings highlight:
- The inherent capacity limits of fixed-dimension dense retrieval under corpus scaling.
- The benefit of expanding the support for lexical evidence via hybrid multimodal signals, and the pitfalls of relying on image-only supervision for sparse token recovery.
Future Directions
Potential future research avenues include:
- Extension and evaluation on multilingual document corpora and other modalities (e.g., video, natural images).
- Scaling to larger VLM backbones and exploring prompt-controlled, region-adaptive captioning strategies.
- Investigating the transferability of lexical grounding techniques to broader multimodal tasks beyond retrieval.
Conclusion
V-SPLADE establishes inference-free, lexically grounded sparse retrieval as a competitive and scalable solution for visual-document search. By addressing the lexical grounding challenge via caption-gated token supervision, it achieves strong empirical results across diverse benchmarks and at production scale, while remaining highly complementary to dense and multi-vector retrieval architectures. This positions it as a practical foundation for next-generation information retrieval systems targeting large, heterogeneous visual-document corpora.