- The paper introduces SAE-SPLADE, which replaces traditional token-based representations with a latent, concept-driven space learned via Sparse Auto-Encoders to address polysemy and synonymy.
- The approach uses a two-stage training paradigm, pre-training on contextual embeddings followed by fine-tuning with KL-divergence and MarginMSE distillation, optimized via TopK sparsity constraints.
- Empirical results demonstrate that SAE-SPLADE achieves near-parity in retrieval effectiveness with advanced baselines while significantly reducing computational cost and improving multilingual IR.
SAE-SPLADE: A Latent Concept Approach to Sparse Retrieval
Introduction
The paper "From Tokens to Concepts: Leveraging SAE for SPLADE" (2604.21511) introduces SAE-SPLADE, a novel framework for sparse neural information retrieval (IR) that replaces the traditional token-based vocabulary of models like SPLADE with a latent, concept-driven space learned via Sparse Auto-Encoders (SAEs). The core motivation is to overcome limitations inherent in backbone vocabulary dependencies—such as issues of polysemy, synonymy, and restricted adaptability to multilingual and multi-modal settings—by leveraging semantic units that are empirically derived from contextualized embeddings.
Architecture and Training Paradigm
SAE-SPLADE fundamentally restructures the SPLADE pipeline by replacing the MLM-based vocabulary prediction head with a trainable SAE module. The SAE is pre-trained to reconstruct dense contextualized representations generated from a frozen encoder (e.g., DistilBERT or BERT), producing highly sparse latent activations. Following pre-training of SAE, the decoder is removed, and only the encoder part is integrated into the relevance modeling pipeline typical of SPLADE. Document-level representations are then aggregated using SPLADE-style max pooling in the latent space (Figure 1).
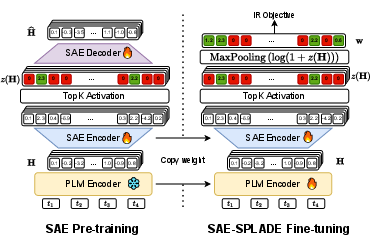
Figure 1: The SAE-SPLADE model architecture—pre-training the SAE on contextual representations, then integrating the encoder for document-level aggregation via SPLADE pooling.
A two-stage training procedure is established: pre-training the SAE for robust concept extraction, and subsequently fine-tuning the IR model (SAE-SPLADE) using standard retrieval objectives, including KL-divergence and MarginMSE distillation, coupled with FLOPs-based regularization for controlling sparsity.
The study presents exhaustive experiments evaluating the impact of key architectural hyperparameters, SAE design choices, and training procedures. SAE-SPLADE is primarily benchmarked on the MS MARCO in-domain collection, TREC-DL tracks, Out-of-Domain (OoD) LoTTE Search, and the BEIR suite for generalization.
The token-to-latent transition is interrogated through the following:
- Vocabulary Size and Latency Control: It is demonstrated that increasing SAE latent vocabulary size yields marginal improvements in IR effectiveness, with M=216 selected as a practical maximum balancing effectiveness with computational cost.
- Sparsity Constraint Analysis: The TopK SAE mechanism constrains token activations, with ablations over k=2 to k=32. Results indicate that moderately higher k values (8 or 16) maximize the trade-off between efficiency (sparsity) and retrieval accuracy (Figure 2, Figure 3).
- FLOPs Regularization: TopK constraint exerts stronger influence over sparsity/efficiency than standard regularization terms, and careful tuning of k is the preferred axis for latency-effectiveness adjustments.
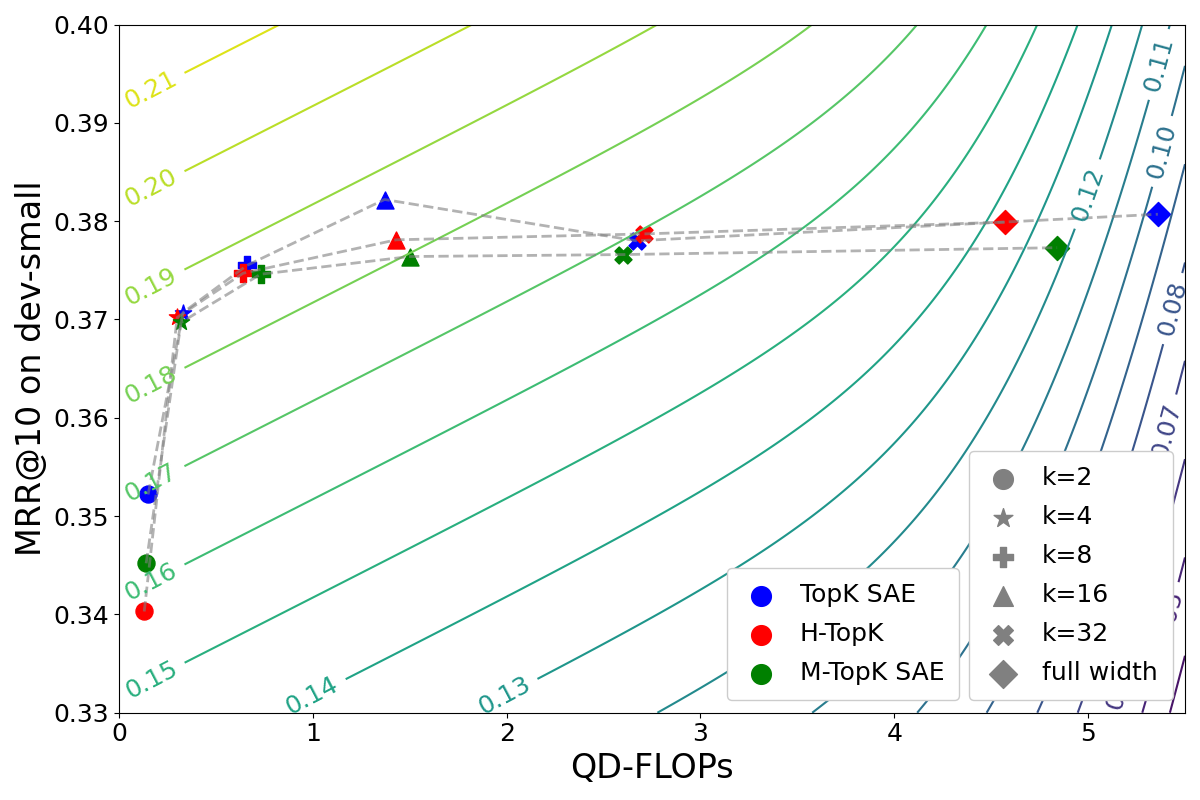
Figure 2: SAE-SPLADE effectiveness (MRR/nDCG) versus efficiency (QD-FLOPs) for varying values of kSPLADE; contour lines denote ΔE (efficiency-effectiveness trade-off score).
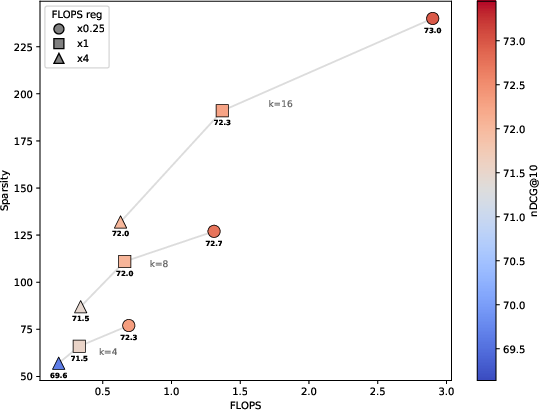
Figure 3: Effectiveness and QD-FLOPs as a function of k and FLOPs regularization; demonstrates that TopK-based sparsity dominates regularization-induced sparsity.
Key empirical findings include:
- SAE-SPLADE with k=8 achieves nearly identical retrieval effectiveness to the best-trained SPLADE and SPLADEv3 baselines on all evaluated benchmarks, while requiring substantially less computational cost—e.g., QD-FLOPs for documents is reduced by 2×.
- The new efficiency-effectiveness measure k=20 establishes that models using top-k=21 constraints on both SAE and MLM heads consistently outperform unconstrained SPLADE for the same accuracy budget.
- SAE-SPLADE is more robust than standard dense retrievers (like SimLM) and approaches the trade-off curve of more advanced multi-vector models such as ColBERTv2, at a fraction of the disk and inference cost.
Theoretical and Practical Implications
Vocabulary Independence and Multilingual IR
A salient contribution is the demonstration of the empirical advantage of SAE-SPLADE in multilingual retrieval. By decoupling the output space from the input tokenization, SAE-SPLADE enables better alignment across languages, evidenced by higher cross-lingual overlap of active latents without compromising document sparsity or IR quality. The approach surpasses the SPLADE baseline for multilingual benchmarks and narrows the gap with leading (but more resource-intensive) multilingual models.
Semantic Interpretability and Analysis of Learned Latents
Through qualitative analysis, the paper provides compelling evidence that SAE-derived latents capture coherent semantic units. Individual latents correspond to clusters of synonym tokens (see Table of synonym/latent groupings), and ambiguous (polysemantic) tokens activate distinct latents in different contexts. This structuring potentially addresses the shortcomings in vocabulary mismatch, offering a better model for representing entities, synonyms, or disambiguated senses—limitations that persist in lexicalized IR systems.
Limitations and Prospects for Future Work
Notwithstanding its strong results, the paper acknowledges that:
- The gap with large-scale, more sophisticated multilingual or cross-lingual alignment models (e.g., MILCO) is non-trivial. Integration of alignment or larger backbones could further improve SAE-SPLADE.
- The "semantic entanglement" of latents—i.e., some overlap in meaning between latents—likely stems from the tension between the reconstruction objective of SAE and the discriminative IR task. This suggests further work in designing IR-specific sparse encoders.
- The combination of lexical exact-matching and semantic concept matching remains an open area; hybrid models that fuse both signals may provide additional gains, particularly for long or noisy queries.
Conclusion
SAE-SPLADE demonstrates that a learned semantic latent space, acquired via unsupervised sparse autoencoding and fine-tuned for relevance, is a highly competitive foundation for sparse neural retrieval. This approach delivers comparable accuracy to state-of-the-art token-based models, but markedly improves latency and cross-lingual generalization. Concept-based vocabularies induced by SAEs offer a strong alternative to fixed lexicalizations, redefining efficiency-effectiveness frontiers in both monolingual and multilingual IR contexts. Further advances are likely through IR-targeted latent modeling and deeper integration with cross-lingual alignment strategies.