REST3D: Reconstructing Physically Stable 3D Scenes from a Single Image
Abstract: Reconstructing physically stable 3D scenes from a single RGB image enables casual images to be converted into simulation-ready digital assets for applications such as immersive interaction and content creation. However, existing single-image reconstruction methods fall short in capturing the physical structure of a scene. As a result, they often produce geometrically plausible but physically inconsistent results, including object floating and penetration, which lead to unstable behavior in physics simulations. Image-conditioned scene generation methods improve physical plausibility but often rely on strong scene priors, yielding plausible yet inaccurate object arrangements that fail to match the input image. We propose REST3D, a single-image reconstruction framework that can reconstruct physically stable 3D scenes by integrating physical scene understanding with physics-constrained refinement. We first introduce an agentic physical scene understanding technique that constructs a scene-tree representation capturing object physical states and inter-object relationships from a gravity-support perspective, providing a structural prior for reconstruction. Leveraging this structure, we initialize the scene using image-to-3D models, followed by scene-tree-guided alignment and physics-constrained optimization to resolve physical violations while preserving visual consistency with the input image. Experiments show that our method significantly reduces physical errors and improves simulation stability on both synthetic and real-world datasets while maintaining strong reconstruction quality. We further demonstrate the reconstructed scenes in VR-based human-object interaction, showing their potential for immersive applications.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
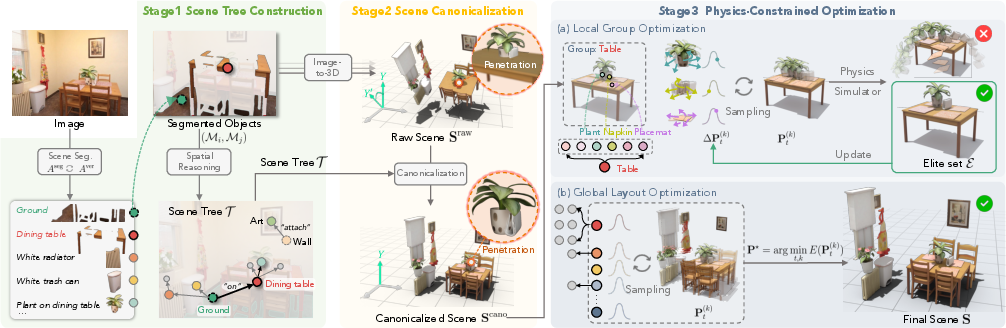
The paper introduces REST3D, a method that can turn a single photo of a room into a 3D scene that not only looks right but also behaves correctly under physics. In other words, when you drop these 3D objects into a virtual world with gravity, they won’t float, slide, or pass through each other—they rest where they should.
What questions did the researchers ask?
They focused on two simple but important questions:
- From just one photo, can we rebuild a 3D scene that looks like the original picture?
- Can we make sure the scene also makes sense physically—so objects sit on surfaces, don’t intersect, and stay stable when simulated?
Most earlier methods did one of these well (either looked right or followed physics) but not both at the same time.
How did they do it?
The method works in three main stages. Think of it like rebuilding a room from a photo and then gently “wiggling” things until they settle into a safe, stable arrangement.
- Stage 1: Understand the scene like a careful observer
- The system uses a smart vision-LLM (an AI that can see and read) to list the objects in the picture (for example, “a plant on the table” instead of just “plant”).
- It finds each object’s outline (mask) in the image.
- It builds a “scene tree,” which is like a family tree of support: who rests on what. For example, the table rests on the floor; the lamp rests on the table; a poster is attached to the wall. This support tree is gravity-aware.
- Stage 2: Build a first 3D version and align it with gravity
- Each object is turned from its 2D mask into a 3D model and placed into the scene (position, size, rotation).
- Then the whole scene is “canonicalized,” meaning it’s rotated so “up” matches gravity, and objects are nudged so children rest on their parents (like a plant being set on top of its table instead of floating slightly above it).
- Stage 3: Make the scene physically stable with a simulator
- The system uses a physics simulator (a virtual sandbox with gravity and collisions) to test different small adjustments to object positions and rotations.
- It tries many tiny changes, keeps the best ones, and repeats. This process is similar to taking many shots at a target and slowly adjusting your aim based on which shots landed closest.
- The goal is to minimize:
- Instability (objects moving or tipping after the simulation runs),
- Collisions/overlaps (objects intersecting),
- And big changes from the original look (it still needs to match the photo).
- It first fixes smaller groups (like a table and the items on it), then refines the whole scene together so everything works globally.
What did they find, and why does it matter?
- Their method greatly reduces common problems like floating objects, objects sinking into each other, or items falling over when the simulation starts.
- Across several datasets (including both synthetic scenes and real photos), their scenes were far more stable than those made by other methods, while still looking like the original image.
- Even in challenging, casual photos (like bedrooms and living rooms from the internet), the method made scenes that stayed put under physics and were ready for virtual interaction.
- They showed this in a VR demo where users can interact with objects in real time—grabbing and moving things without the scene collapsing.
Why it matters:
- It makes single photos useful for games, VR/AR, and content creation by producing “simulation-ready” 3D scenes.
- It saves time: you don’t have to hand-fix floating objects or broken layouts after reconstruction.
- It bridges the gap between “looks right” and “works right,” which is essential for realistic virtual worlds.
What’s the impact and what’s next?
Impact:
- Creators can turn everyday photos into interactive 3D spaces for VR, training robots, education, or design.
- The method keeps both appearance and physics in mind, so scenes are believable and reliable.
Limitations and future directions:
- The system depends on strong vision-LLMs to understand scenes; it may struggle with very cluttered or unusual images.
- It currently focuses on rigid objects (like tables and chairs), not flexible or soft items (like curtains or pillows).
- Future work could add non-rigid objects, better object shapes, and even richer physical effects.
In short: REST3D takes a single photo, figures out who-supports-what like a smart builder, creates the 3D scene, and then uses a physics “shake test” to gently settle everything into a stable, realistic layout—ready for games, VR, and interaction.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Robustness of VLM-driven scene understanding: No systematic analysis of failure modes (e.g., heavy occlusion, small objects, clutter, atypical layouts, domain shifts such as cartoons or industrial scenes) or calibration/uncertainty estimates for VLM outputs used in object listing, mask verification, and support inference.
- Scalability of agentic segmentation: The iterative
seg–verloop with SAM3 and Gemini is potentially expensive; the paper does not report runtime, sample-efficiency, or scaling behavior as object count grows (e.g., >50–100 instances), nor strategies to bound iterations or parallelize. - Limited relation taxonomy: Support inference is constrained to “on/hanging/attached” and four roots (
ground,wall,ceiling,ground-wall); richer relations (e.g., “inside”, “leaning against”, “between”, “under”, “supported by multiple objects”) and non-Manhattan/oblique supports are not modeled. - Multi-support and contact complexity: The
ground-wallspecial case does not generalize to arbitrary multi-contact scenarios (e.g., shelves, corner supports, objects wedged between surfaces); methods to infer and enforce multiple contacts are absent. - Physical properties not estimated: Mass, density, center-of-mass, friction and restitution coefficients, material compliance/rigidity, and joint constraints are not inferred from the image, yet strongly affect stability; defaults are used without validation or sensitivity analysis.
- Rigid-only assumption: Deformable and non-rigid objects are explicitly out of scope; no pathway is proposed for integrating cloth, cushions, cables, or flexible attachments into the pipeline.
- No treatment of articulated objects: Hinges, sliders, and kinematic joints (e.g., doors, drawers, lamps) are not reconstructed or constrained, limiting fidelity and interaction realism.
- Absolute scale and camera ambiguity: Single-image scale and camera intrinsics/extrinsics are underconstrained; the paper does not detail how global scale is determined or validated (beyond SAM3D estimates), nor how errors here affect physical metrics.
- Room envelope and support geometry: The method uses canonical support roots but does not describe how floor/wall/ceiling geometry is reconstructed for contact in simulation (e.g., planar proxies vs. full envelope recovery), nor evaluate errors from misestimated support planes.
- Wall/ceiling objects handled by heuristics: Final placement of wall/ceiling-attached objects is a heuristic postprocess rather than part of the physics-constrained optimization, risking inconsistency with the rest of the pipeline.
- Lack of photometric/image-consistency constraints: Physics optimization uses a layout deviation penalty relative to the canonicalized scene but does not leverage image render-and-compare (silhouette/pixel/feature) losses that could better preserve visual fidelity.
- Collision modeling limitations: Penetration checks use convex hulls and GJK; concave geometry and fine interlocking contacts are not handled, potentially misjudging collisions and stability.
- Optimization efficiency and practicality: The CEM setup (e.g.,
K=2048samples ×T=15iterations × two stages ×L=60sim steps) is potentially costly; no comprehensive runtime/compute budget, memory footprint, or latency analysis is provided for typical scene sizes. - Sensitivity to hyperparameters: Energy weights and CEM settings are not clearly specified (some omitted in text) and no sensitivity analysis is reported; robustness to these choices and reproducibility across implementations are unclear.
- Optimization design choices: The use of diagonal-covariance Gaussians in CEM ignores correlated pose updates across objects; alternatives (full covariance, CMA-ES, differentiable physics, gradient-based methods, learned proposal distributions) are not explored.
- Convergence and correctness guarantees: The hierarchical local-then-global strategy lacks theoretical or empirical convergence analysis; conditions under which the optimizer diverges or oscillates are not characterized.
- Evaluation limited to one simulator: All physical metrics are computed in Isaac Gym; cross-engine generalization (e.g., MuJoCo, Bullet, PhysX) and sensitivity to physics solver parameters (time step, contact solver, friction models) are not evaluated.
- Metrics vs. scene fidelity trade-offs: The paper notes CD/F-score can prefer interpenetrating layouts; however, no new metric is proposed to jointly assess geometric fidelity and physical validity, and no perceptual/user-based evaluation is conducted.
- Quantitative assessment of scene-tree accuracy: The correctness of inferred object lists, masks, and support relations is not measured (e.g., precision/recall, relation accuracy) against annotated ground truth, making it hard to diagnose failure sources.
- Handling heavily occluded or hidden supports: The pipeline does not detail strategies for inferring unseen support surfaces/objects (e.g., shelves behind objects), or using priors to reason about missing geometry.
- Generalization beyond indoor scenes: Experiments focus on replica-like indoor scenes; outdoor, industrial, multi-level, or highly non-Manhattan environments are untested.
- Dataset and annotation gaps: The custom dataset lacks ground-truth geometry; no plan is outlined to collect or release benchmarks with annotated support relations and physical properties for standardized evaluation.
- VR interaction evaluation: The VR demo shows feasibility but lacks user studies, task-based benchmarks, latency/stability measurements under real interactions, or evaluations of how reconstruction errors impact user experience.
- Failure detection and fallback: The system does not include mechanisms to detect unreliable VLM/segmentation outputs, flag uncertain scene-tree edges, or degrade gracefully (e.g., request user input) when confidence is low.
- Integration with stronger image-to-3D models: Although claimed “model-agnostic,” the approach is only demonstrated with SAM3D; performance with alternative or higher-fidelity object reconstruction backbones remains untested.
- Domain adaptation and bias: VLM and segmentation performance across styles (e.g., cartoons) and camera artifacts (motion blur, HDR, low light) is not quantified; strategies for domain adaptation or prompt engineering are not discussed.
- Dynamics beyond static stability: The objective optimizes for settled, quasi-static states; tasks involving dynamic interactions (e.g., pushing, stacking robustness, perturbation resilience) are not evaluated or optimized.
Practical Applications
Practical Applications of REST3D
REST3D converts a single image into a simulation-ready 3D scene by (a) inferring a gravity-aware scene-tree of object supports via VLM agents, (b) canonicalizing orientation/supports, and (c) running physics-constrained optimization in a simulator to eliminate floating/penetration and enforce stability. Below are actionable use cases, tagged by sector, deployment horizon, and key dependencies.
Immediate Applications
The following can be piloted or integrated with existing tools now (e.g., Isaac Gym/Sim, Omniverse, Blender, Unity/Unreal, web viewers).
- Robust photo-to-VR room for immersive interaction
- Sectors: software (VR/AR), gaming, media
- Workflow: take a photo → run REST3D → export USD/glTF → import into Unity/Unreal/Omniverse → enable native physics/hand-interaction (as shown in the paper’s 30 FPS VR demo)
- Product idea: “Photo-to-VR” Unity/Unreal plugin with automatic colliders and gravity alignment
- Dependencies/Assumptions: strong image-to-3D/VLM performance; rigid-object scenes; user consent/privacy for personal spaces; GPU for CEM-based optimization
- Rapid level blockout and asset staging for games
- Sectors: gaming, VFX
- Workflow: designer drops a reference photo → receives a stable 3D blockout with auto-placed colliders → iterate in engine
- Tools: Blender or DCC add-on to export clean meshes and collision shapes
- Dependencies/Assumptions: object fidelity may be coarse; occluded content is not reconstructed; scale may require manual calibration
- Interior design ideation and product staging from a single photo
- Sectors: retail/e-commerce (furniture), real estate, AEC
- Workflow: convert customer room photo → stable 3D layout → drag-and-drop furniture with correct supports and non-penetrating placement
- Product idea: Web configurator that exports glTF/USD for AR previews
- Dependencies/Assumptions: absolute scale and material realism may need manual adjustment; limited view coverage
- Synthetic data generation for vision models
- Sectors: AI/ML, robotics
- Workflow: generate photo-derived, physically stable scenes → render novel views/poses for detectors, pose estimators, grasp models
- Tools: Omniverse Replicator, BlenderProc
- Dependencies/Assumptions: domain gap to real scenes; licensing for use of user photos; scene scale annotation improves utility
- Fast scene prototyping for robot simulation and manipulation tasks
- Sectors: robotics, embodied AI
- Workflow: capture a workstation/desk photo → REST3D → import into Isaac Sim/Gazebo → test grasp, placement, or collision-avoidance with stable contact physics
- Dependencies/Assumptions: occluded obstacles may be missing; friction/contact parameters must match target hardware; rigid-only assumption
- Safety and HSE micro-training in VR from site photos
- Sectors: industrial safety, construction, manufacturing
- Workflow: convert site snapshot → stable 3D → script hazard scenarios in VR (spills, clutter)
- Dependencies/Assumptions: photo must capture the relevant hazards; not a certified safety record; scale verification needed
- Quick scene reconstruction for insurance triage and claims discussion
- Sectors: insurance
- Workflow: claim adjuster obtains a room photo → 3D stable layout → basic measurements/visualization to triage and communicate damage
- Dependencies/Assumptions: not for legal-grade measurement; privacy and chain-of-custody policies; scale uncertainty unless calibrated
- Museum/education demos of statics and contacts
- Sectors: education, museums, outreach
- Workflow: students convert photos of tabletops/shelves → experiment with gravity, friction, and support relations in simulators
- Dependencies/Assumptions: simplified materials; rigid-only interactions
- 3D object extraction for marketplaces and asset libraries
- Sectors: 3D content platforms, e-commerce
- Workflow: per-object masks and meshes extracted from a photo → catalog entries with plausible scale and orientation
- Dependencies/Assumptions: occlusion and partial geometry; attribution and license compliance for user-provided images
- QA for 3D reconstruction pipelines
- Sectors: computer vision, 3D software
- Workflow: use REST3D’s stability metrics (collision rate, drift, velocities) as acceptance criteria for reconstructed scenes before delivery to clients
- Dependencies/Assumptions: availability of a simulator; material/contact parameters standardized per project
Long-Term Applications
These require further research (e.g., faster inference, scale guarantees, non-rigid modeling), standardization, or broader deployment.
- On-device, real-time photo-to-AR room anchoring
- Sectors: mobile AR, consumer tech
- Vision: run REST3D on-phone or via edge to produce gravity-aligned, stable 3D anchored in ARKit/ARCore; interactively edit furniture
- Dependencies/Assumptions: latency and power constraints; fast VLM/segmentation; robust scale estimation
- Home and hospital robot pre-deployment planning from casual images
- Sectors: robotics, healthcare
- Vision: clinicians or users capture a snapshot of a room → generate a digital twin to vet assistive robot paths and manipulation tasks
- Dependencies/Assumptions: high-fidelity scale and semantics; policy for protected health information; non-rigid/fabric modeling for beds, linens
- Automated accessibility and safety checks from photos
- Sectors: policy/regulation, AEC, facilities
- Vision: estimate clearances (e.g., ADA), reach envelopes, and hazard zones from images; auto-generate compliance reports
- Dependencies/Assumptions: validated scale calibration; regulatory acceptance; uncertainty quantification and auditing
- Semi-automated BIM and facility inventory from sparse photos
- Sectors: construction, facility management
- Vision: convert scattered site images to stable 3D snapshots that bootstrap BIM updates and asset inventories
- Dependencies/Assumptions: multi-view integration; metadata linking; variant handling for complex MEP elements
- Forensics and disaster response planning from limited imagery
- Sectors: public safety, emergency response
- Vision: approximate 3D layouts from a few images to reason about paths, occlusions, and object supports
- Dependencies/Assumptions: legal admissibility; rigorous uncertainty bounds; scene generalization across degraded/outdoor conditions
- Large-scale “photo-to-sim” datasets for RL and embodied AI
- Sectors: AI/ML research
- Vision: scale up REST3D across millions of web images to build diverse, physically consistent RL environments
- Dependencies/Assumptions: compute for CEM + simulation; licensing and privacy; automated quality control
- Non-rigid, deformable, and articulated scene reconstruction
- Sectors: graphics, robotics
- Vision: extend REST3D to cloth, cables, plants, and articulated furniture for higher realism and task coverage
- Dependencies/Assumptions: new reconstruction models and simulators; richer material parameter inference
- Retail fit-check and appliance placement verification
- Sectors: retail/e-commerce, smart home
- Vision: from a single photo, verify if a product fits/attaches properly (e.g., wall-mounted units, refrigerators) under gravity and contact constraints
- Dependencies/Assumptions: precise scale and wall/anchor inference; customer guidance for calibration (checkerboard, phone LiDAR)
- Cultural heritage and archival reconstructions
- Sectors: museums, cultural preservation
- Vision: reconstruct approximate, stable 3D representations from historical photos for exhibits and education
- Dependencies/Assumptions: strong generative priors to complete occlusions; curatorial review and provenance
- Standardization of “simulation-ready from images” for industry pipelines
- Sectors: software, standards bodies
- Vision: define export schemas (USD, glTF) with stability tags, support graphs, and contact parameters for downstream engines
- Dependencies/Assumptions: consensus on metadata fields; cross-engine validation (Unreal, Unity, Omniverse)
Cross-Cutting Dependencies and Assumptions
- Single-image limitations: occlusions and unseen regions are not reconstructed; multi-view fusion improves coverage.
- Rigid-object focus: current pipeline assumes rigid bodies; deformables/articulations require future extensions.
- Scale calibration: absolute scale is often ambiguous in single images; add a known reference or user-in-the-loop calibration to improve measurements.
- Physics parameters: simulator friction/restitution/contact settings affect stability; standardize per application.
- VLM/segmentation robustness: errors in object masks and support relations propagate; human verification or confidence thresholds can mitigate.
- Domain coverage: indoor and tabletop scenes perform best; outdoor/complex industrial scenes need adaptation.
- Compute/runtime: CEM with thousands of samples per iteration is GPU-intensive; batching and reduced candidate counts can trade speed vs. optimality.
- Privacy and compliance: photos of personal spaces may contain sensitive information; ensure consent, secure storage, and policy compliance.
Glossary
- 6-DoF pose: A pose representation with three rotational and three translational degrees of freedom. "represented by a 6-DoF pose."
- Agentic: Refers to using autonomous agents to plan or execute parts of a pipeline. "We first introduce an agentic physical scene understanding technique..."
- B-IoU: Boundary Intersection over Union; a metric evaluating overlap between predicted and ground-truth boundaries. "[email protected] (F-Score), and B-IoU"
- Chamfer Distance (CD): A distance between two point sets measuring average nearest-neighbor error, used for geometry evaluation. "CD"
- Cross-Entropy Method (CEM): A population-based stochastic optimization algorithm that iteratively refines a sampling distribution toward elite solutions. "Cross-Entropy Method"
- [email protected] (F-Score): The F-measure computed at a 0.05 threshold to assess geometric reconstruction accuracy. "[email protected] (F-Score)"
- Geodesic distance: The shortest-path distance on the rotation manifold (SO(3)), used to compare orientations. "denotes the geodesic distance between rotations, implemented via quaternion distance."
- Gilbert–Johnson–Keerthi distance algorithm (GJK): An algorithm to compute distances and detect intersections between convex shapes. "GilbertâJohnsonâKeerthi distance algorithm"
- Ground-Truth (GT): Reference data treated as the correct target for evaluation. "GT 3D scene meshes"
- Ground-wall: A composite support category indicating an object is simultaneously supported by the ground and a wall. "composite parent ground-wall"
- ICP alignment: Iterative Closest Point; a method to rigidly align two shapes or point clouds. "we apply ICP alignment"
- Image-to-3D model: A model that reconstructs 3D geometry from a single image. "image-to-3D model"
- Isaac Gym: A GPU-accelerated physics simulator used for robotics and dynamic scene evaluation. "Isaac Gym"
- LLM: A high-capacity neural LLM capable of general reasoning and instruction following. "LLMs"
- Open-vocabulary: Not restricted to a fixed set of labels; capable of recognizing arbitrary categories. "Open-vocabulary Object List Analysis."
- Physics-constrained optimization: Optimization that enforces physical plausibility via constraints or simulation-based objectives. "physics-constrained optimization"
- Quaternion distance: A metric for comparing rotations using their quaternion representations. "quaternion distance"
- Scene canonicalization: Aligning a reconstructed scene to a standard coordinate frame and gravity direction. "Scene Canonicalization."
- Scene-Tree: A hierarchical representation encoding objects and their physical support relations. "Scene-Tree Construction"
- Simulation-based optimization: Optimizing parameters by evaluating candidate solutions through forward physics simulation. "simulation-based optimization under physical constraints"
- State-of-the-art (SOTA): The best-performing methods at the time of writing. "SOTA"
- Support-relation scene tree: A tree where edges indicate which objects physically support others under gravity. "support-relation scene tree"
- Vision-LLM (VLM): A multimodal model that jointly processes images and text for reasoning or prediction. "a VLM (i.e, Gemini)"
- VR-based human–object interaction: Interaction in virtual reality where users manipulate simulated objects. "VR-based humanâobject interaction"
- World frame: The global coordinate system in which object poses and scene layouts are defined. "world-frame layout"
Collections
Sign up for free to add this paper to one or more collections.

