- The paper introduces a novel framework that integrates generative 3D priors with scene-centric multi-view reconstruction to achieve physically realistic multi-object simulation.
- It employs a four-stage pipeline—combining PGSR, SAM3D extraction, spatial/appearance alignment, and a modified MPM—to resolve incomplete object geometries and ensure stable dynamics.
- Quantitative and qualitative evaluations show improved spatial fidelity, appearance consistency, and real-time performance on consumer-grade hardware.
SAM3D-Phys: Multi-Object Interactive Simulation in Reconstructed Real-World Scenes
Overview and Motivation
SAM3D-Phys introduces a computational framework for reconstructing real-world scenes to enable physically plausible multi-object interaction, targeting applications spanning VR, robotics, video generation, and embodied scene understanding (2605.30239). The paper observes a fundamental challenge: object geometries reconstructed via multi-view image methods (e.g., neural rendering, Gaussian splatting) are frequently incomplete due to occlusions or sparse viewpoints. Such artifacts undermine downstream physics simulation, especially in cluttered, multi-object environments where spatial and geometric consistency is vital for stable dynamics. Existing works either focus on single-object cases or restrict simulation to simplified planar scenes, exhibiting limitations in both completeness and physical realism.
Framework Architecture
SAM3D-Phys leverages generative 3D priors (SAM3D) integrated with scene-centric multi-view reconstructions to recover simulatable objects with full geometry and scene consistency. The pipeline executes four stages:
- Scene Reconstruction with PGSR: Multi-view images are processed with Planar-based Gaussian Splatting (PGSR), enhanced by segmentation affinity features, followed by object removal and inpainting using LaMa for background completion.
- Object Extraction via SAM3D: Target objects are segmented and converted from partial observations to complete 3D geometry utilizing generative priors acquired from SAM3D, resolving occlusion-induced incompleteness.
- Object-Scene Alignment: Appearance and metric cues from the reconstructed scene guide spatial optimization and mask-based appearance distillation, restoring objects’ pose and appearance within the original environment.
- Interactive Physical Simulation (MPM): Aligned objects are reinserted and simulated using a modified Material Point Method (MPM), supporting simultaneous, physically consistent dynamics for multiple objects.
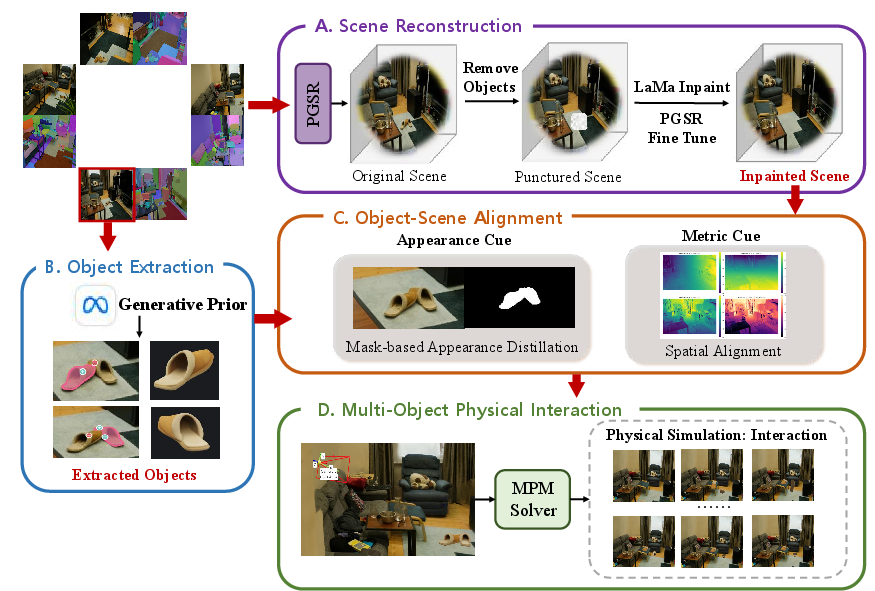
Figure 1: SAM3D-Phys pipeline, from PGSR-based reconstruction to SAM3D object extraction, spatial/appearance alignment, and multi-object MPM simulation.
Object-Scene Spatial and Appearance Consistency
Spatial Alignment
The framework deploys a render-and-compare refinement optimized by SSIM/MS-SSIM objectives, driving per-object pose (translation, rotation) to minimize discrepancies between rendered masks and ground-truth image regions. Depth maps are converted into pointmaps via pinhole back-projection, providing accurate 3D initialization for generative modules.
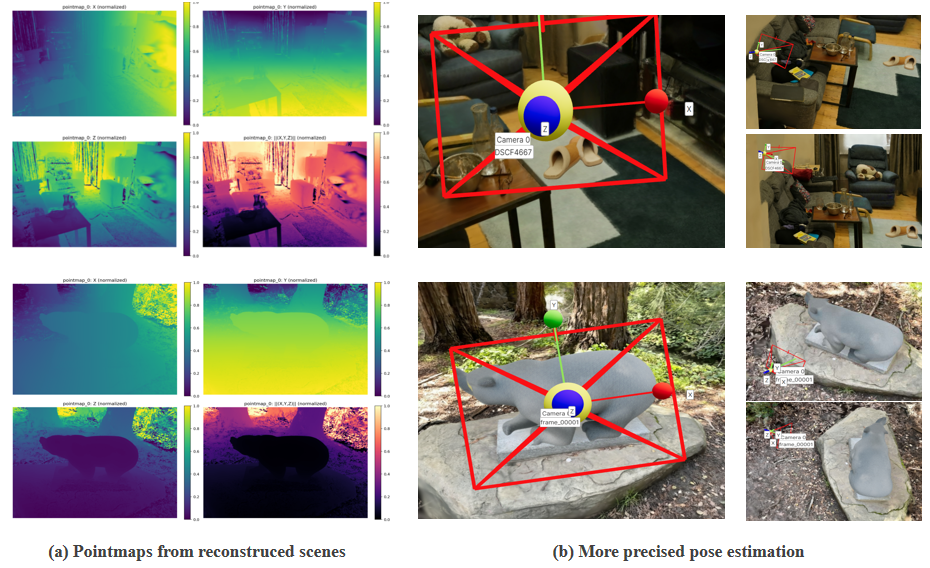
Figure 2: Use of pointmaps enables improved object initialization, enhancing spatial alignment and simulation stability.
Spatial refinement is performed iteratively, with intermediate optimization steps yielding progressive alignment of objects to observed mask regions and correct spatial placement within the scene.

Figure 3: Pose refinement example—rendered object incrementally aligns to image mask during spatial optimization.
Physics-Constrained Alignment
SAM3D-Phys introduces a control graph derived via a multimodal model (Gemini) to encode object-object and scene-object interactions and constraints. Two terms are enforced: one for stable object-ground contact, and one for object-object non-penetration, addressing interpenetration errors and ensuring physically reasonable final placements.
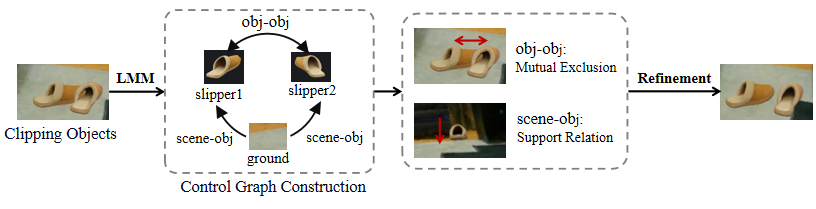
Figure 4: Control graph guides spatial refinement and physically consistent object placement, mitigating interpenetration.
Appearance Distillation
Mask-guided appearance distillation aligns textures via patch-level VGG feature loss within overlapping mask regions. This module eliminates cartoon-like artifacts and bridges appearance gaps between decoupled/generated objects and original observations.

Figure 5: Appearance alignment improves texture fidelity and overall visual consistency with scene context.
Interactive Simulation and Scene Editing
Reintegrated and aligned objects are modeled and simulated using MPM, which efficiently aggregates per-object attributes (position, velocity, deformation) and enforces mass and momentum conservation across the Eulerian grid. Flexible interaction is facilitated via user-defined impulse forces and force fields, enabling scene-centric manipulation.

Figure 6: Visualization of multi-object physical simulation and object removal-editing in the reconstructed environment.
The pipeline achieves real-time efficiency on consumer-grade hardware (RTX 4090).
Experimental Evaluation
Dataset and Metrics
A real-world multi-object benchmark (six scenes, including complex mutual occlusions) was constructed to evaluate the method. Metrics are edge error (Sobel, spatial accuracy) and PSNR/SSIM (appearance fidelity within masks), and baselines include Feature Splatting and DecoupledGaussian.

Figure 7: Dataset scenes—multi-object scenarios with varying occlusion and coupling for robust evaluation.
Comparative Results
SAM3D-Phys demonstrates superior spatial decoupling, geometric completeness, and appearance fidelity relative to baselines, which suffer from fragmentation, tearing, and poor object separation—particularly under multi-object and occlusion-heavy conditions.

Figure 8: Comparative visualization—SAM3D-Phys avoids fragmentation and achieves accurate object separation/alignment.
Zoomed-in comparisons further highlight physically reasonable motion and high spatial/appearance fidelity.

Figure 9: Detail comparisons show baseline failure in multi-object scenarios; generative priors and metric cues resolve object separation gaps and guarantee visual/physical fidelity.
Quantitative ablation shows spatial alignment and appearance distillation modules yield measurable improvements: edge error drops by 1.0%, PSNR increases from 23.9 to 30.0, SSIM rises from 0.869 to 0.954.
User Study and LMM Evaluation
User and LMM-as-Judge evaluations confirm that SAM3D-Phys attains higher scores for both motion realism and visual quality, outperforming baselines by significant margins in both objective and subjective assessment.
Limitations and Future Directions
Appearance inconsistencies due to illumination (specular, shadow artifacts) and insufficient contextual cues remain problematic in scene completion and object inpainting, as shown in failure cases.

Figure 10: Limitations—specular highlights, shadow variations, and low-context degrade appearance reconstruction and alignment.
Further improvements may rely on robust illumination modeling, context-aware generative methods, and synergetic integration with multimodal cues.
Theoretical and Practical Implications
SAM3D-Phys establishes a holistic, training-free pipeline for generating physically simulatable objects from incomplete, occlusion-heavy real-world scene observations. Methodologically, it bridges generative 3D priors and scene-aware reconstruction, enforcing spatial/appearance consistency and physical plausibility. Practically, it advances capabilities in VR, robotics, and embodied AI by supporting dynamic scene editing and interactive simulation in realistic environments, suggesting directions for scalable, context-aware world models and simulation-ready, object-centric scene pipelines.
Conclusion
SAM3D-Phys provides an efficient, modular framework for physical simulation in real-world multi-object scenes, coupling generative 3D priors and spatial/appearance alignment with scene-centric reconstruction and MPM-based simulation. The method yields measurable gains in geometric completeness, spatial fidelity, and stable dynamics, validated across qualitative and quantitative benchmarks. The approach is practically deployable and extensible; addressing illumination/context limitations and scaling to broader multimodal scene modeling remain key avenues for future research.

