Language Models Need Sleep
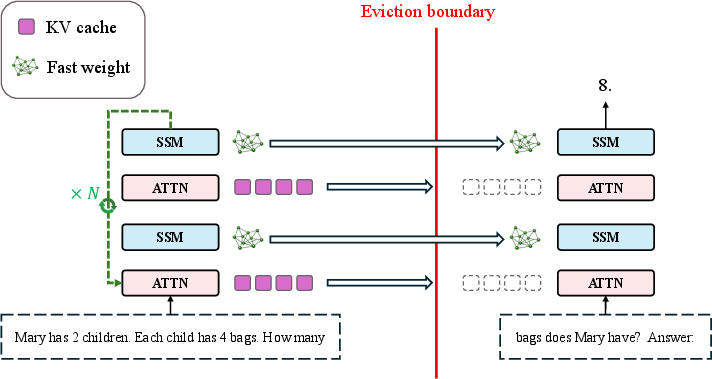
Abstract: Transformer-based LLMs are increasingly used for long-horizon tasks; however, their attention mechanism scales poorly with context length. To handle this, we study a sleep-like consolidation mechanism in which a model periodically converts recent context into persistent fast weights before clearing its key-value cache. During sleep, the model performs $N$ offline recurrent passes over the accumulated context and updates the fast weights in its state-space model (SSM) blocks through a learned local rule. During inference, this shifts extra computation to sleep while preserving the latency of wake-time prediction. We test our method on controlled synthetic tasks, including cellular automata and multi-hop graph retrieval, as well as a realistic math reasoning task, on which a regular transformer as well as SSM-attention hybrid models fail. We then show that increasing sleep duration $N$ for our models improves performance, with the largest gains on examples that require deeper reasoning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple, brain-inspired question: do LLMs need “sleep”? Just like people replay and organize memories during sleep, the authors design a way for AI LLMs to pause, replay what they just read, and store it in a compact, long-term memory before moving on. This “sleep” helps the model remember and reason about earlier parts of very long inputs without slowing down when it’s time to answer.
What questions did the researchers ask?
The authors focus on three kid-friendly questions:
- Can a model turn what it just read into a smaller, long-term memory it can use later?
- Does giving the model extra “sleep time” (more replay steps) help it solve harder, multi-step reasoning problems?
- Can this work without making the model slower when it finally gives an answer?
How does the method work? (In everyday terms)
Think of two kinds of memory inside a LLM:
- Attention cache (like a chat history): it remembers lots of recent words precisely, but it grows with the length of the text and becomes expensive.
- Fast weights (like a small notebook): a fixed-size memory that stores a compressed summary. It doesn’t grow, but you must pick what to write carefully.
The problem: As inputs get very long, keeping the whole chat history (attention cache) is too costly. Hybrid models mix both: they use attention for recent details and fast weights for older, summarized information. But simply having memory isn’t enough—turning raw text into useful memory often needs extra computation.
The idea in this paper: add a “sleep” phase for consolidation.
- As the model reads, once a fixed-size window is full, it pauses external input.
- During “sleep,” it replays the recent chunk N times (N is the “sleep duration”), each time refining what to write into its small notebook (fast weights).
- Then it clears the bulky chat history and continues reading.
- When it’s time to answer, the model makes a normal, single forward pass—no extra loops—so answering remains fast.
In more technical words:
- The model is a hybrid of attention layers and “SSM” layers (state-space/linear recurrent layers) that maintain fast weights.
- At eviction points (when the attention window fills), the model runs N offline recurrent passes over the chunk to update fast weights using a learned local rule, then discards the attention cache.
- Training backpropagates through these sleep passes so the model learns how to compress and organize information for later use.
Two eviction styles were explored:
- Hard eviction: clear the whole attention cache at once.
- Sliding-window eviction: keep only the most recent part of the cache (like a moving window) and evict older parts.
What did they test on?
To make sure the idea helps with reasoning (not just memorization), they used three tasks where the model must reason about information that’s no longer directly accessible through attention:
1) Cellular automaton (Rule 110)
- A simple rule repeatedly changes a line of 0s and 1s over many steps.
- The model sees initial lines but must predict bits many steps later.
- Longer rollouts require deeper, step-by-step computation.
2) Depo (multi-hop graph retrieval)
- A list of directed edges (like “b→a, f→l, …”) is shown in random order.
- Queries ask, “After k steps from node X, where do you arrive?” (larger k = deeper reasoning).
- The edges are spread across multiple windows, so the model must consolidate them into fast weights to answer later.
3) GSM-Infinite (long, math word problems)
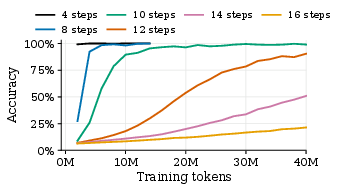
- Long math problems with many distracting tokens; difficulty is controlled by how many arithmetic steps are needed (from 1 to 8).
- The question is shown first so the model can focus its memory on what’s relevant.
- The total text is longer than the attention window, so the model must rely on consolidated memory to solve problems in a single forward pass (no chain-of-thought allowed).
They tried this with both smaller models trained from scratch and realistic pre-trained models:
- Hybrid “Jet-Nemotron” (attention + dynamic convolution fast weights).
- “Ouro” (a looped attention model) augmented with fast-weight layers.
What were the main findings, and why do they matter?
Here’s what they found, in plain language:
- Simply having a small notebook (fast weights) isn’t enough when reasoning gets deep. Hybrid models without sleep struggle as tasks require more steps of reasoning, even if they technically have enough memory to store the facts.
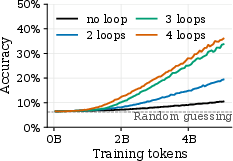
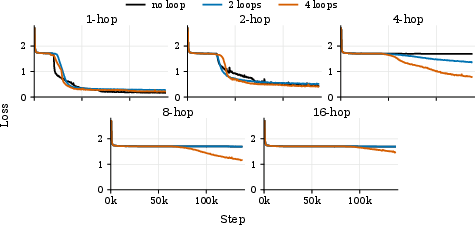
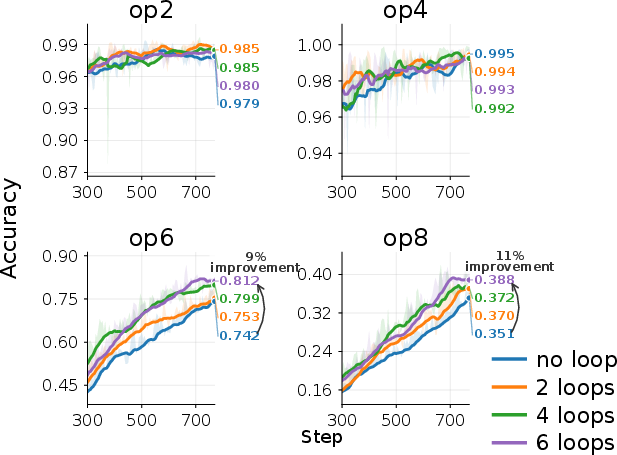
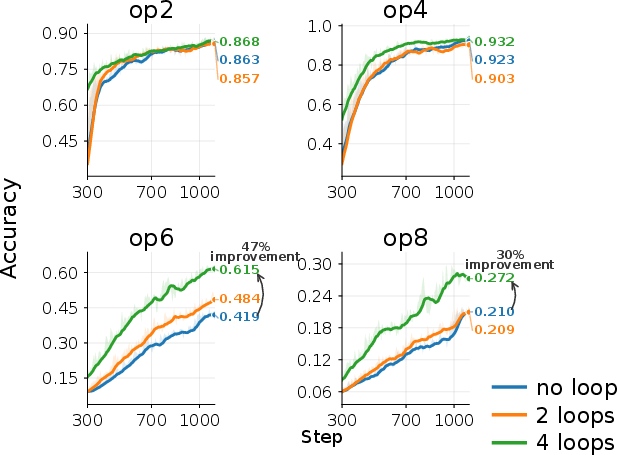
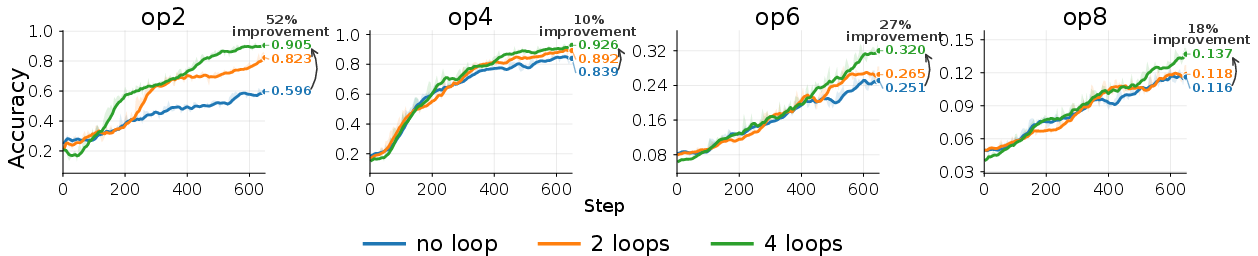
- Adding sleep helps a lot. Increasing sleep duration (more replay passes over the recent chunk) improves accuracy, especially on the hardest cases that need deeper reasoning.
- In the cellular automaton task with long rollouts, models with more sleep passes clearly outperformed those with no sleep.
- In Depo, more sleep helped answer higher-hop queries (like 8 or 16 steps) that stalled without sleep.
- In GSM-Infinite, both pre-trained models improved as sleep duration increased—most noticeably on problems needing 6–8 operations.
- Sliding-window setups benefit too. Even when the model keeps a small recent attention window, adding sleep passes before older text slides out still boosted results—both for retrieving relevant details and for multi-step reasoning.
- Answering stays fast. All extra computation happens during sleep. When it’s time to predict, it’s still a single forward pass.
Why it matters:
- Long documents and complex problems require not just remembering, but also organizing and computing over what you read.
- The “sleep” mechanism shifts extra compute to moments when the model can pause and prepare, so it doesn’t slow down the final response.
Trade-offs:
- Training is slower and more complex because you backpropagate through multiple passes. Cost grows roughly with the number of sleep passes.
- But for tasks that truly require multi-step reasoning over long contexts, the performance gains can be substantial.
What’s the bigger picture?
This work suggests a practical way to make LLMs better at long-horizon reasoning without making them slow at answer time:
- It shows that “memory consolidation” (like human sleep) can help models turn lots of text into a compact, reusable state.
- This could help assistants that read long reports, analyze logs, or work through multi-step plans—any setting where the model must think over information it can no longer directly “see.”
- Future work can explore how to make training more stable and efficient, and how to decide dynamically how much “sleep” a model needs for a given task.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise list of concrete gaps and open questions the paper leaves unresolved, intended to guide follow-up research.
- Scope and realism of evaluation
- Lack of large-scale, real-world benchmarks beyond GSM-Infinite (e.g., GSM8K, MATH, HotpotQA, multi-document QA, code reasoning) to establish external validity.
- No perplexity or general long-form generation metrics reported on open-domain corpora to assess side-effects on language modeling quality.
- Limited languages/modalities; unclear if sleep helps multilingual, multimodal, or code tasks.
- Comparative baselines and controls
- Missing head-to-head comparisons with strong context-distillation, test-time training (TTT), and retrieval-augmented (RAG) baselines under matched latency/compute budgets.
- No comparison to wake-time depth recurrence (e.g., ACT, Universal Transformers) under a relaxed latency constraint to quantify the unique value of shifting compute to sleep.
- No ablation on looping which layers (SSM only vs attention+SSM) and where to loop (early/middle/late) to pinpoint the critical loci for consolidation.
- Sleep scheduling and adaptivity
- Sleep is periodic and tied to window eviction; no mechanism to adaptively trigger sleep based on content difficulty, uncertainty, or confidence.
- Fixed recurrence depth N per window; no learned halting/compute allocation policy that varies N by instance hardness or stage of the sequence.
- No exploration of learned eviction boundaries or selective consolidation (which tokens/segments to consolidate vs ignore).
- Inference-time behavior and latency
- While wake-time prediction latency is preserved per token, end-to-end inference latency is not measured for interactive settings where sleep causes pauses when the window fills.
- No profiling of inference-time throughput/energy vs N and window size; training throughput is analyzed, but not inference-side cost/latency trade-offs.
- Stability and scaling
- Training stability at large N, long sequences, and larger models is discussed but not systematically studied (e.g., gradient explosion/vanishing, optimizer sensitivity, checkpointing strategies).
- No scaling laws quantifying accuracy gains vs N, model size, SSM capacity, or training tokens; unclear diminishing returns and optimal N under a compute budget.
- Limited exploration of parallelization strategies (e.g., pipelining across windows/GPUs) to mitigate sequential dependencies introduced by sleep.
- Mechanistic understanding of consolidation
- The “learned local rule” for fast-weight updates is not analyzed; missing interpretability of what is stored, how representations evolve across passes, and why loops help.
- No diagnostics of interference/forgetting in fast weights across multiple windows (catastrophic interference, overwriting, retention vs plasticity trade-offs).
- Unclear capacity–compute trade-off: how increasing SSM size vs increasing N differentially affects recall and reasoning.
- Robustness and safety
- No robustness analysis under noisy, adversarial, or misleading distractors; unclear if sleep amplifies vulnerability to prompt poisoning or spurious consolidation.
- No guarantees or controls for privacy/safety when consolidating sensitive content into persistent fast weights within a session.
- Generality across architectures and training regimens
- Evaluated primarily with GDN/Jet-style SSMs; unclear if benefits transfer to other SSM variants or pure attention models with added fast-weight modules.
- For Ouro (attention-only pretrain), insertion of SSM layers was minimal; no systematic study of retrofitting ratios, placements, or pretrain vs finetune strategies.
- No exploration of truncated BPTT, implicit gradients, or meta-learning formulations to reduce memory/compute while preserving gains.
- Task design and supervision
- Consolidation is trained indirectly via masked cross-entropy on final answers; no auxiliary objectives (e.g., reconstruction, contrastive, graph-structure prediction) to directly shape the consolidated memory.
- No analysis of error types (retrieval vs computation errors) on synthetic tasks to disentangle where consolidation fails.
- Sliding-window vs hard eviction
- Sliding-window results show improvements with N, but there is no study of optimal overlap, carryover length, or policies for jointly using residual KV cache and fast weights.
- Under SWA, newly added SSM layers can be underutilized; no principled method to ensure balanced use of attention vs SSM during consolidation.
- Session-level persistence and continuity
- Fast weights are zero-initialized per sequence; no study of cross-session or long-session persistence (e.g., continual conversation memory) and mechanisms for selective retention/forgetting across tasks.
- Open question: how to checkpoint, reset, or sandbox fast-weight states to prevent cross-task contamination.
- Integration with reasoning tools and prompting
- Interplay with chain-of-thought, tool use, and external memory/RAG is unexplored; could sleep improve tool selection or planning when tools are available?
- Unknown whether sleep complements or replaces CoT in settings where latency constraints are flexible.
- Applicability to online/streaming use-cases
- Sleep halts intake during consolidation; strategies for real-time streaming, chunk prioritization, or background consolidation are not proposed or evaluated.
- Theoretical grounding
- No formal analysis linking sleep-time recurrence to iterative optimization (e.g., correspondence to gradient descent, Oja’s rule, or EM-like updates) or to bounds on recall/reasoning depth.
- Lack of theory relating N, SSM rank/capacity, and task complexity (e.g., hop count, automaton steps) to achievable accuracy.
Practical Applications
Practical Applications of “LLMs Need Sleep”
The paper introduces a “sleep-like” consolidation mechanism for hybrid SSM–attention LLMs: when the active context window fills, the model performs N offline recurrent passes (“sleep”) over the latest chunk to refine fast-weight memory, then clears the KV cache and continues. This shifts extra compute to consolidation time while preserving single-pass prediction latency. Empirically, longer sleep improves performance on tasks requiring deeper sequential reasoning over evicted context in both controlled settings (cellular automata, multi-hop graph retrieval) and a realistic math-reasoning benchmark, including sliding-window scenarios.
Below are actionable applications derived from these findings, organized by deployment horizon.
Immediate Applications
The following can be prototyped or deployed with current hybrid SSM–attention LLMs and modest engineering effort, leveraging end-to-end fine-tuning with sleep loops and/or inference-time consolidation.
- Low-latency long-context assistants for regulated workflows
- Sector: healthcare, legal, finance, enterprise IT
- Use case: Process long documents (EHRs, contracts, filings) chunk-by-chunk; during natural pauses or segment boundaries, trigger sleep loops to consolidate salient structure into fast weights, then answer clinician/attorney/analyst queries in single-pass, low-latency mode even after the original context has been evicted.
- Tools/workflows: “Sleep-aware inference scheduler” in the serving stack; KV-to-fast-weight consolidation module; policy guardrails for when to sleep.
- Assumptions/dependencies: Hybrid SSM–attention model with sleep fine-tuning; chunking and eviction policy; privacy controls for ephemeral session state.
- Meeting and call analytics with latency SLAs
- Sector: enterprise software, customer support, sales
- Use case: Stream transcripts; sleep during brief silences to consolidate prior segments; provide instant answers/summaries without re-attending the entire transcript.
- Tools/workflows: Streaming ASR → chunker → sleep consolidator → low-latency Q&A; dashboard to track “sleep budget.”
- Assumptions: Short sleeps fit into conversational gaps; small window (e.g., L=512–2k) plus sleep suffices for multi-turn recall and reasoning.
- Repository-scale code assistants with bounded memory
- Sector: software engineering
- Use case: Ingest large repos via staged reads; sleep after each file/package to encode call graphs/interfaces into fast weights; answer developer queries (e.g., “where to add logging?”) with single-pass latency without a massive KV cache.
- Tools/workflows: CI-time pre-scan job with sleep; “repo memory” fast-weight snapshot attached to issue/PR; devtool plugins.
- Assumptions: Session-scoped or task-scoped fast weights; careful chunking (by module/package); evaluation on multi-hop code navigation tasks.
- Customer support copilots with long session memory
- Sector: customer experience, contact centers
- Use case: During long chats, periodically sleep to consolidate user history/preferences/pain points; deliver immediate, on-policy replies without reprocessing whole chat.
- Tools/workflows: Sleep triggers on token count or idle; fast-weight cache per session; guardrails to avoid storing sensitive PII beyond session.
- Assumptions: Ephemeral, session-bound fast weights; compliance with data retention rules.
- On-device assistants with small RAM budgets
- Sector: mobile/edge, embedded systems
- Use case: Replace large KV caches with sliding-window + sleep to compress earlier context into fast weights; preserve snappy responses with much smaller memory footprint.
- Tools/workflows: Edge runtimes implementing sleep passes; loop-depth controller to trade energy vs. quality.
- Assumptions: Efficient SSM kernels and quantization; power-aware scheduling for sleep.
- Financial analysis during earnings season
- Sector: finance
- Use case: Ingest extended filings, call transcripts, and news; sleep offline between documents or after market close; provide intraday, single-pass answers referencing prior materials.
- Tools/workflows: Batch ingestion pipeline with consolidation; “reasoning-ready” state shared to analysts’ terminals.
- Assumptions: Clear task boundaries for safe consolidation; auditable traces mapping answers to sources.
- Long-horizon tutoring with low-latency answers
- Sector: education
- Use case: Read multi-part problem sets with distractors; sleep after each section to encode intermediate results; deliver rapid, single-pass feedback and hints without CoT.
- Tools/workflows: Curriculum-aware chunking; per-lesson fast-weight state.
- Assumptions: Model fine-tuned on math/textbook-like GSM-Infinite style data; explainability overlays to communicate reasoning confidence.
- Cost and memory optimization in inference serving
- Sector: cloud platforms, MLOps
- Use case: Reduce KV cache memory and cross-request context growth; replace with periodic sleep consolidation; increase concurrency on the same hardware.
- Tools/workflows: Serving middleware with “sleep hooks”; autoscaler that adjusts sleep N based on load; telemetry on quality vs. cost.
- Assumptions: Service-level objectives tolerate brief consolidation periods; robust fallback to standard attention for edge cases.
- RAG-lite pipelines with reduced retrieval frequency
- Sector: knowledge management, enterprise search
- Use case: When ingesting a large retrieved set, sleep to encode the local graph/relations into fast weights; subsequently answer related questions without repeatedly querying the vector store.
- Tools/workflows: Retriever → chunker → sleep consolidator → Q&A; consolidation budget per query.
- Assumptions: Retrieval still needed for fresh/out-of-domain content; decay or re-initialization strategy between topics.
- Evaluation and research tooling
- Sector: academia, applied research
- Use case: Benchmarks isolating reasoning depth vs. memory (e.g., Depo, cellular automata, GSM-Infinite-style tasks) to tune sleep duration and eviction policies; ablation harnesses for N loops.
- Tools/workflows: Open-source “SleepKit” with trainers, schedulers, metrics for fast-weight quality.
- Assumptions: Access to hybrid backbones (Jet/Mamba2/GDN) and reproducible long-context datasets.
- Safety/compliance: ephemeral memory lanes
- Sector: policy, governance, security
- Use case: Enforce that fast-weight consolidation remains session-ephemeral for privacy; certify that consolidated state is discarded at session end.
- Tools/workflows: Memory lifecycle policies; attestations/logs on consolidation and erasure.
- Assumptions: Clear separation between base weights and fast weights; auditable serving runtime.
- Adaptive compute scheduling for SLAs
- Sector: platform engineering
- Use case: Dynamically select sleep duration N based on predicted task difficulty (e.g., hop count proxies, entropy of intermediate states) to keep tail latency in check.
- Tools/workflows: Difficulty estimators; per-request N controller; SLO-aware scheduler.
- Assumptions: Reliable early signals of reasoning depth; guardrails to cap worst-case compute.
Long-Term Applications
These require further research, scaling, or ecosystem development (e.g., training stability at larger N, hardware support, standardized APIs).
- Persistent, hierarchical fast-weight memories across sessions
- Sector: enterprise AI, personal AI
- Use case: Promote selected consolidated state from session-ephemeral to project- or user-level memory, with governance; enable “sleep overnight” to refine long-term task representations.
- Dependencies: Mechanisms for selective persistence, provenance, and forgetting; privacy and consent frameworks.
- Agentic systems with scheduled “rest and plan” cycles
- Sector: robotics, autonomous vehicles, multi-agent systems
- Use case: Robots/agents pause to consolidate interaction logs into fast weights, improving future policies without online latency penalties.
- Dependencies: Safe pause points; sim-to-real validation; alignment of consolidation with control objectives.
- Hardware/software co-design for sleep acceleration
- Sector: AI hardware, systems
- Use case: Specialized kernels and memory hierarchies to accelerate looped consolidation passes; async execution overlapping I/O with sleep; fast-weight introspection at runtime.
- Dependencies: Compiler/runtime support; vendor libraries for SSM updates; memory bandwidth optimization.
- Sleep-aware training curricula and objectives
- Sector: academia, foundation model training
- Use case: Pretraining recipes that scale N with reasoning depth; curriculum that increases hop counts/operation counts; implicit-gradient or truncated-BPTT for stability.
- Dependencies: Robust training strategies for deep recurrence; compute-efficient schedulers; new evaluation protocols.
- Compliance-first consolidation for sensitive domains
- Sector: healthcare, finance, government
- Use case: Policy-driven filters determine what gets consolidated; per-attribute masking; automatic redaction within fast weights.
- Dependencies: Interpretable fast-weight slices; compliance audits; standard APIs for “do-not-consolidate” signals.
- Memory-augmented RAG with structured graph consolidation
- Sector: knowledge graphs, enterprise data
- Use case: Consolidate retrieved document graphs into fast weights as compressed operators enabling multi-hop reasoning without repeated retrieval.
- Dependencies: Interfaces between graph stores and SSM blocks; task-aware consolidation rules.
- Long-horizon scientific assistants
- Sector: research, drug discovery, materials
- Use case: Read weeks of lab logs/papers; sleep to internalize protocols/hypotheses; provide instant analyses and experiment suggestions.
- Dependencies: Domain-tuned consolidation; uncertainty estimation; human-in-the-loop checkpoints.
- Education platforms with accumulated mastery models
- Sector: edtech
- Use case: Persist learners’ evolving concept graphs through controlled consolidation; tutors answer instantly while reflecting long-term mastery and misconceptions.
- Dependencies: Consent and data portability; forgetting strategies; fairness audits.
- Event-driven consolidation in streaming analytics
- Sector: energy, IoT, cybersecurity
- Use case: Sleep on regime change events (e.g., grid anomaly, network surge) to encode new patterns; enable immediate, single-pass detection post-change.
- Dependencies: Change-point detectors; real-time pipelines; bounded-latency guarantees.
- SLA-tiered cloud offerings (“Sleep tiers”)
- Sector: cloud providers
- Use case: Pricing/quality tiers where customers choose consolidation depth (N) vs. cost; scheduled off-peak sleeps for batch consolidation in shared models.
- Dependencies: Billing and metering for sleep compute; fairness in multi-tenant environments.
- Standardized “fast-weight state” interfaces
- Sector: ecosystem, interoperability
- Use case: APIs to export/import consolidated fast weights across services or tools (e.g., attach to tickets, notebooks); reproducibility and sharing of reasoning-ready states.
- Dependencies: Formats, security models, versioning.
- Auditable reasoning without CoT exposure
- Sector: safety, trust
- Use case: Since wake-time remains single-pass, develop probes/diagnostics to audit what was consolidated and why an answer is plausible, without revealing step-by-step chain-of-thought.
- Dependencies: Fast-weight probing methods; causal attribution tools.
Notes on feasibility and assumptions across applications:
- Works best with hybrid SSM–attention models trained (or fine-tuned) to use sleep loops; simply adding loops at inference without training may underperform.
- Gains are largest on tasks with deep sequential reasoning over evicted context; pure retrieval tasks may benefit less unless context length >> window size.
- Training costs scale roughly linearly with loop count N, and sleep introduces sequential processing across context windows; production systems must schedule sleep carefully to meet SLAs.
- Fast weights in the paper are session-scoped unless explicitly persisted; any cross-session persistence introduces privacy, compliance, and contamination risks that require governance.
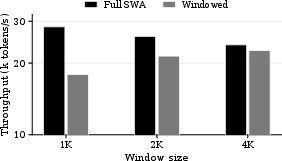
- Sliding-window eviction plus sleep can help when L is small relative to sequence length; warm-up strategies and SSM utilization are important for stability.
- Hardware efficiency (SSM kernels, quantization, activation checkpointing) materially impacts viability on edge and high-throughput servers.
Overall, “sleep” provides a practical knob—sleep duration N—to trade offline consolidation compute for improved long-horizon reasoning while preserving single-pass, low-latency predictions, enabling new workflows where long context and strict latency coexist.
Glossary
- Activation checkpointing: A training memory-saving technique that recomputes intermediate activations during backpropagation to reduce peak memory usage. "additionally uses activation checkpointing across context chunk axis to prevent out-of-memory error."
- Chain-of-Thought (CoT): A prompting or supervision technique that exposes intermediate reasoning steps rather than only final answers. "exclude Chain-of-Thought traces from the data"
- Context distillation: Techniques that transfer information from an explicit input context into model parameters so the model can perform without that context. "Context distillation~\citep{snell2022learningdistillingcontext,askell2021generallanguageassistantlaboratory} aims to distill active context into model weights"
- Delta rule: A local weight-update rule that adjusts parameters in proportion to error signals; used here as an augmentation to fast-weight updates. "add a delta-rule correction"
- Depth-recurrence: Reusing the same layers multiple times within a forward pass to effectively increase network depth and computation. "Depth-recurrence, is one way to increase depth in transformer models and is one method to make them Turing complete"
- Dynamic convolution: A convolution whose kernels are generated conditionally from the input, enabling adaptive sequence mixing. "Jet layers, which use dynamic convolution instead of the fixed convolution in GDN."
- Dynamic-depth models: Architectures that adapt or vary the number of layer applications (depth) per input to allocate compute dynamically. "dynamic-depth models can outperform fixed-depth counterparts on sequential reasoning tasks and solve hard problem instances that fixed-depth models cannot"
- Fast weights: A compact, rapidly updated weight-based memory that stores recent information for later use, distinct from the KV cache. "updates the fast weights in its state-space model (SSM) blocks through a learned local rule."
- FlashAttention 2: An optimized attention algorithm that accelerates and memory-optimizes attention computation. "FlashAttention 2~\citep{dao2024flashattention} is used."
- Gated Delta Networks (GDNs): A class of state-space/linear recurrent models that enhance fast-weight updates with gates and a delta-rule correction. "In our experiments we use Gated Delta Networks (GDNs), which add a delta-rule correction to this update;"
- GSM-Infinite: A procedurally generated long-context math reasoning benchmark that scales both context length and reasoning complexity. "Finally, we consider GSM-Infinite~\citep{zhou2025gsm}"
- Hard eviction: A policy that fully clears the attention KV cache at fixed boundaries, forcing consolidation into fast weights. "we impose a strict context window size as well as a hard-eviction constraint:"
- Hebbian-like outer-product rule: A synaptic update mechanism inspired by Hebbian learning that updates weights via outer products of activity patterns. "a gated Hebbian-like outer-product rule"
- Hippocampal replay: A neuroscience phenomenon where experiences are reactivated during sleep to consolidate memories, used here as inspiration for offline consolidation. "transfer from short-term memory to long-term memory is thought to be supported by hippocampal replay"
- Implicit gradients: Optimization techniques that compute or approximate gradients through implicit differentiation, useful for stable training of recurrent-depth models. "with possible approaches including implicit gradients~\citep{bai2019deep} and truncated backpropagation through time"
- Jet-Nemotron 2B: A specific SSM–attention hybrid LLM that interleaves Jet layers with attention layers. "we fine-tune the pre-trained Jet-Nemotron 2B~\cite{gu2025jet}"
- KV cache (key–value cache): The stored keys and values from prior tokens used by attention to enable efficient autoregressive inference. "the KV cache and are fully evicted before moving onto the next state."
- Linear attention: An attention variant with computation that scales linearly in sequence length by expressing attention as a recurrent/fast-weight update. "linear attention corresponds to a recurrent update over a fixed-size, matrix-valued, state, where key-value mappings are written and queried"
- Linear recurrent layers: Sequence-mixing layers that maintain a fixed-size state updated recurrently, often used as state-space model components. "By contrast, linear recurrent layers, including many SSM-style architectures, store the past in a fixed-size fast-weight state."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank adapters to update weights with minimal additional parameters. "\citet{zhang2026training} attach a LoRA adapter that updates model weights from the current context chunk"
- Mamba2: A family of state-space-style sequence models; here, referring to a Mamba2-style fast-weight update rule. "A simple Mamba2-style~\cite{dao2024transformers} update can be written as a gated Hebbian-like outer-product rule"
- Masked cross-entropy loss: A loss function that computes cross entropy only over positions indicated by a mask, ignoring others. "Masked cross entropy loss"
- Multi-hop knowledge retrieval: Tasks requiring traversal of multiple edges/steps in a graph or knowledge structure to answer queries. "Depo is a multi-hop knowledge retrieval task"
- Muon optimizer: A specific optimizer configuration used in the experiments for training efficiency/stability. "we use the Muon optimizer for all experiments."
- Ouro 1.4B: A depth-recurrent attention-only model used as a base for adding fast-weight memory layers. "Ouro 1.4B~\citep{zhu2025scaling}"
- P-complete: A complexity class capturing problems that are complete for deterministic polynomial time under parallel reductions, indicating inherent sequentiality. "The general problem of predicting Rule 110 after steps is P-complete"
- Sliding-window attention (SWA): An attention scheme that restricts attention to a fixed-size recent window, reducing memory/computation. "as in sliding-window attention (SWA)."
- Sliding-window eviction: A cache policy that retains only the most recent tokens after consolidation, evicting older ones while keeping window size fixed. "We can instead use a sliding-window eviction strategy"
- State-space model (SSM): A class of linear recurrent/neural architectures that maintain and update a compact state representing past inputs. "Linear recurrent neural networks or SSMs can be viewed as maintaining an online fast weight memory"
- Teacher-forced training: A training regime where ground-truth previous tokens are fed during training, enabling full parallelization over sequence positions. "Unlike standard teacher-forced transformer training, which can process all token positions in parallel"
- Truncated backpropagation through time (TBPTT): A training technique that limits the span of backpropagation through recurrent computations to improve efficiency/stability. "truncated backpropagation through time~\citep{geipingscaling,mcleish2025teaching}"
- Turing complete: Capable of simulating any Turing machine given sufficient resources; used to describe the theoretical expressiveness of depth-recurrent transformers. "is one method to make them Turing complete"
Collections
Sign up for free to add this paper to one or more collections.

