- The paper shows that a small set of continuous latent context tokens enables transformers to implement online learning algorithms like MWU and Q-learning efficiently.
- It leverages modular routing and softmax attention to perform state updates and credit assignment in a constant-depth architecture.
- Empirical results indicate that gradient-trained models can recover classical online strategies, outperforming larger LLMs on long-horizon decision tasks.
Continuous Latent Contexts Enable Efficient Online Learning in Transformers
Introduction
The paper "Continuous Latent Contexts Enable Efficient Online Learning in Transformers" (2605.09867) presents a rigorous investigation into the algorithmic capabilities of transformer models equipped with continuous latent state representation, specifically in the context of online decision-making and reinforcement learning. The core thesis is that a small set of continuous latent context tokens suffices for constant-depth transformers to efficiently implement and adapt classical online learning algorithms (Weighted Majority, tabular Q-learning) in an online, autoregressive fashion—contrasting sharply with the limitations imposed by discrete chain-of-thought approaches. The empirical results demonstrate that models incorporating these mechanisms can outperform much larger LLMs on long-horizon synthetic prediction and decision tasks, and can internally encode compact, transferable algorithmic states.
Theoretical Results: Realizing Online Algorithms via Latent Context
A central contribution is the explicit constructive demonstration that constant-depth transformers with a small bank of continuous context tokens (as per the COCONUT paradigm [hao2025training, zhu2025reasoningsuperpositiontheoreticalperspective]) can exactly implement two cornerstone online learning algorithms:
- Weighted Majority Algorithm (WMA): The transformer maintains a continuous latent state encoding expert log-weights in a superposition of expert embeddings. This enables both prediction and credit assignment/update via softmax attention circuits, aligning each attention output with the WMA prediction or update as required. The algorithm’s state update corresponds to a linear operation in latent space, leveraging token orthogonality to isolate expert components. The construction is explicit and uses only O(1) layers/heads, with all algorithmic operations reduced to modular routing and combination in the context buffer.
- Tabular Q-Learning: By representing the Q-table as a set of continuous context tokens, with identity and buffer blocks tracking state, action, and Q-values, the paper shows that value lookup, maximization, temporal-difference update, and action selection can all be realized algebraically in the transformer’s attention/residual stream. Residual updates to the context slot exactly reconstruct the Bellman update at every step, without recourse to long discrete reasoning chains.
These theoretical constructions are soundly justified: the MWU circuit matches expert performance on all sequences, and the tabular Q-learning circuit achieves correct policy and value function iteration for any finite MDP under the usual constraints.
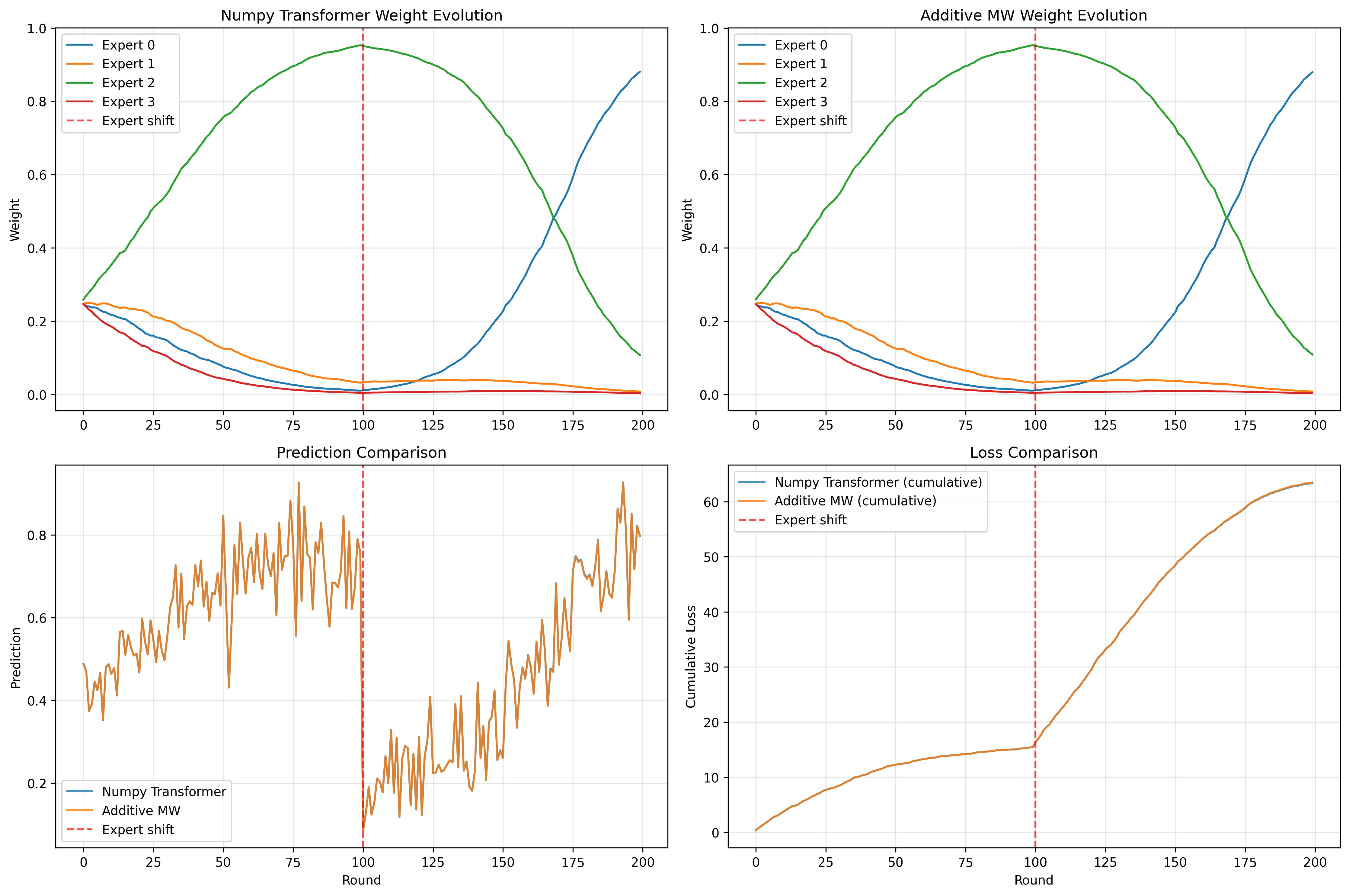
Figure 2: Multiplicative weights (ground-truth) are matched precisely by transformer expert weights over time in the explicit handwired construction.
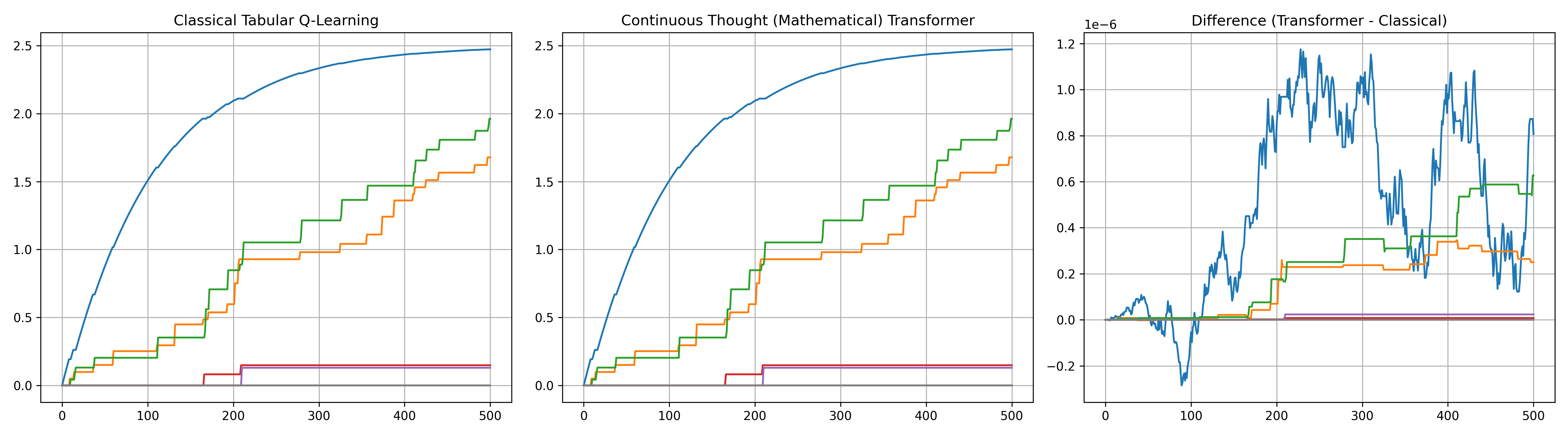
Figure 4: The learned transformer Q-value trajectories via COCONUT align tightly with tabular Q-learning across states and actions.
Learning Latent Contexts from Data
The empirical section probes whether practical, gradient-trained transformers, supplied only with prediction or imitation losses and no direct supervision over the latent context, can learn to implement the algorithmic state dynamics described above.
For expert prediction (unsupervised MWU), small GPT-2 variants with a single latent context token are trained on binary prediction sequences with feedback, and their performance is benchmarked against ideal MWU. Results show strong agreement in regret and state-tracking, with the latent context being heavily attended by subsequent tokens, and per-layer attention interpretable as an online update mechanism.
For tabular Q-learning, curriculum-based training on procedurally generated MDPs allows the transformer to learn a recurrent latent Q-table in context. Across model variants, greedy policies extracted from the context match the performance and value estimates of the tabular ground-truth, and internal probes reveal Bellman signals embedded in context updates.
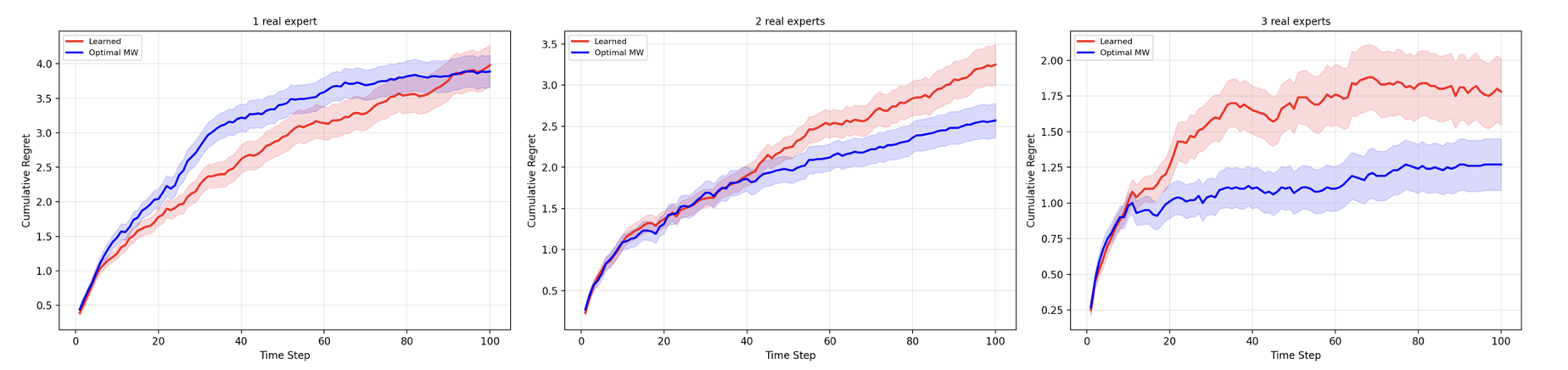
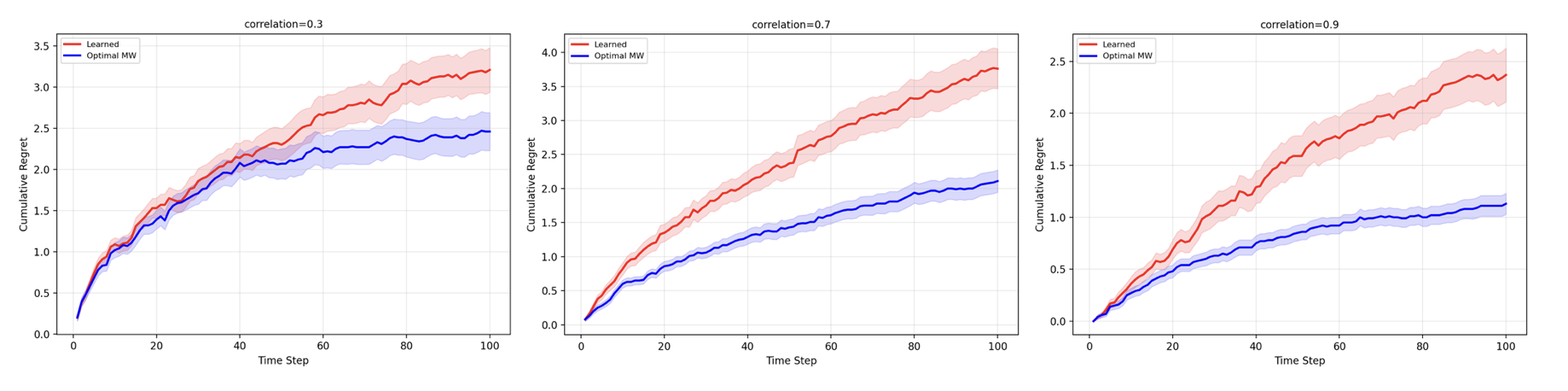
Figure 6: Model evaluations indicate that transformer latent context enables performance comparable to MWU with up to two high-quality experts, but performance saturates or degrades as the latent capacity becomes insufficient for more complex regimes.
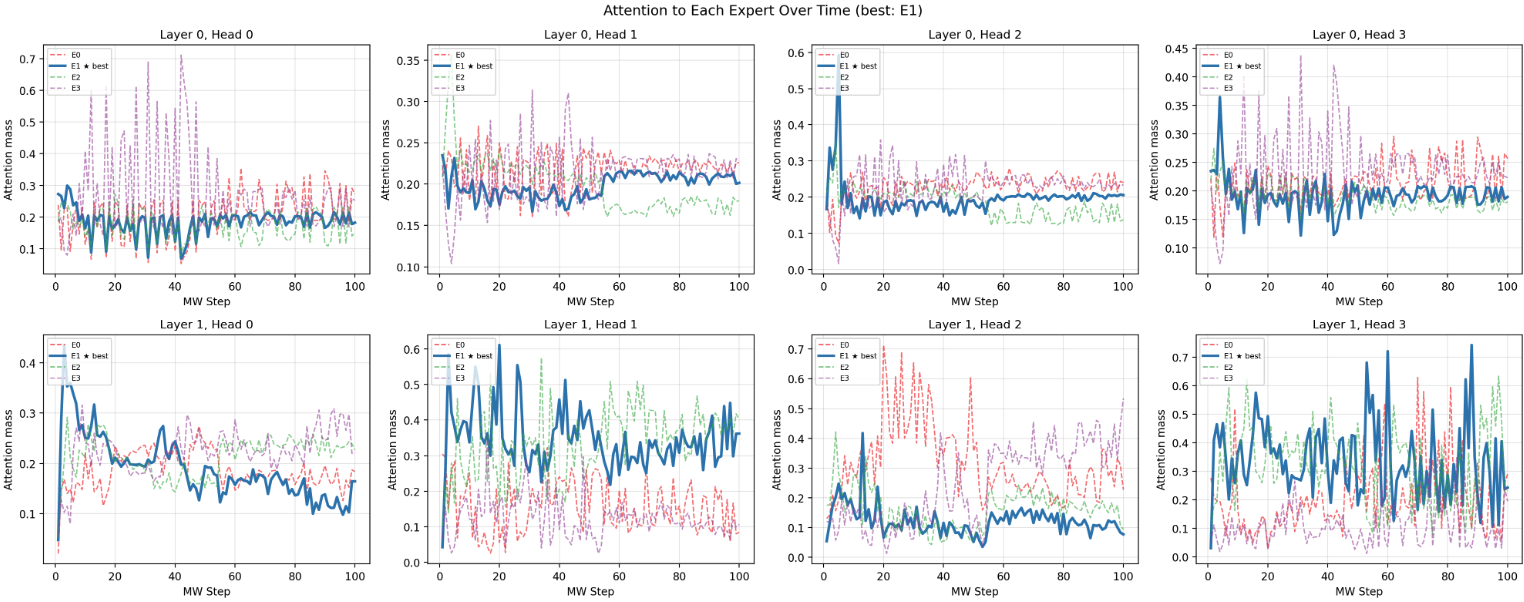
Figure 1: Attention heatmaps across transformer layers verify dynamic focus on relevant expert tokens during prediction and update steps.
LLMs on Online Prediction Tasks: Role of Explicit Memory Channels
The study further benchmarks large-scale LLMs (DeepSeek-V3 and Qwen-3-14B) on interactive online expert prediction. A principal finding is that, absent an explicit persistent context channel, even extremely large LLMs default to short-term exploitation—essentially majority vote or previous-winner heuristics—yielding regret curves comparable to these shallow baselines.
If the prompt is extended to allow the LLM to output and re-ingest a "note" (a visible state summary, not directly supervised), the model rapidly adopts strategies akin to FTL or even MWU, with the note object serving as compressed state and accumulating reliability statistics over rounds. The performance gap between no-note and note-prompted regimes is substantial, especially in environments with one dominant or one adversarial expert.

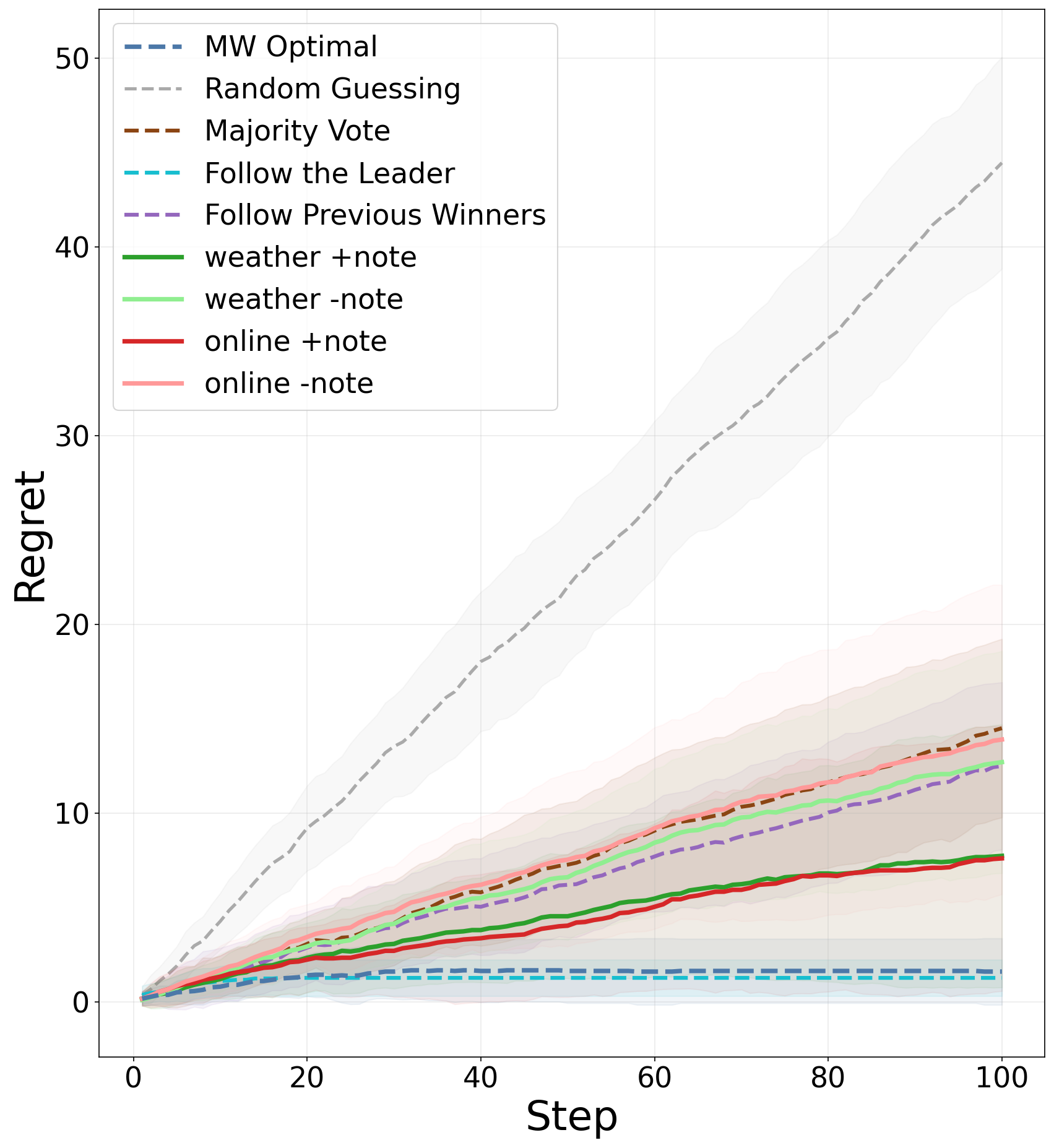
Figure 3: Left—prompting structure illustrating the inclusion of a note for explicit state tracking; Right—cumulative regret curves show that performance with a note matches or exceeds majority and short-term strategies, particularly in stratified regimes.
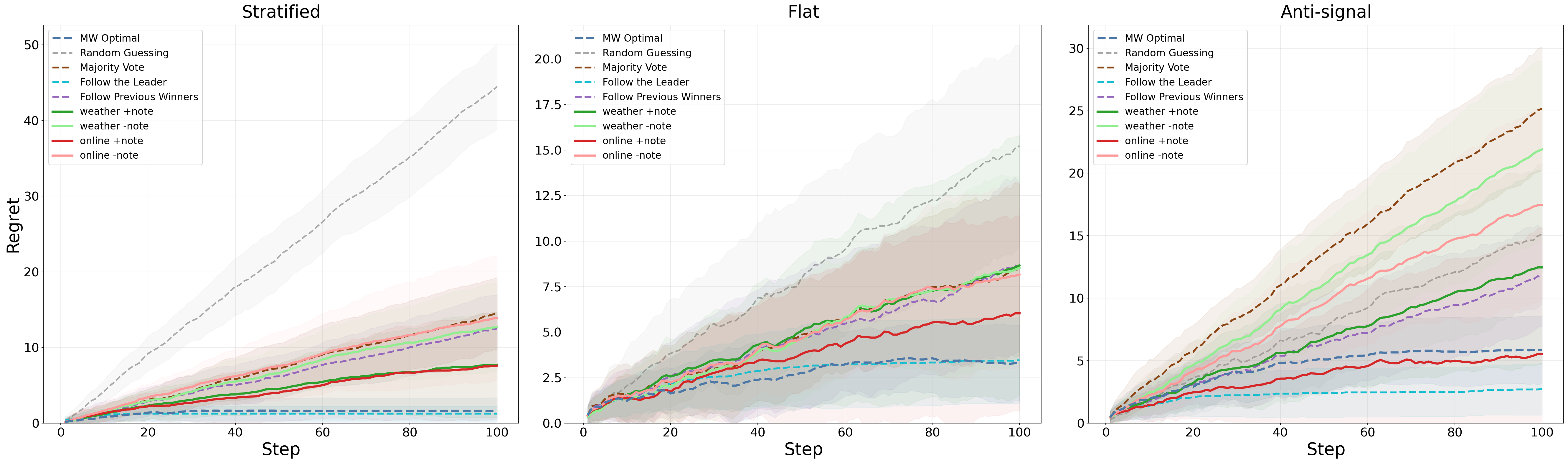
Figure 9: In all expert regimes, cumulative regret is minimized when the model is afforded a compressed, persistent note channel. The effect is largest in adversarial (anti-signal) regimes.
Representation Analysis and Dynamics
Visualization and probing of latent attention reveal that the learned models—even when not trained under directly supervised latent contexts—internally instantiate algorithm-appropriate circuits. Attention across experts is sharply focused at prediction time; context updates align linearly with reward and value function increments; and formed policies are stable under extended rollouts, with negligible degradation beyond training horizons.
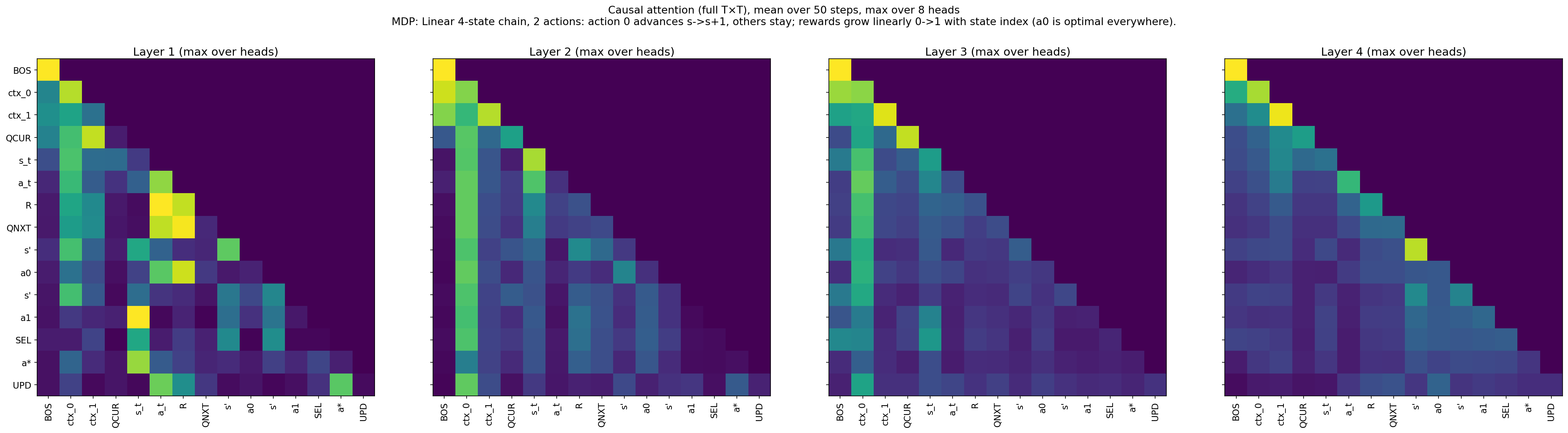
Figure 5: Long-horizon attention heatmaps in MDP sequences show correct localization on optimal actions and execution of maximization and update inductively for many more steps than observed during training.
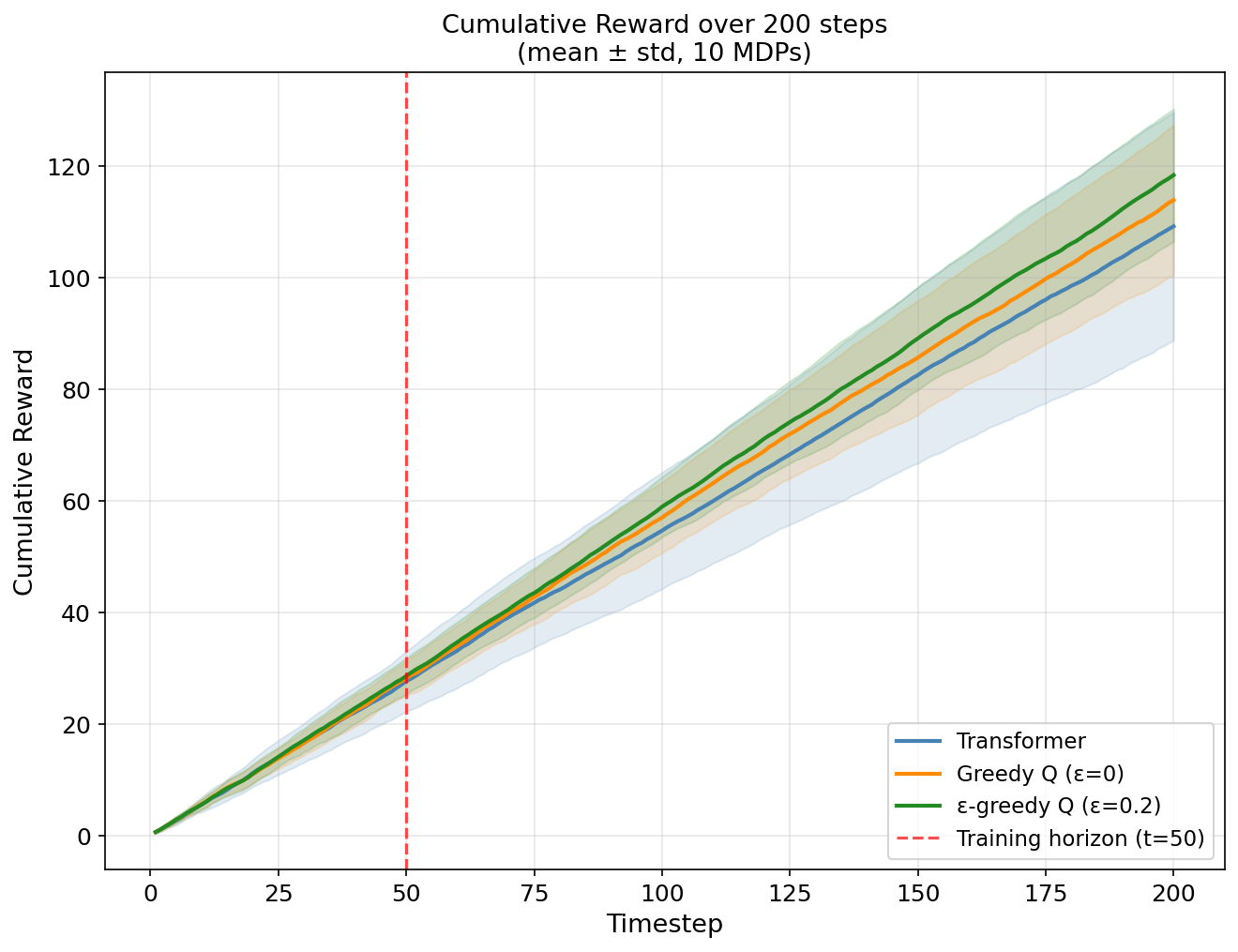
Figure 7: Extended rollouts demonstrate that policy and reward performance remain stable, matching tabular Q-learning even as prediction horizon increases far beyond training window.
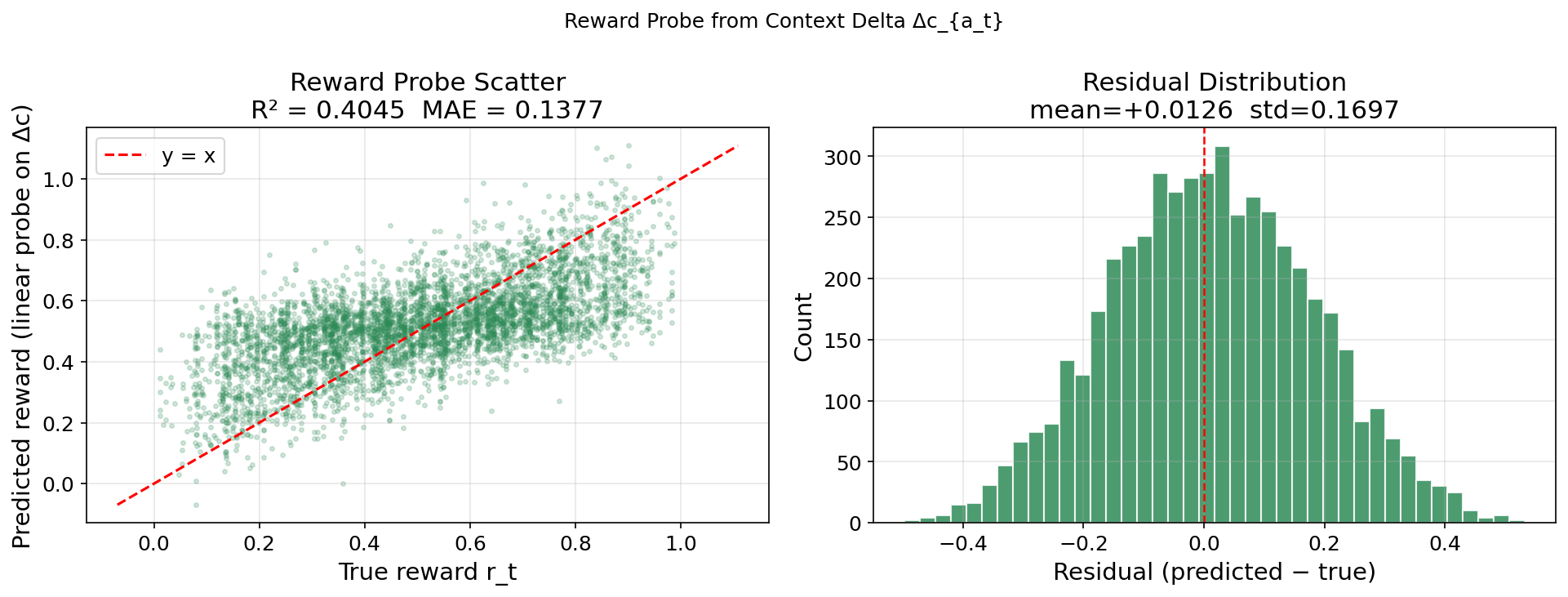
Figure 10: Linear probe analysis establishes that reward signals are decodable from the context change vector, indicating TD-error structure is learned endogenously.
Implications and Future Directions
The theoretical and empirical results have several far-reaching implications:
- Algorithmic Capacity of Transformers: Small, shallow transformer architectures with continuous latent contexts can compactly and efficiently realize classical online learning and RL algorithms. This bridges the gap between symbolic algorithmic reasoning and distributed neural computation.
- Compression and State Abstraction: Latent context tokens function as compact memory/state warehouses that can summarize past information far more efficiently than discrete chain-of-thought or token-level buffering. This perspective aligns with recent findings in amortized state-space modeling [liu2024longhorn, agarwal2024spectralstatespacemodels].
- Practical LLM Performance: For long-horizon tasks, a lack of explicit state maintenance channels in standard LLM inference leads to substantial performance deficits, with models reverting to short-memory heuristics. However, providing even a lightweight, unsupervised memory channel (the "note") enables the LLM to autonomously recover rich, data-efficient online strategies, suggesting simple protocol modifications can unlock latent algorithmic capabilities.
- Alignment and Interpretability: The introduction of non-linguistic, continuous latent reasoning steps—while increasing efficiency and memory capacity—complicates interpretability. The results highlight the need for improved interfaces and diagnostics to ensure reliable, transparent deployment where high-stakes decisions are made.
Further research should explore the capacity and limitations of gradient-based training to induce these latent structures end-to-end, examine their emergence under more complex, distributional, or adversarial regimes, and expand the methodology to domains with richer feedback and partially observable environments.
Conclusion
The paper establishes that transformers with continuous latent context tokens can efficiently and robustly instantiate classical online learning and reinforcement learning procedures as explicit algorithmic circuits, both via direct architectural construction and via practical data-driven imitation. The latent context slots serve as effective, persistent online state, permitting both perfect recovery of reference algorithms in theoretical constructions and strong functional recovery via gradient-based training. LLMs, in turn, benefit substantially from even simple, explicit state interfaces when performing nontrivial sequential prediction, implying practical avenues for protocol design in high-performance, efficient online decision-making.
References
- (2605.09867) Continuous Latent Contexts Enable Efficient Online Learning in Transformers
- [hao2025training] Training LLM to Reason in a Continuous Latent Space
- [zhu2025reasoningsuperpositiontheoreticalperspective] Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
- [liu2024longhorn] Longhorn: State space models are amortized online learners
- [agarwal2024spectralstatespacemodels] Spectral State Space Models

