- The paper demonstrates that single-vector embedding models implicitly encode token-level information through contrastive training, enabling effective fine-grained retrieval.
- It validates SMART’s inference-only adaptation using controlled benchmarks and multi-modal tasks, achieving up to +2.54% improvement in retrieval accuracy.
- The proposed hybrid scoring scheme combines pooled and token-level scores, offering a plug-and-play upgrade with minimal post-training to boost performance.
SMART: Enabling Efficient Multi-Vector Retrieval from Single-Vector Embedding Models
Introduction and Motivation
Single-vector embedding models dominate multimodal retrieval by compressing token sequences into a global pooled representation, optimizing for efficient nearest-neighbor search across text, image, video, and document modalities. However, this paradigm fundamentally limits retrieval capacity, as global pooling erases localized evidence crucial for dense retrieval tasks where queries depend on fine-grained regional or token-level semantics. Empirical and theoretical analyses confirm that single-vector retrievers are strictly bounded by embedding dimensionality, often failing when relevance hinges on local features.
Multi-vector architectures (e.g., ColBERT, Colpali, jina-embeddings-v4) mitigate these limits via late-interaction mechanisms, retaining token-level representations and computing MaxSim-style relevance. The trade-off is considerable: such models require full-scale task-specific retraining, adapter construction, or additional learnable tokens, incurring significant computational and memory costs that scale with sequence length. Critically, many ignore the necessity for a globally summarizing representation for effective retrieval.
SMART (Single-to-Multi Adaptation for Retrieval Transformers) addresses these challenges by exploiting a key observation: standard contrastive training on the pooled token implicitly structures preceding hidden states in a manner compatible with token-level retrieval. Through gradient flow and the network’s architecture, local semantic information is maintained within hidden states though not explicitly optimized for retrieval. SMART unlocks these latent capabilities via direct late-interaction, transforming any single-vector embedder into a highly effective multi-vector retriever at zero training cost, and further enhancing performance with minimal lightweight post-training.
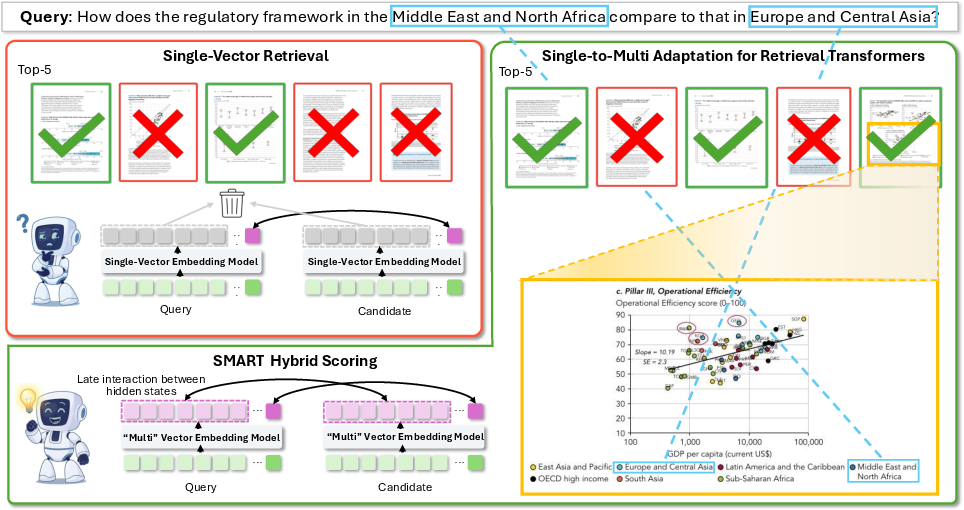
Figure 1: Single-vector models discard local token information via pooling; SMART reveals geometric alignment of hidden states and enables effective multi-vector retrieval with both inference-only adaptation and lightweight post-training.
Framework: Leveraging Implicit Local Evidence
Single-vector embedding models are trained with contrastive InfoNCE loss applied only to the pooled token (e.g., the final-layer <eot> representation). Despite this, all non-pooling hidden states lie on the gradient path due to transformer architecture. The pooled embedding aggregates signal from every non-pooling token. This indirect supervision—rooted in cosine similarity objective—encourages non-pooled hidden states to organize compatibly for local similarity computation, even without explicit token-level retrieval supervision.
SMART operates by extracting these hidden states at inference. For each input, the model produces token-level hidden states, which can be directly matched via MaxSim late-interaction: for every query token, find the most similar candidate token using normalized cosine similarity, and aggregate over all query tokens. This score (slate) is combined with the original pooled score (ssingle) in a hybrid scoring scheme (shybrid), retaining global compatibility while exposing local evidence.
This adaptation is hyperparameter-free and requires no additional training, acting as a plug-and-play upgrade for any single-vector backbone.
Empirical Validation: Controlled Benchmark Analysis
To explicitly test the pooling bottleneck, the authors constructed a controlled visual report benchmark where each query targets a local code–marker binding; hard negatives have identical layout, codes, colors, and shapes but permutations ensure no correct local bindings. Results show pooled single-vector scoring selects positives only 31.9% of the time, while late-interaction over hidden states improves to 56.8%, confirming the presence and utility of local evidence inaccessible via pooling.
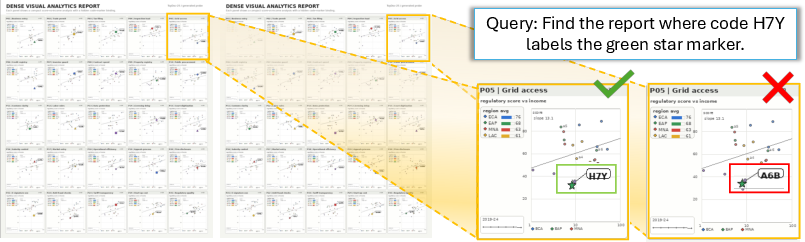
Figure 2: Controlled benchmark isolates local binding retrieval—hard negatives share global content; late-interaction reveals local evidence missed by pooled score.
Broad-Scale Evaluation: MMEB-V2 Retrieval Tasks
SMART was applied inference-only to a range of state-of-the-art models (VLM2Vec-V2.0, GME, Qwen3-VL-Embedding) on MMEB-V2, covering image, visual document, and video retrieval. Across all backbones and domains, SMART consistently yields up to +2.54% improvement in retrieval metrics, scaling robustly even on the SoTA Qwen3-VL-Embedding-8B. These gains are achieved entirely at inference, no additional parameter updates needed.
Lightweight Post-Training and Efficient Conversion
SMART’s efficacy is further amplified by minimal post-training. By freezing the embedder and training only a token-wise adapter, performance is boosted by an additional point or more, efficiently converting a single-vector model to a SoTA multi-vector retriever often within less than 2 hours (for Qwen3-VL-Embedding-2B). When compared to full-scale multi-vector training (e.g., LamRA-Multi), SMART conversion achieves competitive performance, saving ∼20% training time.
Qualitative Visualizations
SMART corrects single-vector failures where global similarity leads to plausible but incorrect matches, recovering localized details through token-level evidence. Visualization of retrieval tasks shows SMART retrieving correct instances missed by pooling, with MaxSim mapping query patches to meaningful candidate regions.

Figure 3: SMART rectifies single-vector retrieval errors by leveraging token-level late-interaction; colored boxes indicate evidence-driven localized matches.

Figure 4: Additional examples—SMART retrieves candidates missed by pooling through token-level matching, critical for fine-grained visual information.

Figure 5: Token-level visualization—SMART maps selected query regions to top candidate-image tokens, highlighting retrieval of localized evidence.
Layer-wise Analysis
Late-interaction performance increases monotonically with layer depth in pooling-based readouts, confirming that deep layers encode progressively discriminative representations. Importantly, the final-layer pooled token remains robust even when paired with earlier hidden states for late interaction, supporting flexibility in hybrid scoring decisions.
Implications and Future Directions
Practical implications of SMART are substantial: inference-only adaptation improves retrieval accuracy and is universally compatible with all tested backbones, providing an avenue to unlock latent performance from off-the-shelf models with zero overhead. Theoretical implications challenge the notion that single-vector models are inherently unable to leverage local evidence, demonstrating that contrastive training does structure hidden states favorably.
Future directions involve expanding SMART to more complex temporal and holistic tasks (e.g., video moment retrieval, grounding), exploring integration with new aggregation modules that can bridge fine-grained alignment and high-level abstraction. The approach also invites investigation into amortized retrieval pipelines and the integration with continual learning for real-time multimodal search applications.
Conclusion
SMART establishes that single-vector embedding models retain latent multi-vector retrieval capabilities, recoverable via direct late-interaction scoring over hidden states. The framework acts as an efficient inference-time enhancement and enables conversion to powerful multi-vector retrievers with minimal additional training. SMART thus elevates dense retrieval performance, overcoming long-standing expressiveness bottlenecks and maximizing architectural efficiency in multimodal embedding models.

