Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini
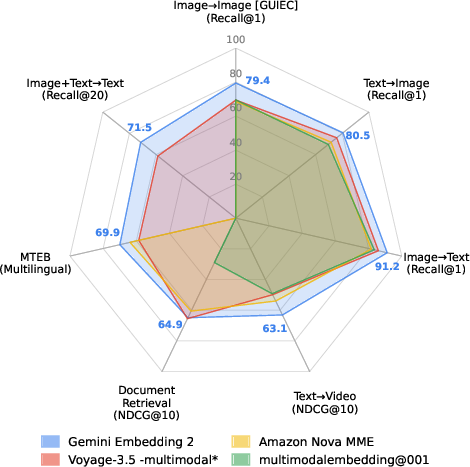
Abstract: We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini”
What is this paper about?
This paper introduces Gemini Embedding 2, a computer model that can understand many kinds of information—text, images, audio, and video—and turn them all into the same kind of compact “fingerprint” made of numbers, called an embedding. Because everything is mapped into one shared space, the model can match things across types, like finding a video from a sentence, an image from a question, or an answer from a picture plus some words.
Think of it like a giant world map where every piece of content—photos, sounds, videos, and sentences—gets coordinates. Things that mean the same (or belong together) end up close on the map; things that are different are far apart.
What questions are the researchers asking?
They set out to answer a few simple questions:
- Can one model create useful “fingerprints” for many types of content at once (text, images, audio, video), not just one at a time?
- Can it understand combinations, like a picture plus a question, or a video with a hint of text?
- Can it do well on lots of tasks without special tricks or instructions each time?
- Is “listening” to audio directly better than first turning speech into text (ASR) and then embedding it?
- Can one model beat specialized models in areas like code search or niche subjects (like astronomy or cooking)?
How does the model work? (Methods in everyday language)
Here’s the basic recipe the team followed:
- Turning everything into tokens: The model starts by converting different inputs (words, image pixels, audio signals, video frames) into a common format the computer can read, like turning all foods into ingredients you can mix.
- A shared brain: It uses a powerful transformer (a kind of neural network) that looks at all parts of the input at once (bidirectional attention), like reading a whole paragraph to understand the meaning, not just going word-by-word.
- Making a single fingerprint: After it processes the input, it averages the information to create one compact vector (a list of numbers) that represents the whole thing. You can think of it like summarizing a long story into a short, meaningful sentence.
- Learning by comparing (contrastive learning): The model practices by pulling matching pairs closer together and pushing non-matching pairs apart. For example, the caption “a dog catching a frisbee” should land close to the actual photo, and far away from a photo of a pizza. This is like training your sense of smell by comparing correct and incorrect scents.
- Two training stages:
- Pre-Fine-Tuning: The model first learns from lots of noisy, mixed tasks to get good at the basics.
- Fine-Tuning: Then it trains on targeted tasks (text, code, images, documents, audio, video), often with “hard negatives” (very tricky wrong answers) so it learns to be precise.
- Works at different sizes: It supports multiple embedding sizes inside one model (like Russian nesting dolls), so the same model can produce smaller or larger “fingerprints” depending on your needs.
- Model soup: They blend (average) different trained versions to combine strengths, like mixing the best parts of several recipes.
What did they find, and why is it important?
The model performed strongly across many tests. In simple terms, it:
- Finds the right image or caption more often than other models on popular image-text tests (like MSCOCO and Flickr30k).
- Finds the right video clips for a text query better than others on video tests (like Vatex and MSR-VTT).
- Does great on text-only tests in many languages (MMTEB), proving that being multimodal doesn’t hurt its language skills.
- Excels at code search (MTEB Code and CoIR), even versus code-focused models.
- Works well in specialized areas like microscopy (bioscience), fine art, astronomy, and cooking—without extra training for those areas.
- “Listens” better than a pipeline that first transcribes speech to text: using raw audio directly gave better search results than ASR+text in both same-language and cross-language tests.
Why this matters:
- One model that understands everything saves time and effort. You don’t need a separate model for text, pictures, audio, and video.
- It supports real-world tasks like searching inside documents with images, finding a moment in a video using a short description, or answering a question that needs both a picture and words.
- It’s strong even without special prompt instructions, so it works “out of the box.”
What could this change in the real world?
This model can power:
- Smarter search: Find the right photo, video moment, sound clip, or paragraph—even when your query is in a different format.
- Better recommendations: Suggest videos, songs, or images based on what you like, across content types.
- Stronger AI assistants: Agentic RAG systems that can read long, mixed documents (text+charts+images), watch videos, listen to audio, and fetch the right information quickly.
- Easier domain use: From labs to museums to kitchens, you can use it in specialized fields without custom training.
In short, Gemini Embedding 2 is like building a single, shared language for text, images, audio, and video. By putting everything on one map, it makes it much easier—and faster—to find and connect the right pieces of information across different kinds of media.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper presents strong results, but leaves several important aspects missing or underexplored. Future work could address the following gaps:
- Training data transparency: The paper does not specify the sources, sizes, licensing, language distribution, domain coverage, or proportions for text, image, video, audio, and code datasets used in PFT/FT, limiting reproducibility and assessment of potential data leakage or bias.
- Audio data coverage: The native-audio evaluation (MSEB) does not disclose languages, accents, noise conditions, sampling rates, or domain diversity, making it unclear how robust the audio embeddings are across real-world scenarios (e.g., noisy environments, low-resource languages).
- Mixed-modality generalization: Despite claiming support for “arbitrary interleaved inputs,” evaluations largely cover single- or dual-modality setups (e.g., image+text→text, text→video). There is no quantitative assessment for richer query configurations (e.g., audio+image+text, video+audio+text) or cross-modal retrieval with triple-modality inputs.
- Video temporal fidelity: Video embeddings are produced at 1 FPS up to 32 frames, but the impact of frame sampling strategies on fine-grained temporal event retrieval (e.g., brief actions, transitions) is not studied, nor are longer videos, streaming inputs, or adaptive frame selection.
- Document embedding pipeline: The paper references specialized document processing (tiling, layout understanding), yet provides no details on how PDFs, charts, tables, multi-page documents, or OCR are handled end-to-end, nor ablations on chunking, page selection, or layout-aware pooling.
- Instruction Retrieval weakness: The MMTEB Instruction Retrieval score (2.9) is notably low with no analysis of root causes or targeted remedies (e.g., instruction-specific training, task prompting strategies, or hard negative mining tailored to instructions).
- Hard negative mining: The training objective mentions optional hard negatives, but the mining strategy, cross-modal hard negative design, and effect on modality bias are unspecified and unablated.
- Pooling strategy constraints: Mean pooling is adopted without comparative analysis versus attention-based or learned pooling, especially for long interleaved sequences, documents, and videos where local salience may matter.
- Temperature and hyperparameter visibility: Key objective hyperparameters (e.g., temperature τ, batch sizes per task, learning rates, optimizer settings) and their tuning strategies are not reported, impeding reproducibility and targeted optimization.
- MRL sub-dimension choices: Only 768 and 1,536 sub-dimensions are supported; the rationale, trade-offs at other sizes (e.g., 256, 1024, 2048), and downstream indexing impacts (PQ/IVF performance, latency) are not explored.
- Model soup methodology: Checkpoint selection criteria, weighting schedules, and consistency across modalities (text, image, audio, video) are unspecified, and ablations are limited to video; it is unclear how souping affects text-only and audio tasks.
- Modality alignment diagnostics: The paper lacks interpretability analyses (e.g., cross-modal embedding geometry, cluster purity, alignment metrics) that would validate how well different modalities co-locate semantically in the unified space.
- Robustness and safety: No stress tests are reported for adversarial inputs, corruptions (e.g., blur, noise), out-of-distribution detection, fairness across languages/domains, or content safety (e.g., sensitive audio content); risk mitigation strategies are unspecified.
- Real-world retrieval scale: Aside from GUIEC (200k images), large-scale retrieval performance (multi-million to billion-scale corpora), indexing strategies, latency/throughput, and memory footprints are not evaluated.
- Efficiency and deployment: There is no discussion of inference costs, throughput on standard hardware, on-device feasibility, quantization, batching across modalities, or latency trade-offs for enterprise deployments.
- Cross-lingual audio→text retrieval: Audio evaluations focus on spoken query→text retrieval but do not examine mixed-language queries, speech-to-speech retrieval, or multilingual audio→multilingual text alignment beyond reported averages.
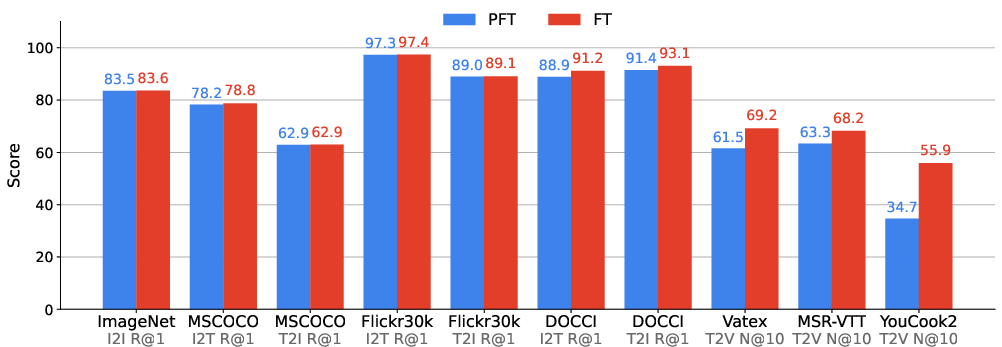
- Video in-domain vs. out-of-domain trade-offs: Fine-tuning with MSR-VTT/Vatex boosts in-domain scores but slightly degrades YouCook2; a principled method to balance task mixtures (adaptive sampling schedules, regularization) is not provided.
- Task sampling sensitivity: The paper notes sensitivity to multi-task sampling rates and batch sizes, but offers no systematic approach (e.g., curriculum learning, automated mixture optimization) to maintain cross-modality balance.
- End-to-end RAG validation: Although RAG is a key target use case, there is no end-to-end evaluation (latency, retrieval quality, grounding fidelity, augmentation robustness) comparing native multimodal embeddings versus ASR/caption pipelines in realistic agentic workflows.
- Benchmark comparability: Some competitor results are API-reported and may use differing evaluation settings; standardized, open, reproducible benchmarking setups and test-time instructions/prompts are not detailed.
- Tokenization and modality boundaries: The mechanics of interleaving (special tokens, separators, positional encodings across modalities) and their effect on retrieval are not described or ablated.
- Code retrieval generalization: Gains from synthetic data are large on MTEB Code and CoIR, but potential overfitting to synthetic distributions, performance on real developer logs, and generalization to non-text code artifacts (e.g., ASTs, binaries) are not explored.
- Audio prosody and paralinguistics: While native audio claims to preserve prosodic cues, no explicit evaluation isolates prosody, emotion, speaker characteristics, or emphasis effects on retrieval accuracy.
- Long-context constraints: The maximum token budget and degradation patterns for very long interleaved sequences (e.g., long documents with embedded media) are not reported, nor strategies for context compression or hierarchical pooling.
- Negative duplication mask: The mask for classification tasks prevents duplicate positives but does not address false negatives or semantic near-duplicates in retrieval; mining strategies to mitigate retrieval false negatives are not discussed.
- Domain breadth beyond images: Specialized-domain evaluations focus on image→text; equivalent domain-specific assessments for audio (e.g., bioacoustics), video (e.g., scientific microscopy videos), and documents (e.g., legal/medical PDFs) are missing.
- Privacy and governance: The paper does not address privacy implications of embedding sensitive audio/video, compliance (e.g., PII handling), or techniques like selective obfuscation and privacy-preserving embeddings.
- Release and reproducibility: There is no mention of releasing code, checkpoints, data mixtures, or evaluation scripts; reproducibility remains limited given the proprietary Gemini backbone and unspecified pre/post-processing.
Practical Applications
Practical Applications Derived from “Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini”
Below are actionable, real-world applications grounded in the paper’s reported capabilities (unified multimodal embeddings across text/image/audio/video, interleaved inputs, strong zero-shot performance, multilingual and code strength, native audio, document layout understanding, MRL multi-dimension support, and practical training insights such as model souping).
Immediate Applications
- Multimodal enterprise search and knowledge management (Software, Enterprise)
- What: Unified search over PDFs (with tables/charts/layout), slide decks, images, videos, audio transcripts/recordings, and code snippets using a single embedding model.
- How: Ingest → modality-aware segmentation (pages, figures, frames at ~1 FPS up to 32 frames, audio clips) → embed with Gemini Embedding 2 → ANN index (e.g., ScaNN/HNSW/FAISS/Milvus/Pinecone) → hybrid retrieval + re-ranking → display results.
- Assumptions/dependencies: Access to Gemini Embedding 2 API; document chunking and layout parsing still critical; privacy/compliance for audio/video; index scale and latency budgets; choose embedding dimension via MRL (768/1536/3072) to balance cost vs. quality.
- Multimodal RAG (Retrieval-Augmented Generation) across documents, images, and videos (Software)
- What: Answer complex questions by retrieving evidence from mixed modalities; support interleaved queries (e.g., image + text prompt to find relevant text passages).
- How: Use embeddings to fetch evidence (images, frames, pages, code) → pass to an LLM for grounded synthesis; minimal prompt engineering due to robust zero-shot embeddings.
- Assumptions/dependencies: Vector DB and chunking strategy; latency constraints for multi-modal retrieval; governance of content; optional domain-specific fine-tuning to boost in-domain accuracy.
- Voice search and audio-first retrieval without ASR (Contact Centers, Media, Education)
- What: Search large text corpora (FAQs, knowledge bases, course notes) using spoken queries; retrieve across languages.
- How: Directly embed audio queries (native audio > ASR pipeline per MSEB results) → match to text/document embeddings → surface results.
- Assumptions/dependencies: Audio ingestion pipelines (sampling, normalization); privacy/consent for voice data; ensure sufficient compute for real-time embedding.
- Video content search and recommendation (Media & Entertainment, Social Platforms, Education)
- What: Content-based retrieval and recommendations using text-to-video and image+text-to-video queries; zero in on temporal events using frame-level embeddings.
- How: Sample videos at ~1 FPS up to 32 frames (per evaluation setup) → embed and index frames/clips → support queries like “find the goal at minute 23” with combined textual and visual cues.
- Assumptions/dependencies: Storage and compute for frame extraction; timestamp mapping from retrieved frames back to the source timeline; moderation/fairness considerations for recommendations.
- E-commerce visual+text search and product discovery (Retail)
- What: Query with a product photo plus constraints (e.g., “same jacket but in navy, under $100”); style matching; near-duplicate detection.
- How: Cross-modal indexing of product catalog (images, titles, specs) and UGC; cosine similarity search + business rules; optional re-ranking with click/engagement signals.
- Assumptions/dependencies: High-quality catalog images and metadata; SKU lifecycle updates (re-embedding); hybrid ranking for price/availability; A/B-tested metrics.
- Code search and developer assistance (Software Engineering)
- What: Retrieve code snippets across 15+ languages, link code to docs/issues, and power “code RAG” for IDE assistants.
- How: Embed repositories (functions, files, docstrings) + developer queries; leverage state-of-the-art performance on MTEB Code and CoIR.
- Assumptions/dependencies: Indexing strategies for large monorepos; security/access control; privacy for proprietary code; continuous updates; choosing embedding dimension for speed in IDEs.
- Multilingual and cross-lingual enterprise search (Global Support, Public Sector)
- What: Search across 250+ languages without per-LLMs; cross-lingual query-to-doc matching for help desks and knowledge portals.
- How: Embed all languages into one space; serve localized experiences with a single index.
- Assumptions/dependencies: Language coverage vs. target user base; quality monitoring for low-resource languages; translation policies.
- Document QA over complex PDFs and forms (Finance, Legal, Insurance)
- What: Retrieve passages that consider layout and embedded text (charts/tables/footnotes).
- How: PDF/page segmentation → embed page-level or region-level content → retrieval for RAG-style QA.
- Assumptions/dependencies: Robust PDF segmenters/OCR where needed; chunking and overlap strategies; evaluation on internal doc formats.
- Media archives and newsroom search (Media & Entertainment, Cultural Heritage)
- What: Cross-modal search in large archives (scripts, clips, images, audio, subtitles) for editorial workflows and rights management.
- How: Unified embeddings for all assets → retrieval and clustering for curation and re-use.
- Assumptions/dependencies: Index scale; content rights; frame sampling parameters; descriptive metadata integration for re-ranking.
- Content moderation, IP protection, and near-duplicate detection (Trust & Safety)
- What: Cross-modal matching to find visually or semantically similar content, including memes (image+text) and clips.
- How: Batch-embed assets → nearest-neighbor search for similar/near-duplicate items → human-in-the-loop triage.
- Assumptions/dependencies: Policy definitions and thresholds; bias and fairness auditing; high-throughput indexing and alerting.
- Academic and scientific retrieval (Academia, R&D)
- What: Retrieve figures and methods from papers, link lab images (e.g., microscopy) to protocols and literature.
- How: Index papers (text + figures), domain images, and code; use zero-shot strength shown in specialized domains (microscopy/astronomy) for retrieval.
- Assumptions/dependencies: Domain-specific ontologies improve performance; robust figure/table extraction; data licensing.
- Customer support and troubleshooting (Consumer Electronics, Automotive)
- What: Visual+text triage (user uploads device photo + issue text to retrieve relevant KB articles or video how-tos).
- How: Cross-modal embeddings; map customer context to the closest troubleshooting steps or clips.
- Assumptions/dependencies: Secure media handling; privacy; careful UI for mixed-modality queries.
- Education and learning (EdTech)
- What: Retrieve lecture/video segments and diagrams answering student queries; build study guides across modalities.
- How: Index videos (frames) + slides + notes; support voice queries; multimodal RAG for summary answers.
- Assumptions/dependencies: Content rights; latency for classroom use; accessibility features (captions, alt text).
- Dataset curation, clustering, and deduplication (Data Platforms)
- What: Multimodal clustering to organize large image/video/audio/text corpora, remove duplicates, and find representative examples.
- How: Embed and cluster; use MRL to pick a smaller dimension for faster ops; sampled verification.
- Assumptions/dependencies: Compute limits; quality thresholds; human review for edge cases.
Long-Term Applications
- Agentic multimodal RAG trained end-to-end with ranking signals (Software, Search)
- What: Jointly optimize embeddings with downstream ranking/click signals and multi-hop reasoning for “agentic” systems.
- How: Integrate search logs and task success metrics into training; leverage model souping to balance domain gains and generalization.
- Assumptions/dependencies: Access to high-quality interaction data; careful evaluation for bias; scalable training pipelines.
- Real-time multimodal assistants and AR experiences (Consumer Devices, Industrial Ops)
- What: Live audio/video ingestion for context-aware retrieval and guidance (e.g., AR maintenance, meeting assistants).
- How: Stream embeddings on-device/edge → low-latency ANN → fetch relevant procedures or past incidents.
- Assumptions/dependencies: Low-latency hardware; on-device or federated deployment; privacy-by-design; battery/compute constraints.
- Healthcare multimodal retrieval and decision support (Healthcare)
- What: Retrieve relevant guidelines, prior cases, and literature from imaging (x-ray, microscopy), EHR notes, and waveforms.
- How: Unified embedding for clinical text/images/audio; domain fine-tuning and validation.
- Assumptions/dependencies: Strict regulatory compliance (HIPAA/GDPR), clinical validation, bias/safety testing, data de-identification; often requires in-domain fine-tuning.
- Multimodal robotics perception-to-instruction mapping (Robotics)
- What: Map current scene (video + audio + operator notes) to manuals or action policies; retrieve affordances from a library of tasks.
- How: Embed sensor frames and textual instructions in one space for rapid retrieval of relevant steps.
- Assumptions/dependencies: Tight integration with control systems; real-time constraints; safety certification.
- Search and recommendations trained with explicit business metrics (Ads, E-commerce, Media)
- What: Jointly train embeddings with click/conversion/watch-time signals to align with KPI goals.
- How: Combine contrastive learning with ranking signals; periodic model souping to stabilize.
- Assumptions/dependencies: Robust counterfactual evaluation; guardrails for unfair amplification; data volume and quality.
- Scientific discovery platforms (Academia, Pharma, Materials)
- What: Cross-modal linking of instrument outputs (microscopy, spectra), figures, and code to accelerate hypothesis generation.
- How: Domain-specific fine-tuning and synthetic data generation; integrate lab ELNs and literature.
- Assumptions/dependencies: Proprietary dataset access; domain ontologies; reproducibility and provenance tracking.
- Public-sector emergency response and policy delivery (Government)
- What: Retrieve procedures, maps, and prior incident videos from mixed-modality evidence during crises.
- How: Mobile/edge indexing; robust cross-lingual audio queries; offline-friendly caches.
- Assumptions/dependencies: Ruggedized hardware; security models; multilingual robustness in noisy conditions.
- On-device embeddings and federated indexing for privacy (Consumer, Enterprise)
- What: Local embedding and search over personal photos, notes, and recordings; federated/secure aggregation.
- How: Use MRL to reduce embedding size; quantization and acceleration; edge ANN libraries.
- Assumptions/dependencies: Efficient model variants; hardware acceleration; privacy-preserving protocols.
- Multimodal provenance and safety verification (Trust & Safety, Legal)
- What: Detect manipulated or harmful content by cross-modal matching and provenance linking.
- How: Embed assets and associated metadata (captions, transcripts) for robust similarity checks.
- Assumptions/dependencies: Evolving threat models; watermark/provenance standards; human oversight.
- Finance research and compliance (Finance)
- What: Retrieve insights across earnings call audio, filings (PDFs with charts), and news images.
- How: Unified indexing and RAG for analysts and compliance officers; cross-lingual support for global markets.
- Assumptions/dependencies: Data licensing; timeliness and latency; audit trails and explainability.
- Cultural heritage and museum curation (Arts & Culture)
- What: Cross-modal curation and retrieval across artwork images, catalog text, and audio guides; assist restoration research.
- How: Embed collections for curator queries and public discovery; multilingual support.
- Assumptions/dependencies: High-resolution media handling; rights management; domain taxonomies.
Notes on feasibility across applications:
- Model access and cost: Requires access to Gemini Embedding 2 and sufficient compute; embedding dimension choice via MRL impacts cost/performance.
- Data pipelines: Success depends on solid ingestion, segmentation (esp. video frames and PDF structure), and indexing.
- Evaluation and governance: Zero-shot is strong, but in-domain fine-tuning (and model souping) can be necessary; monitor bias, fairness, and security.
- Latency and scale: ANN infrastructure and caching are essential for large indexes and real-time use.
- Privacy and compliance: Audio/video and sensitive documents require rigorous governance, especially in regulated sectors.
Glossary
- Ablation Study: A controlled analysis to measure the contribution of components or training choices by systematically removing or modifying them. "Ablation Study"
- ASR: Automatic Speech Recognition; converting spoken audio into text, often used as a pipeline step in audio retrieval. "text-based alternatives like ASR or captioning."
- autoregressive: A generative modeling setup where each token is predicted conditioned on previous tokens only (causal direction). "causal (autoregressive) LLMs"
- bidirectional attention: An attention mechanism that allows each token to attend to tokens on both its left and right, enabling contextual encoding. "a transformer with bidirectional attention initialized from Gemini"
- bitext mining: The task of finding parallel sentence pairs across languages for translation or alignment. "- Bitext Mining"
- contrastive learning: A training paradigm that pulls semantically related pairs together and pushes unrelated pairs apart in the embedding space. "Applying large-scale contrastive learning"
- cosine similarity: A similarity measure between vectors based on the cosine of the angle between them, commonly used for retrieval. "retrieve using cosine similarity between queries and documents"
- cross-lingual: Involving multiple languages, typically measuring generalization or retrieval across language boundaries. "cross-lingual retrieval"
- cross-modal: Involving different data modalities (e.g., text, image, audio, video) and their interactions. "cross-modal retrieval"
- decoder-only: A LLM architecture comprising only the decoder stack, optimized for autoregressive generation. "decoder-only or massive LLM backbones"
- dual-tower models: Architectures with separate encoders for each modality that are trained to align in a shared embedding space. "dual-tower models like CLIP"
- encoder-only architectures: Models that encode input bidirectionally for understanding tasks (e.g., BERT), without a generative decoder. "encoder-only architectures (e.g., BERT"
- error propagation: The accumulation of mistakes across stages in a pipeline (e.g., ASR errors degrading retrieval). "suffers heavily from error propagation."
- Fine-Tuning (FT): A training stage that adapts a pre-initialized model to specific tasks or modalities with curated objectives and data. "Fine-Tuning (FT)"
- hard negative: A challenging negative example that is semantically close to the query and thus harder to distinguish than random negatives. "hard negative target triplets"
- hard negative mining: The strategy of selecting especially confusable negatives to improve model discrimination during training. "modality-aware hard negative mining"
- in-batch negatives: Using other examples within the same batch as negative samples for contrastive objectives. "with in-batch negatives"
- instruction tuning: Training an embedder or LLM with task-specific prompts/prefixes to align representations to target behaviors. "instruction-tuned representations"
- latent space: The continuous vector space where embeddings encode semantic relationships for retrieval and other tasks. "a robust, unified latent space"
- linear projection: A learned affine transformation that maps pooled token representations to the final embedding dimension. "a randomly initialized linear projection"
- masking term: A loss adjustment that prevents certain pairs (e.g., identical labels) from being treated as negatives in contrastive training. "This masking term is particularly relevant"
- Matryoshka Representation Learning (MRL): A technique to support multiple effective embedding dimensionalities by training overlapping subspaces. "using MRL"
- Mean Reciprocal Rank (mrr@10): A retrieval metric averaging the reciprocal ranks of the first relevant result, evaluated up to rank 10. "Mean Reciprocal Rank at 10 (mrr@10)"
- mean pooling: Aggregating token embeddings by averaging across the sequence to form a single vector. "we choose mean pooling"
- MMTEB: Massive Multilingual Text Embedding Benchmark; a suite of multilingual tasks for evaluating embedding models. "Massive Multilingual Text Embedding Benchmark (MMTEB)"
- MSEB: Massive Sound Embedding Benchmark; an evaluation suite for audio understanding and retrieval. "Massive Sound Embedding Benchmark (MSEB)"
- multimodal: Handling multiple data types (e.g., text, image, audio, video) natively within one model. "a native multimodal embedding model"
- Multimodal LLMs (MLLMs): LLMs extended to process and reason over multiple modalities beyond text. "Multimodal LLMs (MLLMs)"
- multi-stage training: Training organized into sequential phases (e.g., pre-fine-tuning then fine-tuning) to progressively adapt capabilities. "multi-stage type of training"
- multi-task training: Jointly training on many tasks to learn generalizable representations across domains and modalities. "multi-task setup"
- NCE (noise-contrastive estimation): A contrastive loss framework that differentiates positive pairs from sampled negatives. "noise-contrastive estimation (NCE) loss"
- NDCG@10: Normalized Discounted Cumulative Gain at rank 10; a ranking metric that emphasizes ordering and relevance in the top results. "NDCG@10"
- pooler: The component that aggregates token-level representations into a single sequence-level embedding. "a pooler is applied"
- Pre-Fine-Tuning (PFT): An adaptation stage that transitions a generative backbone toward encoding objectives before final fine-tuning. "Pre-Fine-Tuning (PFT)"
- RAG: Retrieval-Augmented Generation; systems that retrieve relevant documents to ground or improve generative outputs. "RAG applications"
- Recall@1 (R@1): The fraction of queries whose correct item appears at the top rank (position 1) in retrieval. "Recall@1"
- Reranking: Reordering a candidate set (often retrieved by a first-stage model) using a more precise model or features. "- Reranking"
- STS: Semantic Textual Similarity; tasks measuring how well embeddings capture similarity of meaning between text pairs. "- STS"
- tokenization: Converting raw inputs (text, image, audio, video) into sequences of tokens for model processing. "After tokenization"
- unimodal: Involving a single modality (e.g., text-only or image-only tasks) as opposed to cross-modal setups. "unimodal, cross-modal, and multimodal retrieval"
- zero-shot: Evaluating or applying a model to tasks/domains without task-specific fine-tuning or examples. "robust zero-shot performance"
Collections
Sign up for free to add this paper to one or more collections.