The Log is the Agent: Event-Sourced Reactive Graphs for Auditable, Forkable Agentic Systems
Abstract: Most agent frameworks are built around the LLM: a conversation loop comes first, then tools, then rules, and finally a logging layer bolted on for observability, with state persisted as retrievable "memory." We describe ActiveGraph, a runtime that inverts this arrangement. The append-only event log is the source of truth; the working graph is a deterministic projection of that log; and behaviors--ordinary functions, classes, LLM-backed routines, or logic attached to typed edges--react to changes in the graph and emit new events. No component instructs another; coordination happens entirely through the shared graph. This single design decision yields three properties that retrieval-and-summarization memory systems do not provide: deterministic replay of any run from its log, cheap forking that branches a run at any event without re-executing the shared prefix, and end-to-end lineage from a high-level goal down to the individual model call that produced each artifact. We present the architecture, a determinism contract that makes replay sound, and a worked diligence example whose full causal structure is reconstructable from the log alone. We discuss--without claiming to demonstrate--why this substrate is unusually well suited to self-improving agents, and how it extends the BabyAGI lineage and prior graph-memory research.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to build AI “agents” (computer programs that plan and act with LLMs). Instead of treating the agent as a chat loop with a little logging on the side, it flips the idea: the log itself is the agent. Think of it like this:
- The agent keeps a careful, never-changing diary (the log) of everything it does.
- A live “map” (a graph) is rebuilt from that diary at any time.
- Small helpers (behaviors) watch the map for changes, react, do work (including calling an AI model), and write new entries into the diary.
By making the diary the main thing, the system gains three superpowers: you can replay any run exactly, you can branch and try “what if” without redoing past steps, and you can trace every final answer back to the exact steps and model calls that created it.
What questions is it trying to answer?
In simple terms, the paper asks:
- Can we build AI agents so that every action is recorded in a single, trustworthy history?
- Can we make it easy to rewind and exactly replay what happened, even when AI models are usually random?
- Can we cheaply “fork” a run at any point to try a different choice without paying again for all past model calls?
- Can we give full “lineage” (a traceable chain) from a big goal down to every tiny decision and source?
The goal is not to make the agent smarter at tasks, but to make it more reliable, auditable, and experiment-friendly.
How does it work? (Methods and approach)
Here are the key ideas using everyday analogies:
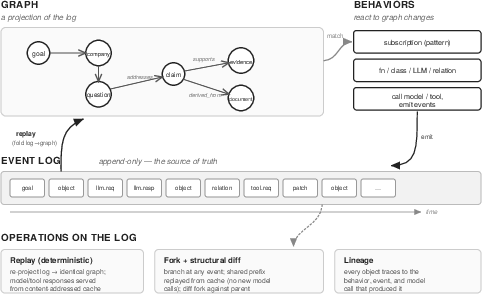
The diary (event log) is the source of truth
- Imagine a notebook where you only ever add new lines. Each line is an event: a goal set, a rule changed, a tool used, a model asked, or a fact produced.
- You never edit old lines—this makes the history trustworthy and permanent.
The map (graph) is rebuilt from the diary
- From the diary, the system builds a live “map” of objects (like goals, questions, documents, claims) and the connections between them (like “derived from” or “supports”).
- If you lose the map, you can rebuild it exactly by rereading the diary.
Helpers (behaviors) react instead of a boss orchestrating
- There’s no single master script. Instead, little helpers subscribe to patterns on the map, like “when a new company appears, create research questions.”
- When the map changes in a way a helper cares about, it acts and writes new events to the diary. Those events may trigger other helpers, and so on.
Making replay exact (determinism)
- AI models can be random. To replay exactly, the system saves the model’s request and response in the diary.
- On replay, it doesn’t call the model again; it just returns the saved answer. This guarantees the same results every time.
- Helpers follow a “determinism contract”: they can’t secretly use randomness or the current clock without recording it. If they do, strict replay will catch the mismatch.
Forking like a video game save file
- You can “fork” at event number k: copy the first k diary entries and then continue in a new branch.
- Past model calls in the shared prefix are free on the fork because their saved answers are reused from the diary.
- You can run the fork forward with different settings and compare outcomes.
Seeing differences and lineage
- The system can show “what changed” between two runs by comparing their maps (objects, links, edits).
- Every statement (like “Revenue grew 28%”) carries a breadcrumb trail back to the exact model call, rule, and evidence that created it.
What did they find, and why is it important?
The paper is a systems/architecture contribution (it doesn’t claim better task accuracy). It shows that treating the diary as the agent gives three big benefits:
- Exact replay: You can rebuild the agent’s state and steps byte-for-byte from the diary, even though models are usually random, because responses are cached.
- Cheap forks: You can branch at any point and test “what if” without re-paying for earlier model calls.
- Full lineage: You can trace every final output back to the goal, rules, evidence, and exact model calls.
They demonstrate this with a worked example: an “investment diligence” pack. Starting from a company name, the system generates questions, researches documents, extracts claims with evidence, finds contradictions and risks, and writes a memo. The important part: every claim in the memo is traceable to its sources and model calls through the diary.
Why does this matter? (Implications and impact)
- Better trust and audit: In fields like research, compliance, or finance, you need to explain not just the answer but how you got there. This system makes that easy by design.
- Faster iteration: Forking lets you try new prompts or rules without paying again for the whole history. That speeds up testing and comparison.
- Safer self-improvement: If an agent modifies its own rules or prompts, those changes are recorded. You can fork before the change, run after, and compare honestly. This enables careful, testable self-improvement.
- Practical trade-offs: Saving all model/tool responses takes storage; very long runs may need future features like checkpoints; and helpers must follow the determinism rules to keep replays clean.
In short, by making the diary the center of the agent, the system turns reliability (replay), exploration (forking), and explainability (lineage) from hard problems into built‑in features.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps the paper leaves unresolved and that future work could address:
- Deterministic replay in distributed settings: precise semantics for concurrent or distributed writers (ordering, contention resolution, exactly-once delivery, idempotence, CRDT/transaction model) are not specified.
- Long-run scalability: no checkpointing/compaction or incremental replay; replaying million-event runs from scratch is acknowledged but unaddressed (design and correctness of snapshots, partial replay, log pruning).
- Schema evolution at scale: a formal versioned type system, automated migrations, and guarantees for backward/forward compatibility across heterogeneous historical events are not detailed.
- Static enforcement of the determinism contract: no formal methods, static analysis, or sandboxing are provided to prevent wall-clock randomness, hidden I/O, or global-state dependence; enforcement is only via post hoc strict replay.
- External tool side effects: no mechanism to make forks “honest” when tools mutate the outside world (snapshots, mocks, transactional outboxes, idempotency protocols, or side-effect simulation on fork/replay).
- LLM caching robustness: stability of request canonicalization/hashing across library versions and providers (e.g., JSON key ordering, tool/function definitions, streaming outputs, tokenizer/version drift) is not analyzed; ambiguity about handling provider model updates under a constant model id.
- Code, prompt, and environment provenance: how behavior code, prompt templates, tool specs, and runtime environment are pinned/versioned and linked to events (e.g., content-addressed artifacts, container/image hashes) to ensure true replayability is not specified.
- Storage footprint and retention: strategies for compression, deduplication across forks, garbage collection of unreachable objects, retention policies, and cost modeling are unaddressed.
- Privacy and compliance: append-only logs conflict with “right to be forgotten”; selective redaction, encryption-at-rest, access control, and multi-tenant isolation policies are not described.
- Integrity and trust: no cryptographic tamper-evidence (hash chains, signatures), chain-of-custody, or verifiable lineage mechanisms beyond shared ids are provided.
- Behavior scheduling semantics: ordering, fairness, priority, backpressure, and starvation avoidance for behavior firing—while preserving determinism—remain unspecified.
- Loop/cascade control beyond budgets: only coarse ceilings are offered; no static cycle detection, confluence analysis, or guarantees of termination/liveness for reactive chains.
- Structural diff at scale: algorithms, complexity bounds, and human-centered representations for diffs over large graphs (semantic vs. syntactic diffs, noise reduction) are not given.
- Frames semantics and merge: how parallel sub-contexts deterministically converge (conflict resolution, merge policies, associativity/commutativity guarantees) is not defined.
- Multi-agent operation over a shared graph: namespaces, isolation, permissions, and conflict resolution between independent agents are open.
- Provenance query performance: indexing, time-travel queries, and efficient lineage reconstruction over very large logs are not evaluated.
- Empirical benefits: no quantitative evidence that replay/forking/lineage improve task accuracy, cost, latency, or reliability versus baselines; no benchmarks or ablations.
- Domain generality: demonstrations are limited; applicability to real-time agents, high-throughput tool use, or domains with volatile external data isn’t shown.
- Self-improvement pipeline: concrete procedures for proposing, selecting, and validating changes via fork-and-diff (objective functions, safety constraints, stopping criteria, avoiding Goodharting) are not developed.
- Fault tolerance and recovery: atomic event commits, crash consistency, replays after mid-flight failures, and exactly-once behavior execution semantics are unspecified.
- Identifier and time handling: guarantees for deterministic id generation across forks and runs, clock/timestamp provenance, and cross-timezone reproducibility are not detailed.
- Non-deterministic tools and data drift: strategies to capture and archive volatile inputs (e.g., web pages), detect and handle drift, and decide when to invalidate cached responses are missing.
- Type system and validation: strong typing, constraints/invariants, schema-level validation, and rejection of ill-formed or contradictory events are not elaborated.
- Performance engineering: throughput/latency under load, reactive scheduling overhead, batching, and safe parallelization of behaviors while maintaining deterministic outcomes are unevaluated.
- Integration with retrieval/memory: how to project embeddings/summaries as secondary indices from the log, maintain their consistency, and support efficient RAG over evolving state remains open.
- Developer tooling: interactive debugging, step-through causality, visual lineage/diff UIs, and ergonomics for authoring/testing behaviors are not discussed.
- Cross-platform reproducibility: sensitivity to library/runtime differences (JSON encoding, floating-point ops, tokenizer changes), and canonicalization libraries/protocols are not specified.
- Governance and collaboration: policies for who can edit/fork/merge runs, review workflows for behavior/prompt changes, and provenance of policy changes are undefined.
- Cost/budget management: predictive cost models, dynamic budget adaptation, and trade-offs between replay storage vs. live recomputation are not analyzed.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage ActiveGraph’s event-sourced runtime, deterministic replay, fork-and-diff, and full lineage capture. Each item names likely sectors, emergent tools/products/workflows, and key assumptions/dependencies.
- Agent CI/CD and observability
- Sectors: Software/LLMOps, Platform teams, SaaS
- Tools/Products/Workflows:
- “Flight recorder” for agents that captures every step (events, prompts, tool calls) for postmortems
- Agent regression testing suites that fork past runs to A/B prompts, tools, or policies without re-paying model costs
- Deterministic offline replays (fixtures + content-addressed cache) for reproducible bug reports and support tickets
- Visual lineage explorers and structural diff viewers integrated into MLOps dashboards
- Assumptions/Dependencies:
- Teams adopt the determinism contract (no hidden I/O/time/randomness) and wrap tools through the framework
- Storage and retention policies accommodate cached model/tool responses
- Existing agents are adapted to behaviors and the event log projection
- Audit-ready enterprise chatbots and RPA
- Sectors: Customer support, HR, IT helpdesk, Shared services
- Tools/Products/Workflows:
- End-to-end audit trails of chatbot and automation decisions (who/what/why/when) with strict replay proofs
- “Policy pack” behaviors that enforce and log compliance rules as events
- Incident-response playbooks that fork a problematic conversation at the offending event to test mitigations
- Assumptions/Dependencies:
- Governance acceptance of storing full interaction logs (PII handling, redaction, RBAC)
- Tool side effects are acknowledged (first execution mutates the world; replay is read-only)
- Investment and commercial due diligence with provenance
- Sectors: Finance (PE/VC/public markets), Corporate strategy, Market intelligence
- Tools/Products/Workflows:
- Deploy the provided diligence pack to produce memos where every claim links to questions, sources, and evidence
- Counterfactual forks to compare research strategies (e.g., different question generators, document retrieval settings)
- Compliance-ready exports where lineage is the deliverable (traceable from goal to memo)
- Assumptions/Dependencies:
- Accept that the paper claims systems guarantees, not accuracy gains—domain validation still required
- Source access and RAG/document tools integrated as ActiveGraph tools
- Legal review with chain-of-custody style lineage
- Sectors: Legal (contract analysis, e-discovery), Compliance
- Tools/Products/Workflows:
- Contract/risk extractors where each extracted clause, assertion, and risk maps to source passages and model calls
- “Red-team forks” to test alternative prompts and consistency checks before filing or disclosure
- Assumptions/Dependencies:
- Secure storage for sensitive documents; encryption and access controls
- Human-in-the-loop validation remains essential; the runtime supplies traceability, not legal judgment
- Healthcare administrative automation with audit trails
- Sectors: Healthcare admin (prior auth documentation, claims coding support), Revenue cycle management
- Tools/Products/Workflows:
- Event-level provenance for every suggestion and tool invocation (e.g., code lookup) to support audits
- Fork-and-diff to assess the impact of updated policies or prompt templates on documentation outcomes
- Assumptions/Dependencies:
- Limit to non-clinical decision support initially; clinical use demands additional validation and approvals
- PHI handling compliant with HIPAA/GDPR; strong data governance
- Scientific and academic research assistants with reproducible traces
- Sectors: Academia, Industrial R&D
- Tools/Products/Workflows:
- “LLM lab notebook” where hypotheses, evidence, and claims are objects with links and provenance
- Byte-identical replays for peer review and teaching reproducible methods
- Assumptions/Dependencies:
- Researchers model tasks as behaviors and accept event log artifacts as part of publication supplements
- Citation and source licensing policy integration
- LLM-infused data/ETL with end-to-end provenance
- Sectors: Data engineering, Analytics, BI
- Tools/Products/Workflows:
- Transformation steps (classification, extraction) logged as events with source–claim links for downstream audits
- Structural diffs between pipeline versions to explain metric changes to stakeholders
- Assumptions/Dependencies:
- Tooling wrappers around connectors/ETL steps; cost control for large runs via fixtures/checkpoints as systems scale
- Cost and carbon optimization via cached replays
- Sectors: Any org with heavy evaluation workloads
- Tools/Products/Workflows:
- Content-addressed cache to avoid re-running identical model calls during dev, QA, and demos
- Assumptions/Dependencies:
- Cache hygiene and deduplication; disk budget proportional to run sizes
- Policy pilots for transparent AI governance
- Sectors: Public sector, Regulated industries
- Tools/Products/Workflows:
- FOIA-ready/traceable decision records of AI-assisted processes
- Replayable impact assessments by forking at policy-change events and comparing outcomes
- Assumptions/Dependencies:
- Clear retention/redaction standards; stakeholder training to interpret lineage artifacts
Long-Term Applications
The following opportunities likely require additional research, scaling, or integration (e.g., concurrency models, checkpoints, sector-specific validation, regulatory approvals).
- Self-improving agents with fork-and-diff evaluation loops
- Sectors: Software/LLMOps, Autonomous systems
- Tools/Products/Workflows:
- “Agent PRs”: propose a prompt/tool/policy change, fork at the proposal point, run forward, diff outcomes, auto-merge on predefined metrics
- Continuous optimization harnesses that evaluate many candidates without re-paying for shared history
- Assumptions/Dependencies:
- Robust metrics and guardrails; sandboxing to avoid harmful side effects
- Governance for accepting/reverting self-modifications
- Scalable multi-agent and distributed deployments
- Sectors: Enterprise platforms, Robotics fleets, Supply chain
- Tools/Products/Workflows:
- Shared or sharded event logs with ordering/consistency for multiple agents
- Conflict resolution and merge semantics for graph state across distributed writers
- Assumptions/Dependencies:
- Concurrency control protocols; eventual consistency policies; security for cross-agent data sharing
- Checkpointing, compaction, and long-horizon operations
- Sectors: Any long-running agentic workload (ops, monitoring, planning)
- Tools/Products/Workflows:
- Periodic checkpoints/snapshots and log compaction to handle million-event runs
- Time-travel queries over compacted histories
- Assumptions/Dependencies:
- Sound snapshot/restore semantics that preserve replay guarantees
- Safety-critical autonomy and digital twins
- Sectors: Energy, Manufacturing, Transportation/Robotics
- Tools/Products/Workflows:
- “What-if” scenario planning by forking control runs into simulated twins to test policy changes before deployment
- Post-incident analyses with strict replay and structural diff to isolate causal factors
- Assumptions/Dependencies:
- High-fidelity simulators; certification processes; isolation of real-world side effects from simulated forks
- Regulated clinical decision support with verifiable provenance
- Sectors: Healthcare (clinical), Pharma
- Tools/Products/Workflows:
- End-to-end lineage from patient input to recommendation, including model/tool specifics for audit and validation
- Assumptions/Dependencies:
- Clinical trials, FDA/EMA approvals, bias and safety evidence; robust PHI protections
- Finance-grade autonomous workflows with audit and rollback
- Sectors: Banking, Trading, Insurance, AML/KYC
- Tools/Products/Workflows:
- Agentic risk assessments, model-assisted investigations, and claims adjudication with replayable histories
- “Change impact forks” to evaluate new risk policies or model versions on historic cases
- Assumptions/Dependencies:
- Model risk management alignment (SR 11-7-like frameworks), regulator acceptance, strong controls for side effects
- Government policy design and evaluation via counterfactuals
- Sectors: Public policy, Urban planning
- Tools/Products/Workflows:
- Forking at policy-draft events to compare alternative interventions and produce transparent, auditable impact narratives
- Assumptions/Dependencies:
- Data availability and validation; stakeholder interpretability of lineage and diffs
- Marketplaces of reusable “packs” with lineage guarantees
- Sectors: Software ecosystems, Vertical AI vendors
- Tools/Products/Workflows:
- Domain packs (e.g., safety audits, procurement, clinical triage) published with sample fixtures and reproducible runs
- Certification badges for packs that pass strict replay and provenance checks
- Assumptions/Dependencies:
- Community standards for schemas, migrations, and provenance; versioning and compatibility tooling
- Explainable analytics and BI with causal tracebacks
- Sectors: Enterprise analytics, Risk/Compliance
- Tools/Products/Workflows:
- Dashboards where every metric or insight has a click-through lineage to source data, transformations, and model calls
- Assumptions/Dependencies:
- Harmonized schemas across data sources; integration with data catalogs and governance layers
- Consumer-grade personal knowledge and automation with provenance
- Sectors: Daily life, Productivity
- Tools/Products/Workflows:
- “Personal agent journals” that show why a recommendation or plan was produced, and allow users to fork scenarios safely
- Assumptions/Dependencies:
- Simple UX for non-experts; private-by-default storage; local or encrypted cloud caches
Cross-cutting assumptions and dependencies
- Determinism contract adherence: behaviors must avoid non-deterministic reads outside the framework; violations surface in strict replay.
- Storage/governance: logs include prompts, tool arguments, and outputs; plan for PII/PHI handling, encryption, retention, and access control.
- Tool side effects: first execution mutates the real world; replay is deterministic but does not undo side effects—sandboxes/simulations mitigate risk.
- Model/provider changes: replay relies on cached responses for exactness; forks that change prompts/models will re-execute downstream calls.
- Schema evolution and migration: operational discipline and tooling needed as object/event types evolve.
- Performance/scaling: very long runs need checkpoints/compaction; distributed use requires ordering and concurrency models.
These applications flow directly from the paper’s core innovations: treating the append-only event log as the source of truth, projecting a deterministic graph from it, reacting via behaviors, caching model/tool responses for exact replay, and enabling cheap, honest counterfactual forks with structural diffs and full lineage.
Glossary
- append-only event log: A write-once, ordered history of events where entries are only appended and never mutated, serving as the system’s source of truth. "The append-only event log (bottom) is the source of truth."
- blackboard systems: An AI architecture where independent knowledge sources coordinate by reading from and writing to a shared knowledge structure. "Blackboard systems~\cite{blackboard} from the 1970s and 80s organized problem solving around a shared knowledge structure that independent ``knowledge sources'' read from and wrote back to, with no direct calls between them"
- command-query responsibility segregation: A design pattern that separates operations that change state (commands) from those that read state (queries). "Event sourcing and command-query responsibility segregation are established patterns in data systems"
- content-addressed cache: A cache keyed by hashes of full request content, enabling exact replay of model/tool outputs without re-executing them. "including a content-addressed cache that records model and tool responses so replay performs no new model calls"
- counterfactual: A hypothetical alternative scenario used to evaluate “what if” changes without re-executing shared history. "cheap counterfactual forks over computations that include nondeterministic model calls"
- Cypher: A graph query language used to express structural patterns over graphs. "a graph-shape pattern expressed in a Cypher subset"
- determinism contract: A set of rules requiring behaviors to be deterministic functions of their inputs during replay (e.g., no uncontrolled I/O or randomness). "a determinism contract that makes replay sound"
- deterministic fold: Computing current state by deterministically folding (reducing) an event log into a projection. "graph state is a deterministic fold over an append-only event log"
- event sourcing: An architectural approach where system state is derived from an immutable sequence of events rather than being stored directly. "event sourcing and CQRS, in which state is a fold over an immutable event log"
- fork: A branched run that shares a parent’s event prefix up to a cutoff and then proceeds independently. "A fork branches a run at a chosen event."
- frame: A lightweight, in-run sub-context for parallel branches that reconverge within the same log. "The runtime offers a lighter-weight in-run primitive, the frame, for parallel sub-contexts that converge back within a single run and share that run's log."
- incremental dataflow: A computation model where derived results update reactively as inputs change. "the core of incremental dataflow and of spreadsheet engines."
- lineage: The end-to-end causal trace linking goals, decisions, and artifacts back to their origins. "end-to-end lineage from a high-level goal down to the individual model call that produced each artifact."
- LLM-backed behavior: A behavior whose logic is implemented by a LLM call, with requests and responses logged as events. "an LLM-backed behavior, which is what makes ActiveGraph an agent rather than a workflow engine."
- monotonic id space: An identifier sequence that only increases, avoiding collisions across branches. "After the cutoff the fork has its own monotonic id space, so ids do not collide."
- permissive replay: A replay mode that allows deviations when hashes don’t match, issuing fresh calls while using cache for matches. "will pass permissive replay and fail strict replay"
- provenance: Metadata capturing the origin and derivation of objects, including which behavior and event created them. "carries a provenance block naming the behavior that created it"
- relation-behavior: Logic attached to a specific relation (edge) type, firing when that relation is established or changed. "and a relation-behavior---logic attached to a typed edge, so that the act of relating two objects can itself carry computation."
- schema evolution: The process of changing event or object type definitions over time while preserving historical data. "Schema evolution---changing an event or object type after events using the old shape are already on disk---is handled by migration tooling but remains a real operational burden."
- strict replay: A replay mode that requires the live reproduction of events to exactly match the recorded log, otherwise raising a divergence error. "A green strict replay is a proof that the run is reproducible."
- structural diff: A comparison of graph structures between runs to identify differences in objects, relations, and patches. "A structural diff between parent and fork then reports exactly which objects, relations, and patches differ as a consequence of the change introduced at the fork point."
- typed edge: A graph relationship with an explicit type, enabling semantics and edge-attached computation. "relation-behaviors make typed edges first-class carriers of logic"
Collections
Sign up for free to add this paper to one or more collections.