- The paper introduces CopT, a novel method that first generates a draft answer and then employs contrastive continuous verifiers to trigger selective on-policy thinking.
- It leverages a reverse-KL estimator and dynamic visibility control to balance answer quality with token efficiency, achieving up to 23% accuracy gains and significant token reductions.
- Empirical results across math, coding, and agentic reasoning benchmarks demonstrate CopT’s potential for cost-efficient, transparent, and adaptive LLM deployments.
CopT: Contrastive On-Policy Thinking with Continuous Spaces for General and Agentic Reasoning
Introduction and Motivation
Chain-of-thought (CoT) prompting has established itself as an effective paradigm for extracting explicit reasoning behavior from LLMs. However, the canonical approach incurs inefficiencies by mandating exhaustive deliberation prior to answer emission, which delays answer availability and increases token consumption. Empirical observations indicate that LLMs often possess performative reasoning abilities: they can identify plausible answers before completing full reasoning chains. Consequently, the traditional CoT protocol can force models to "think aloud" unnecessarily, wasting computation and tokens.
CopT introduces a reversed reasoning protocol: LLMs first generate a draft answer, then decide if, and how much, explicit reasoning (on-policy thinking) should be performed to reflect on and potentially amend the draft. The framework achieves high token efficiency while preserving or improving accuracy on complex reasoning tasks, all at test-time without additional fine-tuning.
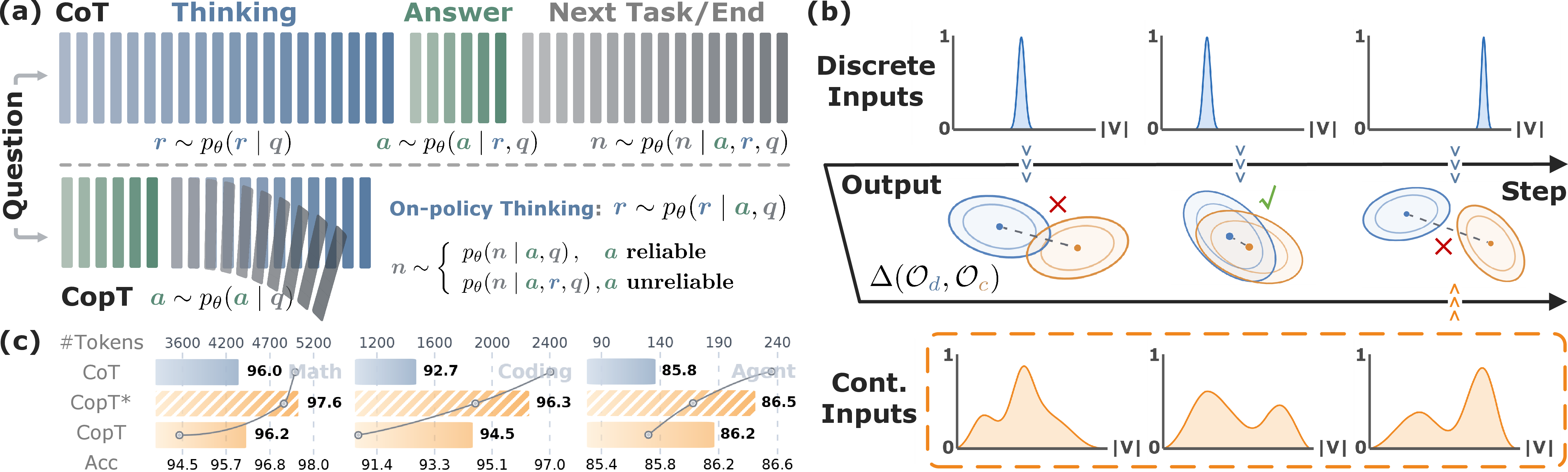
Figure 1: (a) Comparison between canonical CoT and CopT; (b) CopT's contrastive verification in discrete vs. continuous input modes; (c) CopT attains higher peak accuracy and dramatically reduces token usage.
Methodological Framework
The core innovation in CopT is to treat continuous embeddings as contrastive verifiers, not generation vehicles, at inference time. The method consists of two tightly coupled components:
1. Draft Answer Stage:
The model outputs a preliminary answer with minimal "thinking". At each generation step, CopT caches (i) the probability assigned to the chosen token and (ii) a continuous embedding formed as the expectation over the next-token distribution. This embedding retains token-level uncertainty information.
2. Reliability Estimation via Contrastive Reverse-KL:
CopT introduces a sequence-level, normalized reverse-KL estimator κa that compares the token-wise log-likelihood under two situations: the original (discrete-input) and a constructed (continuous-input) context, the latter formed from the cached embeddings during draft answer generation. A high κa implies draft unreliability, likely requiring deeper thinking.
3. On-Policy Thinking with Dynamic Visibility Control:
If κa exceeds a threshold, CopT triggers reflection steps (on-policy thinking). Critically, it controls the draft answer's visibility: using a chunked, intra-chain contrastive estimator κr, CopT dynamically decides, at each chunk, whether to expose the draft answer as context. This mechanism balances the utility of partial information in the draft with the risk of being misled by errors.
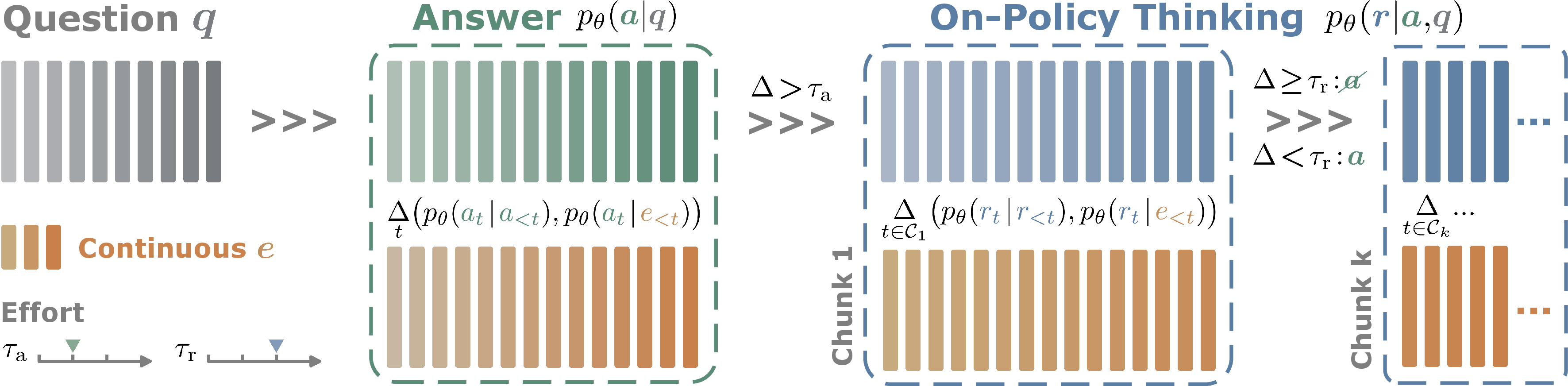
Figure 2: Draft answer followed by on-policy reflection; reliability and exposure are constantly re-evaluated contrastively.
Theoretical Interpretation
CopT's KL-based draft reliability estimator quantifies answer-relevant uncertainty, not mere latent state entropy. The paper proves that under a mixture-linear assumption for the continuous prefix, the expected reverse-KL estimator is equivalent to the mutual information I(S;A) between the unresolved latent state S and the generated answer token A. This means CopT is sensitive only to uncertainty that actually affects the answer distribution, not useless latent indeterminacy. High latent entropy is not penalized when all plausible reasoning chains agree on the answer.
Empirical Results
CopT is validated on a battery of math (GSM8K, Math500, AIME 2024/2025, GPQA Diamond), coding (HumanEval, LeetCode-Contest, MBPP), and agentic reasoning (BFCL v4, ZebraArena) benchmarks across Qwen3 (transformer-based) and Qwen3.5 (hybrid, agent-focused) models at multiple scales.
Main Quantitative Outcomes
- Peak accuracy improvements range up to 23% on hard benchmarks (AIME, ZebraArena large), even without any retraining.
- At matched or better accuracy, token usage reductions approach 57% on medium-difficulty math/coding and 40%+ on agentic tasks.
- On more difficult instances, CopT is able to flexibly increase reflection to achieve high accuracy, while for easy instances, it collapses to "shallow" inference with substantial latency and token savings.
Figure 3: (Left, Center) Reasoning effort is controlled by reliability thresholds, trading off accuracy and token cost; (Right) Latency reductions due to early answer emission and selective reflection.
CopT surpasses existing training-free latent CoT baselines such as Soft-Thinking (Zhang et al., 21 May 2025) and SwiReasoning (Shi et al., 6 Oct 2025) in both accuracy and interpretability, as its generated reasoning traces remain in natural language.
Agentic Reasoning
On long-horizon, multi-turn benchmarks (ZebraArena), accuracy gains accumulate—CopT provides 13–23% improvement on medium/large splits with concurrent token and latency reductions.
Ablations and Control
CopT demonstrates robust and meaningful draft error detection through its contrastive reliability estimator. Dynamic visibility control during on-policy thinking enhances the capacity for error correction without overexposing unreliable content.
Figure 4: (Left) κa sharply identifies draft answer errors; (Right) τr threshold modulates correction rate and exposed tokens in reflection.
Practical and Theoretical Implications
By enabling earlier access to answers and employing dynamic, verifiable reasoning augmentation, CopT makes reasoning-focused LLM deployments substantially more cost-efficient. This is significant for commercial and scientific applications where latency and API costs are bottlenecks. Theoretically, the approach unifies explicit CoT readability with contrastive calibration from latent reasoning research, making it suitable for LLM deployment scenarios where both transparency and inference-time efficiency are critical.
Notably, CopT is fully training-free, requiring only inference-time modifications for open-weight (logit-accessible) models. However, its reliance on next-token probabilities may limit direct application to closed API LLMs without further adaptation.
Future Directions
Key areas for extensions include the design of API-compatible reliability surrogates, the adaptation of CopT to multimodal agentic environments, investigation into lower-variance estimators through multi-sample scoring, and integration with self-improvement or long-term memory protocols in persistent agentic systems.
Conclusion
CopT establishes a flexible, contrastive, and training-free protocol for controlling LLM reasoning effort and answer exposure. By reversing the CoT workflow and employing mutual information-grounded verification, the method achieves strong gains in both efficiency and accuracy across diverse reasoning tasks and model architectures. The integration of continuous contrastive verification as an inference-time primitive points toward a new direction for adaptive, resource-aware, and transparent LLM reasoning systems.

