- The paper introduces CAP-CoT as a cyclic adversarial prompt framework that leverages a solver, adversarial challenger, and feedback agent to address reasoning instability in LLMs.
- It demonstrates improved accuracy and reduced output variability on benchmarks like MATH, achieving 89.2% accuracy on math tasks through iterative prompt refinement.
- The framework balances token efficiency with robust stability by using structured feedback, paving the way for scalable inference-time prompt optimization without full model finetuning.
CAP-CoT: Cycle Adversarial Prompt Optimization for Chain-of-Thought Stability and Accuracy in LLM Reasoning
Motivation and Foundation
The CAP-CoT framework addresses inherent instability and lack of robustness in Chain-of-Thought (CoT) reasoning for LLMs. Standard CoT approaches, while effective in eliciting intermediate steps for mathematical and symbolic reasoning, exhibit pronounced sensitivity to prompt perturbations, premise order, and contextual distractions—resulting in inconsistent or fragile solutions, particularly for long and complex tasks. Previous strategies focus on enhancing the forward trace and aggregating multiple reasoning trajectories but generally neglect iterative correction mechanisms leveraging explicit contrasts between correct and erroneous chains.
CAP-CoT introduces a principled multi-agent cycle—comprising a solver, an adversarial challenger, and a feedback agent—designed to optimize prompts through adversarial contrast and structured refinement. The adversarial component in CAP-CoT is task semantic rather than safet-oriented; its purpose is to elicit logical vulnerabilities in the chain, not to induce prohibited behavior.
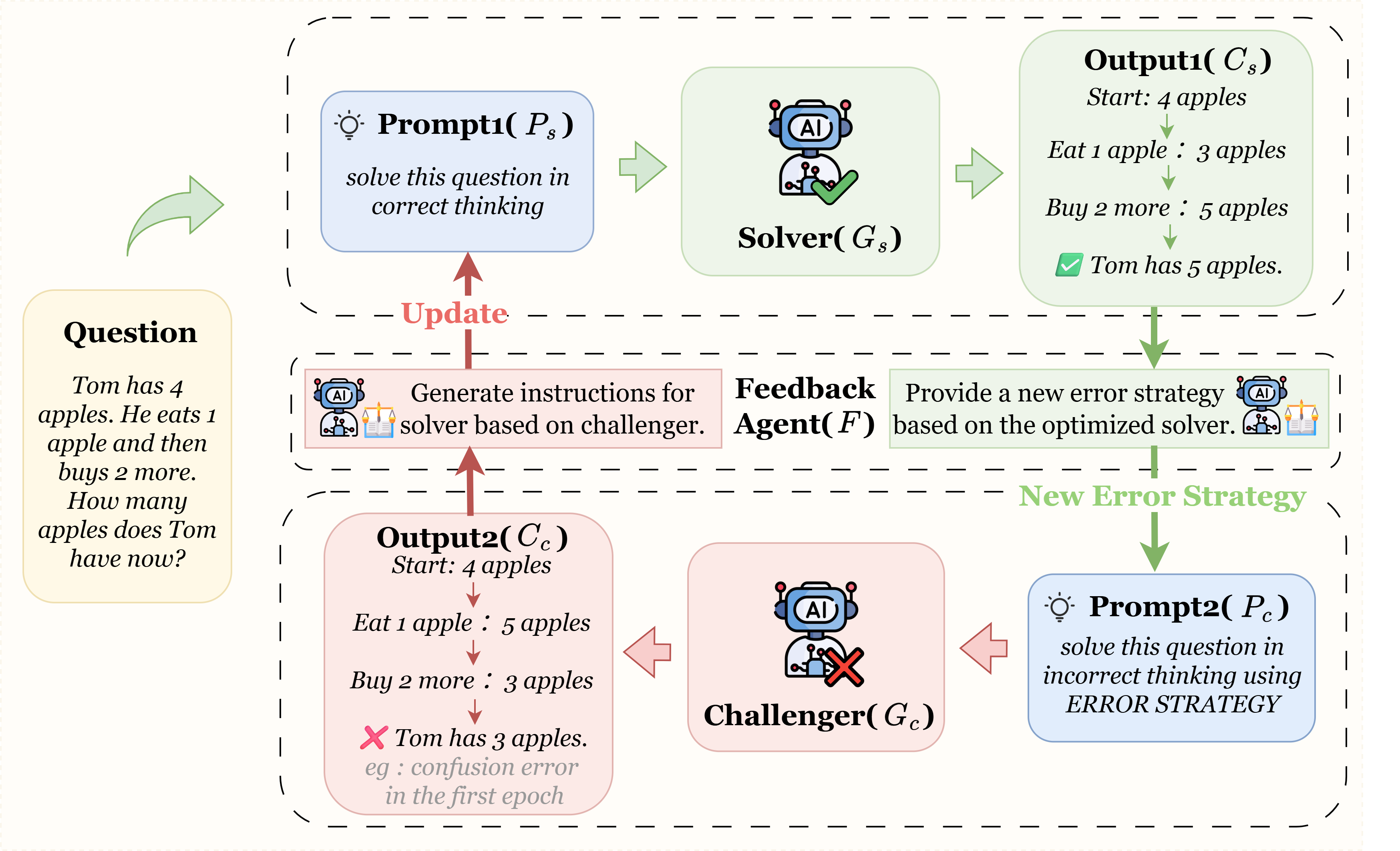
Figure 1: Overview of CAP-CoT, showing the cycle between solver, adversarial challenger, and feedback agent with prompt refinement in both directions.
Framework Mechanics
The CAP-CoT cycle operates with three distinct yet collaboratively optimized LLM agents:
- Solver Agent (GS): Generates stepwise, logical CoT traces for the input task.
- Adversarial Challenger (GC): Constructs semantically plausible but deliberately flawed reasoning chains using a dynamically evolving taxonomy of error types (e.g., logical leap, concept confusion, vague reasoning, wrapper errors).
- Feedback Agent (F): Contrasts solver and challenger outputs via step-aligned structured feedback, identifying fragile reasoning steps and guiding explicit prompt updates for both agents.
Prompt refinement is achieved via Structured Feedback Prompt Refinement (SFPR), in which the feedback agent's recommendations are used to concretely update both the solver and challenger prompts. The process iteratively calibrates the error strategies in GC to match the solver's improving performance, ensuring that hard negatives remain diagnostic as the system evolves. Unlike static negative examples, this dynamic adversarial loop continuously surfaces new failure modes in the solver.
Empirical Evaluation
Accuracy and Robustness
CAP-CoT demonstrates consistent improvement in accuracy and stability compared to a spectrum of baseline methods, including CoT, CoT-SC, Self-Refine, Analogical Prompting (AP), Contrastive CoT (CCoT), Tree-of-Thought (ToT), Graph-of-Thought (GoT), Forest-of-Thought (FoT), Atom of Thoughts (AoT), MAD, and ECON. Benchmarks span MATH, GSM8K, BBH, MMLU-CF, HotpotQA, and LongBench, covering advanced mathematics, logical reasoning, multi-hop QA, and long-context tasks.
Numerical results indicate that CAP-CoT achieves significant gains over baselines, particularly on math-intensive and multi-hop tasks. For example, on the GPT-4o backbone, CAP-CoT attains accuracy of 89.2% on MATH, compared to 85.5% (AoT) and 86.4% (ECON), and 84.0% average across all six datasets with three optimization rounds (see Figure 2).
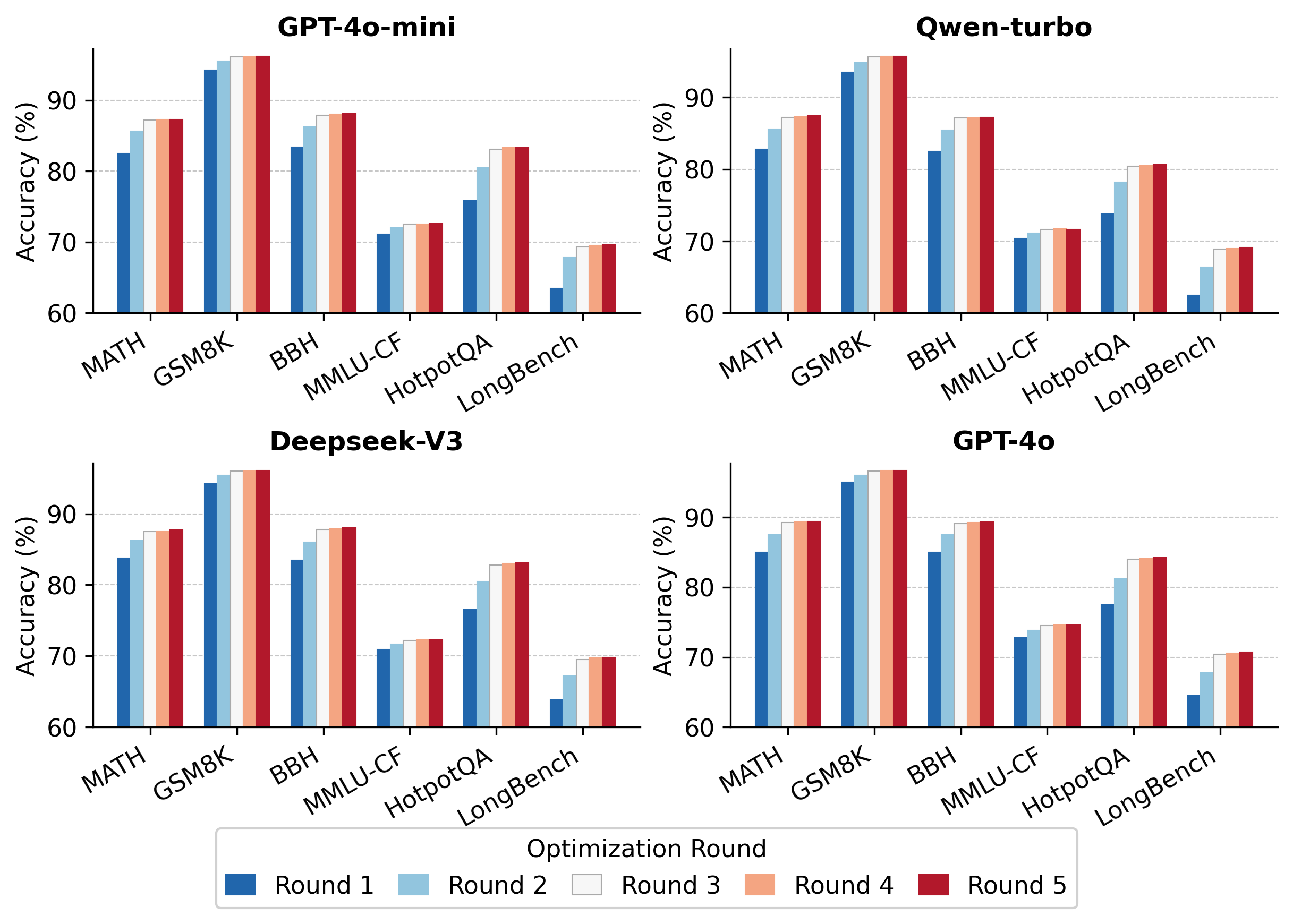
Figure 2: Accuracy improvement across optimization rounds for four LLM backbones, highlighting rapid gains and saturation by round 3.
Ablation analyses show that the adversarial challenger and structured feedback are critical components, yielding the largest improvements in both solver accuracy and cross-run stability.
Stability Under Sampling and Perturbations
The effect of LLM sampling temperature is examined in the context of reasoning stability. CAP-CoT delivers substantial reduction in answer variability compared to baselines. With increased temperature (up to 1.0), mean variation of accuracy drops below 1.0 after three optimization rounds, maintaining high robustness against stochasticity in output sampling.
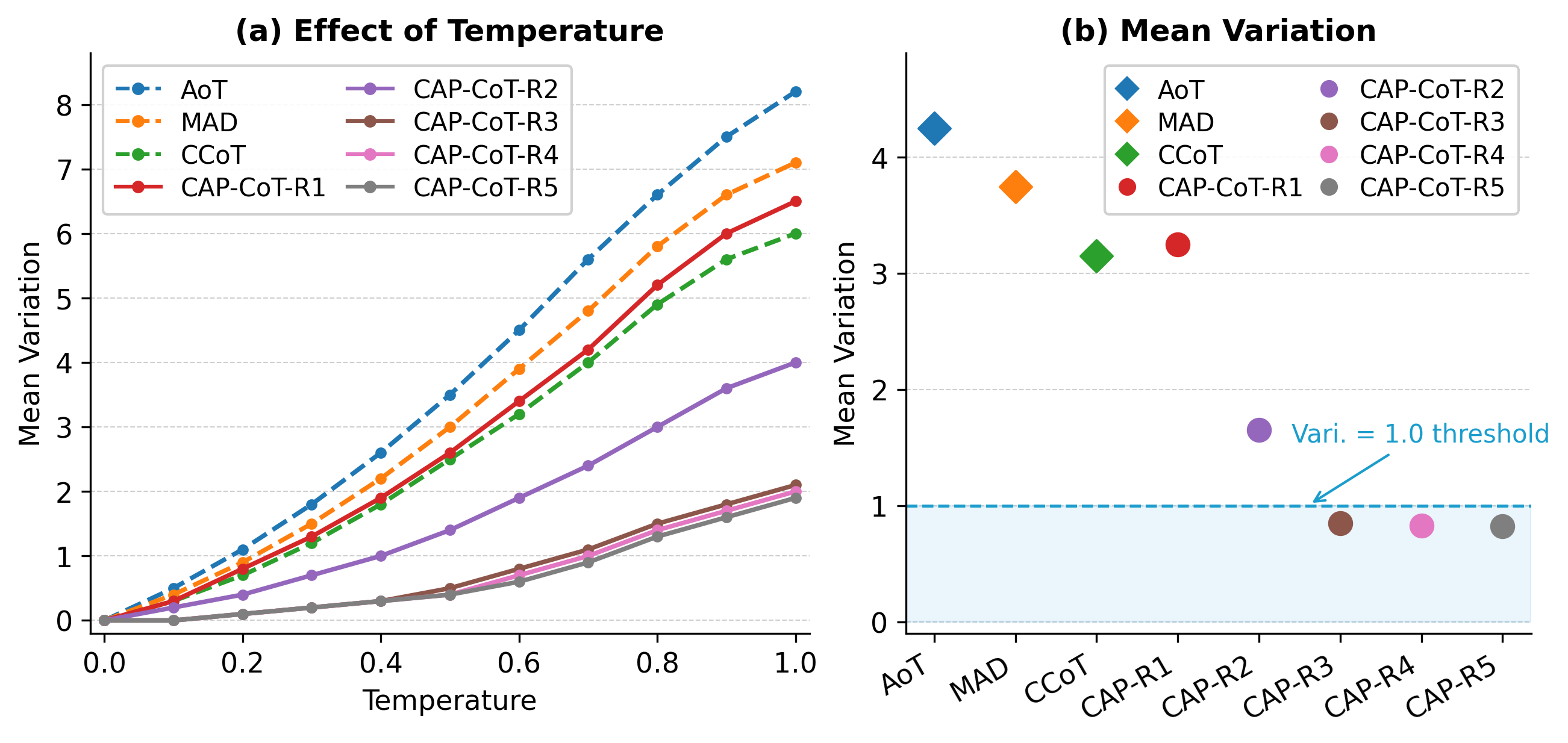
Figure 3: Comparison of variation in accuracy as a function of temperature and optimization rounds; CAP-CoT exhibits markedly superior stability.
Token Efficiency
Reasoning cost, measured by average token consumption and efficiency per question, is a practical concern. While single-pass methods (CoT, AP) are most efficient, higher-performing strategies such as ToT, GoT, and committee-based approaches incur major token costs due to combinatorial expansion. CAP-CoT strikes a favorable balance, achieving above-baseline accuracy with moderate overhead: additional challenger and feedback agent generations are necessary only during a few optimization rounds, after which inference proceeds via the solver alone.
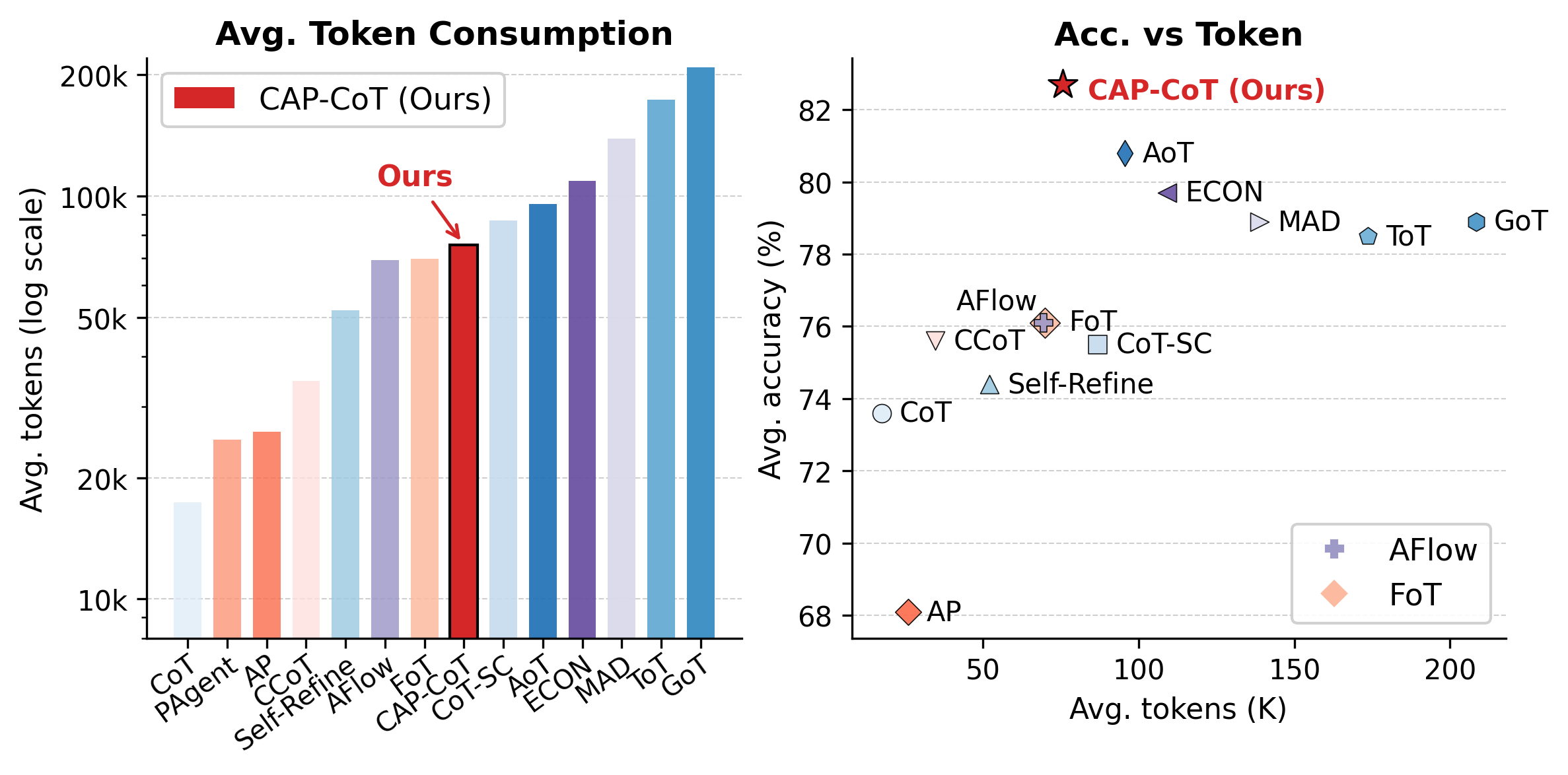
Figure 4: Per-question token consumption and efficiency across six datasets, showing CAP-CoT achieves high accuracy without heavy combinatorial cost.
Design Minimality and Error Taxonomy
CAP-CoT's adversarial component is initialized by a lightweight taxonomy of four error families—jump, confusion, fuzzy, wrapper—designed to bootstrap the feedback cycle. Single-error cold-start ablations demonstrate near-equivalent final performance across all variants after two to three cycles, indicating that the framework is not dependent on elaborate error engineering. Subsequent cycles, guided by feedback, naturally discover and target more fine-grained and solver-specific weaknesses.
Qualitative examples from the appendix confirm that the challenger and feedback loop evolve error patterns with increasing diagnostic value, progressing from generic omissions or confusion to nuanced logical gaps and subtle invalid assumptions.
Implications and Future Directions
CAP-CoT formalizes a feedback-driven, adversarial prompt optimization paradigm that directly improves CoT stability and accuracy while maintaining competitive token efficiency. By reifying explicit contrasts between plausible correct and plausible erroneous reasoning chains, the system enables LLMs to learn from both positive demonstrations and dynamically generated hard negatives. This approach is highly compatible with preference-based learning, workflow-level prompt optimization, and modular agentic architectures.
Practically, CAP-CoT offers scalable, inference-time prompt refinement for deployed solvers, sidestepping parameter updating and training-time finetuning. Theoretically, it establishes a foundation for contrastive and adversarial prompt engineering—integrating principles from supervised contrastive learning, self-refinement, and dynamic agent collaboration.
Potential extensions include integration with multimodal reasoning tasks, continuous strategy evolution under nonstationary task distributions, incorporation into multi-agent committee frameworks, and synthesis with preference alignment mechanisms from RLHF.
Conclusion
CAP-CoT systematically improves LLM reasoning robustness via cycle adversarial prompt optimization, pairing solver and challenger chains with rigorous feedback for prompt refinement. Empirical results across multiple datasets and backbones establish superior and stable accuracy over prominent baselines, with favorable efficiency. The framework's modular, feedback-driven adversarial cycle underpins future developments in robust AI reasoning, prompting further exploration of contrastive prompt engineering, adaptive error taxonomy, and agentic optimization workflows for LLMs (2604.23270).

