- The paper demonstrates that hardware-native destination-agnostic communication for MoE can eliminate costly software mediation and yield up to 3.08× per-layer speedup.
- It introduces specialized modules (AAU, RPM, DAM) that optimize packet merging, address resolution, and dependency management across GPUs.
- Experimental results show robust scalability and minimal hardware overhead, closing 96.8% of the latency gap to the theoretical optimum.
MoE-Hub: Hardware-Software Co-Design for Seamless MoE Overlap in Multi-GPU Systems
Introduction and Motivation
The Mixture-of-Experts (MoE) architecture is central to the scaling of LLMs, enabling multi-trillion parameter capacity with only marginal additional per-token computational cost. MoE achieves this via sparse routing: each input token is dynamically assigned between experts (sub-networks), and only a subset of experts are active per token. This architectural paradigm, validated in models such as Mixtral-8×7B, DeepSeekMoE, and various state-of-the-art LLMs, demands expert parallelism—partitioning expert parameters across multiple GPUs due to prohibitive memory footprints.
However, distributed MoE execution introduces severe inter-GPU communication bottlenecks. Dispatching and combining tokens between experts across devices contributes up to 47% of layer execution latency. The canonical optimization—computing-communication overlap—remains cumbersome and suboptimal due to a fundamental abstraction mismatch: MoE’s dynamic token routing conflicts with commodity GPU’s static address-centric communication model, forcing complex software mediation for address resolution and synchronization (Figure 1).
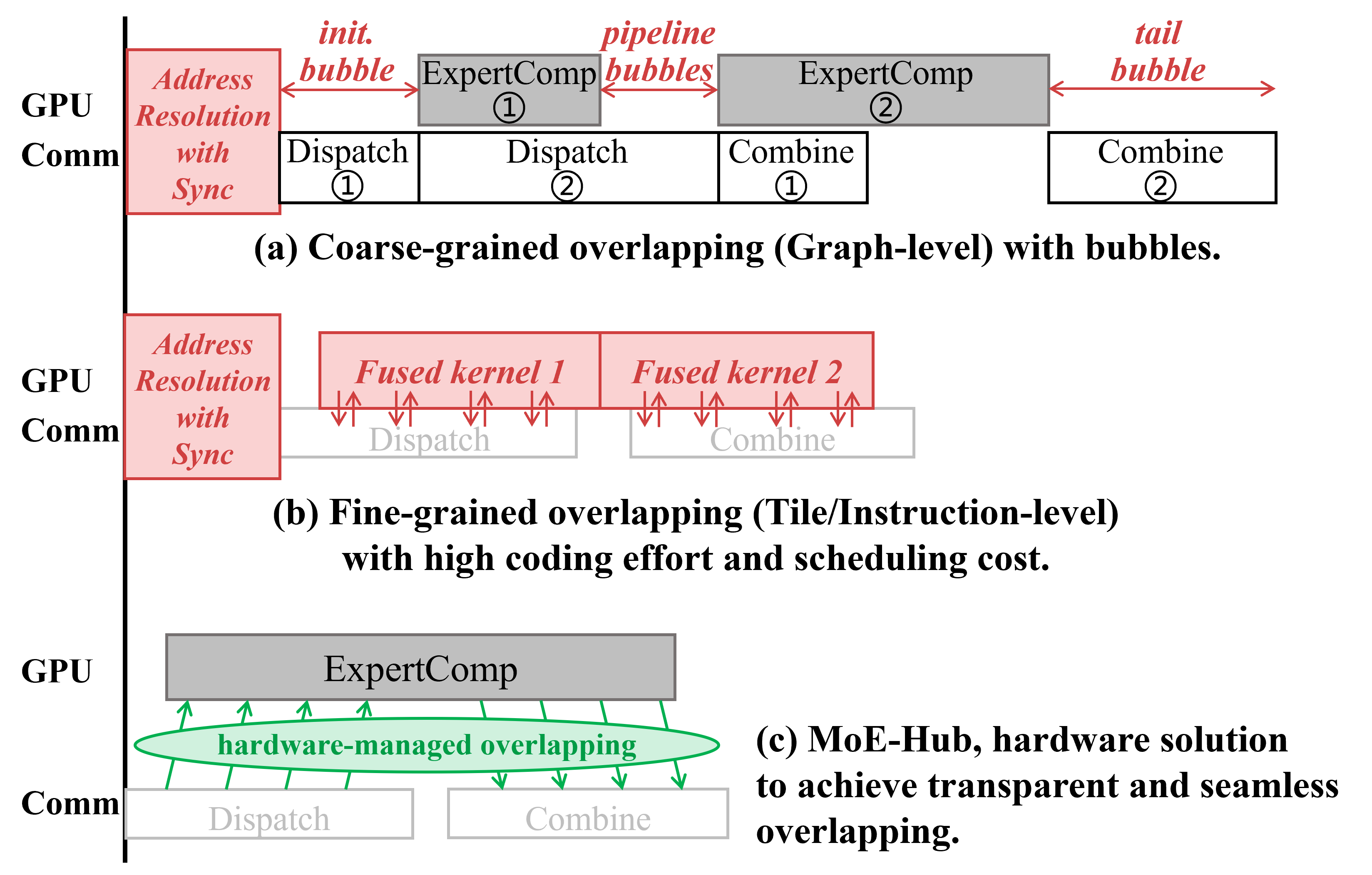
Figure 1: Comparison of computation-communication overlap strategies in MoE systems.
Architectural Insights and Design Philosophy
MoE-Hub identifies two pathological sources of inefficiency in prevailing systems:
- Producer-Consumer Abstraction Mismatch: The MoE algorithm determines expert assignment per token, but not its memory address within the expert input buffer. GPUs require explicit memory addresses for remote stores, compelling complex software synchronization and address resolution before communication.
- Inefficient Fine-Grained Data Management: The out-of-order, fragmented packet streams resulting from MoE’s dynamic routing degrade link utilization and induce producer/consumer stalls. Software cannot efficiently orchestrate these fine-grained flows, leading to polling overheads and resource underutilization (Figures 5, 6).
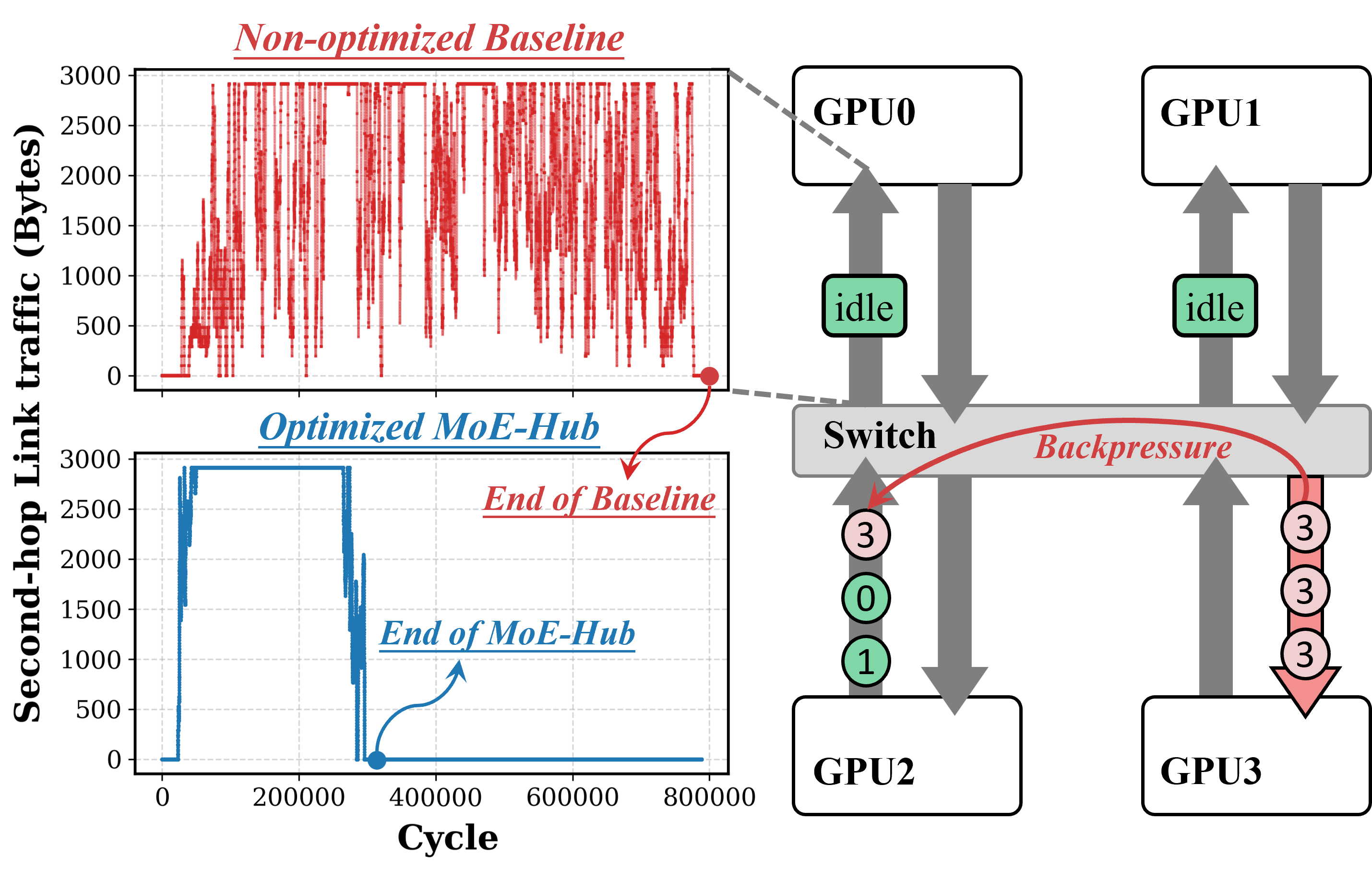
Figure 2: MoE’s dynamic, irregular routing often causes traffic bursts and congestion, degrading bandwidth utilization.
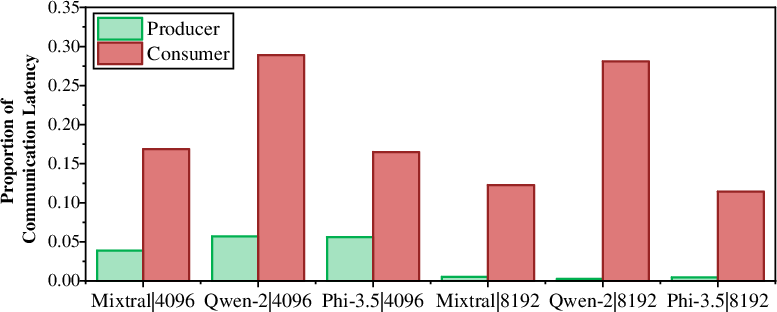
Figure 3: Proportion of communication latency on both producer and consumer sides of dispatch phase.
MoE-Hub’s design philosophy is to offload the control plane of communication to hardware, introducing a destination-agnostic paradigm: producers transmit packets tagged only with logical destination (expert ID), and the hardware hub resolves addresses dynamically on arrival. This eliminates the software-address mediation phase and enables immediate, fine-grained overlap.
Design and Implementation
Core Architectural Modules
MoE-Hub integrates three pivotal hardware modules in the GPU hub:
- Address Allocation Unit (AAU): Translates (ExpertID, RowID) tuples from incoming packets into real memory addresses, enforcing dense packing and avoiding CPU-level address resolution.
- Runtime Packet Manager (RPM): Buffers and coalesces outgoing packets per destination, merging fragmented requests into interconnect-friendly bursts, scheduling transmission with congestion- and consumer-aware policies (Figure 4).
- Data Availability Manager (DAM): Tracks memory-level dependencies and triggers consumer thread block scheduling as soon as required data arrives, obviating software polling (Figure 5).
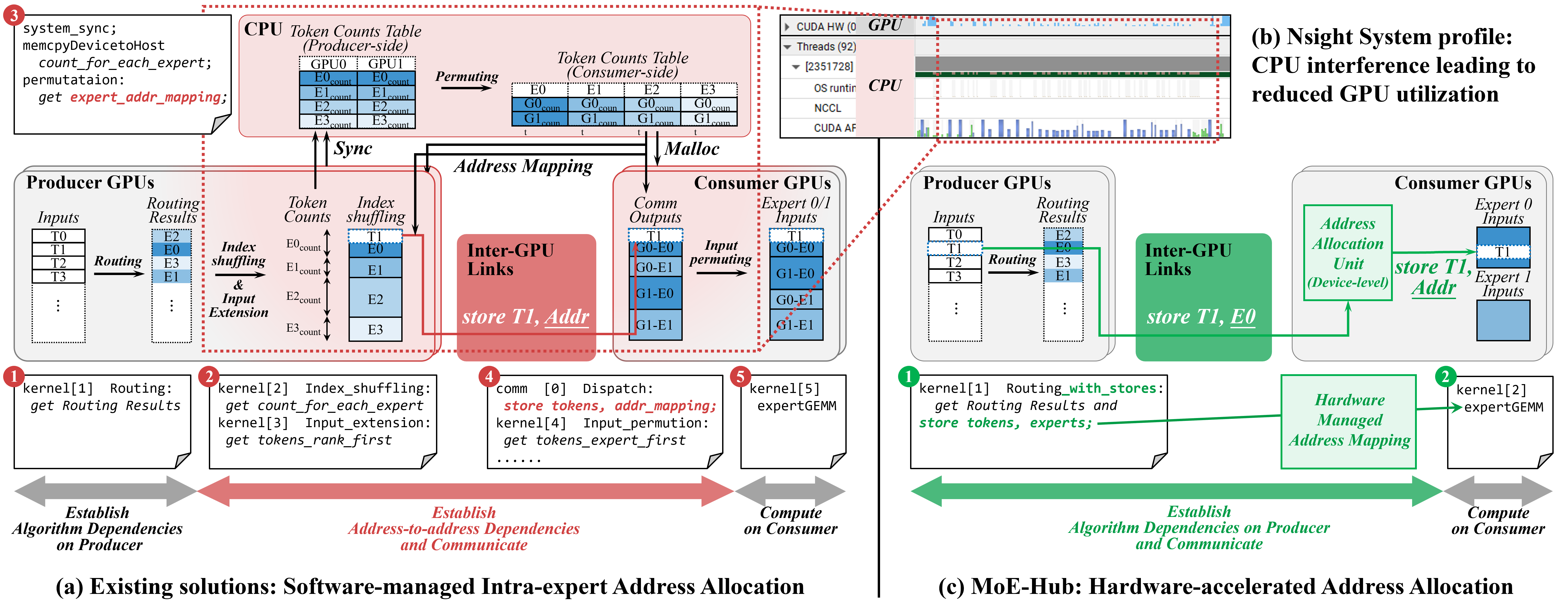
Figure 6: From software-mediated address resolution (a, b) to hardware method (c), MoE-Hub eliminates heavy software overheads.
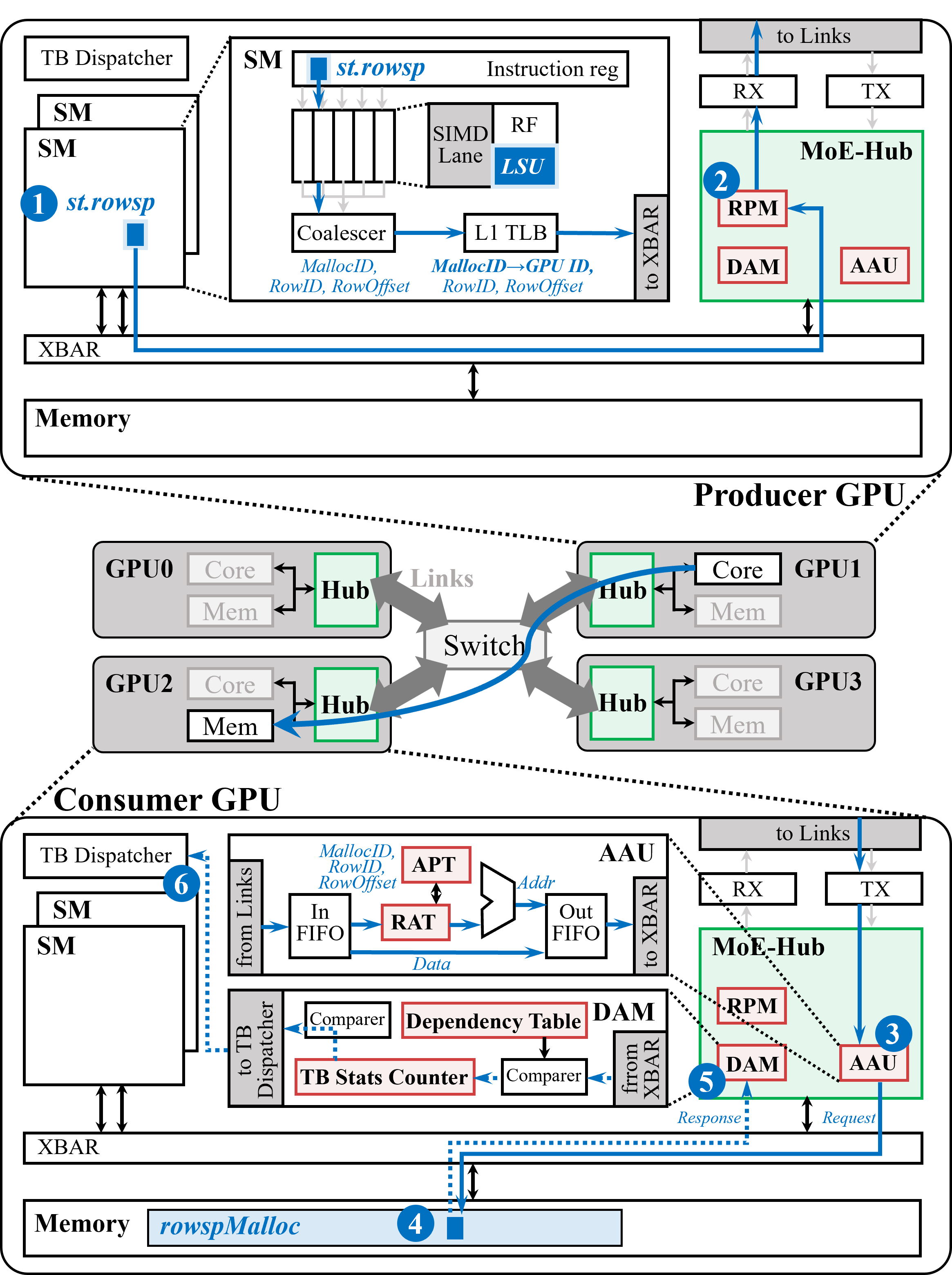
Figure 7: MoE-Hub overview: hub-side extensions and datapath integration.
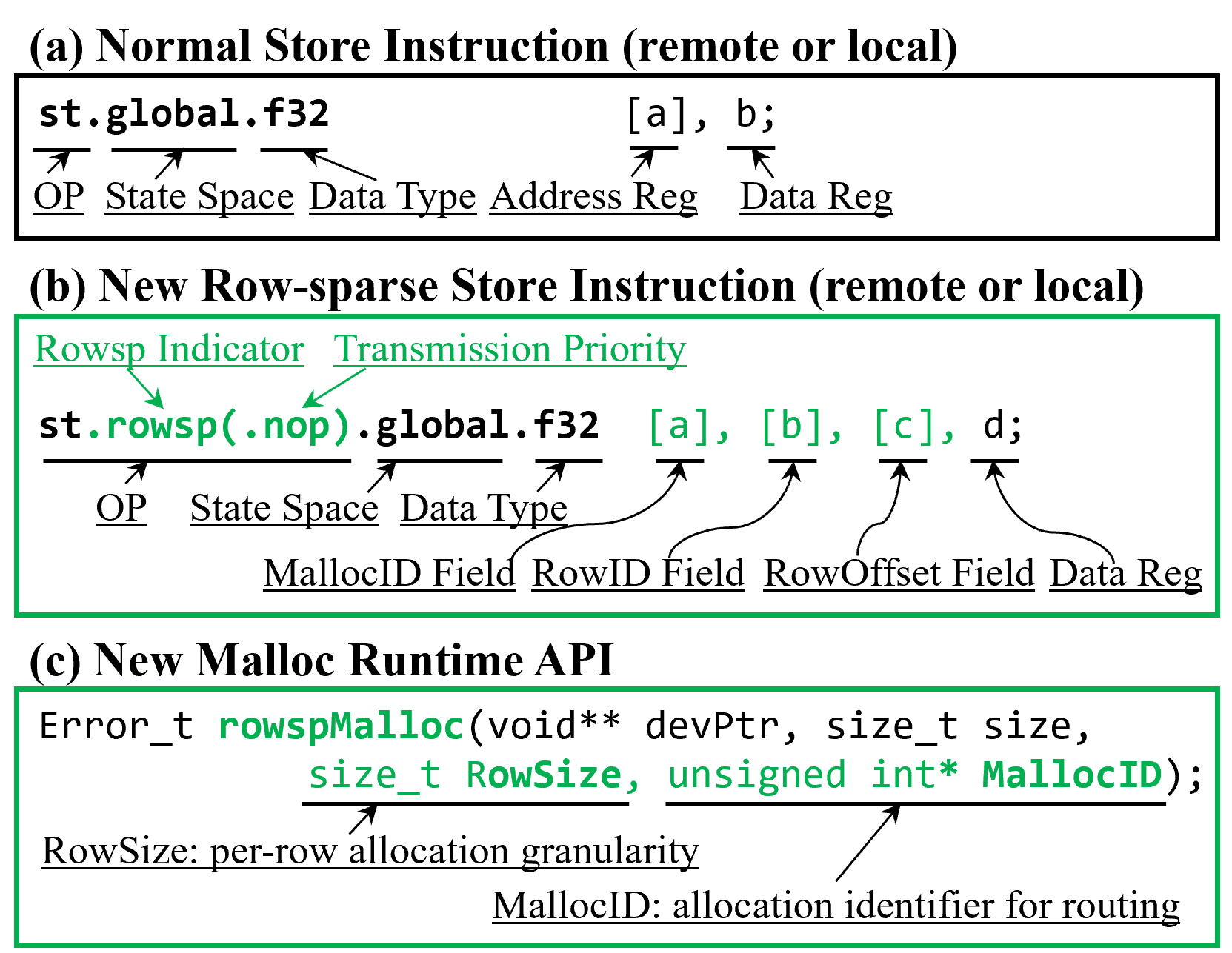
Figure 8: ISA and runtime API extensions.
ISA extensions (st.rowsp instruction and rowspMalloc API) abstract away explicit addresses, allowing logical destination-tagged communication. Hardware modules in the hub guarantee parallel address allocation, traffic management, and event-triggered kernel launches.
Communication Paradigm and Dataflow
The producer issues st.rowsp instructions as soon as routing results are obtained, specifying logical destination only. Packets are merged and scheduled in RPM, sent over NVLink, and resolved by the AAU on the consumer side. DAM monitors packet arrivals and triggers kernel execution based on data readiness (Figure 9, Figure 4, Figure 5).
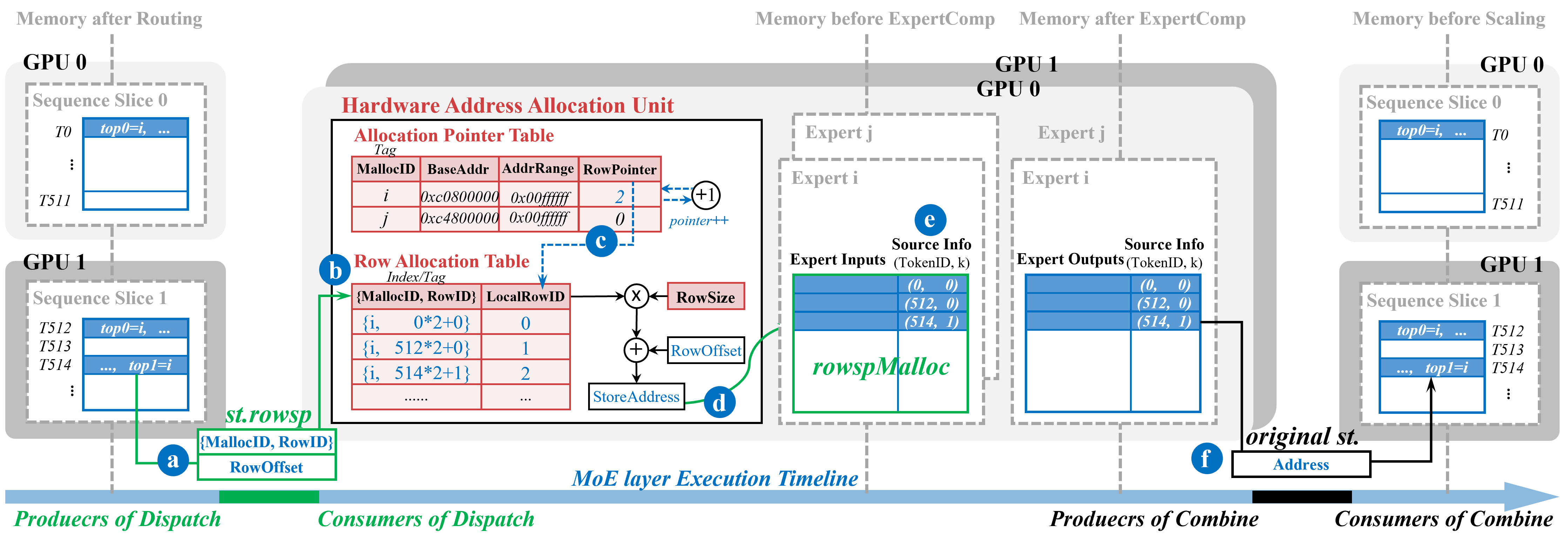
Figure 9: Illustration of MoE layer dataflow under the destination-agnostic communication paradigm.
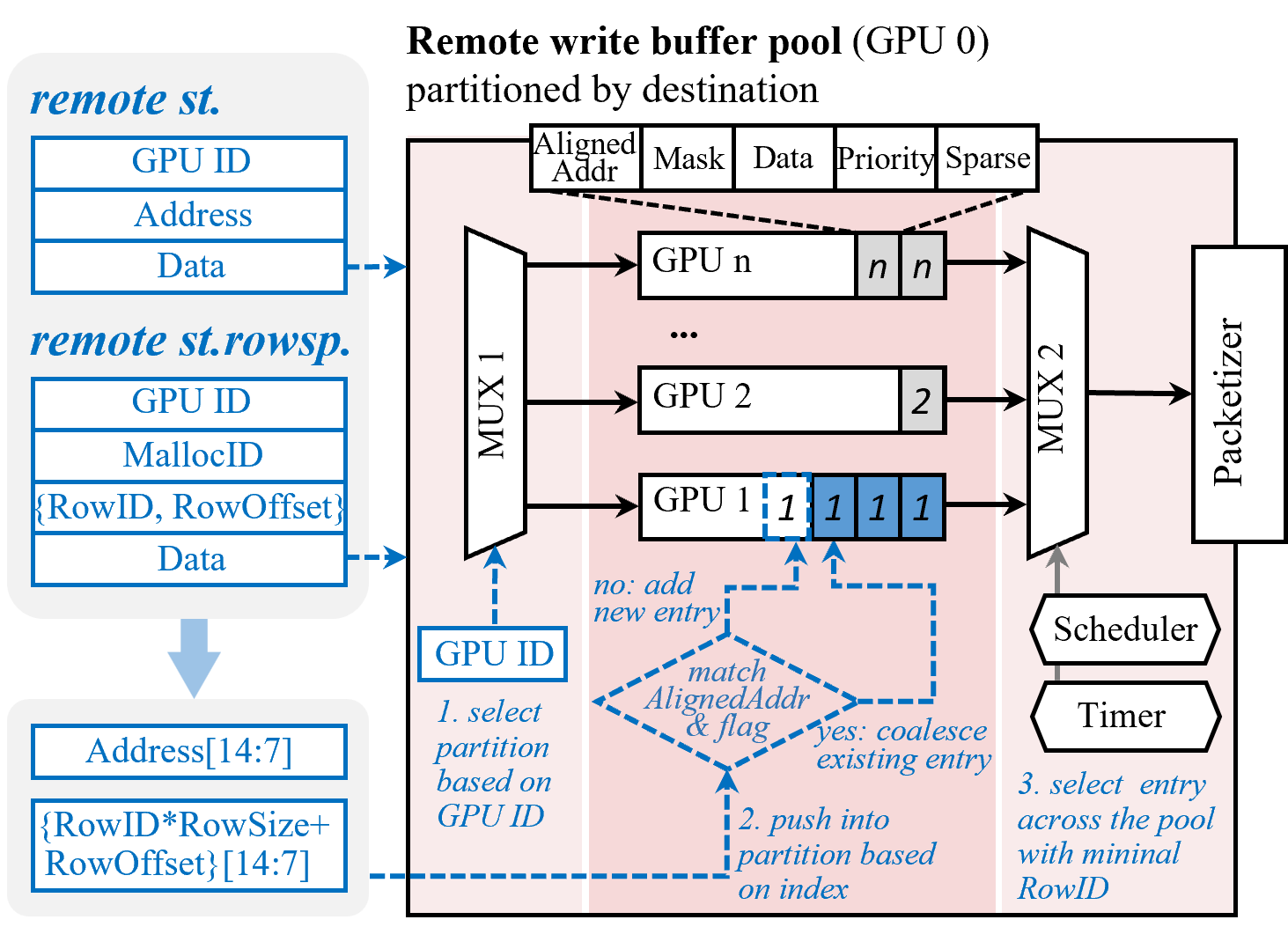
Figure 4: Runtime Packet Manager microarchitecture.
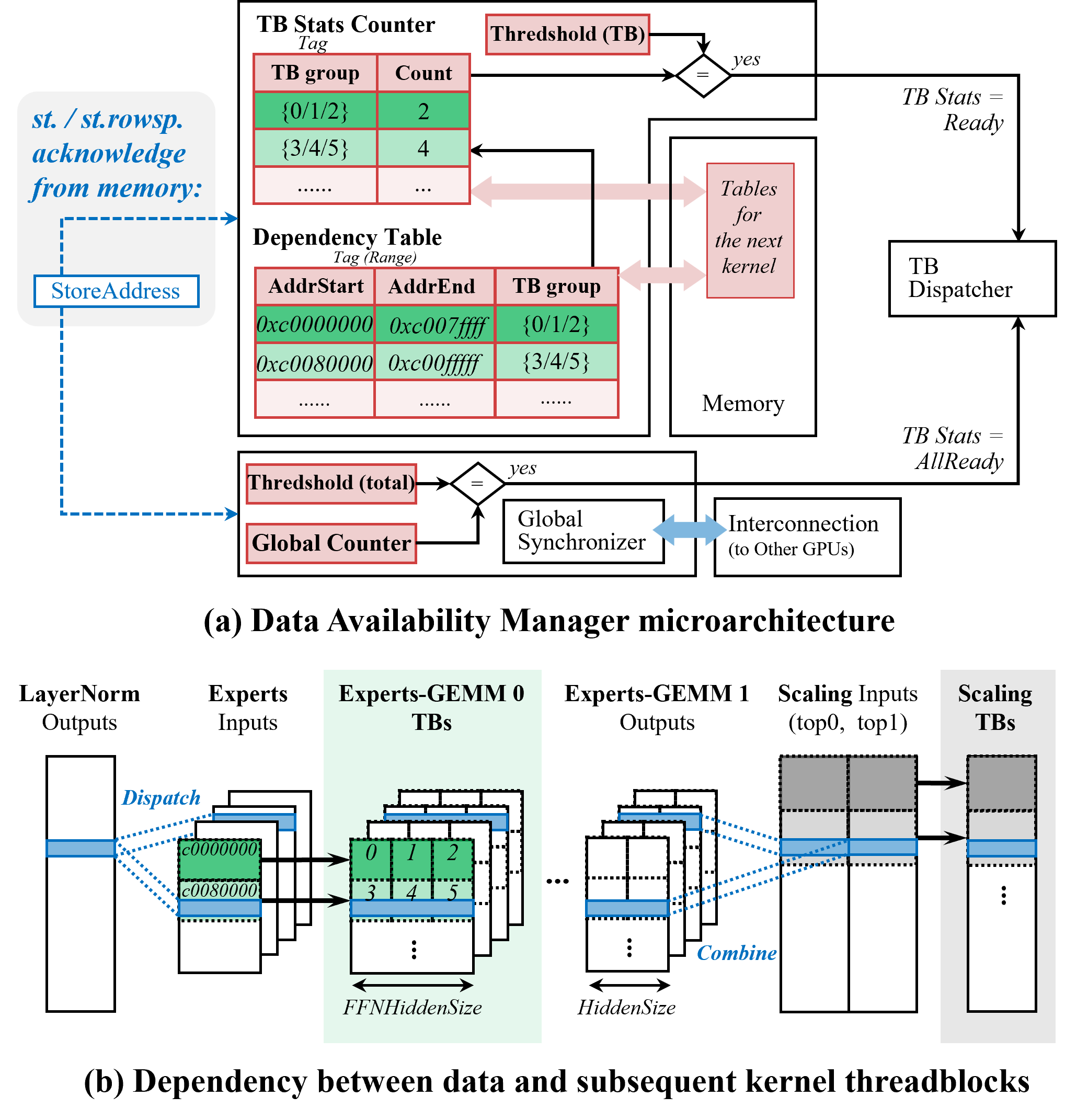
Figure 5: Data Availability Manager microarchitecture and its role in managing dependencies between data and threadblocks.
Algorithmic Workflow
The end-to-end MoE layer execution on MoE-Hub proceeds as follows:
- Routing: Tokens routed locally.
- All-to-All Dispatch: Immediate packet emission, tagged with expert IDs.
- Expert Computation: Launched upon partial or full packet arrival.
- All-to-All Combine: Reverse communication, handled similarly.
- Scaling: Outputs aggregated.
Experimental Results
Evaluated using cycle-accurate multi-GPU simulation and scaled MoE workloads (Mixtral-8×7B, Qwen2-MoE-2.7B, Phi-3.5-MoE), MoE-Hub achieves strong numerical results:
- Per-layer speedup: 1.40×–3.08× over state-of-the-art (SOTA) baselines.
- End-to-end speedup: 1.21×–1.98× over SOTA (Megatron-TE, Comet, Tutel, FasterMoE, CCFuser).
- Latency gap to ideal: MoE-Hub closes 96.8% of the gap to theoretical optimum, with negligible address mediation and scheduling overheads.
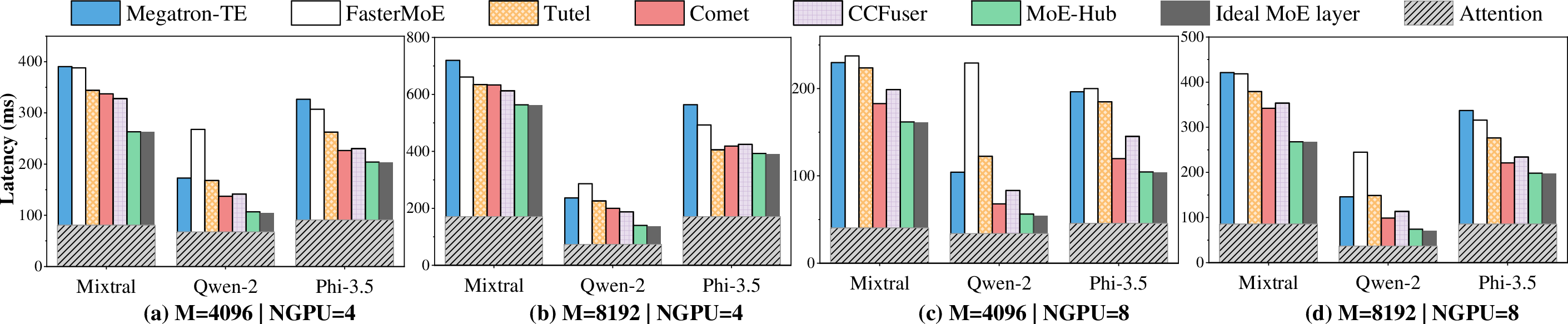
Figure 10: End-to-end latency evaluation. Total token count is M=SeqLength×NGPU, where NGPU is the number of devices.
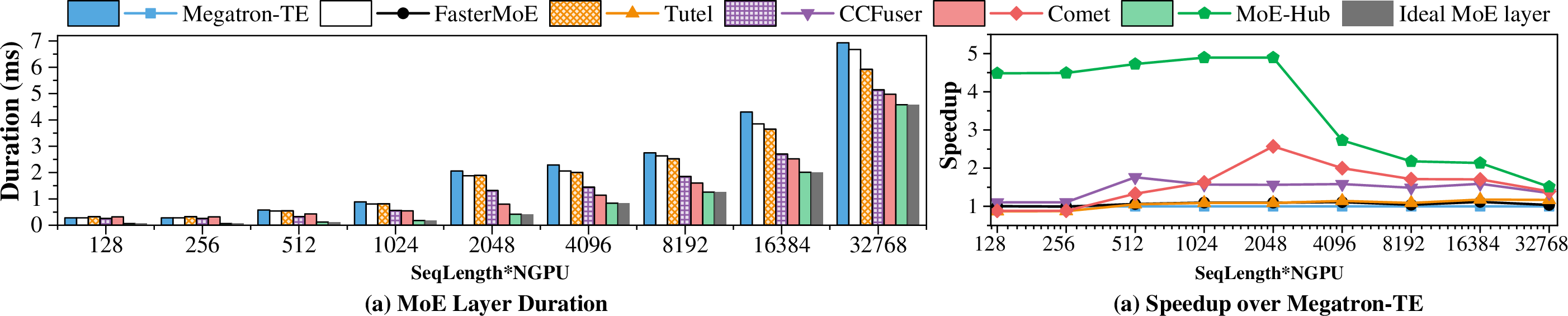
Figure 11: Layer duration and speedup with varying total token count on 8 GPUs. Other parameters follow Mixtral 8×7B.
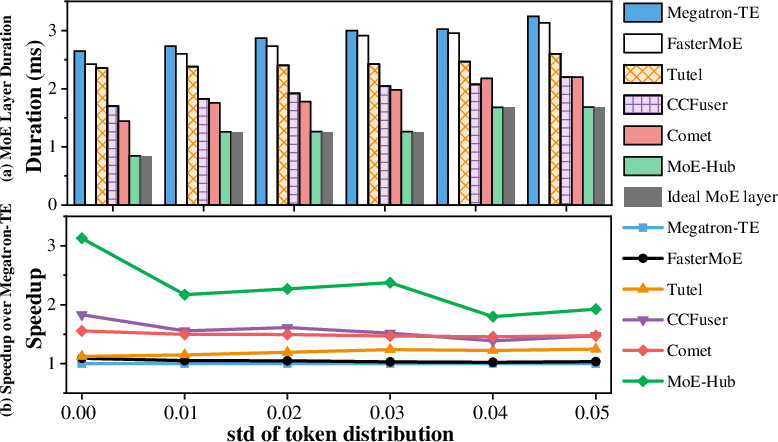
Figure 12: Layer duration and speedup with a total token count of 8192 on 8 GPUs. Other parameters follow Mixtral 8×7B.
- Ablation study: RPM and DAM independently contribute 13–14% speedup, and the full MoE-Hub design achieves 30–40% speedup.
- Robustness to token imbalance: Performance remains high even under highly irregular token-to-expert distributions.
- Scalability: Maintains near-linear throughput with increasing GPU counts (Figures 16, 17, 18).
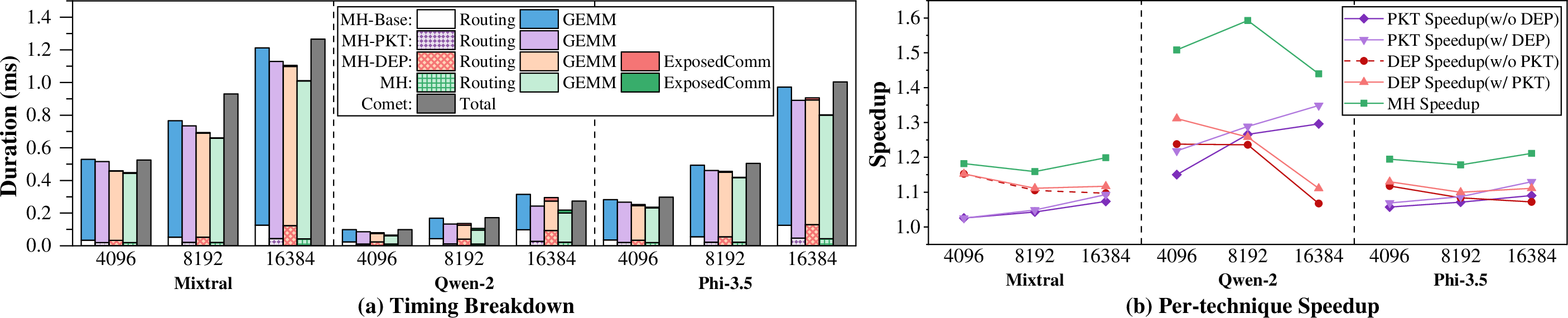
Figure 13: Comparison of four MoE-Hub variants with Comet from routing to expert GEMM1, and speedups achieved by Runtime Packet Management, Hardware Signaling, and the full design.
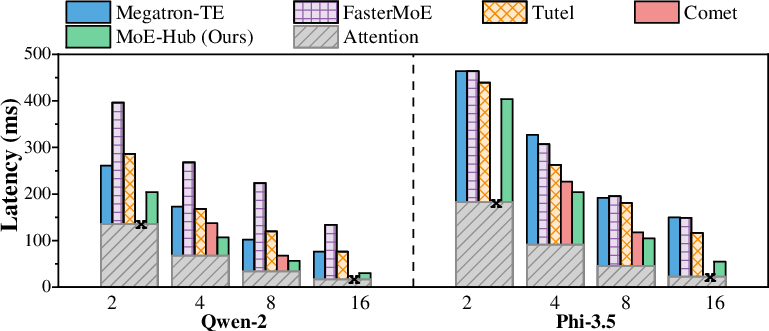
Figure 14: End-to-end latency evaluation on Qwen-2 and Phi-3.5 across 2–16 GPUs, with a total token count of 8192.
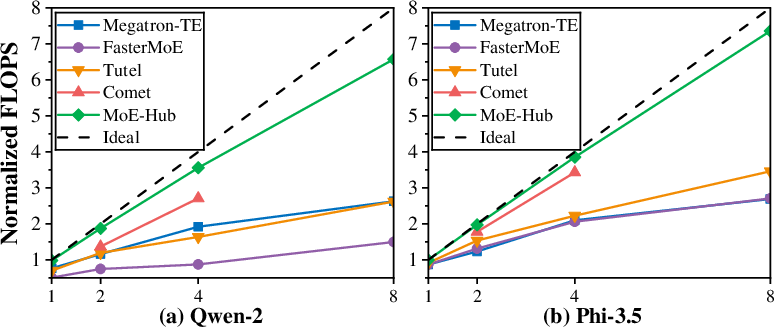
Figure 15: Normalized FLOPS for 1×, 2×, 4×, and 8× GPU scaling, with the dashed line indicating ideal FLOPS scaling.
- Hardware overhead: <0.06% die area (0.49 mm²), minimal integration cost.
Practical and Theoretical Implications
MoE-Hub’s hardware-native abstraction for destination-agnostic communication fundamentally redefines multi-GPU orchestration for sparse and dynamic workloads. It abolishes synchronization barriers and CPU involvement, dramatically reducing software complexity and porting costs. The abstraction enables immediate, asynchronous overlap of computation and communication, facilitating scalable distributed training and inference for MoE models.
MoE-Hub is compatible with advanced MoE scheduling strategies (load balancing, expert replication, hybrid EP/TP parallelism) and immediately extensible to dynamic, distributed attention and KV-cache exchange workloads, presaging next-generation AI scaling infrastructure.
Theoretically, the design sets a precedent for future AI accelerator interconnects: sparse, runtime-determined, destination-agnostic communication with hardware-managed orchestration.
Conclusion
MoE-Hub introduces a destination-agnostic, hardware-accelerated communication paradigm, resolving the intrinsic mismatch of MoE’s producer-consumer abstraction and enabling seamless fine-grained overlap in distributed MoE execution. With strong speedups over SOTA baselines and robust scalability, MoE-Hub provides an efficient, portable, and area-feasible solution for next-generation large-scale MoE models and related sparse workloads (2605.05888).

