- The paper introduces DySHARP, a framework that combines dynamic multimem addressing and token-centric kernel fusion to eliminate up to 50% redundant communication in MoE layers.
- The paper demonstrates that integrating in-switch computing with token-paced pipeline scheduling yields up to 1.79× speedup over state-of-the-art solutions on multi-GPU systems.
- The paper shows that the coordinated hardware and software co-design not only improves bandwidth utilization but also scales efficiently with increased GPUs and varied token distributions.
Accelerating Mixture-of-Experts with Dynamic In-Switch Computing
Motivation: Communication Redundancy in MoE Expert Parallelism
Mixture-of-Experts (MoE) architectures are adopted in large-scale models to manage compute and memory scaling by partitioning feed-forward networks into multiple experts activated selectively per token. With expert parallelism (EP), MoE distributes experts across GPUs, necessitating frequent inter-GPU communication for Dispatch (token routing) and Combine (aggregation). Profiling reveals these communication operations account for the majority of MoE layer execution time and exhibit significant redundant transfers—up to 50% of total traffic in commercial MoE models—primarily due to repeated transfer of identical or aggregatable data across GPUs.
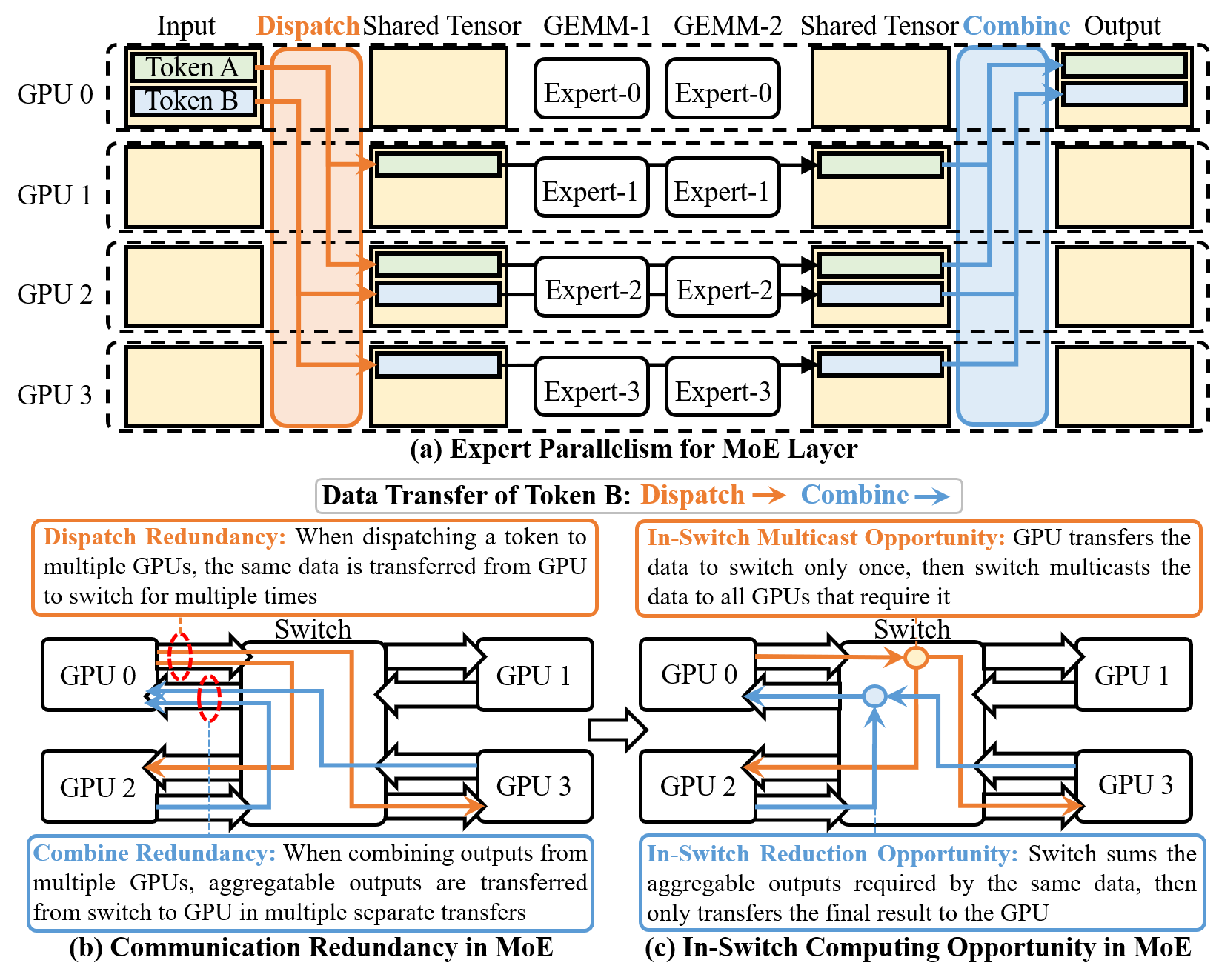
Figure 1: In-switch computing opportunity in MoE. Significant redundant transfer exists, addressable with in-switch computing.
Prior optimization libraries and computation-communication overlap schemes target latency amortization but do not fundamentally address this redundancy. While NVLink SHARP (NVLS) offers in-switch multicast and reduction for static collectives, the rigid target group and addressing model preclude its applicability to MoE’s dynamic, irregular expert activation patterns, resulting in severe inefficiencies when forced to emulate MoE communication with static collectives.
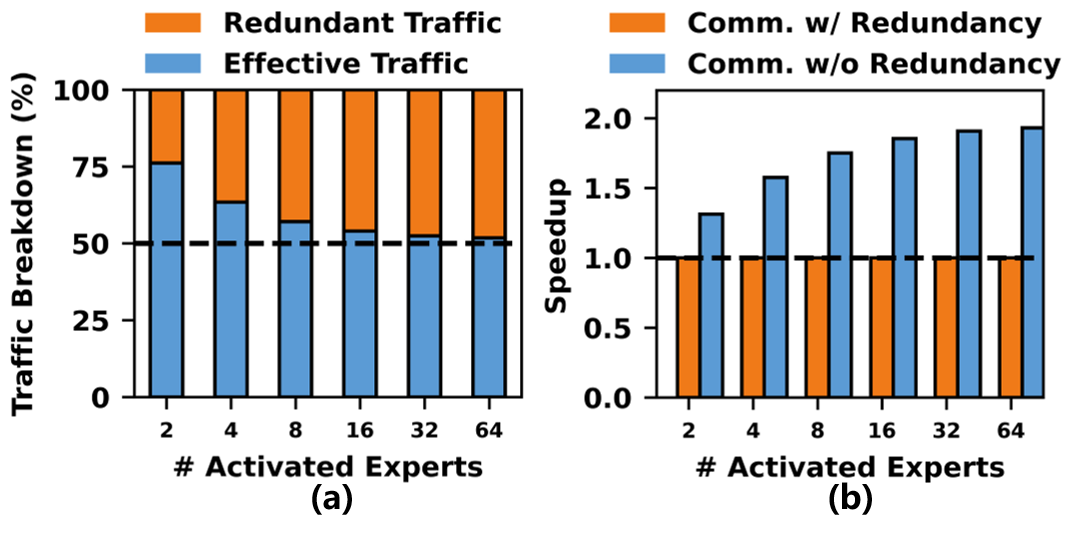
Figure 2: Quantification of redundant data transfer and acceleration opportunity. Up to 50% redundancy in MoE traffic in DeepSeek-V3.
DySHARP Framework: Integral Dynamic In-Switch Computing
DySHARP introduces full-stack support for dynamic in-switch computing in MoE, encompassing communication primitives with dynamic multimem addressing, and communication-aware scheduling using token-centric kernel fusion.
Dynamic Multimem Addressing
DySHARP enables efficient in-switch computing for irregular MoE communication by extending the multimem paradigm:
- Packet Format: Carries a single algebraic (multimem) address with a compact expert target list. This preserves near-ideal payload efficiency.
- ISA Extension: Instructions dymultimem.st (dynamic multicast) and dymultimem.ld_reduce (dynamic reduction) encode target lists and algebraic indices, delegating destination memory layout tracking to hardware managers.
- Microarchitecture: At the destination, a hardware manager maintains an algebraic-layout mapping table (AL Table) for each expert, ensuring dense local memory compaction and fast lookup via an AL TLB. Architectural changes are minimally intrusive, leveraging existing datapaths.
Explicit addressing, though supporting arbitrary irregularity, incurs prohibitive payload overhead and necessitates extensive software tracking of memory states, compared to DySHARP’s compact, hardware-managed approach.
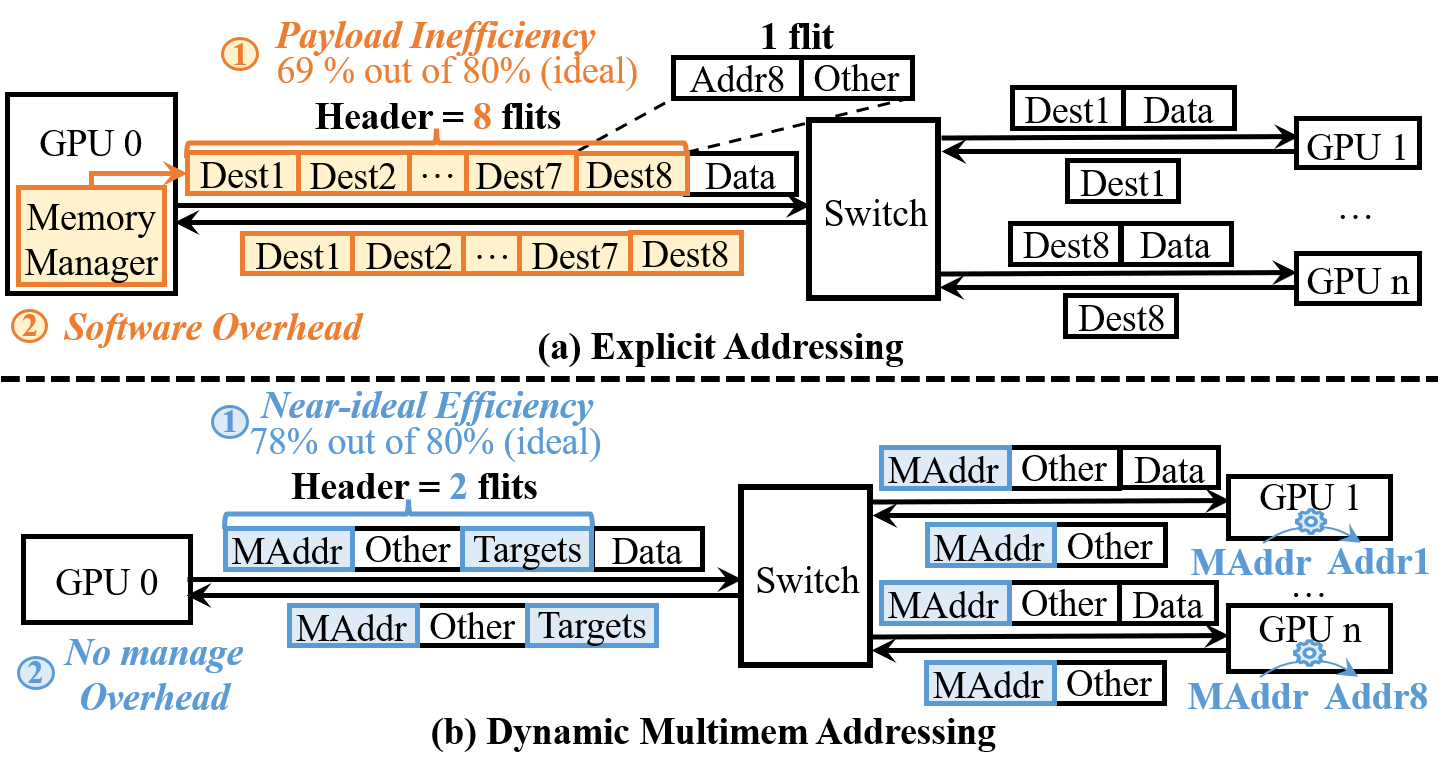
Figure 3: Dynamic multimem addressing achieves near-ideal payload efficiency and zero software overhead versus explicit addressing.
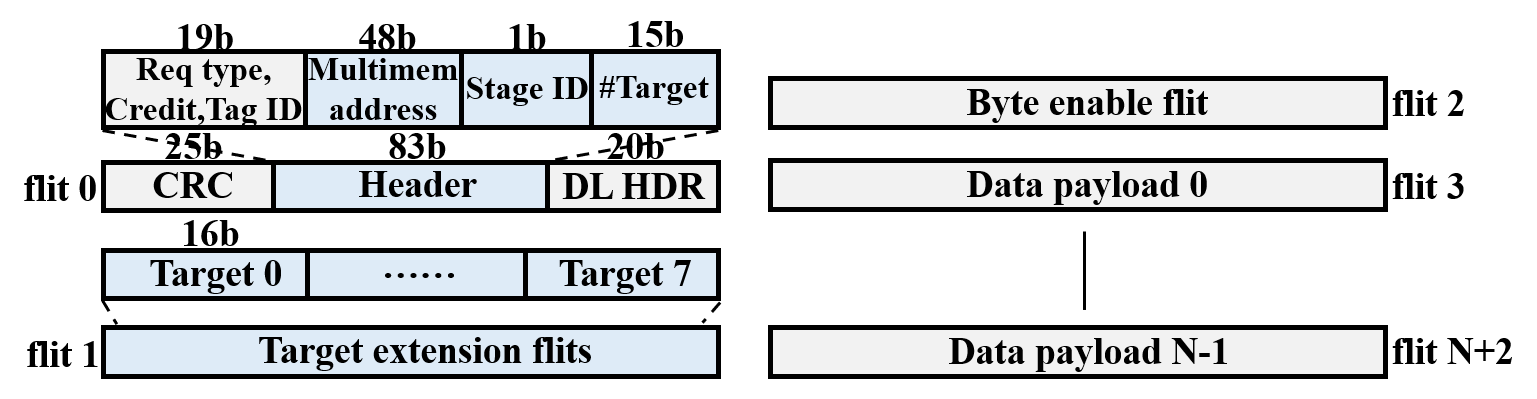
Figure 4: DySHARP’s extended NVLink packet format. Packet has a single multimem address and a lightweight target list.

Figure 5: ISA extension for dynamic multimem addressing. Dymultimem instructions add registers for target list specification.
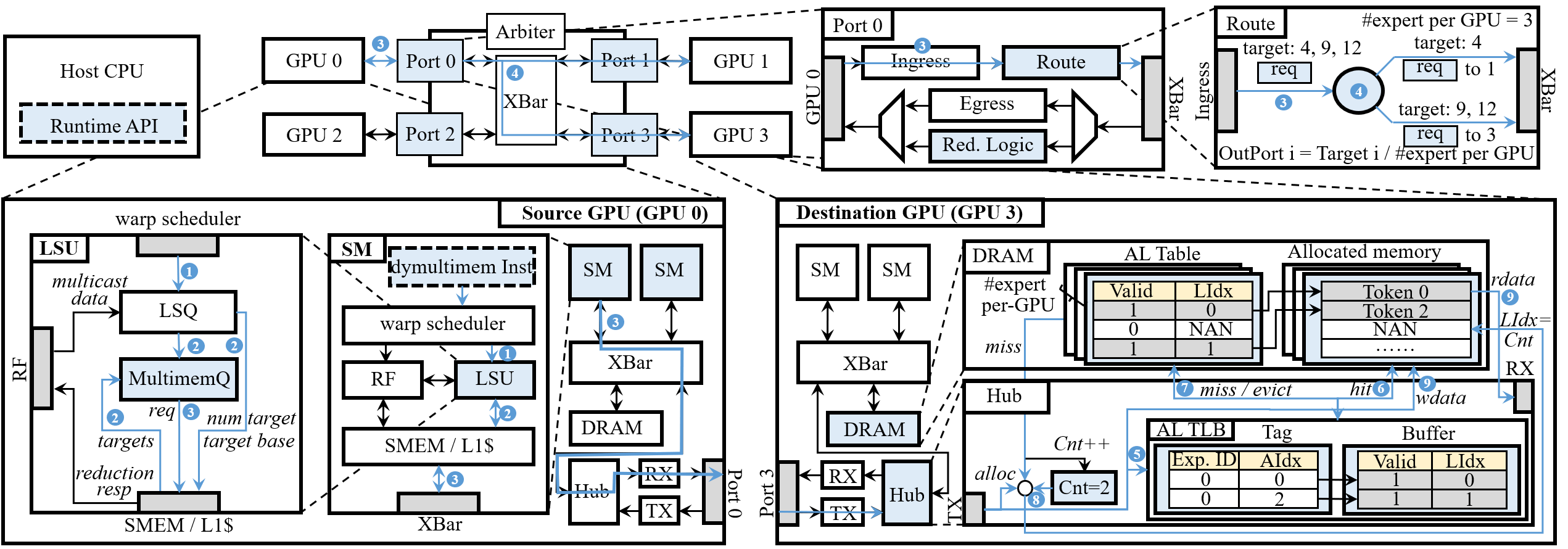
Figure 6: Architectural design and workflow for dynamic multimem addressing in GPUs and switches.
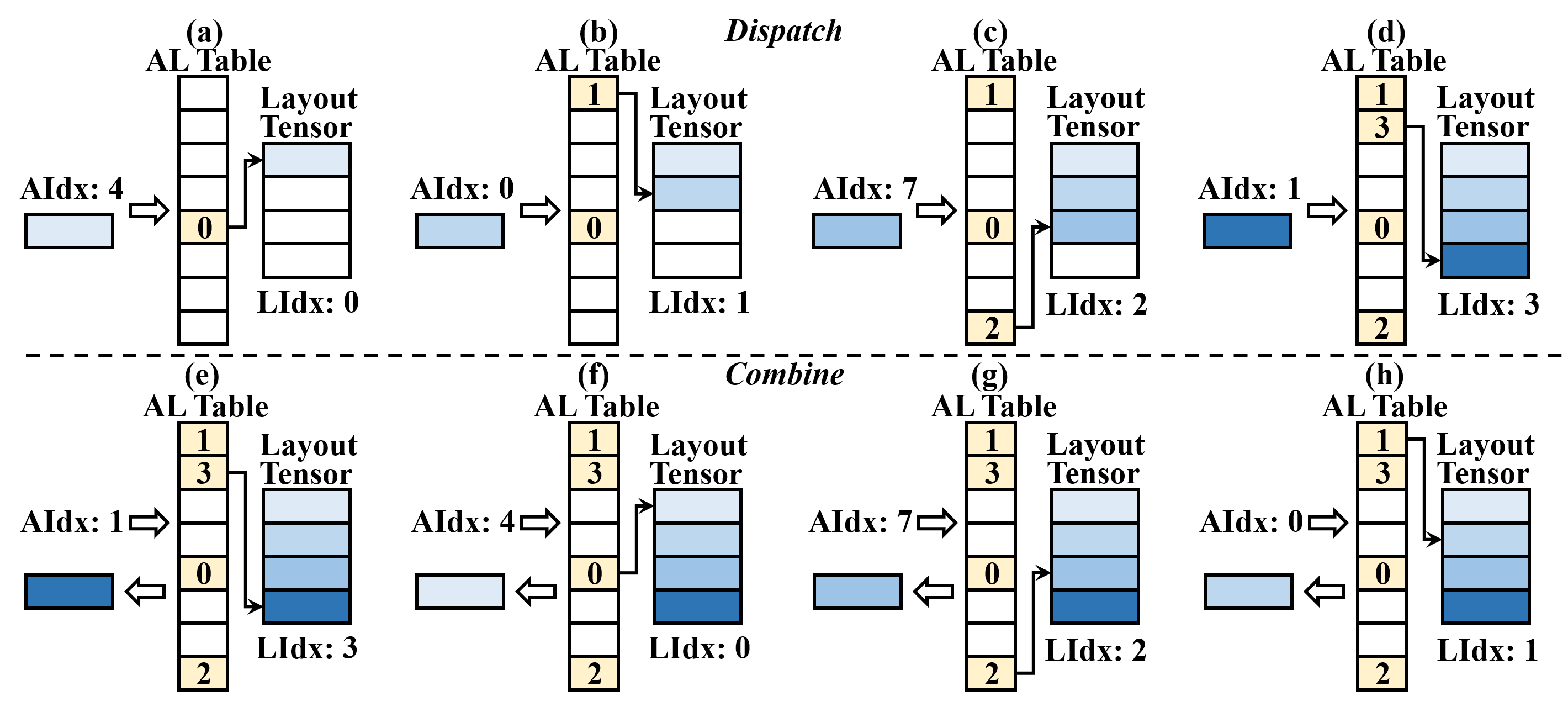
Figure 7: Hardware memory manager workflow: dynamic allocation of dense memory layout and reuse of algebraic-layout mapping.
Token-Centric Kernel Fusion
Combining Dispatch and Combine communication independently creates asymmetric traffic reductions that do not translate to speedup due to bandwidth imbalances. DySHARP implements token-centric kernel fusion, pipelining the MoE layer at token/tile granularity:
- Token Tracker: Tracks fine-grained readiness chains across Dispatch, GEMM-1, GEMM-2, and Combine via lightweight table structures.
- Scheduler: Implements a token-paced pipeline using persistent thread blocks, concurrent execution, and readiness-gated scheduling, merging complementary asymmetric communication patterns for improved bandwidth utilization.
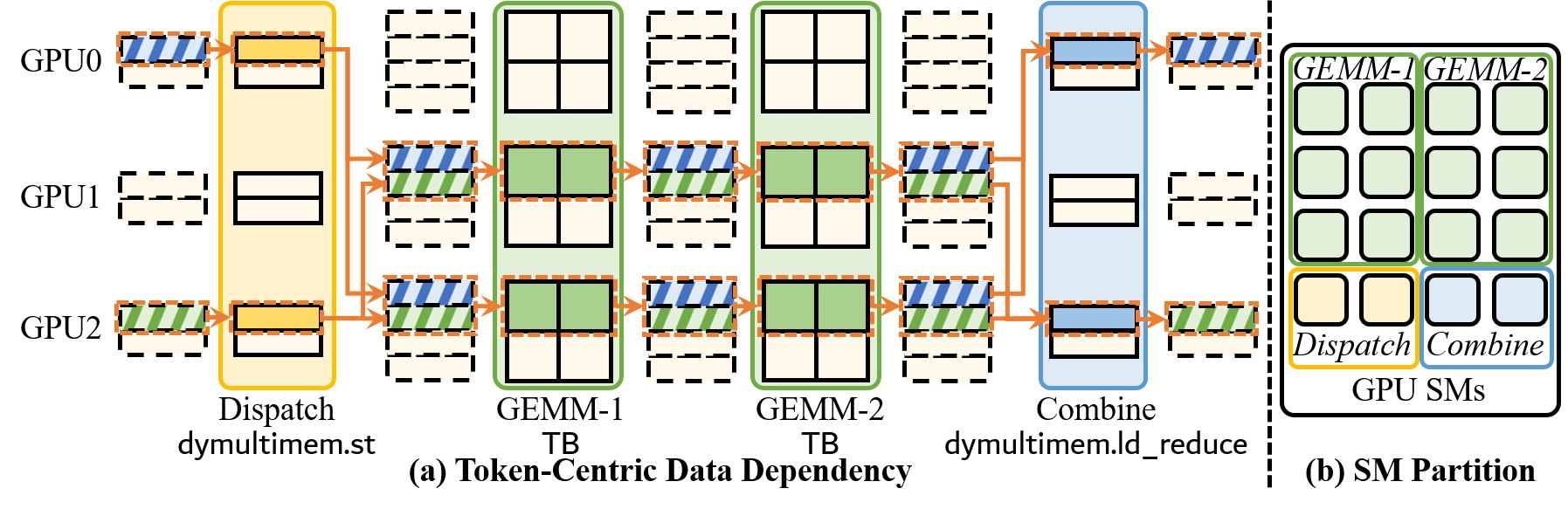
Figure 8: Token-level data dependency chain and SM partition for pipelined execution.
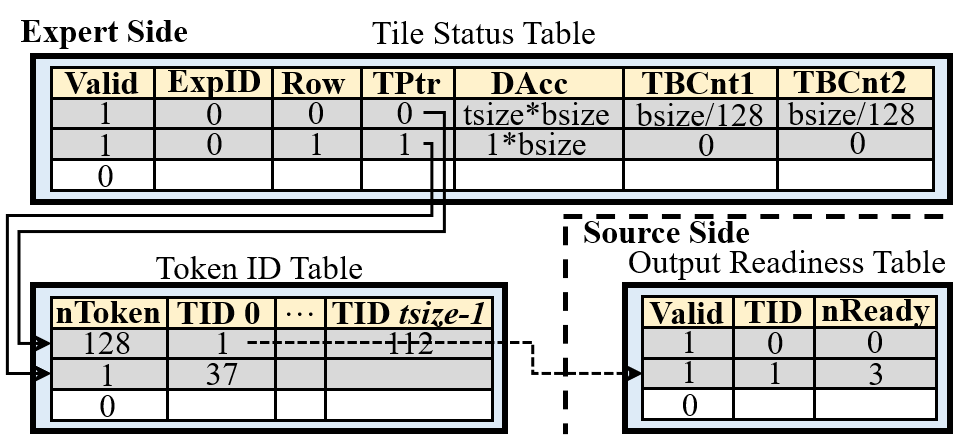
Figure 9: Token tracker architecture, enabling token-wise readiness tracking for pipeline activation.
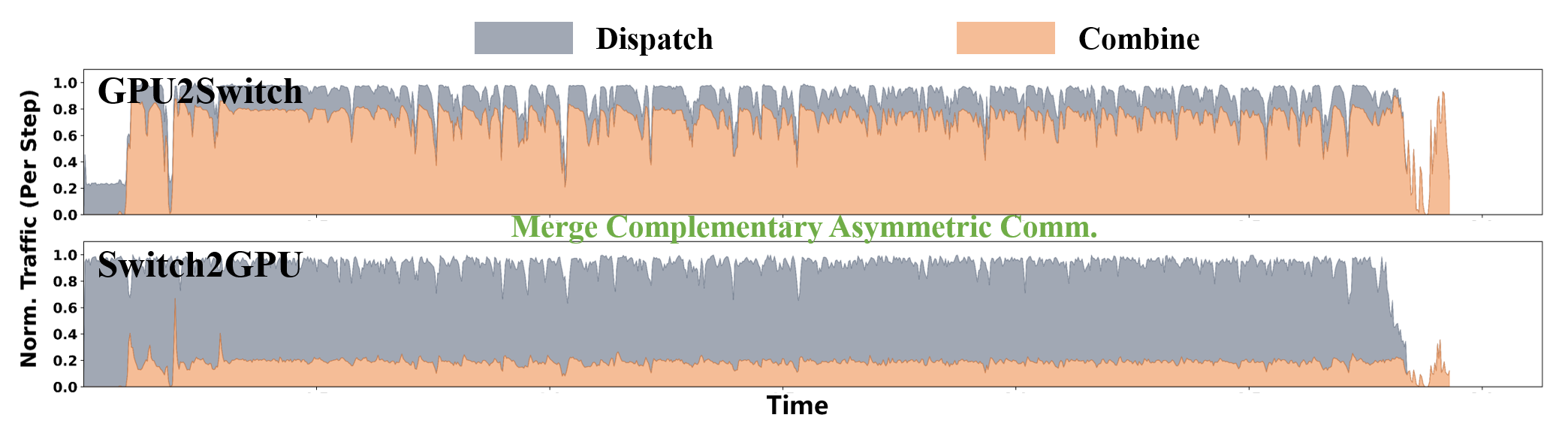
Figure 10: Merging complementary asymmetric communication transforms traffic reduction into speedup.
DySHARP achieves substantial speedups—up to 1.79× for MoE layers (geometric mean)—over the state-of-the-art COMET overlap solution and up to 6.93× versus NVLS, primarily through redundancy elimination with dynamic multicast and reduction and pipeline concurrency.
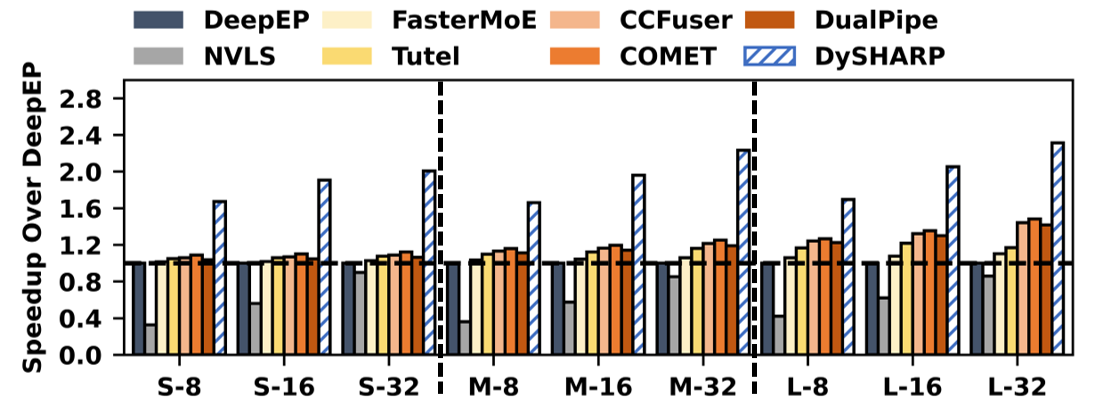
Figure 11: End-to-end model training speedup across configurations.
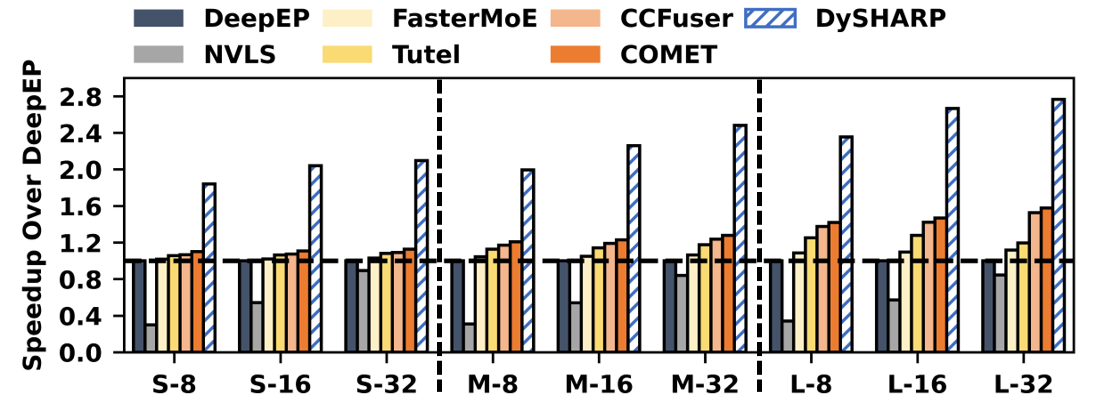
Figure 12: MoE layer speedup across model configurations.
Ablation studies reveal that neither dynamic multimem addressing nor token-centric kernel fusion alone suffice: only their integration translates traffic reduction into execution speedup.
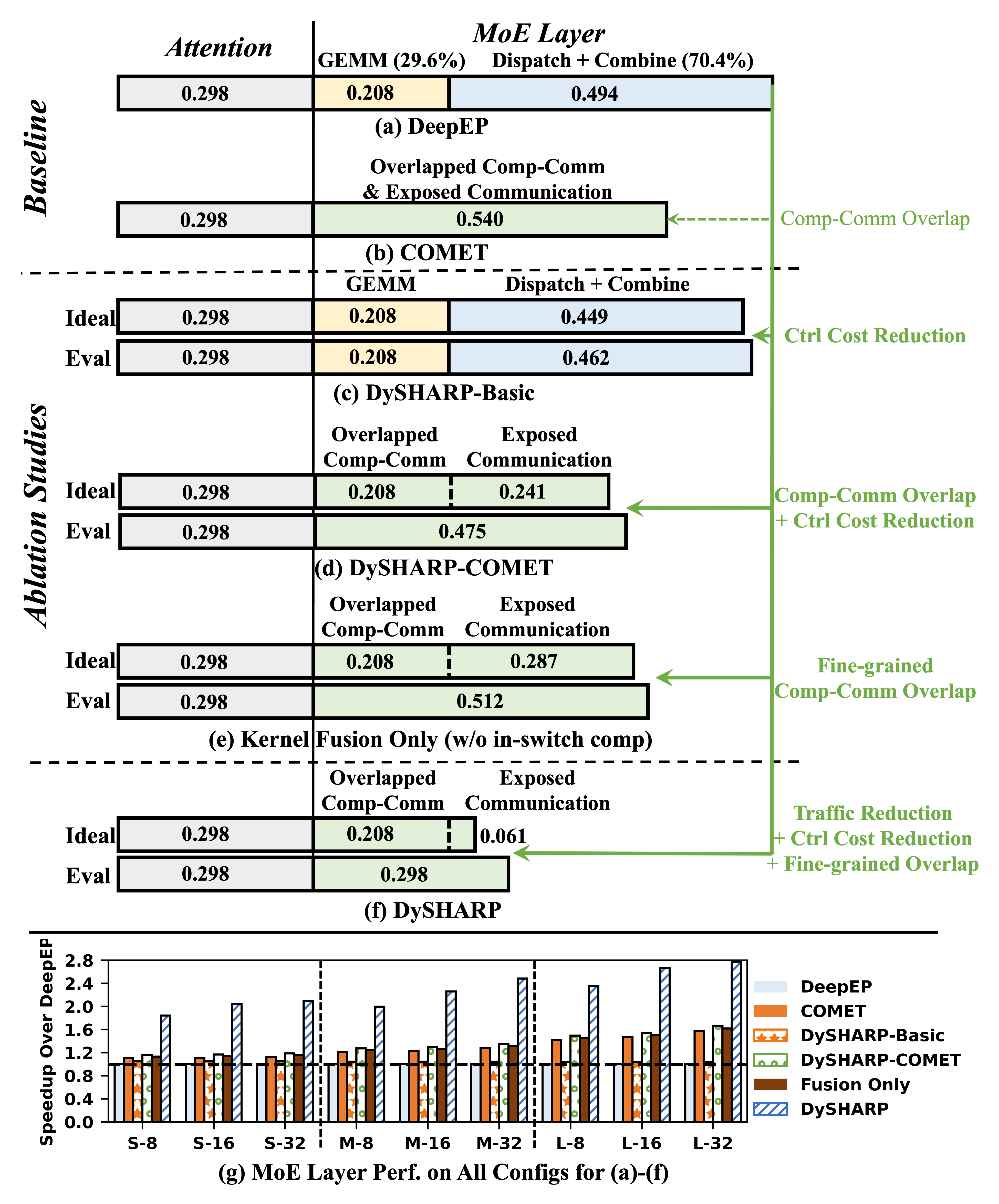
Figure 13: Time breakdown and ablations validate the interplay of traffic reduction and fusion for speedup.
DySHARP reduces communication traffic by nearly 50% compared to DeepEP. It achieves over 90% efficiency relative to the ideal communication performance and maintains high payload efficiency versus explicit addressing.
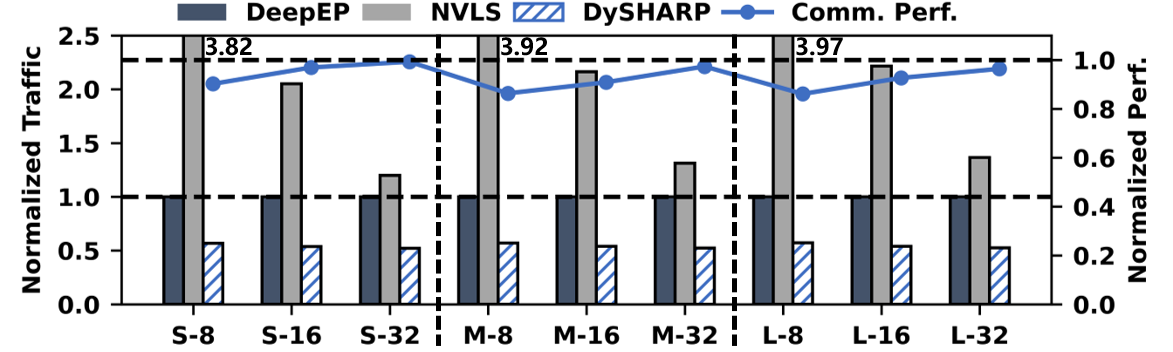
Figure 14: Traffic volume reduction and DySHARP communication capacity.
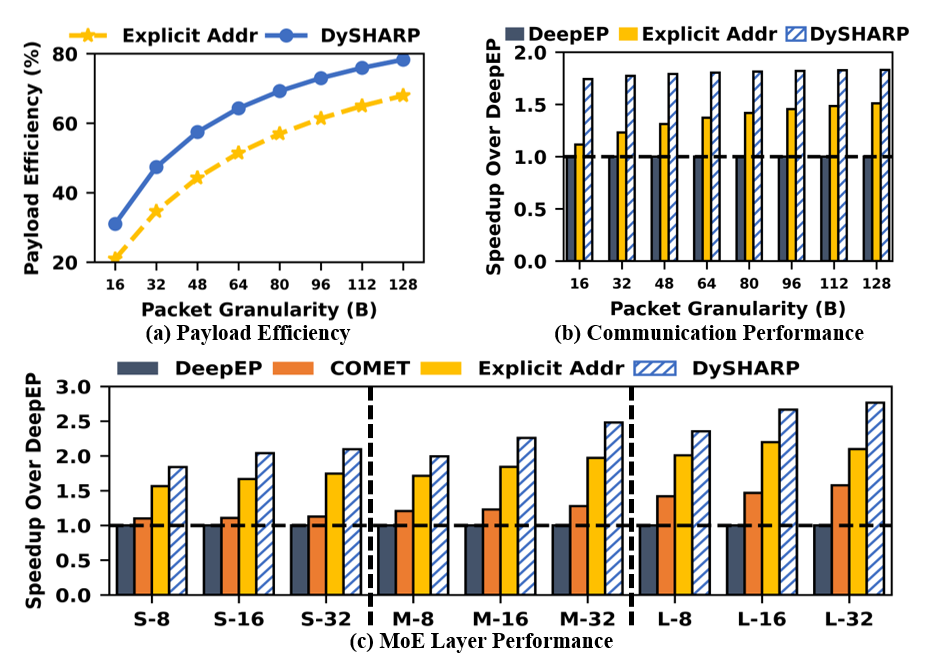
Figure 15: DySHARP vs. explicit addressing. Superior payload efficiency and MoE-layer performance.
Bandwidth utilization is substantially improved by the token-centric fusion, surpassing both non-overlap and overlap-only schemes.
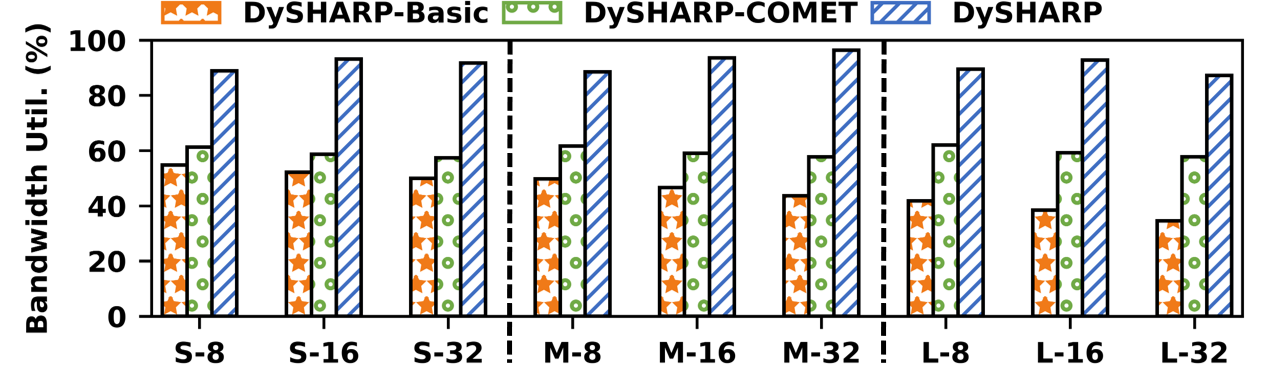
Figure 16: Bandwidth utilization comparison; fusion improves over all baseline overlap solutions.
Performance scales with number of GPUs, sequence length, and token distribution, demonstrating robust applicability.
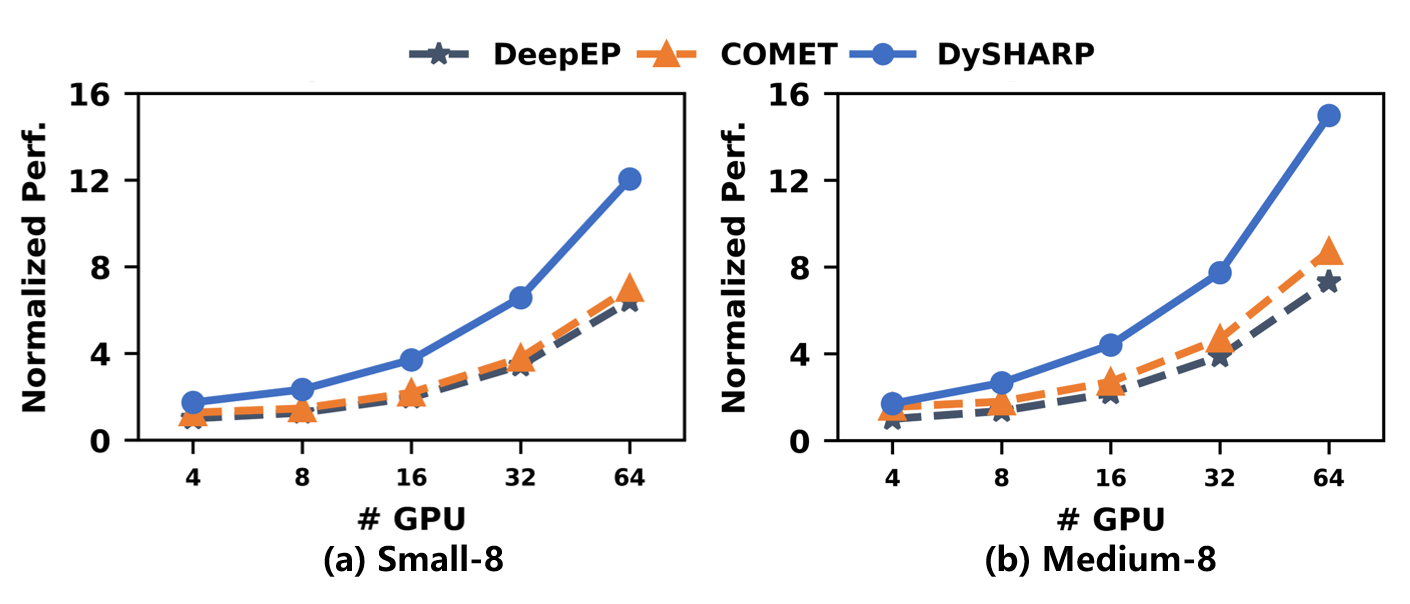
Figure 17: Performance sensitivity to number of GPUs.
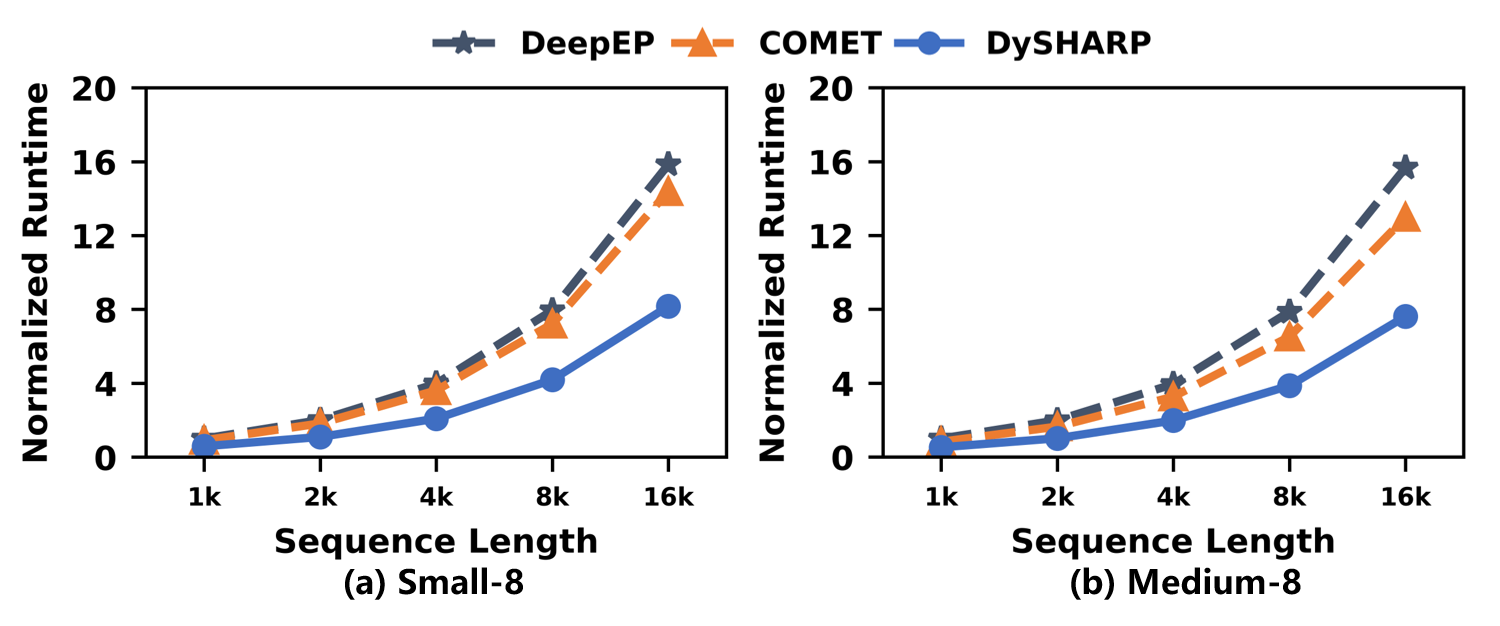
Figure 18: Performance sensitivity to sequence length.
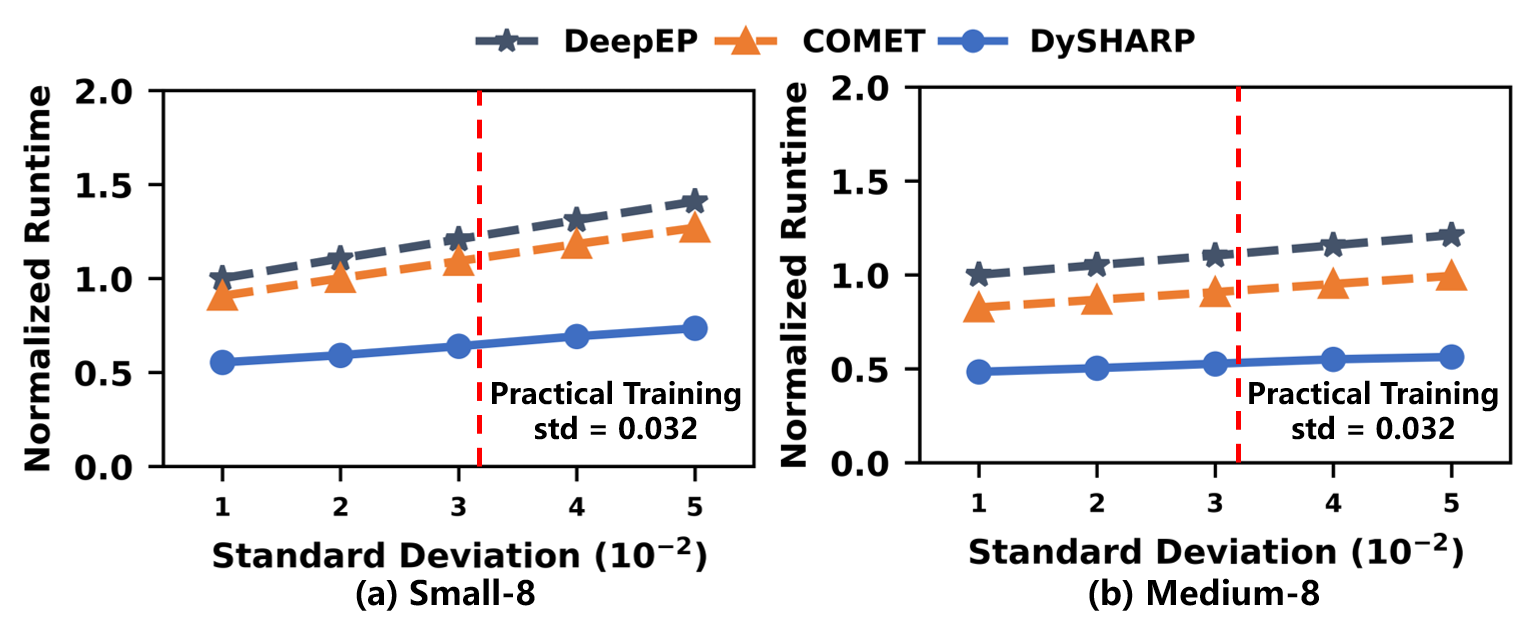
Figure 19: Performance sensitivity to token distribution in training.
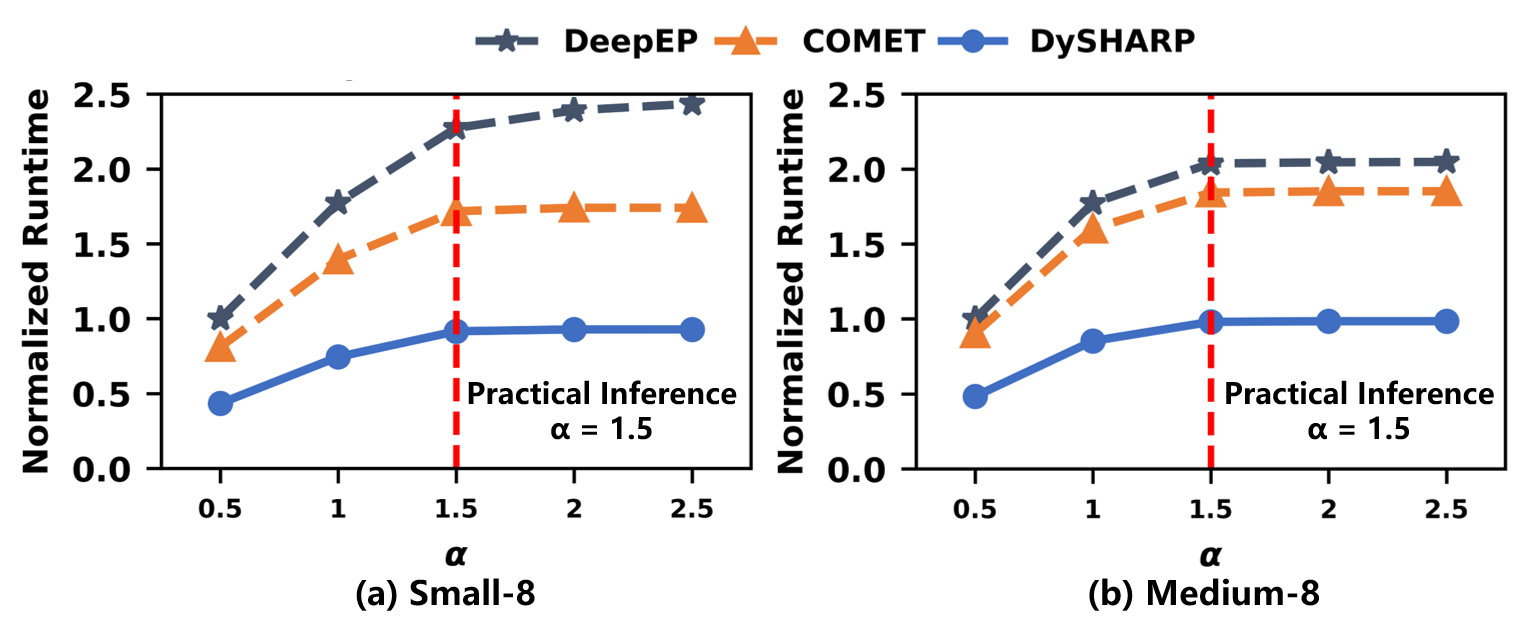
Figure 20: Performance sensitivity to token distribution in inference.
Hardware Overhead and Design Space
DySHARP’s hardware supports incur negligible area overhead (<0.024% of H100 die; <0.1% NVSwitch die). AL-TLB and reduction buffer sizing are explored; 512 AL-TLB entries and 64KB reduction buffer provide near-optimal hit rates with minimal overhead.
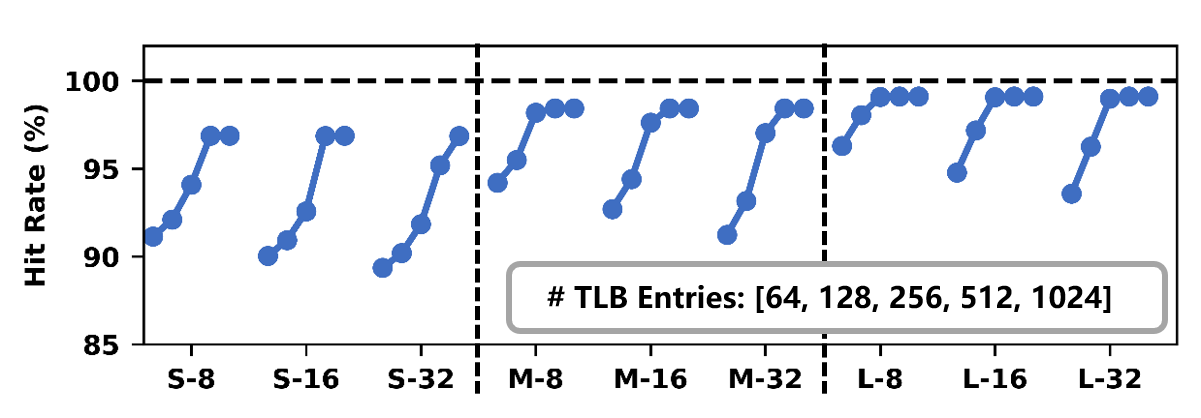
Figure 21: AL-TLB design space exploration finds 512-entry optimum.
Discussion and Extensions
DySHARP generalizes to inference workloads, where fine-grained synchronization and reduced software overhead reduce latency. It delivers superior performance for diverse MoE models (GPT-OSS, Qwen3) and other platforms (DGX-H100, NVL32).
(Figure 22)
Figure 22: End-to-end inference speedup with DySHARP.
Tile size for kernel fusion is tuned (128 matches GEMM tile size), balancing computation utilization and overlap granularity.
Extensions to multi-node systems using InfiniBand with Quantum Switch are feasible, abstracting the cluster as a shared-memory system and coordinating global routing. Preliminary multi-node evaluations reveal further redundant traffic elimination and speedup over hierarchical communication libraries.
(Figure 23)
Figure 23: DySHARP multi-node extension outperforms hierarchical baseline.
Implications and Future Directions
DySHARP raises both practical and theoretical implications:
- Efficient Expert Parallelism: By removing fundamental communication inefficiencies, DySHARP enables scalable MoE training and inference even as GPU counts, model sizes, and sequence lengths increase.
- Hardware and Network Interface Co-design: DySHARP demonstrates that dynamic, memory-semantic in-switch computing is essential for non-static tensor parallelism, and motivates further architectural enhancements for dynamic collectives beyond MoE.
- Unified Communication Abstraction: The algebraic-layout mapping and token-paced pipeline abstraction could inform future compiler/runtime designs for dynamic communication workloads.
- Multi-Node Clusters: Integrating dynamic in-switch computing across intra- and inter-node networks may optimize distributed LLM training at SuperPOD scale, with redesigned packet aggregation and address mapping.
Future developments may extend DySHARP's principles to other sparse activation models, dynamic graph workloads, and context-dependent communication patterns in large-scale AI architectures.
Conclusion
DySHARP provides a comprehensive solution to MoE communication redundancy via dynamic in-switch computing and token-centric kernel fusion, yielding up to 1.79× speedup over contemporary baselines. Its architectural and scheduling co-design paves the way for performant, scalable MoE execution on large multi-GPU systems and distributed clusters, establishing critical benchmarks and abstractions for future AI hardware and runtime designs.