- The paper introduces CAIS, a framework that integrates compute-aware ISA, microarchitecture extensions, and compiler/runtime co-design to alleviate communication bottlenecks in tensor-parallel LLMs.
- It employs merging-aware thread block coordination and graph-level dataflow optimization to reduce switch buffer size by 87% and enable efficient compute-communication overlap.
- Quantitative results show up to 2.03× speedup over state-of-the-art methods, demonstrating scalable performance and near-peak bandwidth utilization in multi-GPU systems.
Compute-Aware In-Switch Computing for LLM Tensor Parallelism on Multi-GPU Systems
Introduction and Motivation
The scaling of LLMs to trillions of parameters imposes severe communication bottlenecks for distributed training and inference—particularly under tensor parallelism (TP). While data and pipeline parallelism contribute minimally to inter-GPU traffic, TP accounts for the overwhelming bulk (>99%), largely via collective operations like AllReduce, AllGather, and ReduceScatter. Advanced interconnects such as NVLink and NVSwitch provide required bandwidth, yet are constrained by redundant data movements and inefficient compute-communication overlap, as shown by excessive communication time dominating at scale.
NVLink SHARP (NVLS) extends in-switch computing capabilities to multi-GPU collectives, accelerating collective operations by performing reductions within switch fabric. However, NVLS exhibits a communication-centric design that fails to align its communication modes (push/pull primitives) with the memory semantics expected by LLM compute kernels like GEMM. The resulting semantic mismatch enforces global barriers between computation and communication, with compute and network resources underutilized and limited scope for overlapping these critical phases.
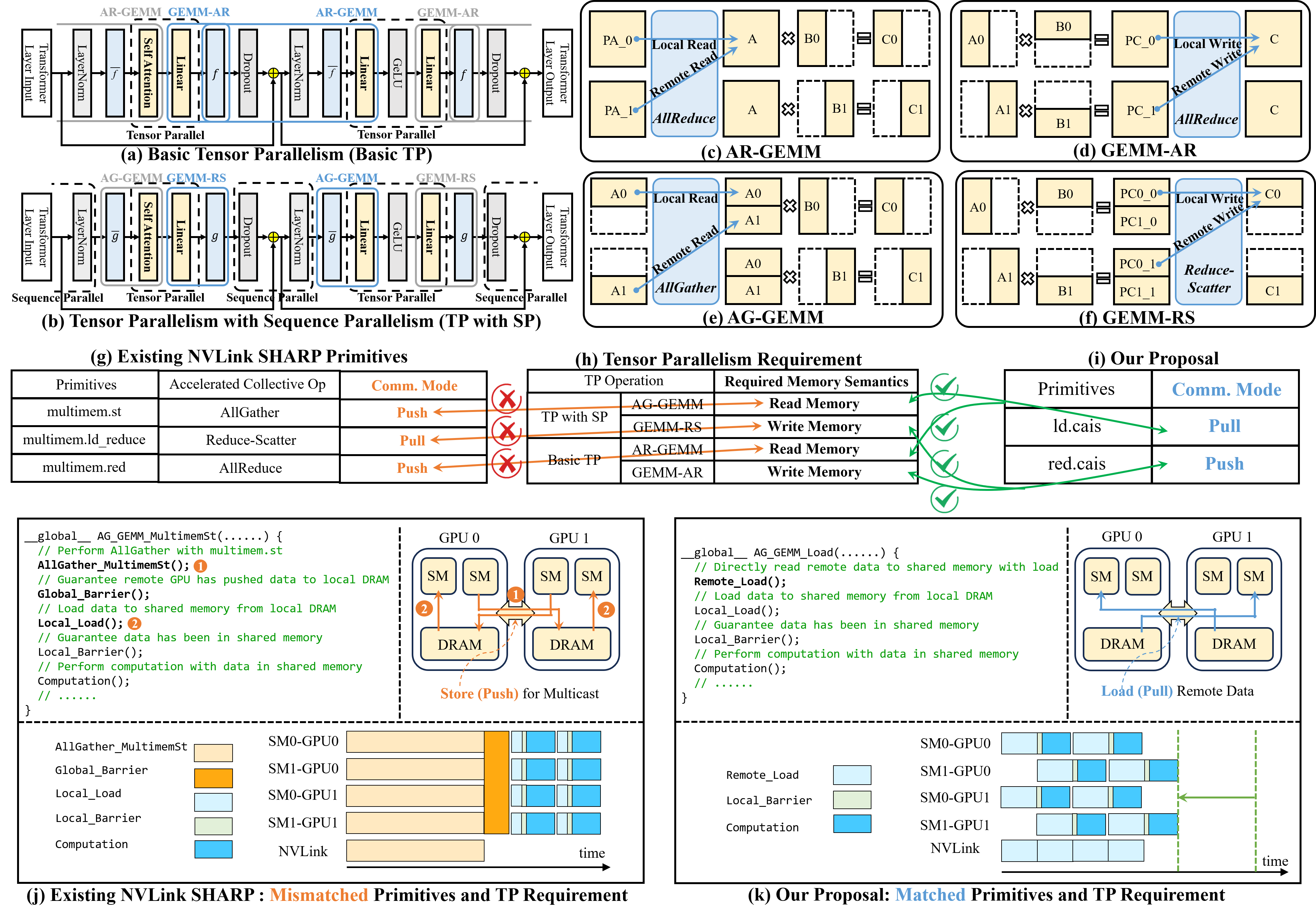
Figure 1: Motivation for compute-aware in-switch computing—visualizing (a-b) TP procedures, (c-f) collective/computation relationships, (g-i) limitations of existing NVLS primitives, and (j-k) computation detail comparisons.
Empirical measurements indicate that in large TP model deployments—even with state-of-the-art hardware—communication time quickly exceeds compute time, a trend exacerbated with increased GPU counts and model scale.
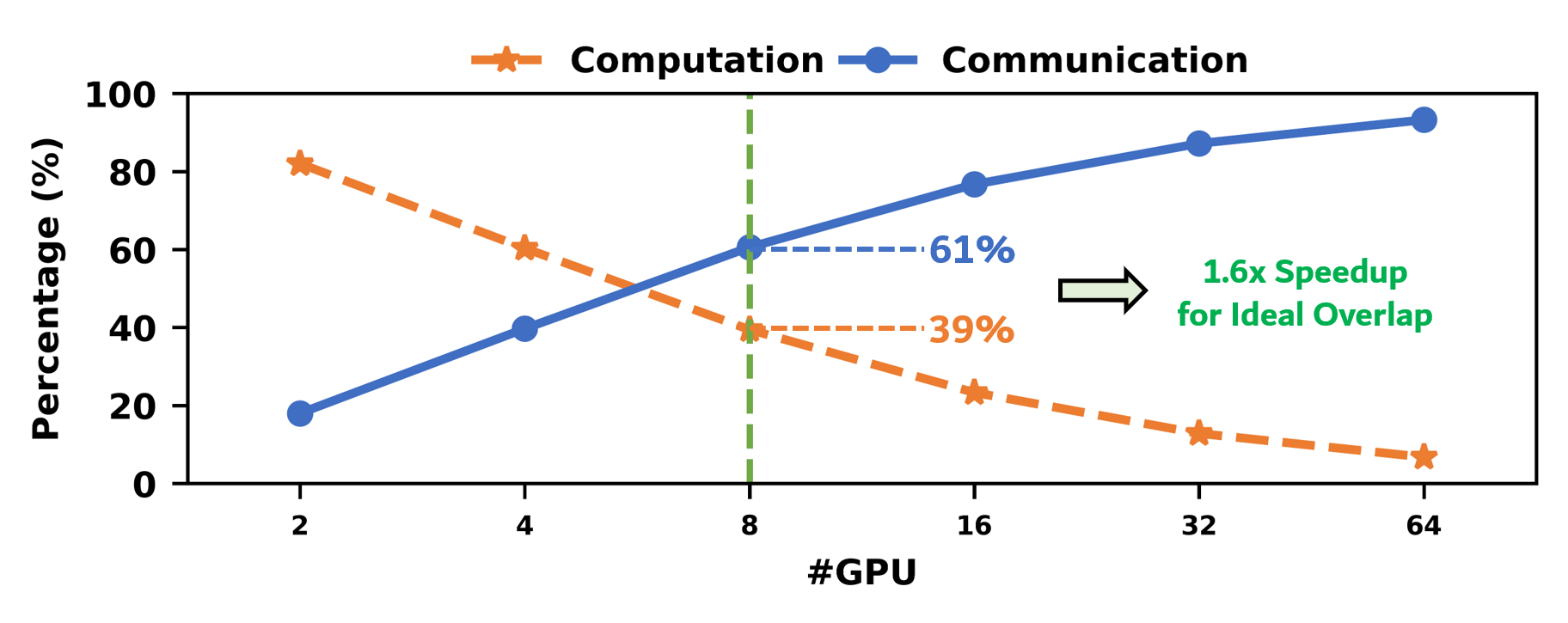
Figure 2: Communication time rapidly outpaces computation when scaling model/GPU counts.
The major research challenge is to break this communication-computation isolation and unlock fine-grained, kernel-integrated overlap for TP-centric LLM workloads.
The CAIS Framework: Key Innovations
CAIS (Compute-Aware In-Switch Computing) directly addresses the communication-compute semantic mismatch by integrating architecture, compiler, and runtime co-design. CAIS consists of three foundational contributions:
- Compute-Aware ISA and Microarchitecture Extensions: CAIS introduces new PTX instructions (ld.cais, red.cais) that express whether a memory access is mergeable at the switch. The switch microarchitecture is extended to include dynamic request merging units, leveraging CAM-based lookup and merging tables for both load and reduction requests.
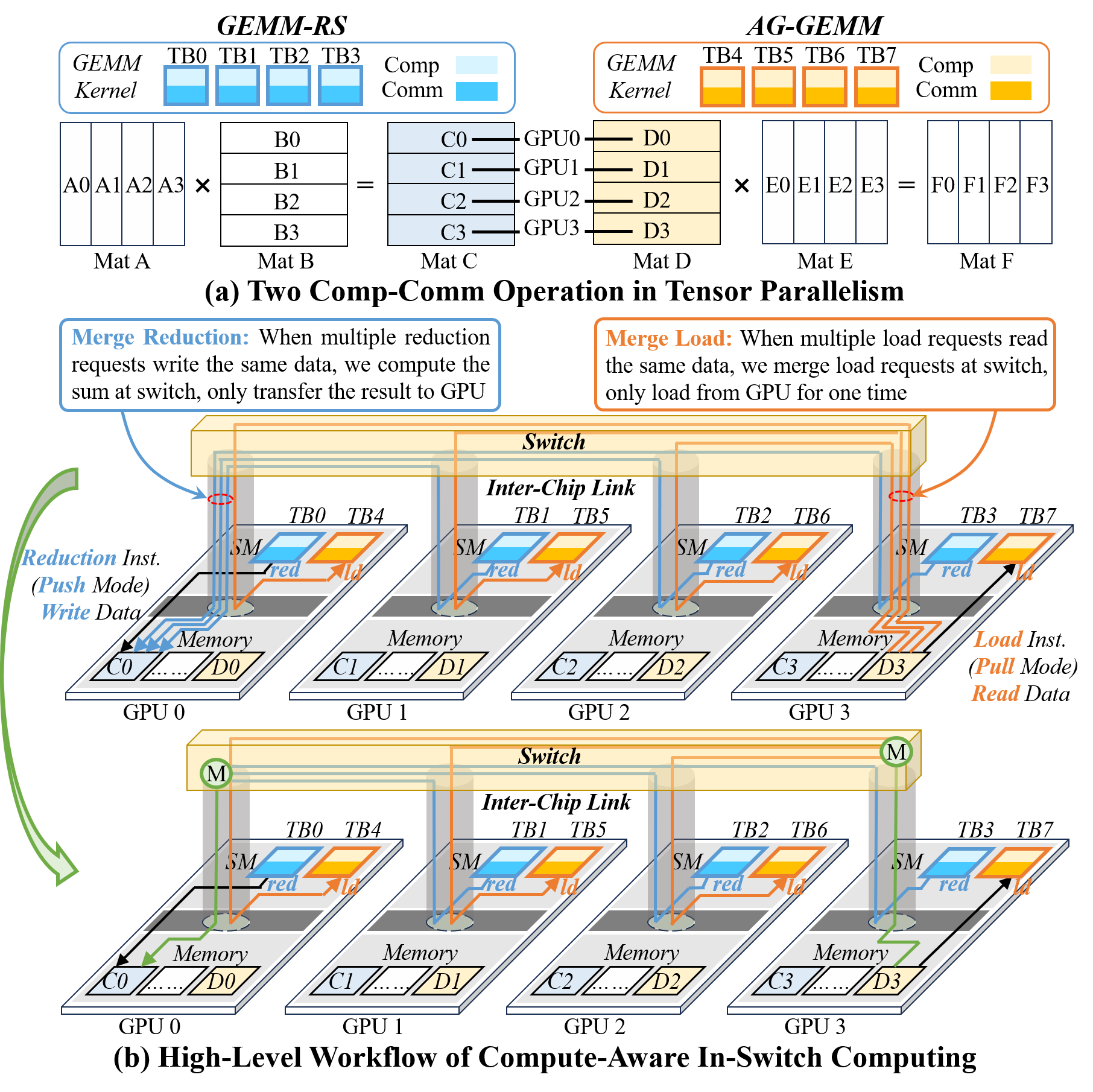
Figure 3: Overview of the CAIS system architecture, integrating ISA, microarchitecture, and compiler/runtime support.

Figure 4: PTX ISA extensions for compute-aware CAIS operations.
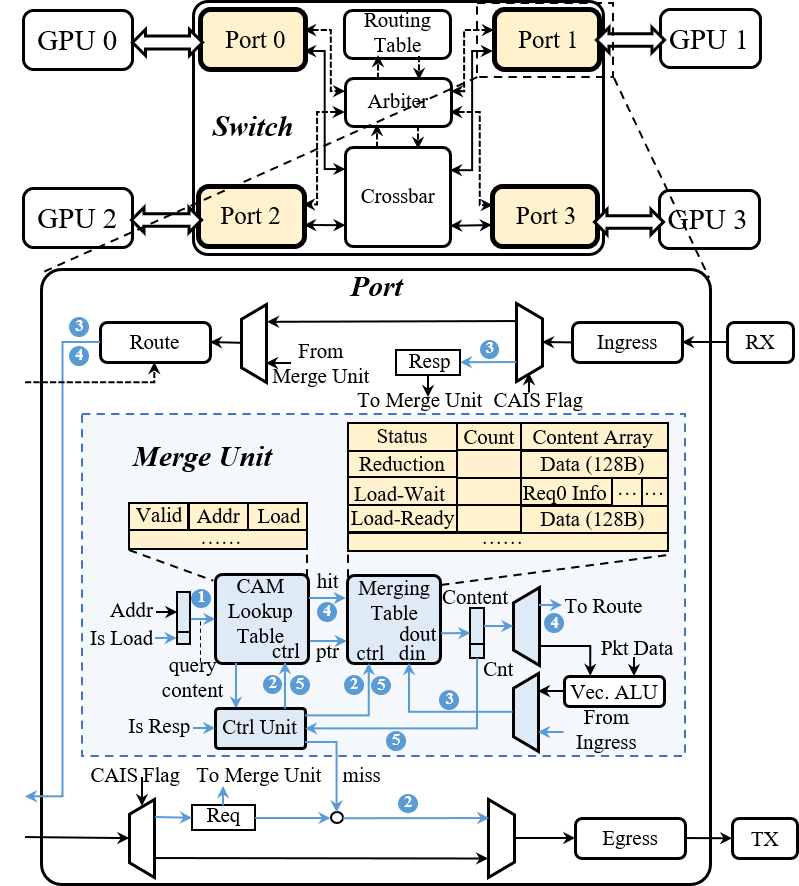
Figure 5: Switch microarchitecture with merge units for dynamic aggregation operations.
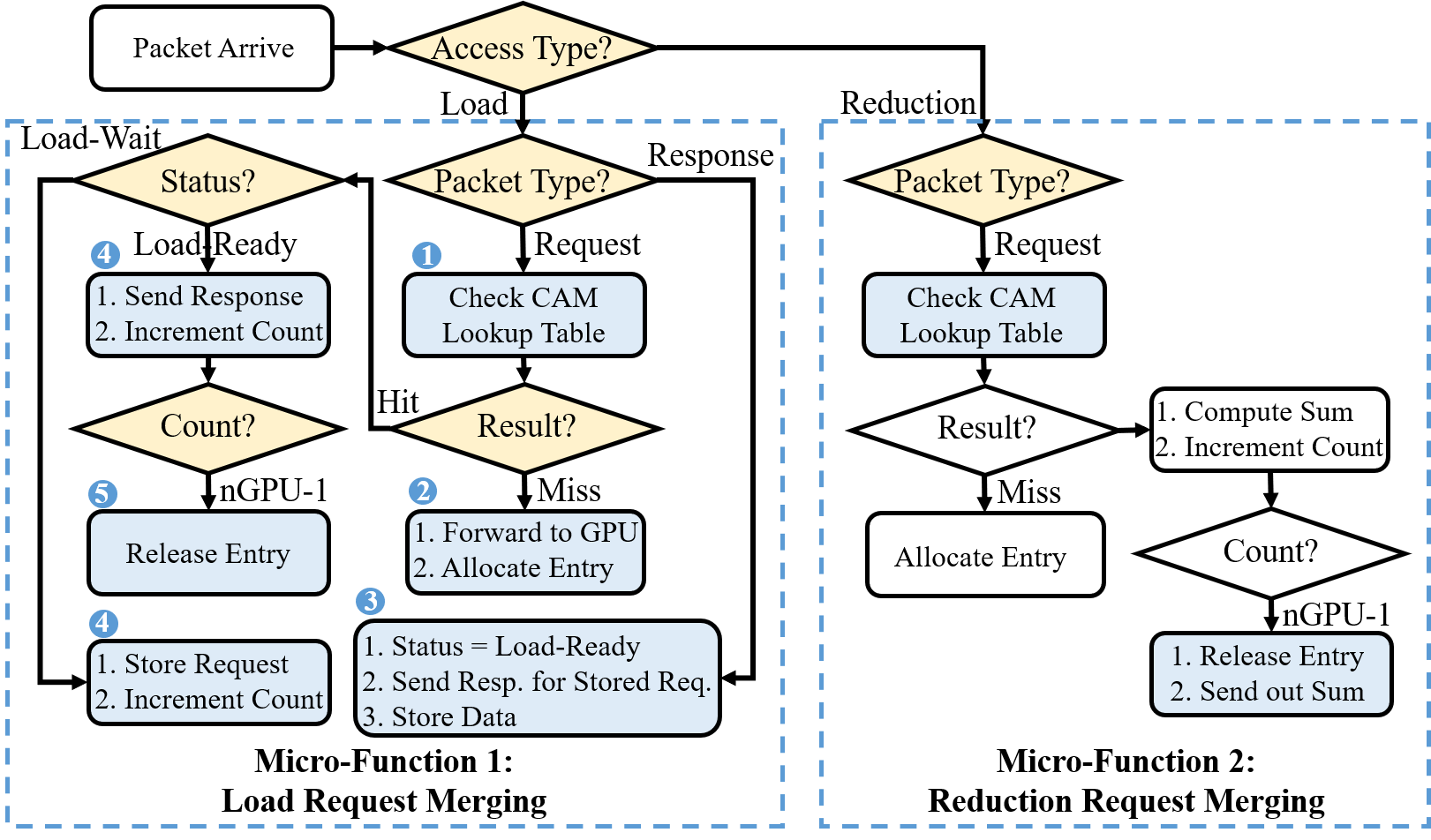
Figure 6: In-switch micro-functions implementing dynamic load and reduction request merging.
- Merging-Aware Thread Block Coordination: CAIS provides compiler- and runtime-enabled TB-grouping mechanisms that temporally align memory requests across GPUs, maximizing opportunities for merging at the switch and drastically reducing the required switch buffer size.
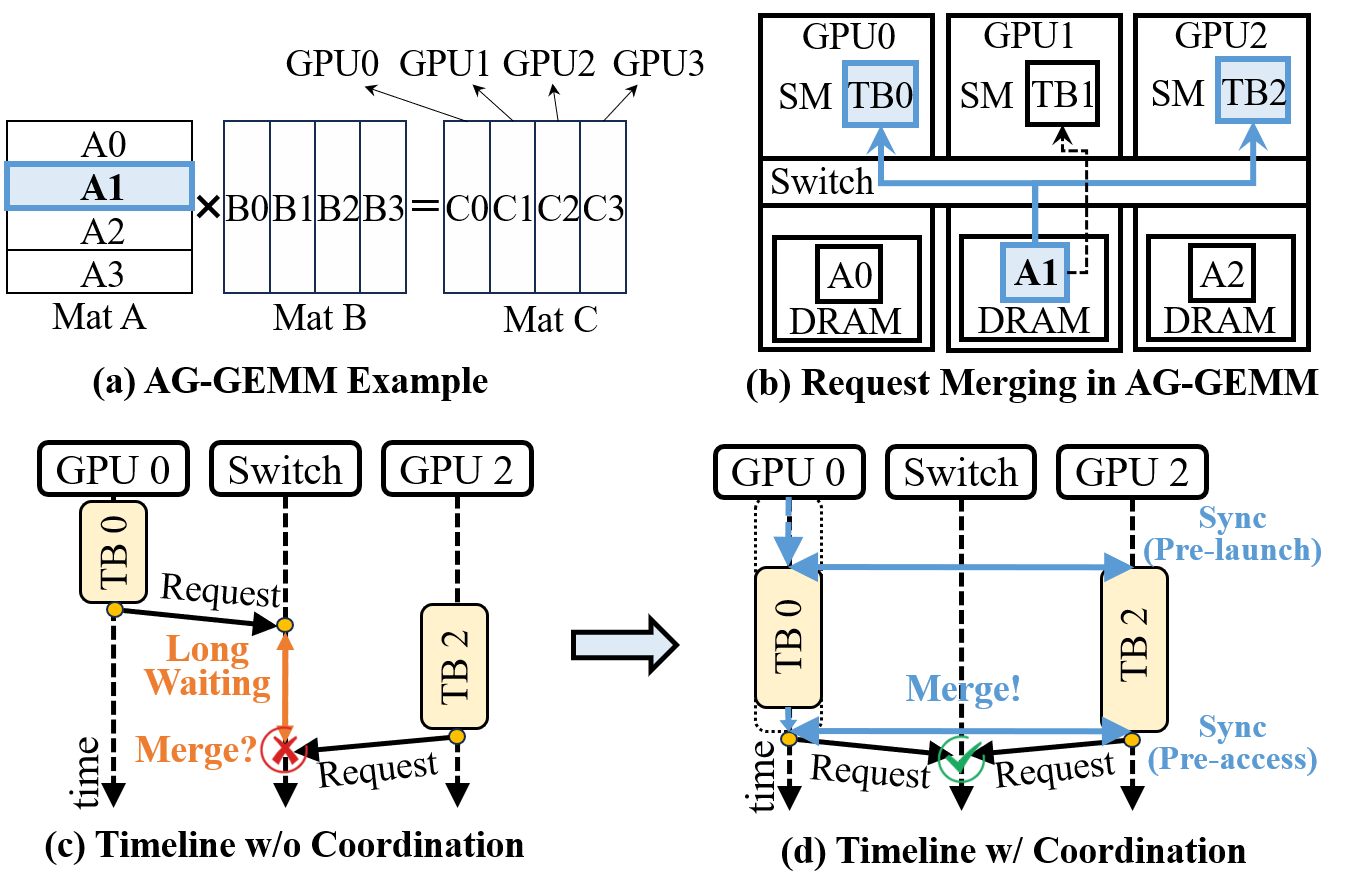
Figure 7: Merging-aware thread block (TB) group coordination for temporal alignment across GPUs.
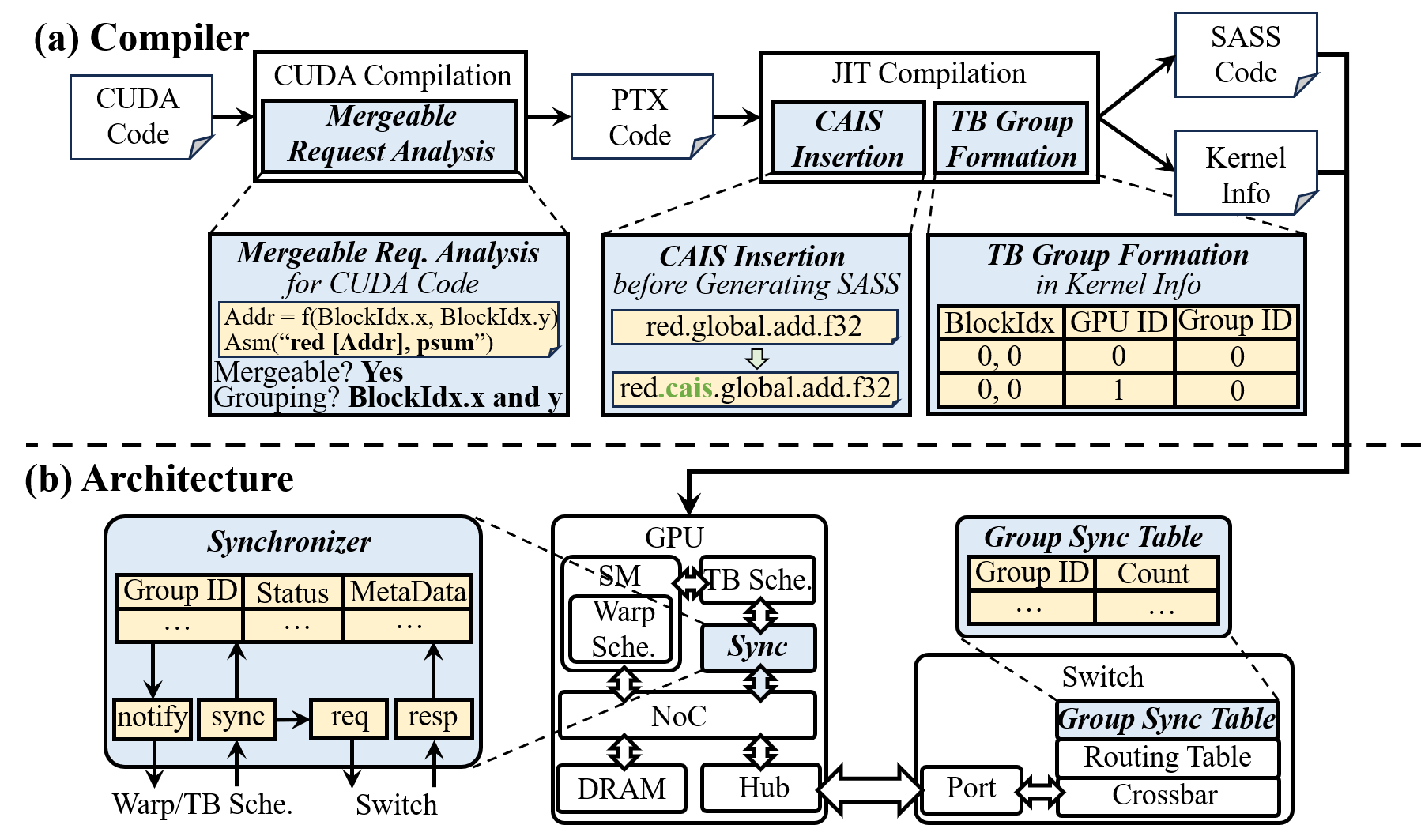
Figure 8: Compiler and architectural support for synchronization and TB group management.
- Graph-Level Dataflow Optimization: Fine-grained TB-level data dependencies facilitate deep kernel fusion and asymmetric kernel overlapping, particularly for communication-heavy operator sequences common in LLM dataflows (e.g., GEMM-RS + LN + AG-GEMM).
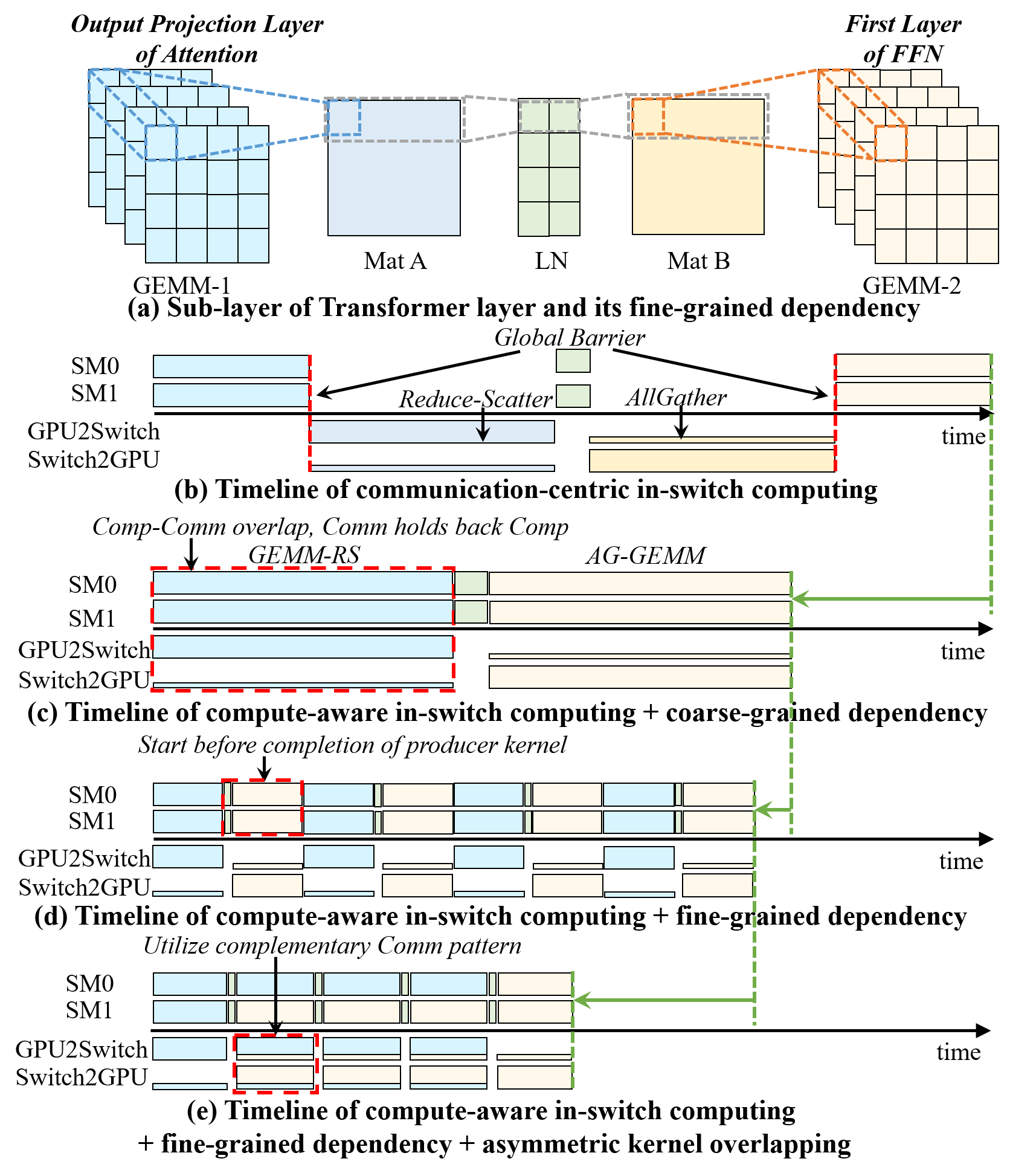
Figure 9: Graph-level dataflow optimization enabling early launch of consumer TBs based on fine-grained data dependencies.
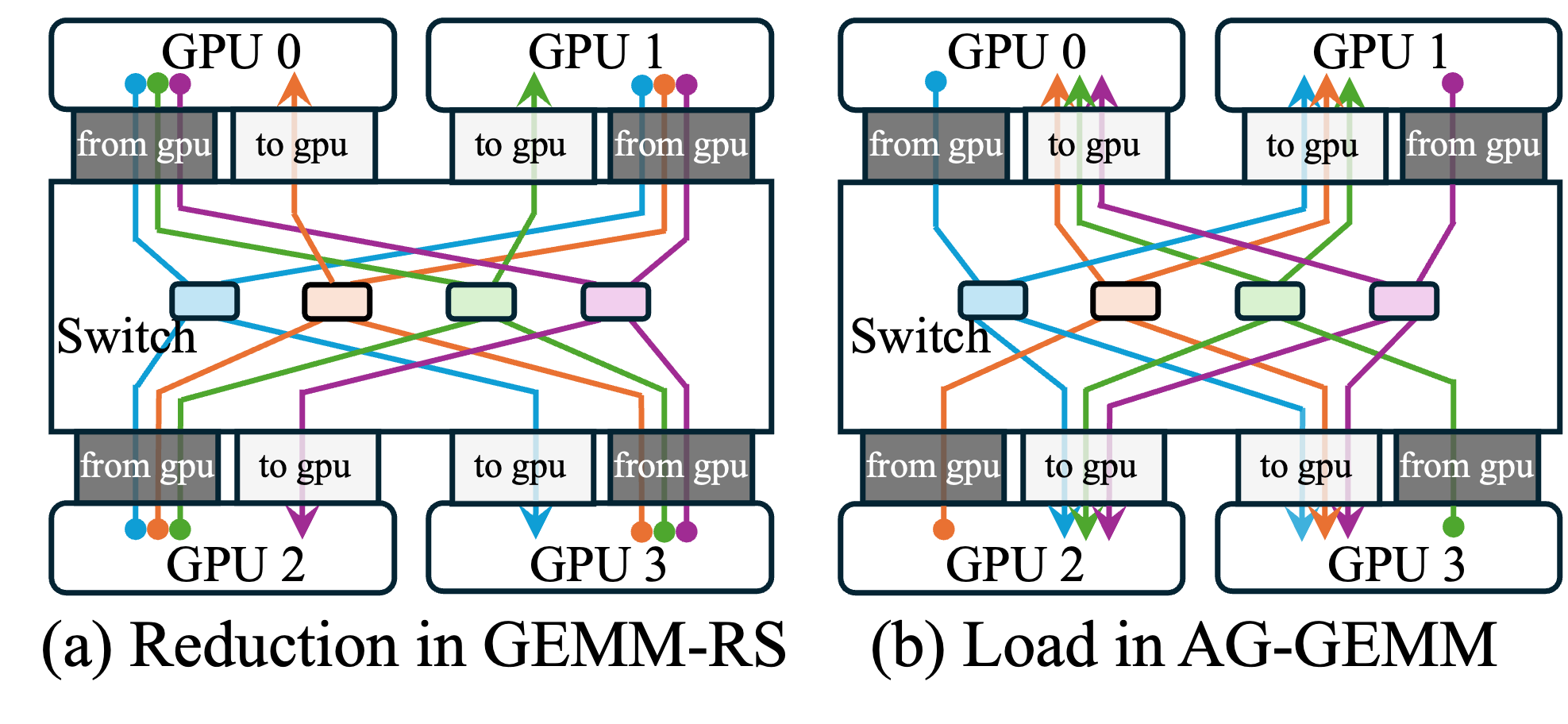
Figure 10: Illustration of asymmetric traffic flows arising due to different communication phases.
Quantitative Results
Extensive cycle-accurate simulation using variants of LLaMA and GPT models on an 8-GPU NVSwitch topology demonstrates up to 1.44× end-to-end speedup over leading NVLS-based TP baselines and up to 2.03× over state-of-the-art hardware/software compute-communication overlap methods (e.g., T3). CAIS also significantly surpasses prior approaches to kernel fusion and software-level overlap, including CoCoNet and FuseLib, with robust speedup across both training and inference and in all communication-intensive model sub-layers.
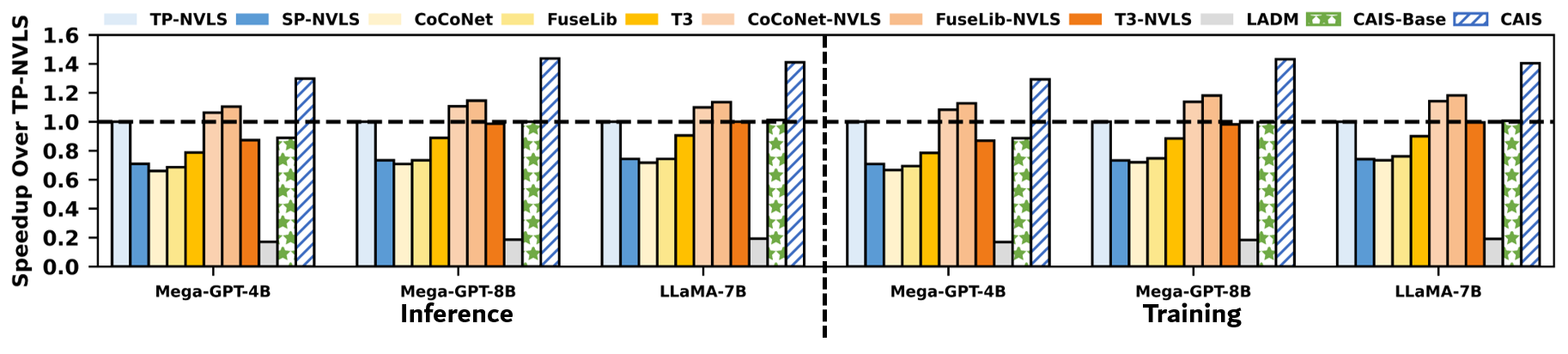
Figure 11: End-to-end model speedup in training and inference for CAIS vs. prior approaches.
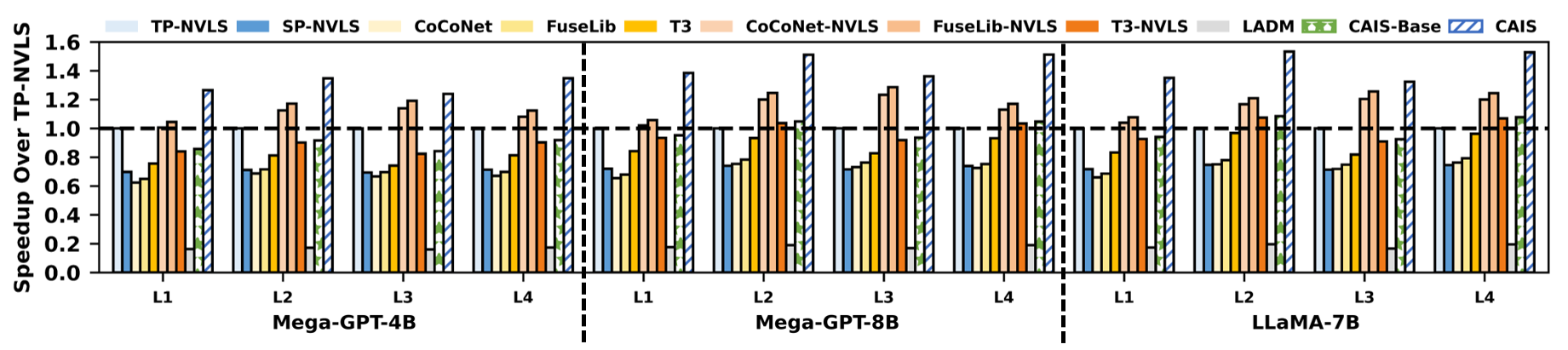
Figure 12: Sub-layer (FFN and Attention) speedup highlighting strengths of CAIS in communication-heavy model segments.
CAIS’s performance stems not only from eliminating global computation-communication barriers via compute-aware ISA and microarchitecture, but also from effective TB coordination and graph-level dataflow integration. Notably, merging-aware TB coordination reduces minimum required switch buffer size by 87% and delivers consistent performance even with modest hardware resources.
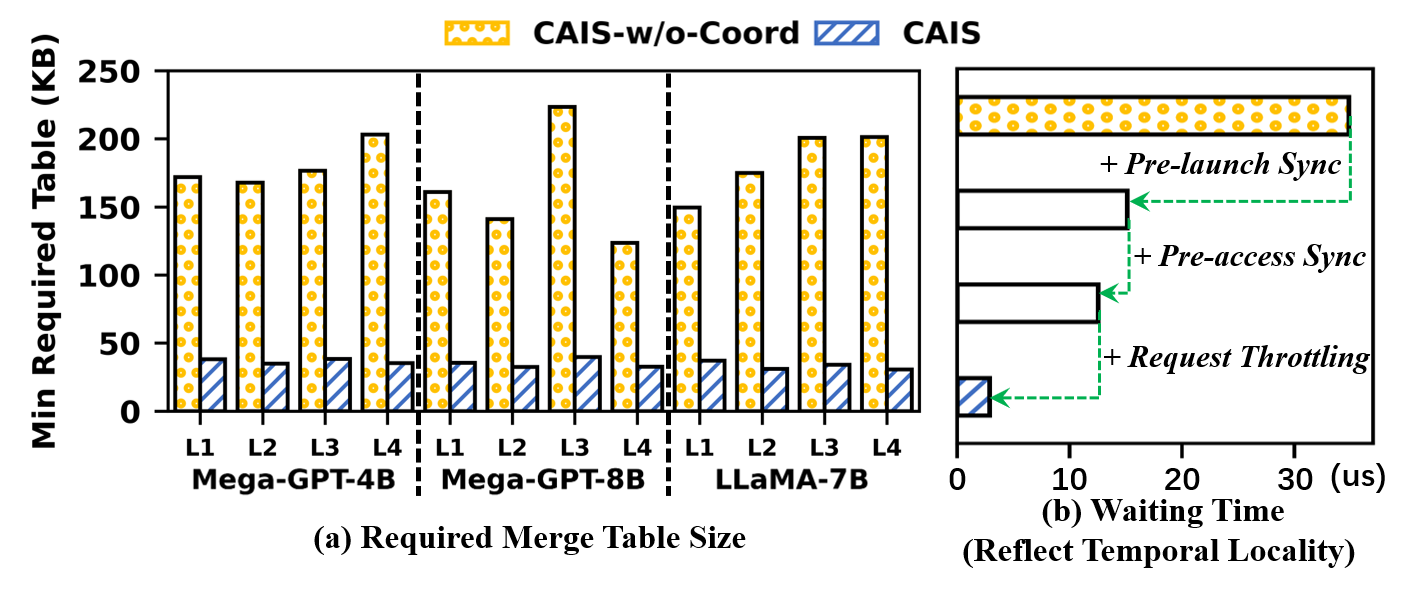
Figure 13: (a) Merge table size reduction with merging-aware TB coordination; (b) Ablation on temporal alignment impact.
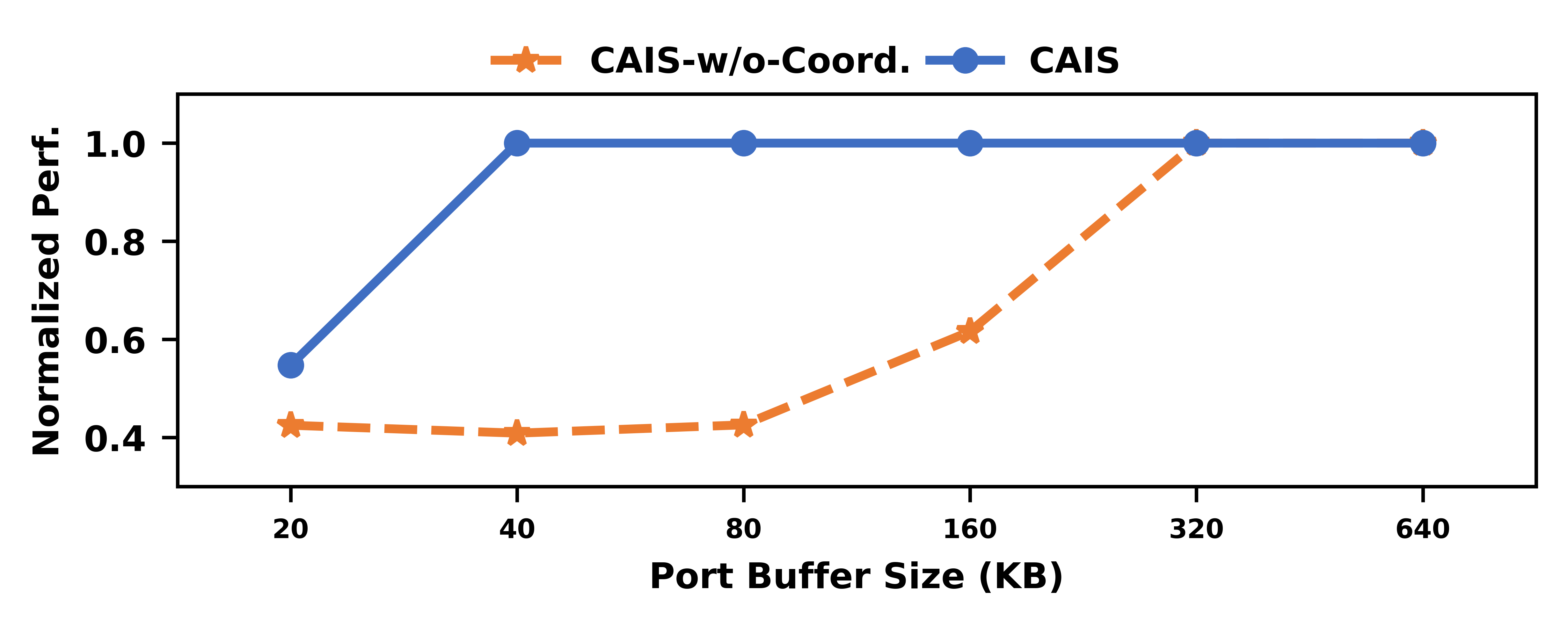
Figure 14: CAIS robustness to merge table size compared to baseline, maintaining 90%+ performance with small buffers.
Bandwidth utilization is another critical metric—CAIS’s graph-level optimizer and traffic control maintain near-peak link utilization, overcoming bidirectional imbalances inherent to asymmetric collectives.
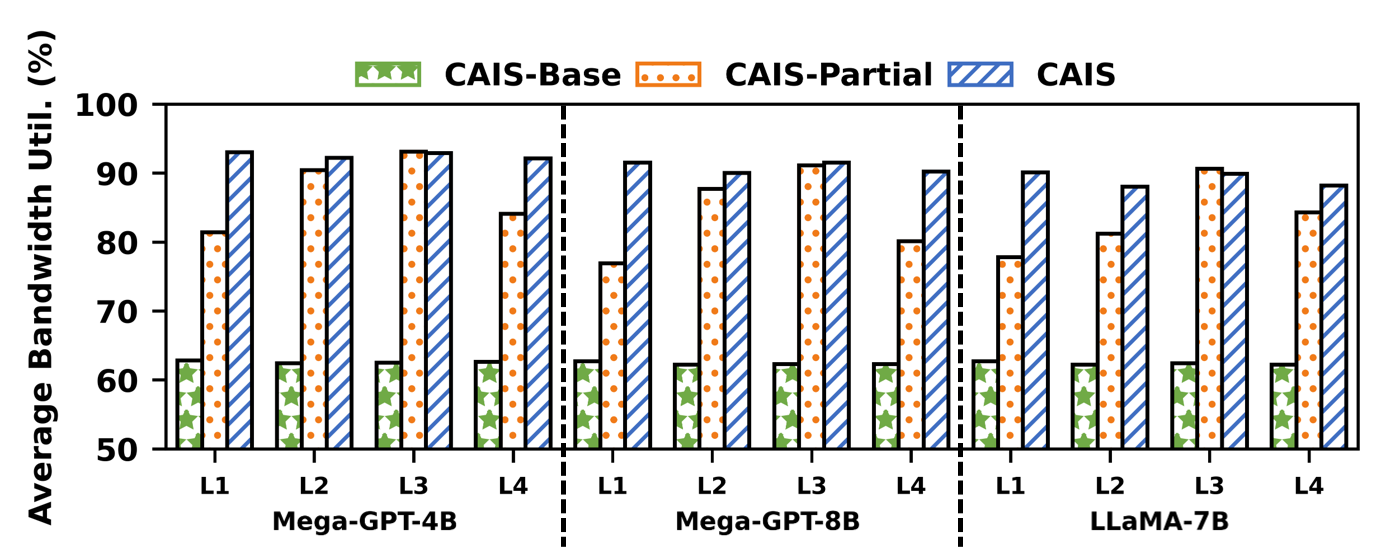
Figure 15: Average bandwidth utilization per sub-layer under CAIS and baseline systems.
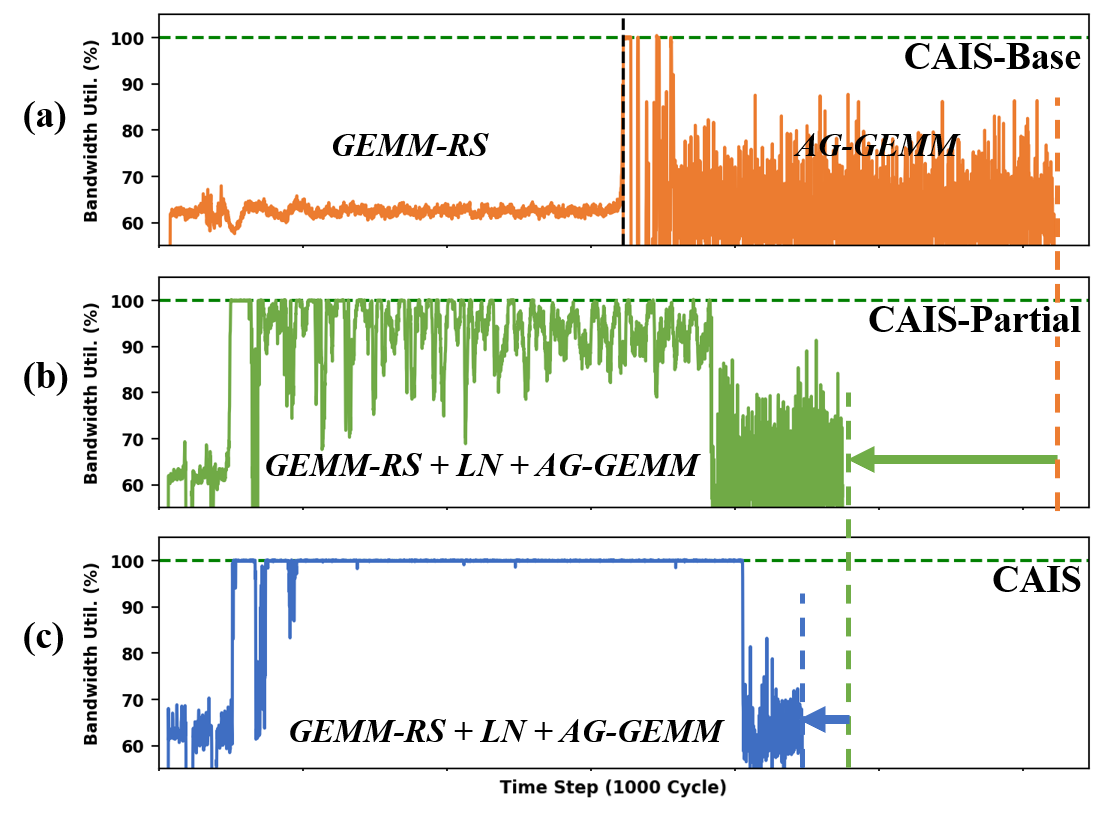
Figure 16: Bandwidth utilization traces over time for CAIS’s baseline, partial, and full optimization configurations.
Scalability analysis confirms that the per-GPU throughput is maintained and hardware overhead remains constant as GPU count increases; required switch memory is bounded by outstanding requests per GPU rather than total system size.
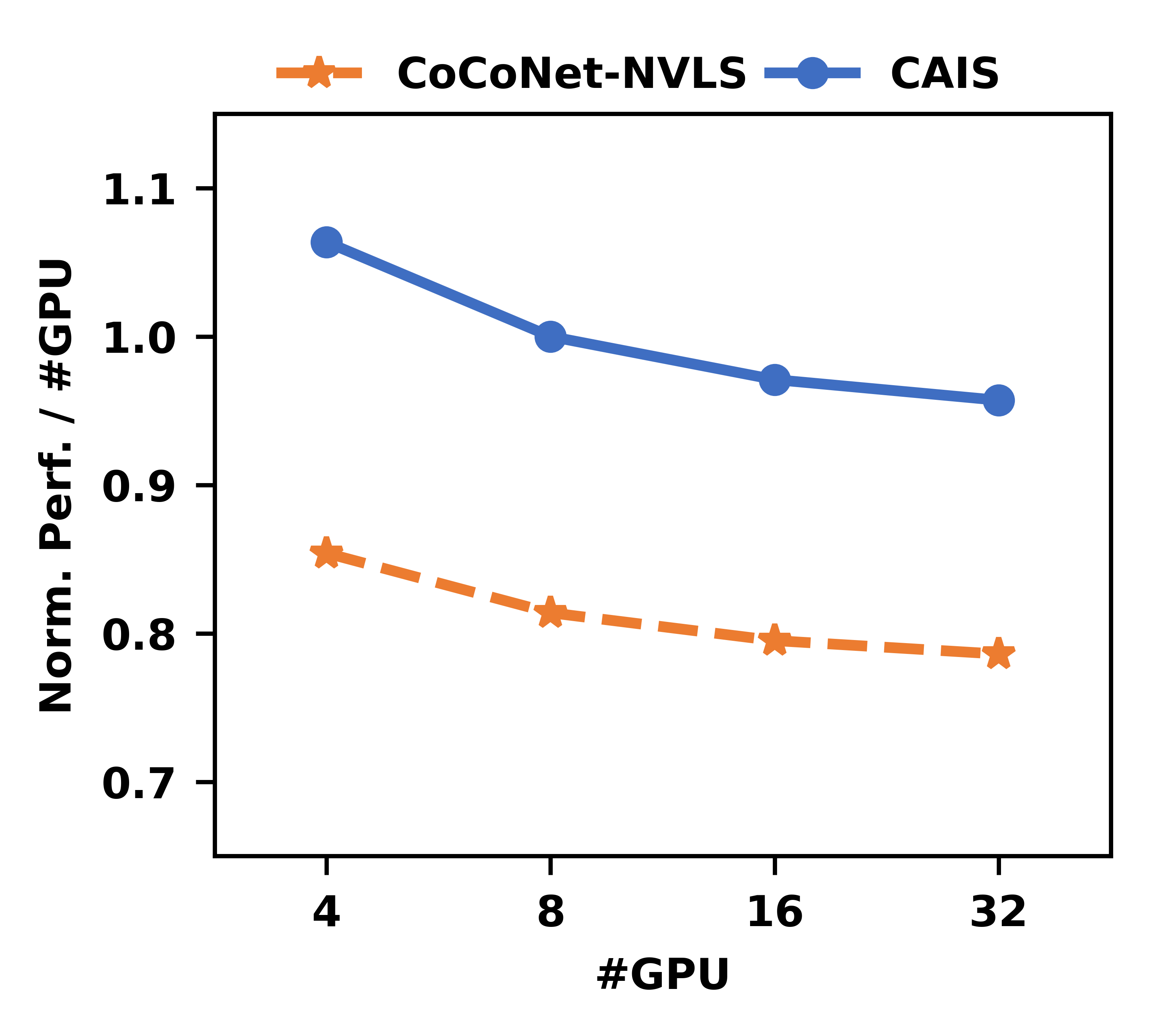
Figure 17: Scalability with increasing GPU count—CAIS maintains efficiency at larger system scales.
Discussion and Implications
CAIS sets a precedent for co-designed compute-aware in-switch architectures that supersede the old division between computation and collective communication. Key theoretical implications include:
- Semantic Integration of Computation and Communication: By aligning memory load/reduction semantics with in-switch merge operations, CAIS offers a hardware/software interface that directly expresses parallel workload dependencies—enabling tight, automated overlap and avoiding ad hoc software kernel fusion or global barriers prevalent in earlier methods.
- Temporal Locality as a First-Class Optimization: Compiler-guided TB coordination exposes new architectural levers, benefiting from regularity in TP dataflows to maximize switch aggregation efficiency and minimize buffer pressure.
- Hardware Feasibility and Efficiency: CAIS enhancements are lightweight (<1% of NVSwitch die area), and due to deterministic merging, hardware scalability is not penalized as system scale increases. This makes CAIS suitable for deployment in next-generation multi-GPU clusters for LLM workloads.
- Future Systems: The practical implications point to next-generation AI clusters that will increasingly require semantic awareness in switch-level logic, with ISAs that offer fine-grained programmable collectives commensurate with diverse model parallel patterns. This trajectory may stimulate further architectural/software synergy for ML system design, reducing both communication bottleneck and code complexity as model sizes continue to scale.
Conclusion
CAIS fundamentally redefines in-switch compute for TP-intensive LLM workloads by establishing a compute-aware semantics bridge between GPU kernels and switch microarchitecture. Through co-designed ISA, microarchitecture, and compiler optimizations, CAIS achieves significant and scalable performance gains that surpass both communication-centric and overlap-enhanced baselines. Its integration unlocks fine-grained compute-communication overlap and efficient hardware utilization, providing a robust foundation for future multi-GPU LLM architecture and workload co-optimization.
(2605.05628)

