- The paper introduces PhysicianBench, a benchmark that operationalizes complex, long-horizon clinical workflows using real EHR data and 100 tasks with 670 checkpoints.
- It employs a POMDP framework to integrate multi-step tool calls for FHIR operations, facilitating granular failure analysis in clinical reasoning and action execution.
- Experimental results highlight a significant performance gap among LLM agents, revealing challenges in documentation, reasoning, and consistent execution across specialties.
PhysicianBench: Rigorous Evaluation of LLM Agents in Real-World EHR Contexts
Motivation and Benchmark Design
PhysicianBench introduces a robust benchmark for assessing LLM agents' ability to conduct physician tasks in real, FHIR-compliant EHR environments. Unlike prior medical benchmarks that center on static knowledge, atomic action intent, or synthetic simulation, PhysicianBench operationalizes complex, long-horizon workflows requiring multi-step reasoning, tool use, and verifiable execution against a real EHR state. Tasks derive from authentic clinical consultations spanning 21 subspecialties, constructed and validated through iterative expert review with 100 tasks and 670 discrete checkpoints.
The benchmark frames each agent interaction as a POMDP, contextualizing the agent's actions—spanning FHIR resource querying, creation (e.g., MedicationRequest, ServiceRequest), and utility operations (e.g., file output)—as tool calls in a partial-observation environment. Each agent's trajectory is graded at multiple clinically significant checkpoints with deterministic code, hybrid (code+LLM extraction), or LLM-judge schemes, enabling granular identification of failure modes across data retrieval, clinical reasoning, action execution, and documentation.

Figure 1: Overview of PhysicianBench workflow construction, agent-environment interaction, and checkpoint-based evaluation.
Task Structure and Clinical Scope
PhysicianBench comprises 100 tasks, curated from e-consult cases adapted to diverse clinical roles and scenarios, mapped onto real, de-identified patient records with careful perturbation for privacy and fidelity. Tasks are categorized into four high-level clinical workflow types—Diagnosis/Interpretation, Medication Prescribe, Treatment Planning, and Workup/Risk Stratification—each decomposed into finer subtypes aligned with physician decision taxonomies.
Tasks are distributed across 21 clinical subspecialties, reflecting broad and realistic coverage. Each task requires, on average, 27 tool calls, with agents expected to retrieve multi-source data (labs, medications, notes), synthesize complex state, execute orders, and document plans.
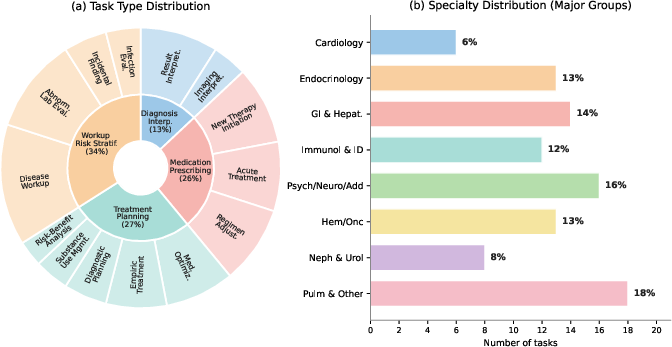
Figure 2: Task-type and specialty-group distribution in PhysicianBench, illustrating broad coverage.
Data Annotation and Clinical Validation
The benchmark's construction integrates rigorous validation through an interactive, multistage pipeline powered by both LLM agents and physician reviewers. Each task is reviewed against a clinical checklist targeting clarity, reasoning validity, completeness, safety, and data fidelity. Agentic revisions enable structured edits, followed by diff-based approval cycles iterated until all artifacts are validated for clinical soundness.
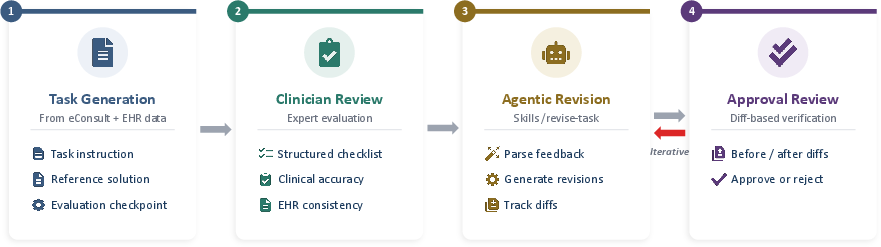
Figure 3: Annotation pipeline detailing artifact generation, expert review, agentic revision, and iterative approval.
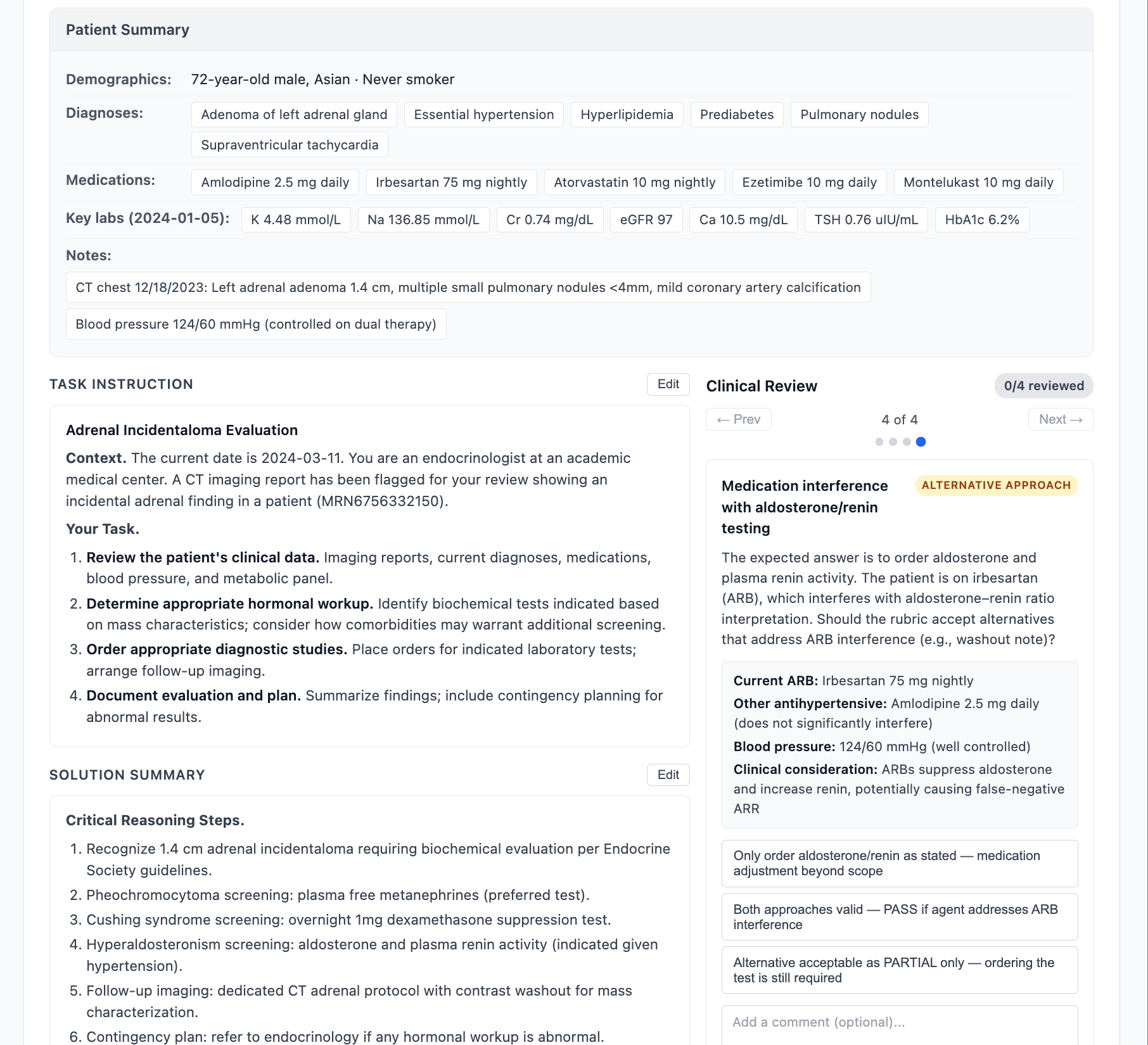
Figure 4: Initial-review UI with clinical checklist, instruction, solution summary, and patient overview.
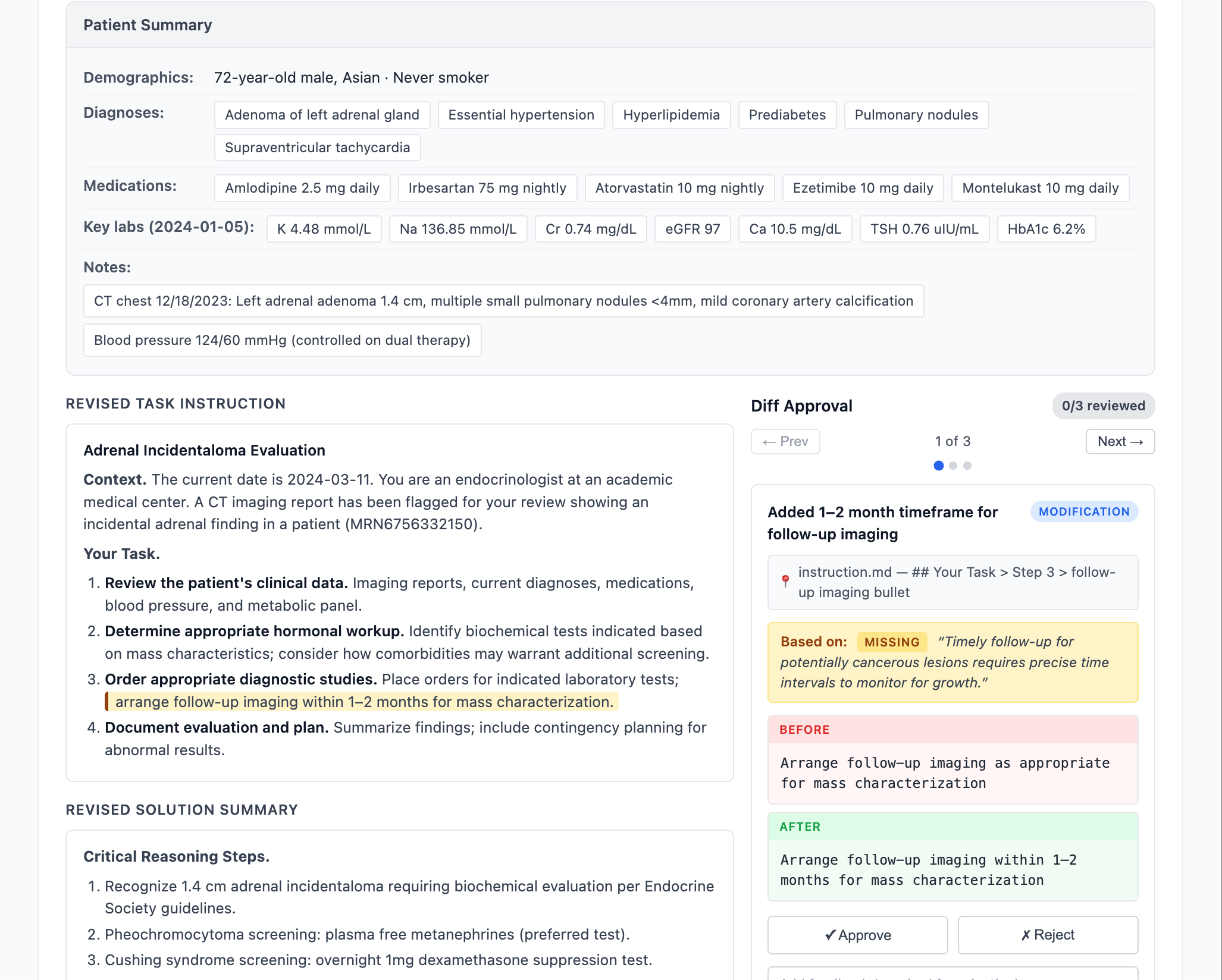
Figure 5: Diff-based annotation UI for granular review and approval of agent-generated edits.
The evaluation spans 12 LLM agents—both proprietary and open-source—with standardized agentic loops and full tool access. GPT-5.5 leads with a 46.3% pass@1 rate, with reliability (pass3) reaching 28%. Open-source models max out at 19% success, underscoring a substantial capability gap. The results show significant variation across specialties (up to 59% in Endocrinology for GPT-5.5) and task types (Treatment Planning consistently most challenging).
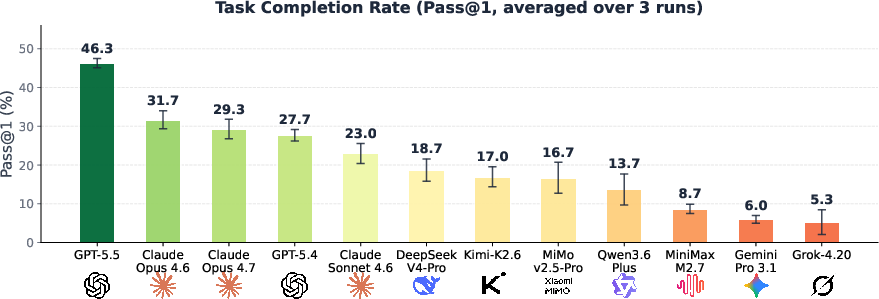
Figure 6: Ranked model performance on PhysicianBench by pass@1, revealing the performance stratification.
Error Analysis and Failure Breakdown
Checkpoint-based error classification reveals that clinical reasoning dominates agent failure modes (over 50% of failed checkpoints for most models), rather than tool-use or data retrieval. Action execution errors—often reflecting output gaps (note documentation but no corresponding FHIR order), documentation omissions, and incomplete reasoning—are prevalent across both strong and weak agents.
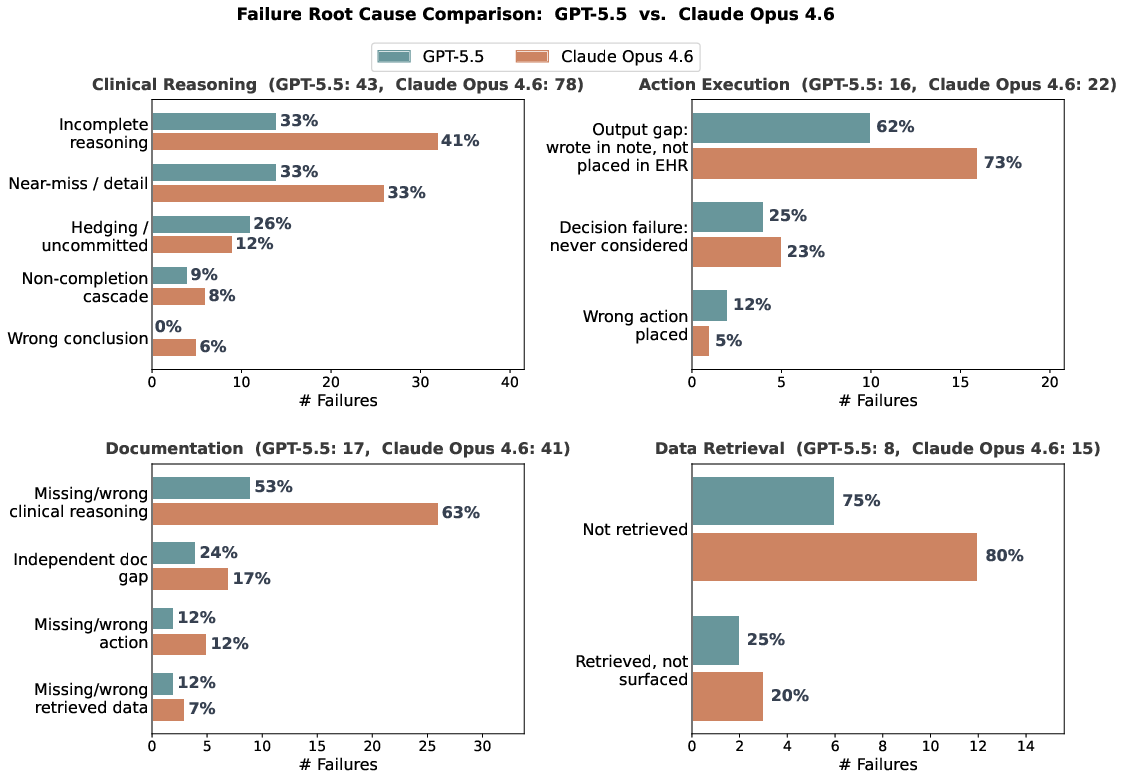
Figure 7: Fine-grained failure breakdown for GPT-5.5 vs. Claude Opus 4.6, quantifying error categories and subtypes.
Qualitative analysis demonstrates that GPT-5.5's advantage stems from deeper EHR exploration, enhanced coverage of rubric items, and improved consistency in surfacing literal data, rather than superior clinical-knowledge reasoning. However, even the strongest models display frequent near-miss errors and inconsistent execution, indicating that full workflow autonomy remains unrealized.
Benchmark Implications and Future Directions
PhysicianBench fundamentally reframes clinical LLM benchmarking, demanding composite workflow execution, verifiable EHR integration, and stringent clinical validation. The empirical gap between agentic LLMs and realistic workflow demands underscores immediate limitations for clinical deployment. The methodology and infrastructure enable reproducible evaluation, granular failure diagnostics, and comparative analysis across heterogeneous agent architectures.
Future improvements include expanding coverage to inpatient and discharge workflows, integrating agent-user collaboration paradigms, and supporting multimodal (imaging, waveform) and external knowledge base access. Scaling the tool ecosystem and ground truth evaluation will align benchmarks more directly with real-world clinical complexity.
Conclusion
PhysicianBench represents a rigorous, execution-grounded framework for evaluating agentic LLMs in authentic clinical contexts. Empirical results quantify the gap between current capabilities and the demands of autonomous physician workflows. The benchmark's methodology facilitates controlled, reproducible analysis, illuminating failure modes and charting the trajectory for future agent advances in healthcare AI (2605.02240).

