- The paper introduces a novel rubric-based benchmark using real clinician interactions to rigorously assess LLM performance and safety.
- It employs multi-stage peer review and stratified sampling, including adversarial red-teaming, to create challenging, realistic clinical tasks.
- Results show ChatGPT for Clinicians outperforming physicians in documentation, care consult, and research, highlighting the importance of system harness design.
HealthBench Professional: Rigorous Evaluation of LLMs on Real-World Clinician Tasks
Introduction
The clinical application of LLMs is increasingly prevalent, supporting millions of clinicians globally. However, the evaluation methodologies for these models often focus on narrow, synthetic, or saturated benchmarks that poorly reflect practical clinical workflows. "HealthBench Professional: Evaluating LLMs on Real Clinician Chats" (2604.27470) addresses this gap by introducing a high-quality, rubric-based benchmark grounded in real clinician-LLM interactions, aiming to assess both performance and safety on tasks of direct clinical relevance.
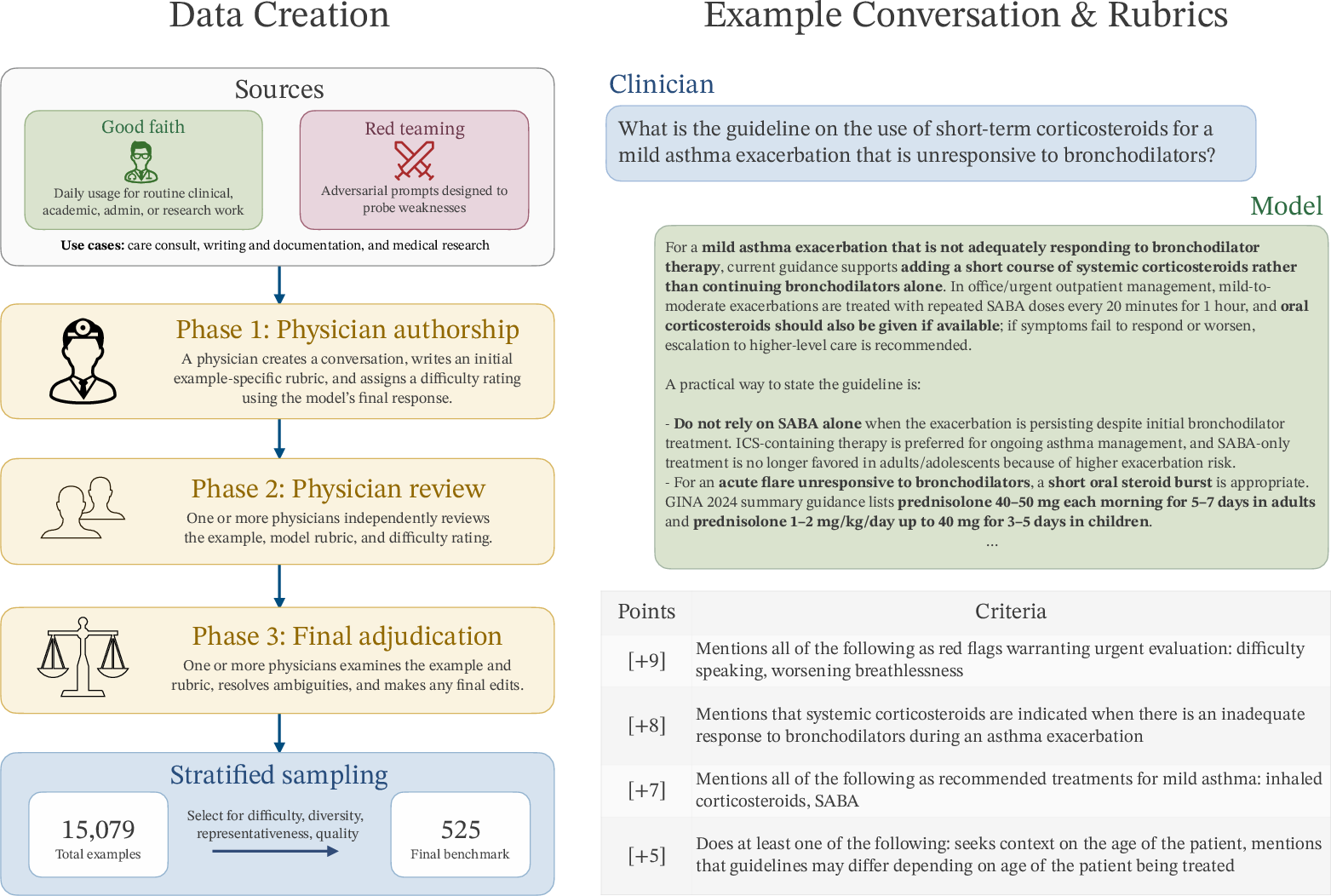
Figure 1: HealthBench Professional evaluates real clinician chat tasks across care consult, writing/documentation, and medical research, using daily clinical use and adversarial red-teaming. All conversations and rubrics undergo multi-physician review.
Benchmark Construction and Methodology
Dataset Sourcing and Composition
HealthBench Professional comprises 525 tasks authored by 190 experienced physicians across 50 countries and 26 specialties. Tasks derive from real-world usage of ChatGPT for Clinicians and are categorized into three central use cases:
- Care consult: Differential diagnosis, management, and treatment reasoning.
- Writing and documentation: Structured note-writing, summaries, coding, and patient messaging.
- Medical research: Retrieval and synthesis of clinical/scientific evidence.
Examples originate from both good faith testing (routine use) and red teaming (deliberate adversarial probing for model failures). Notably, about one-third of tasks are adversarially constructed, and stratified sampling increases the prevalence of difficult cases by 3.5×, ensuring headroom for frontier model assessment.
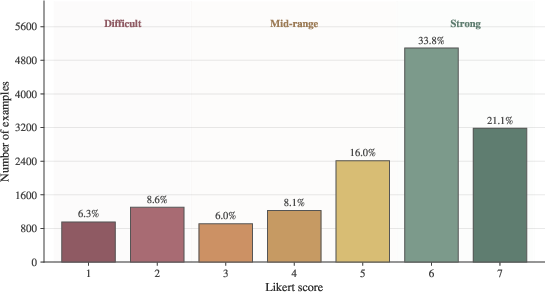
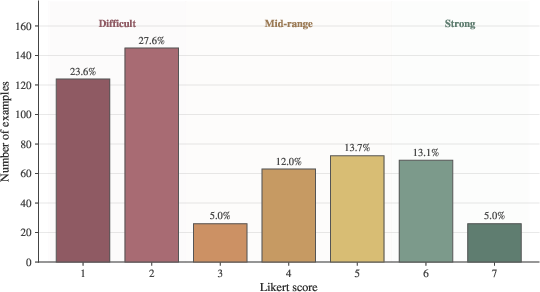
Figure 2: Likert difficulty score distribution before review and stratified sampling, illustrating the enrichment of difficult and adversarial cases in the final benchmark.
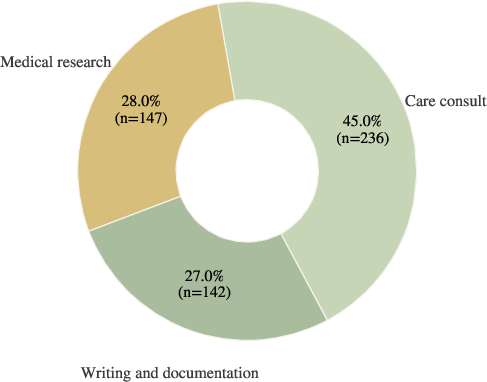
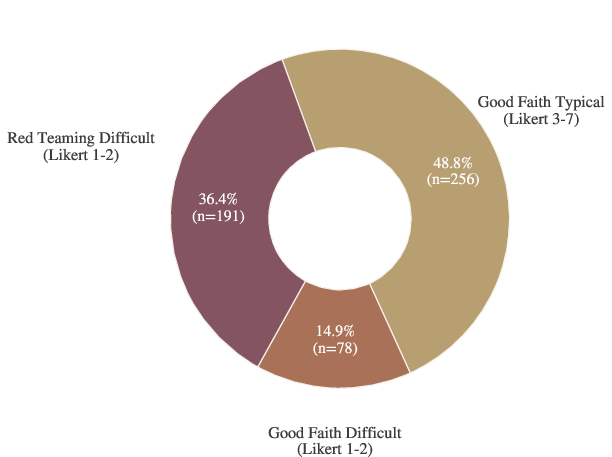
Figure 3: Benchmark composition by use case (left) and by source slice (right); care consult is dominant, with substantial representation from writing, documentation, and medical research.
Annotation and Multi-Stage Review
Each benchmark example undergoes a rigorous three-phase construction:
- Initial authorship: Physicians create the conversation, draft a tailored rubric, and assign a 7-point Likert difficulty rating.
- Peer review: Independent physician reviewers assess and refine annotations for realism and objectivity.
- Final adjudication: Additional physicians resolve ambiguities, emphasizing generalizable, high-confidence criteria.
Difficulty ratings are anchored to model performance on OpenAI's recent frontier models, and every hard example is independently validated for both challenge and realism.
Human Baseline
For all 525 cases, physician specialists—provided unbounded time and internet access—compose ideal model responses. These human references serve as a robust baseline for performance calibration.
Rubric-Based Grading and Length Adjustment
Scoring employs example-specific rubrics, with positive and negative criteria weighted between −10 and +10 points each. A model-based grader (GPT-5.4, low-reasoning) determines whether a response meets each criterion. Scores are normalized and then length-adjusted to penalize verbosity-induced inflation, using empirically derived linear penalties for answers exceeding 2,000 characters—a critical design choice for fairness given real-world clinician preferences and the propensity of LLMs for verbosity.
Results
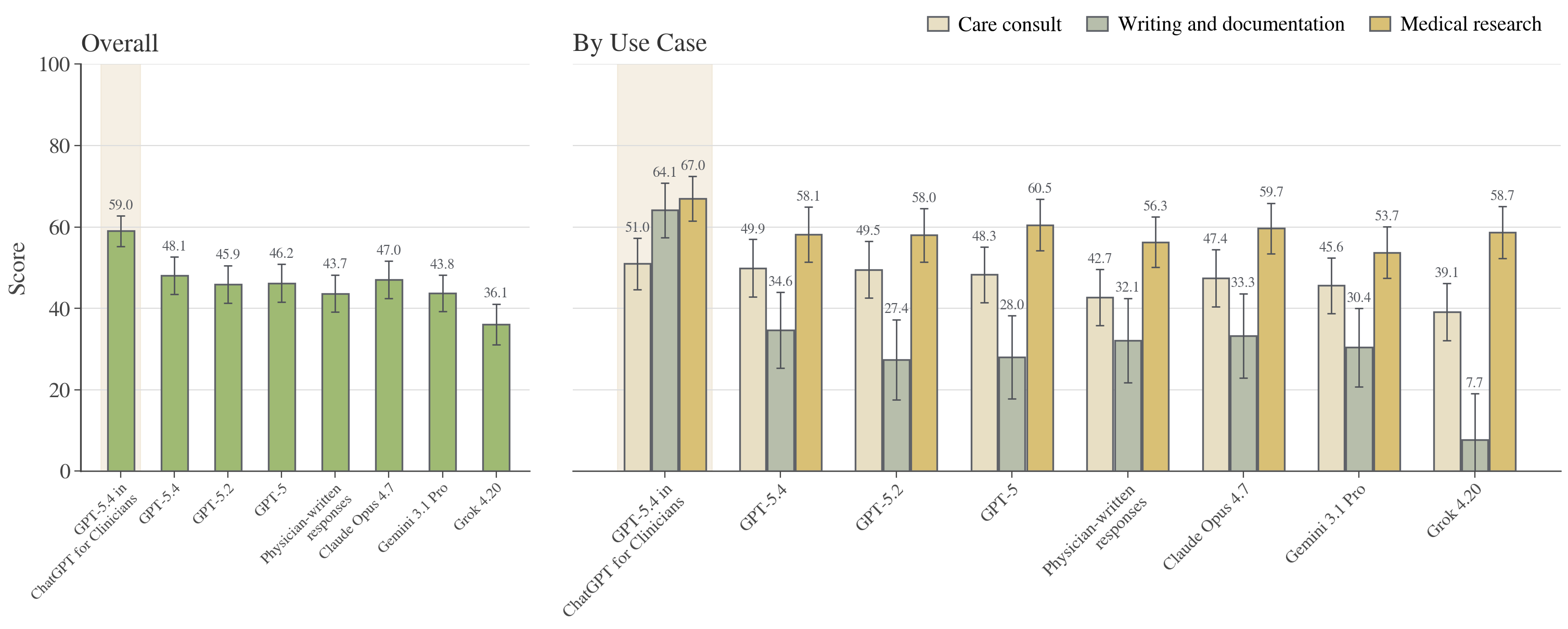
Figure 4: HealthBench Professional scores, overall (left panel) and by use case (right panel), across frontier models and physician baselines. Each bar decomposes global and per-use-case performance.
Key findings:
- ChatGPT for Clinicians (GPT-5.4 harness) achieved the top overall benchmark score (59.0), outperforming both physician baselines (43.7; p=3.7×10−10) and other LLMs.
- It dominated especially in writing/documentation (64.1 vs 32.1 for physicians; p=1.2×10−8), substantially narrowing historical gaps between LLMs and clinical experts.
- In care consult (51.0 vs 42.7) and medical research (67.0 vs 56.3), LLMs scored statistically higher than physicians, though margins were narrower.
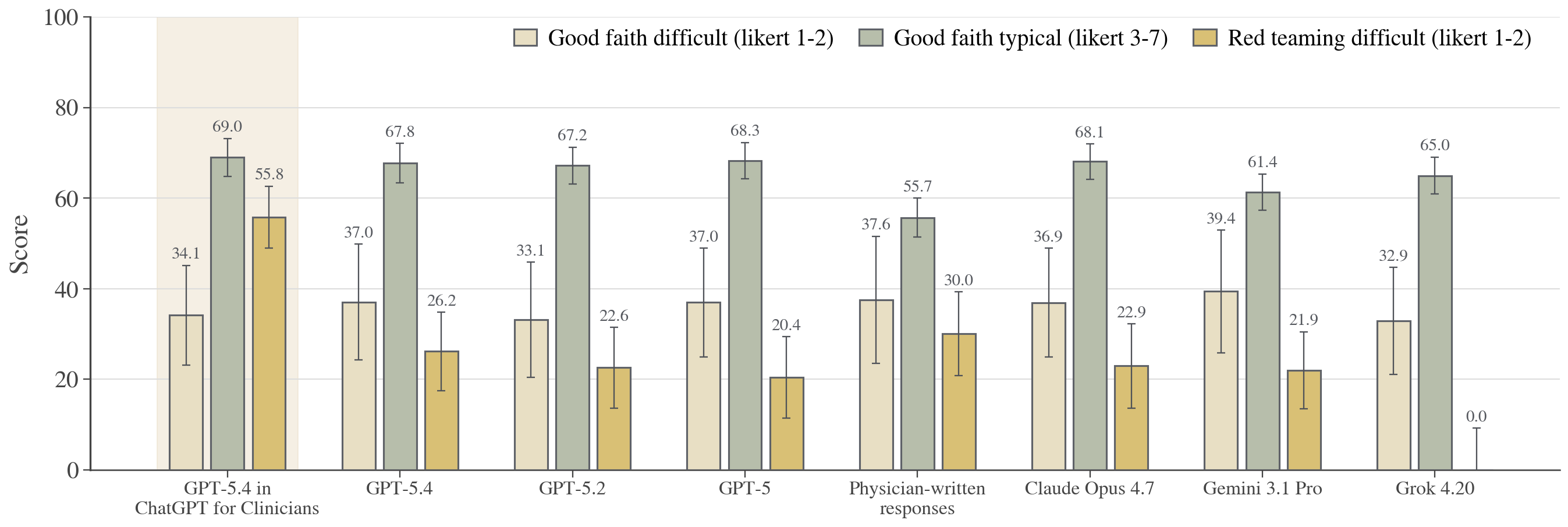
Figure 5: Scores by dataset slice—good faith typical/difficult and red teaming—illuminating LLM resilience in adversarial settings.
GPT-5.4 in ChatGPT for Clinicians maintained a decisive advantage on the most challenging red teaming subset (55.8 vs 30.0 for physicians, p=5.7×10−7) and showed marked gains over baseline GPT-5.4 in both adversarial and realistic, but hard, cases. In good faith typical tasks (routine, non-stress scenarios), the margin versus physicians, though significant, was less pronounced.
Specialty-Level Analysis
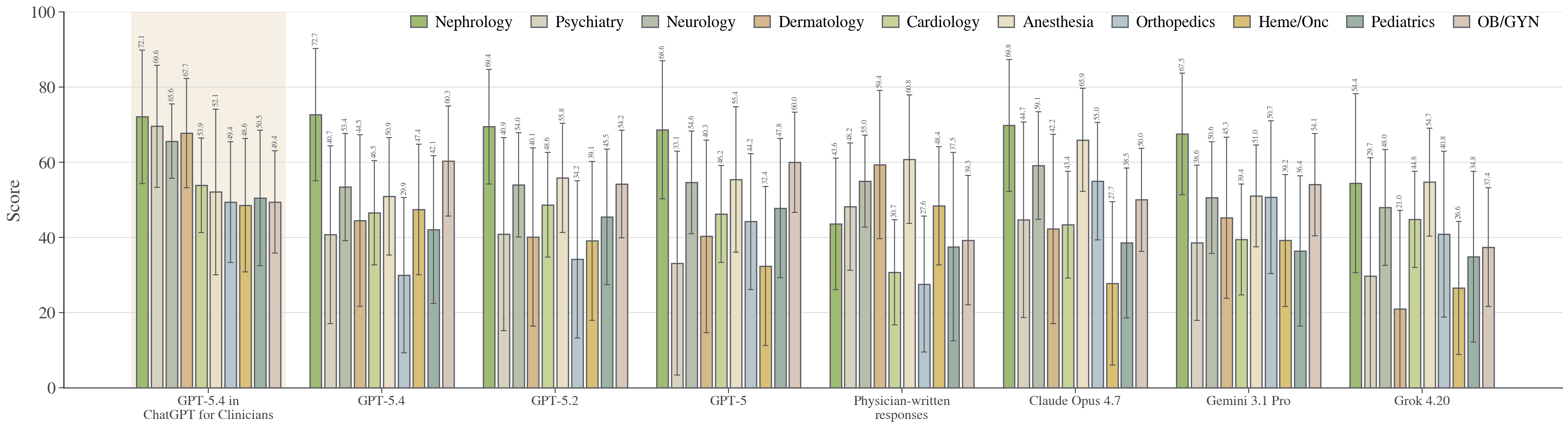
Figure 6: Performance decomposed by specialty (top 10), revealing generally broad LLM gains, with significant outperformance in nephrology and cardiology.
GPT-5.4 in ChatGPT for Clinicians was the top performer in 6 of the top 10 specialties, significantly outperforming in nephrology (72.1 vs 43.6) and cardiology (53.9 vs 30.7), with mixed or statistically indistinguishable results in other specialties. Specialty-level disparities are most evident in subfields highly reliant on structured reasoning or complex documentation tasks.
System Harness Comparisons
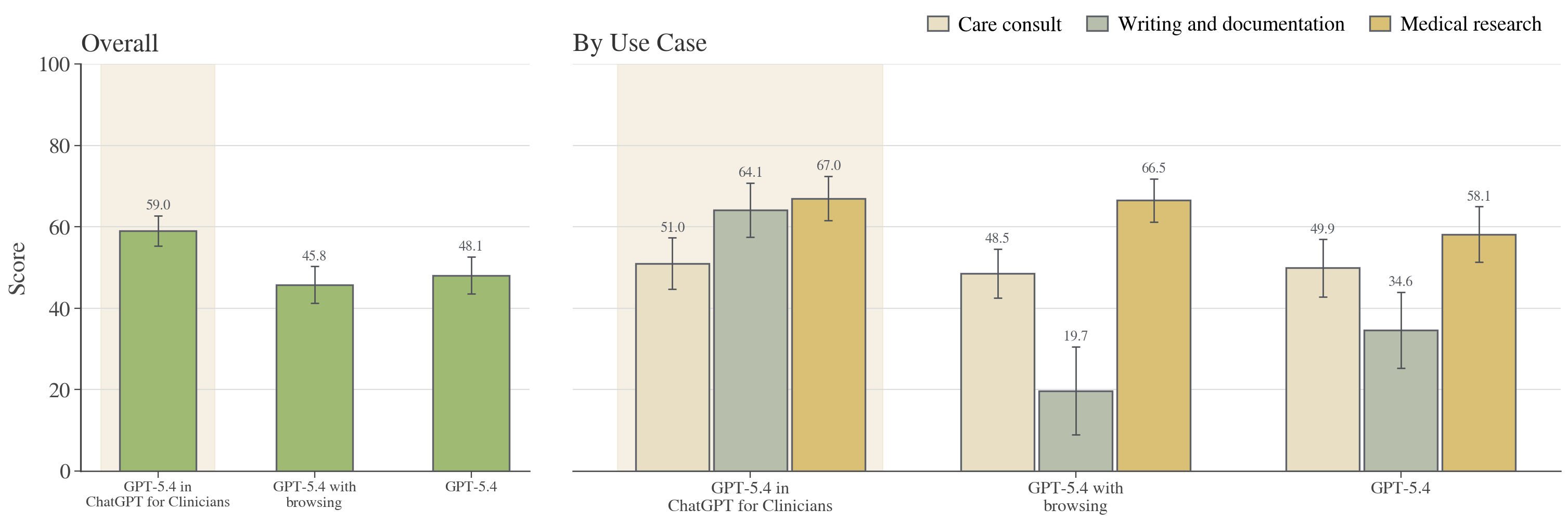
Figure 7: GPT-5.4 in ChatGPT for Clinicians surpasses base GPT-5.4 and GPT-5.4 with simple browsing, evidencing harness-induced gains.
Harness effects are substantial: ChatGPT for Clinicians' augmented model pipeline yields significantly higher scores than both base models and models scaffolded with browsing tools, particularly for documentation and research use cases.
Effects of Verbosity and Reasoning Effort
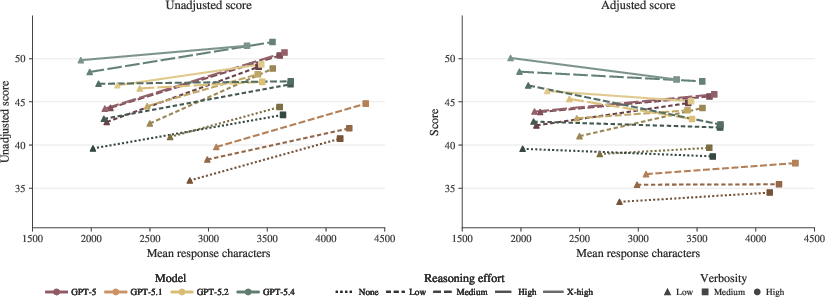
Figure 8: Length adjustment neutralizes spurious gains from verbosity; unadjusted scores rise with answer length, but adjusted scores yield a fairer cross-model comparison.
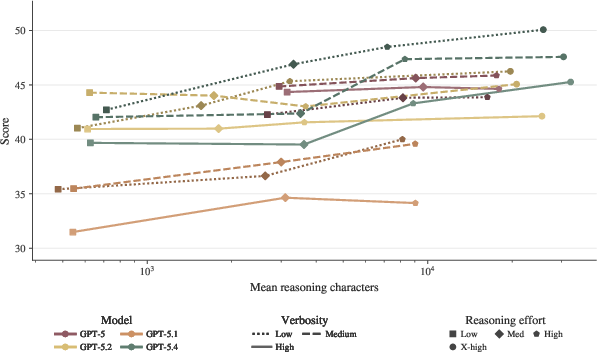
Figure 9: HealthBench Professional score as a function of reasoning characters. Increased reasoning effort correlates with higher quality after length adjustment.
Systematic verbosity increases produce higher unadjusted scores, but the main (adjusted) metric effectively debiases this trend, underscoring genuine content gains over superficial length. Higher reasoning effort at test-time incrementally improves adjusted scores, indicating that compute scaling translates to clinically meaningful improvements.
Implications and Future Directions
HealthBench Professional represents a critical advance in the clinical evaluation of LLMs. By grounding the benchmark in real clinician conversations, applying rigorous multi-stage physician review, and adversarially enriching for difficult tasks, the work provides a robust tool to discriminate between model generations and harnesses, even as typical-use performance saturates.
Implications include:
- Frontier LLMs, when paired with tailored product harnesses (e.g., ChatGPT for Clinicians), now systematically outperform human physicians in high-difficulty, multi-turn chat tasks pertaining to care, documentation, and research.
- Harness and system design, not just scaling or model choice, are critical for maximizing clinical value.
- Despite aggregate LLM gains, specialty- and slice-level heterogeneity persists, warranting domain-specific evaluation and deployment caution.
Theoretically, this benchmark validates rubric-based, automated physician-in-the-loop evaluations as reliable for high-stakes clinical NLP, supporting earlier findings that model-human grader concordance approaches inter-physician agreement [arora2025healthbench].
Future research avenues prompted by HealthBench Professional:
- Extension to institution-specific workflows, EHR-integrated tasks, and longitudinal case management.
- Evaluation of models on extended-duration, procedurally complex tasks and real clinical implementation feedback loops.
- Domain adaptation for low-resource specialties and non-English conversations, exploiting the dataset's diversity.
Conclusion
HealthBench Professional delivers a stringent, transparent, and challenging evaluation framework for LLMs in clinical chat scenarios. It establishes that, on adversarial and routine tasks requiring nuanced reasoning and documentation, modern LLM-based systems—properly harnessed—are now achieving or exceeding physician-level performance. This benchmark sets a new standard for future development and assessment of AI assistance in healthcare and provides actionable signals for model, system, and interface design improvements, as well as robust substrate for safety and trustworthiness analysis (2604.27470).

