Map2World: Segment Map Conditioned Text to 3D World Generation
Abstract: 3D world generation is essential for applications such as immersive content creation or autonomous driving simulation. Recent advances in 3D world generation have shown promising results; however, these methods are constrained by grid layouts and suffer from inconsistencies in object scale throughout the entire world. In this work, we introduce a novel framework, Map2World, that first enables 3D world generation conditioned on user-defined segment maps of arbitrary shapes and scales, ensuring global-scale consistency and flexibility across expansive environments. To further enhance the quality, we propose a detail enhancer network that generates fine details of the world. The detail enhancer enables the addition of fine-grained details without compromising overall scene coherence by incorporating global structure information. We design the entire pipeline to leverage strong priors from asset generators, achieving robust generalization across diverse domains, even under limited training data for scene generation. Extensive experiments demonstrate that our method significantly outperforms existing approaches in user-controllability, scale consistency, and content coherence, enabling users to generate 3D worlds under more complex conditions.



































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
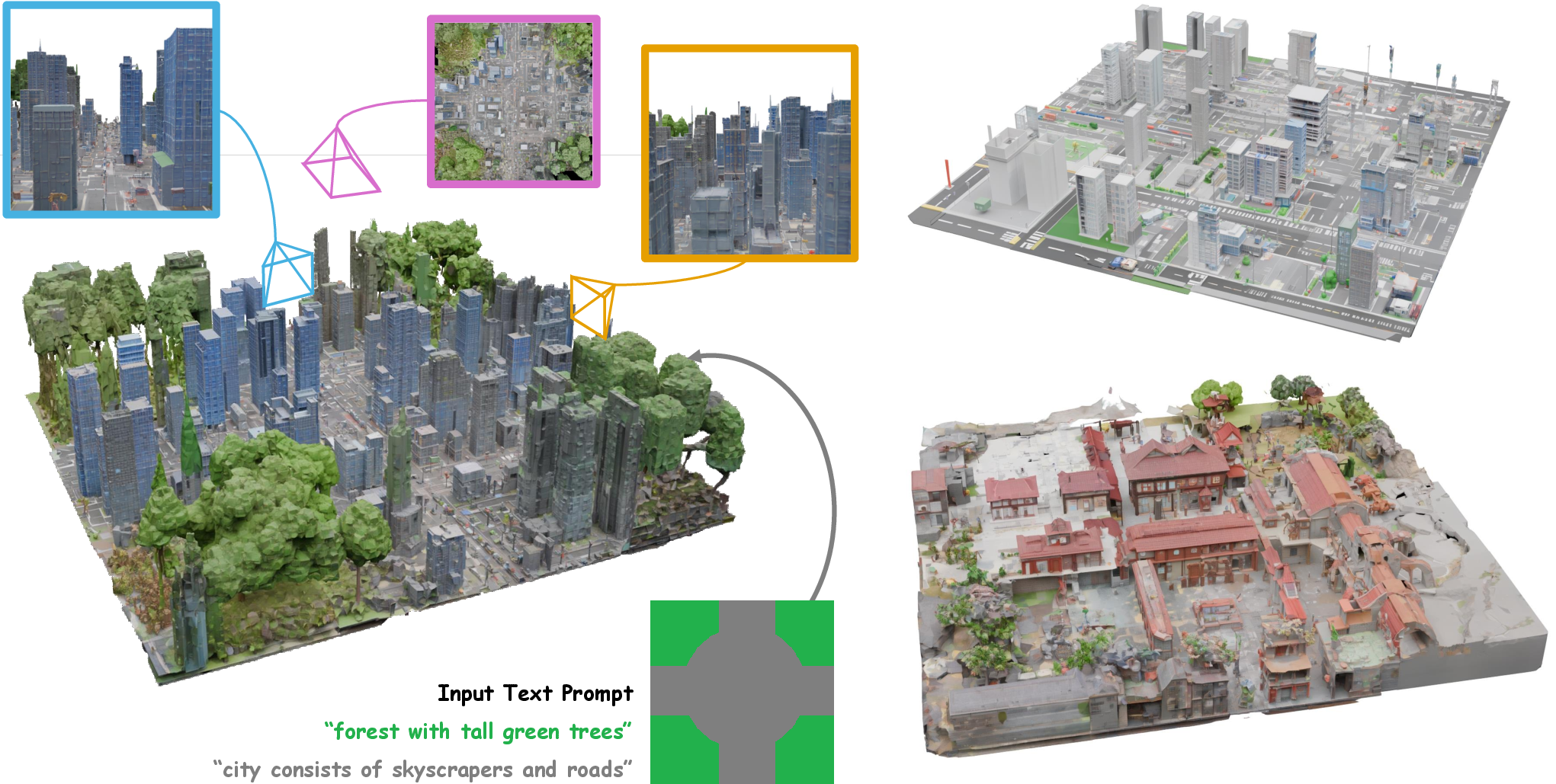
This paper introduces Map2World, a system that can create large 3D worlds from simple instructions. You give it a “segment map” (a map divided into regions) and a short text for each region like “forest,” “city center,” or “lake.” Map2World then builds a big, coherent 3D world that follows your map and descriptions, with objects that look the right size and connect smoothly across borders.
What questions is the paper trying to answer?
The researchers focused on three simple questions:
- How can we let people design 3D worlds by drawing regions on a map and labeling them with text?
- How can we make sure the whole world fits together nicely, with objects that are the right size everywhere and no awkward seams between parts?
- How can we get high-quality details without needing a huge amount of special training data?
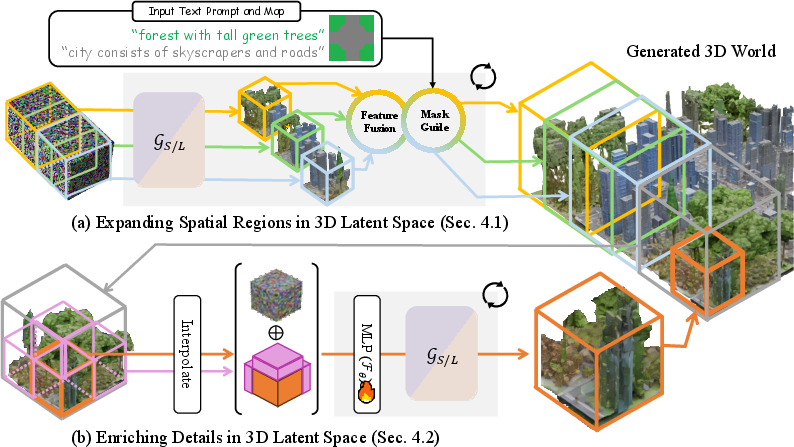
How does Map2World work?
Think of Map2World as a smart city builder that follows a plan, works in small sections, and then adds decorations to make everything look great.
1) Planning with a segment map
- A “segment map” is like a coloring book page where each colored area means something different, e.g., green for forest, gray for city, blue for water.
- You also give a short text for each area, like “dense pine forest” or “modern skyscraper district.”
- Map2World uses this as the layout plan for the whole world.
2) Building the world piece by piece
- The system builds the world in small 3D cubes, like making a patchwork quilt from squares.
- These cubes overlap and are blended carefully so there aren’t visible seams or gaps.
- This “overlapping cubes” idea is inspired by image generation tricks that make big pictures by stitching together smaller ones—but Map2World does it in 3D.
- Because the cubes overlap and share information, the world looks continuous and objects keep a consistent size across the entire scene.
3) Keeping sizes consistent from the start
- 3D generation usually starts from random noise (like TV static) and gradually turns it into a scene.
- The team tweaks that starting “noise” so buildings, trees, and roads come out at consistent sizes throughout the whole world. You can think of it as setting the “scale” before drawing, so houses don’t look giant in one place and tiny in another.
4) Adding fine details with a “detail enhancer”
- After the basic world is laid out, a special “detail enhancer” adds small, realistic features—like textures, fine geometry, and extra richness.
- It works a bit like image “super-resolution,” where a blurry image is made sharper. Here, a coarse 3D section is split into eight smaller parts, and the model predicts more detailed “codes” for each smaller part.
- It uses two kinds of hints:
- The coarse “code” for the larger area (to keep the big structure consistent).
- Neighboring parts (so edges match and things connect smoothly across borders).
- This is done in a way that reuses a powerful object generator’s knowledge, so the model doesn’t need tons of new training data.
5) Turning the “secret code” into 3D
- Inside, the system represents the scene using a compact “secret code” (called a latent). You can think of this as a recipe for the 3D world.
- A decoder turns this code into a visible 3D scene. The team lightly fine-tunes this decoder so it works well on partial scenes, not just complete objects.
- The final 3D is rendered using a method called 3D Gaussian splatting, which you can imagine as painting the world using lots of tiny, soft dots to make smooth, fast-rendered visuals.
What did the researchers find, and why is it important?
Based on examples and evaluations, Map2World:
- Handles any region shapes, not just square tiles. This is more like how real maps look and gives users much more control.
- Keeps object sizes consistent across the whole world. Buildings in one area won’t suddenly look huge next to tiny ones in a neighbor area.
- Creates smooth transitions between regions. Forests can blend into cities cleanly, without unnatural breaks.
- Produces richer, more complete worlds than previous methods that simply place separate objects on a grid and try to blend them later.
- Scores higher on quality metrics that judge the sharpness, completeness, coherence, and realism of the generated worlds.
These improvements mean users can design bigger, more natural-looking scenes that feel like one continuous world, not a bunch of disconnected chunks.
Why does this work matter?
- For games, movies, virtual reality, and simulations (like self-driving car training), making realistic, large-scale 3D environments is time-consuming and expensive. Map2World makes this faster and more controllable.
- It reduces the need for giant training datasets by smartly reusing knowledge from strong object generators and blending results cleverly.
- It gives creators an intuitive way to direct the world—draw a map, label each region, and let the system produce a coherent 3D environment with consistent scale and detail.
In short, Map2World brings us closer to easy, flexible, and high-quality 3D world creation: you sketch the plan, write a few words, and the system builds a believable world that matches your idea.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up research.
- Conditioning dimensionality and semantics
- The segment “map” appears effectively 2D (top-down) with no explicit support for heightmaps, elevation constraints, or fully 3D segmentation volumes; how to condition world generation on volumetric labels, height/elevation maps, or layered vertical semantics is not addressed.
- No mechanism to encode topology-aware constraints (e.g., continuous roads/rivers across segments, intersections, drivable surfaces) beyond free-form semantic regions; how to enforce functional validity remains open.
- Scale control and units
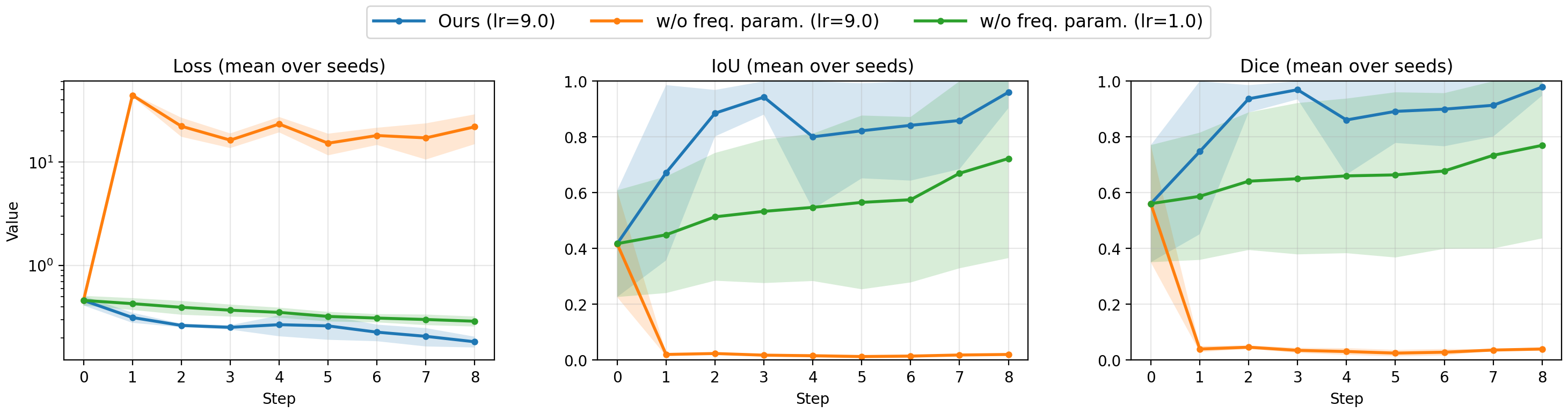
- Scale-aware initial latent optimization steers outcomes empirically but does not provide a user-facing, unit-calibrated scale control (e.g., meters); mapping prompts or parameters to absolute, repeatable spatial scales is unresolved.
- Sensitivity of scale optimization to hyperparameters (learning rate, step count), target definitions, and world sizes is not characterized; robustness and reproducibility across seeds and scenes are unknown.
- Latent fusion limits
- The multi-window velocity fusion uses a local Gaussian-weighted averaging; long-range dependencies and global constraints are not modeled, raising questions about consistency over very large distances (e.g., city-scale worlds).
- Boundary behavior: the time-varying Gaussian smoothing of segment masks can cause semantic bleeding at thin/narrow regions; no analysis of failure rates, hard-boundary enforcement, or boundary-aware alternatives.
- Detail enhancer capacity and generality
- The enhancer is a lightweight MLP prepended to frozen TRELLIS transformers; capacity limits for capturing high-frequency details in dense, complex scenes are not measured; comparison to stronger super-resolution or refinement baselines is missing.
- Detail enhancement is demonstrated for a single 2× split (eight subcubes) and one recursion step; scalability to multi-level recursive upscaling, stability across multiple refinements, and error accumulation are not explored.
- Auto-regressive enhancement uses previously generated neighbors; compounding errors, drift, and artifact propagation across deep hierarchies of cubes remain unquantified.
- Decoder fine-tuning side effects
- Decoder fine-tuning uses small cubes from a limited dataset; potential biases or catastrophic forgetting for object-centric generation or for domains outside the training set are not evaluated.
- Impact on other 3D representations (e.g., meshes vs 3DGS) and on downstream tasks (e.g., physics, collision, path planning) is not studied.
- Dataset and domain coverage
- Training for the detail enhancer relies on only 35 Objaverse scenes (filtered by NuiScene43); domain diversity, category coverage, and generalization to indoor, natural, or highly stylized worlds are uncertain.
- No evidence the method handles out-of-distribution prompts (rare styles, non-photorealistic domains) or complex, mixed-domain maps beyond qualitative examples.
- Evaluation gaps
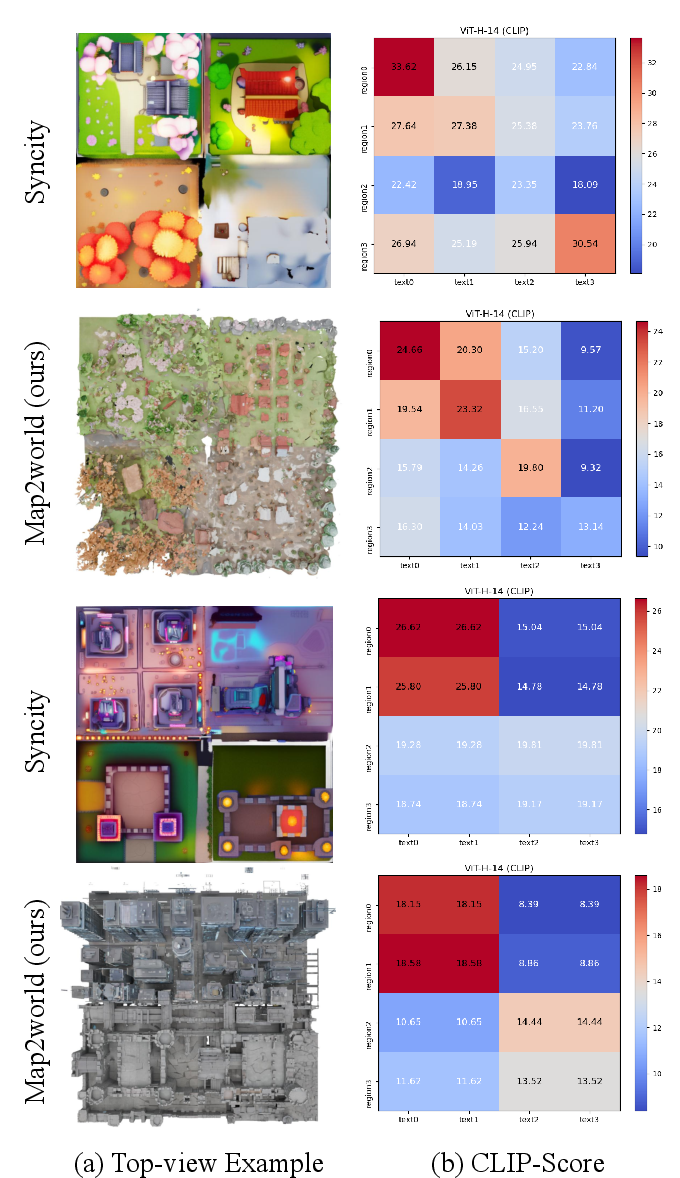
- No quantitative measurement of segment-to-world alignment (e.g., IoU between input segment regions and generated occupancy/semantic labels); fidelity to user maps is assessed only visually.
- World-scale 3D metrics are absent (e.g., connectivity, hole rate, intersection-free geometry, manifoldness, density uniformity); only image-based and LLM-based scores are reported.
- The proposed World Quality (WQ) metric depends on GPT-based judgments without a human study or inter-rater validation; reproducibility, calibration, and bias of GPT-based evaluation are not assessed.
- No ablation on the Gaussian kernel choice, window overlap, or fusion weighting in rectified-flow space; alternative fusion strategies (e.g., learned fusion, cross-window attention) are not compared.
- Computational efficiency and scalability
- Inference time, GPU memory footprint, and scaling behavior with scene extent and window count are not reported; feasibility for kilometer-scale or city-scale environments is unclear.
- The cost and latency impact of initial noise optimization and multi-window fusion for large canvases remain unspecified.
- Controllability beyond segment labels and text
- The system lacks fine-grained control over object counts, placements, orientations, or layout graphs within segments; integrating vector GIS inputs (roads, parcels, building footprints) is not explored.
- No mechanism to enforce hard constraints (e.g., reserved empty zones, protected corridors) or to lock unchanged regions during partial edits.
- Physical and functional validity
- Worlds are evaluated visually, not for functional realism (e.g., drivable roads, traversability, accessibility, traffic rules) required by simulation use cases.
- No global illumination or lighting consistency controls; how lighting/material coherence is maintained across fused regions is unclear.
- Interactivity and editability
- Incremental editing (e.g., modifying one segment after initial generation) and local re-synthesis without degrading global consistency are not demonstrated.
- History-aware or session-based controls for interactive world design are not addressed.
- Representation and export
- Focus is on 3D Gaussian Splatting; producing watertight, manifold meshes suitable for physics, collision, or game engines (Unreal/Unity) is not shown; asset export pipelines are unspecified.
- Texture/material parameterization for consistent rendering across engines is not evaluated.
- Robustness and failure analysis
- Failure cases (e.g., thin structures at boundaries, extreme aspect ratios, highly fragmented maps) are not reported; conditions that cause degeneracies or artifacts are unknown.
- Effects of disabling CFG on prompt adherence and semantic accuracy are not quantified; trade-offs between guidance strength and stability are not characterized.
- Ethical and safety considerations
- The method inherits biases and limitations from TRELLIS and text models; analysis of biased content, misuse risks, or safety controls for prompt filters is absent.
- Reproducibility and release
- Details on code, model weights, training data curation, and evaluation protocols (especially GPT-based scoring prompts and settings) are insufficient for full replication.
These gaps highlight opportunities for future work on principled scale control, boundary-robust fusion, richer conditioning (GIS/topology/3D volumes), objective 3D evaluations, computational scalability, interactive editing, physically valid layout generation, and mesh-ready outputs for real-world applications.
Practical Applications
Immediate Applications
Below is a concise set of deployable, real-world uses that can leverage Map2World’s current capabilities (segment-map–conditioned text-to-3D generation, latent fusion for global coherence, and the detail enhancer), together with suggested tools/workflows and feasibility notes.
- Game development and immersive content previsualization (sectors: gaming, film/animation, VR/AR)
- Use case: Rapid level “greyboxing” and previsualization by sketching a 2D segment map and assigning per-region prompts (e.g., “dense forest,” “medieval town,” “river delta”), producing a coherent 3D world for early design and blocking.
- Tools/workflows:
- A DCC/editor plugin (e.g., Unreal/Unity) that accepts a 2D segment mask + text prompts, runs Map2World, exports assets as mesh/point-based scenes (via TRELLIS decoders for mesh/3DGS), and auto-generates collision proxies.
- Iterative editing: update a segment or prompt → regenerate affected regions with latent fusion while preserving global scale/continuity; use the detail enhancer for local fidelity.
- Assumptions/dependencies:
- Requires access to the TRELLIS model and Map2World pipeline; GPU resources for multi-window latent fusion.
- Export to game-engine–friendly formats may require mesh conversion from 3DGS; quality depends on decoder fine-tuning and domain coverage.
- Synthetic data generation for perception (sectors: robotics, autonomous driving, computer vision R&D)
- Use case: Programmatically vary layouts (e.g., roads/sidewalks/vegetation zones) via segment maps to produce diverse scenes for training/benchmarking perception models (segmentation, depth, detection).
- Tools/workflows:
- Batch generation API that sweeps seeds, prompts, and scale-aware initialization to expand scene diversity; render multi-view images and depth for training.
- Integrate with CARLA/LGSVL/Isaac Sim via mesh export and basic drivable-surface tagging aligned to “road” segments.
- Assumptions/dependencies:
- Static world focus; no dynamic traffic/physics baked in.
- Labels are reliable at region level (segment map), not necessarily per-object; fine annotations may require post-processing or additional tooling.
- Architectural/urban design ideation and stakeholder communication (sectors: AEC, urban planning, public engagement)
- Use case: Early-stage massing/context studies from rough zoning/land-use segment maps with textual descriptors (e.g., “mixed-use mid-rise,” “urban park”), producing navigable 3D concepts to communicate design intent.
- Tools/workflows:
- GIS-to-segment-map adapter (e.g., import shapefiles/OSM land-use polygons → prompts) → Map2World → export to USD/GLB for stakeholder walk-throughs.
- Assumptions/dependencies:
- Conceptual only; geometry is not metrically accurate or code-compliant.
- Requires methodical scale control (provided by the initial-latent optimization) and careful prompt engineering to avoid mismatches.
- Education and training content creation (sectors: education, edtech, safety training)
- Use case: Rapid creation of virtual field-trip environments or practice worlds (e.g., “coastal ecosystem,” “mountain village”) from simple classroom-drawn maps.
- Tools/workflows:
- Web UI for drawing segment maps and prompts; one-click generation and VR export.
- Assumptions/dependencies:
- Content realism and appropriateness depend on prompts and base model priors; moderation/filters advisable for classroom use.
- Creative prototyping and storyboarding in 3D (sectors: creative studios, advertising, XR agencies)
- Use case: Produce quick, navigable 3D mood boards from storyboard segment maps (e.g., “futuristic skyline” adjacent to “desert outskirts”).
- Tools/workflows:
- Map2World baked into a studio pipeline; export multi-view renders, camera paths, and roaming video.
- Assumptions/dependencies:
- Not production-final: geometry/texture quality varies by domain; detail enhancer improves fidelity but may still require manual art pass.
- Research on 3D generative models and benchmarking (sectors: academia, corporate R&D)
- Use case: Study large-scene coherence, latent fusion strategies in 3D, and scale-aware initialization; generate controlled benchmarks by varying segment layouts and prompts.
- Tools/workflows:
- Open scripts to reproduce segmentation-conditioned generations, ablation on smoothing kernels, and decoder fine-tuning.
- Assumptions/dependencies:
- Reproducibility requires access to TRELLIS weights and the curated training cubes; GPU availability for large scenes.
- Rapid environment backdrops for product visualization (sectors: e-commerce, marketing)
- Use case: Generate non-specific, thematic environments (e.g., “minimalist showroom,” “urban loft district”) as backdrops for product shots.
- Tools/workflows:
- Segment maps to define zones (stage, audience, street), text prompts for style, export for render farms.
- Assumptions/dependencies:
- Style consistency depends on prompt quality and training priors; legal vetting for commercial use of generated visuals may be needed.
Long-Term Applications
The following opportunities require further research, scaling, integration, or validation before broad deployment.
- City-scale digital twins from GIS and land-use data (sectors: urban planning, smart cities, infrastructure)
- Vision: Convert large, irregular GIS layers (zoning, parcels, land cover) into text-conditioned segment maps to generate coherent, city-scale 3D worlds that serve as preliminary “look & feel” digital twins.
- Potential products:
- GIS-to-3D “Concept Twin” service that maps administrative labels to style prompts (“historic rowhouses,” “industrial waterfront”) and generates navigable prototypes.
- Dependencies/assumptions:
- Needs high-fidelity metric accuracy and validated scale calibration; integration with procedural rules, CAD/BIM, and regulatory constraints.
- Must incorporate dynamic elements (traffic, pedestrians) and physics for simulation utility.
- Scenario-at-scale simulation for AV/robotics safety (sectors: autonomous mobility, robotics, insurance, regulators)
- Vision: Automated generation of vast, variable driving and navigation scenarios from templated segment maps (road types, junctions, sidewalks, occlusions), with consistent global scale and style.
- Potential products:
- “Scenario bank” generator embedding Map2World with traffic agents, weather/time-of-day variation, and sensor simulators.
- Dependencies/assumptions:
- Requires dynamic agent models and physics; strict realism validation and regulatory acceptance of synthetic data for safety-critical training/testing.
- Co-creative, constraint-aware world-building tools (sectors: gaming, film, virtual production)
- Vision: Interactive tools that combine segment-map guidance with learned constraints (e.g., accessibility, narrative beats, gameplay metrics) for on-the-fly regeneration of sections without breaking global coherence.
- Potential products:
- World editors that round-trip between human edits and constrained regeneration; style-locking and version control for iterative pipelines.
- Dependencies/assumptions:
- Needs incremental editing and fine-grained control over large assets; richer condition modalities (sketches, references, style tokens).
- Public participation platforms for urban policy and design (sectors: government, civic tech)
- Vision: Citizens sketch segment maps (e.g., “green corridor,” “mixed-use block”) and immediately explore a 3D world rendering of proposals to inform consultations and feedback loops.
- Potential products:
- Web-based co-design portals; scenario comparison with embedded environmental or mobility analytics.
- Dependencies/assumptions:
- Requires robustness to free-form inputs, strong content safety filters, and clear disclaimers (non-authoritative visuals).
- Domain-adaptive generation for specialized environments (sectors: healthcare, logistics, defense, energy)
- Vision: Generate specialized facilities (e.g., hospital layouts, warehouses, substations) conditioned on segment maps with domain-specific constraints and equipment catalogs.
- Potential products:
- Plug-ins that link to asset libraries and enforce compliance templates; rapid training environments for SOPs and emergency drills.
- Dependencies/assumptions:
- Requires extensive domain priors, validated asset libraries, and compliance-aware generation; current model priors may be insufficient.
- World-as-a-Service platforms for the “open metaverse” (sectors: XR, social platforms)
- Vision: On-demand, personalized worlds created from sketched layouts and prompts; users co-create spaces for events, learning, or social use.
- Potential products:
- Cloud APIs that generate and stream 3D worlds; style tokens, user moderation, and content governance.
- Dependencies/assumptions:
- Real-time or near-real-time generation requires major optimization; consistent moderation and IP compliance frameworks.
- High-fidelity, style- and era-conditioned reconstruction (sectors: cultural heritage, media)
- Vision: Reconstruct plausible historic or stylistic cityscapes from map sketches and textual descriptions (e.g., “1920s Art Deco district”).
- Potential products:
- Heritage visualization tools for museums and documentaries, with layered historic overlays.
- Dependencies/assumptions:
- Risk of hallucination and historical inaccuracies; needs curated priors, reference alignment, and expert oversight.
Cross-cutting dependencies and considerations
- Technical
- TRELLIS availability and licensing; Map2World’s dependence on high-end GPUs for large scenes.
- Engine integration: 3D Gaussian Splatting may require conversion to meshes/point clouds; exporters and decoders must be robust.
- Scalability: multi-window latent fusion scales memory/compute with area/volume; streaming or chunked generation needed for city scale.
- Static scenes today; dynamic entities and physics need integration for many simulations.
- Data, legal, and quality
- Priors learned from limited domains (detail enhancer trained on 35 scenes) can bias outputs; broader, curated datasets improve generalization.
- IP and licensing for training data; commercial deployments require clear provenance.
- Safety and content moderation for user prompts.
- Validation
- Metric gaps: perceptual and “world completeness” measures exist, but application-specific validation (e.g., AV safety, accessibility) requires new protocols.
- Scale calibration: the initial-noise optimization steers scale, but production use will need stronger, explicit metric controls.
These applications map directly to Map2World’s strengths—arbitrary-shaped segment conditioning, global coherence across large extents, and detail enhancement—while acknowledging where additional research, tooling, or validation is required for production-grade deployment.
Glossary
- 3D FFT: Three-dimensional Fast Fourier Transform; transforms a 3D signal into the frequency domain to stabilize and accelerate optimization. "using a 3D FFT."
- 3D Gaussian splatting (3DGS): A point-based 3D representation and rendering technique that uses Gaussian primitives for efficient view synthesis. "3D Gaussian splatting~\cite{kerbl20233d}"
- 3D latent space: The volumetric latent space where 3D scene features are represented and manipulated during generation. "Expanding Spatial Regions in 3D Latent Space"
- Active voxel: A grid cell marked as occupied/filled in a 3D grid representation, indicating presence of geometry or content. "the positional index of an active voxel"
- Autoregressive (auto-regressively): A generation approach where outputs are produced sequentially, each step conditioned on previously generated parts. "We auto-regressively estimate the structured latent of small cubes from index 0 to 7."
- Classifier-free guidance (CFG): A diffusion sampling technique combining conditional and unconditional predictions to steer generation toward prompts. "We note that we do not use classifier-free guidance (CFG)~\cite{ho2021classifierfree} when fine-tuning or sampling the model."
- Denoising trajectory: The sequence of latent states evolving over diffusion/flow time from noise to data. "we approximate the denoising trajectory by"
- Detail enhancer: A network module that enriches or upsamples fine-grained details in a generated 3D scene while preserving global structure. "we propose a detail enhancer network that generates fine details of the world."
- Flow matching loss: An objective for rectified flow models that aligns predicted velocity fields with ideal transport fields. "Then, the flow matching loss~\cite{lipman2023flow} is applied to fine-tune our model."
- Flow Transformer: A Transformer architecture that predicts velocity fields to transport latents from noise to data in rectified flow. "flow Transformer of the original model"
- Gaussian kernel (3D Gaussian kernel): A Gaussian weighting function used to smoothly fuse overlapping window predictions in 3D. "Using a shared 3D Gaussian kernel ,"
- Initial noise optimization: Adjusting the starting noise/latent to steer generation toward desired scales or constraints. "inspired by the idea of initial noise optimization~\cite{baek2025sonic}"
- Latent fusion: Combining predictions from overlapping latent windows to form a coherent, large-scale scene. "we present our latent fusion strategy to expand generation to a wider scene"
- Latent manifold: The low-dimensional space of valid latent codes learned by the model, capturing coherent structures/scales. "reside within TRELLISâs latent manifold"
- Monocular depth estimator: A model that predicts depth from a single image to lift 2D content into 3D. "with a monocular depth estimator."
- Multi-window diffusion frameworks: Methods that jointly denoise overlapping windows on a larger canvas to maintain global coherence and regional control. "Multi-window diffusion frameworks treat a large canvas as a collection of overlapping windows"
- Outpainting: Extending an image beyond its current borders using generative models to add new content. "The image is then outpainted, and the generated region is lifted and stitched"
- Radiance fields: Neural 3D representations mapping position and view direction to color and density for novel-view synthesis. "radiance fields~\cite{gao2023strivec}"
- Rectified flow model: A continuous-time generative framework that transports noise to data via learned velocity fields instead of stochastic diffusion. "based on the rectified flow model."
- Rectified-flow Transformers: Transformer modules implementing rectified flow for structure and latent prediction in 3D generation. "rectified-flow Transformers, $\bm{\mathcal{G}_S$ and $\bm{\mathcal{G}_L$."
- Segment map: A spatial map partitioning the world into labeled regions, each conditioned by a text prompt during generation. "Map2World supports 3D world generation conditioned by multiple text prompts with a segment map."
- Semantic maps: Maps specifying semantic labels across regions, used to guide conditional scene synthesis. "our approach can flexibly incorporate semantic maps as conditions"
- Signed 3D scalar field: A volumetric field where the sign indicates inside/outside occupancy; positive values mark filled (active) voxels. "a signed 3D scalar field where the voxels with positive values are filled with contents and called active."
- Sparse structure: The sparse set of occupied positions (and possibly features) within a 3D grid capturing coarse scene layout. "sparse structures exhibit different scene scales"
- Sparse-voxel-hierarchy: A multiscale data structure organizing occupied voxels sparsely to improve memory and scalability. "sparse-voxel-hierarchy~\cite{ren2024xcube}"
- Stop-gradient operator: An operator that prevents gradients from flowing through certain parts of a computation graph. "Here, $[\cdot]_{\mathrm{sg}$ denotes the stop-gradient operator."
- Structured latent (SLAT): A set of local latent vectors positioned on a 3D grid encoding jointly geometry and appearance. "The structured latent (or SLAT)~\cite{xiang2025structured} encodes geometry and appearance with a set of local latents on a 3D grid"
- Velocity field: A vector field that directs how latents move during rectified flow denoising toward the data manifold. "velocity field predictions "
- World Quality (WQ): A composite evaluation metric weighting sharpness, completeness, coherence, and realism for generated worlds. "World Quality (WQ), defined as"
Collections
Sign up for free to add this paper to one or more collections.

