- The paper introduces a latent-free, hierarchical model that transports raw voxel data through progressive flows from noise to detailed 3D scene textures.
- It employs conditional flow matching across coarse geometry and fine texture layers, overcoming challenges like quantization artifacts and mode collapse.
- Experimental evaluations show improved geometric regularity, rapid convergence, and explicit controllability in both outdoor and indoor 3D environments.
WorldFlow3D: Latent-Free Flow-Based Unbounded 3D World Generation
Introduction and Motivation
Unbounded 3D world synthesis is an essential task for spatial intelligence across computer vision, rendering, and autonomous driving. Existing object-level and scene-level generative models exhibit either limited scalability, domain specificity, or trade-offs between photorealistic texture and large-scale geometric fidelity. WorldFlow3D, introduced in "WorldFlow3D: Flowing Through 3D Distributions for Unbounded World Generation" (2603.29089), proposes a latent-free, fully volumetric generative model that formulates 3D scene synthesis as optimal transport through a hierarchy of data distributions—moving from pure noise, through causal coarse volumetric geometry, to fine-scale detail and scene appearance. This approach enables not only high-fidelity unbounded world generation but also explicit geometric and texture controllability without the representational and computational bottlenecks inherent to latent autoencoders.
Methodology
WorldFlow3D employs a flow-matching paradigm, where each stage in the hierarchical scene generation pipeline corresponds to an independently parameterized flow that transports the distribution from one volumetric representation to a more complex one. Specifically, the process begins with noise, flows through coarse geometry (using unsigned distance fields), then to fine geometry, and finally to volumetric texture. The model does not use explicit latent spaces; instead, the flows operate directly on raw voxels, avoiding quantization artifacts and the error accumulation seen in hierarchical latent-diffusion pipelines.
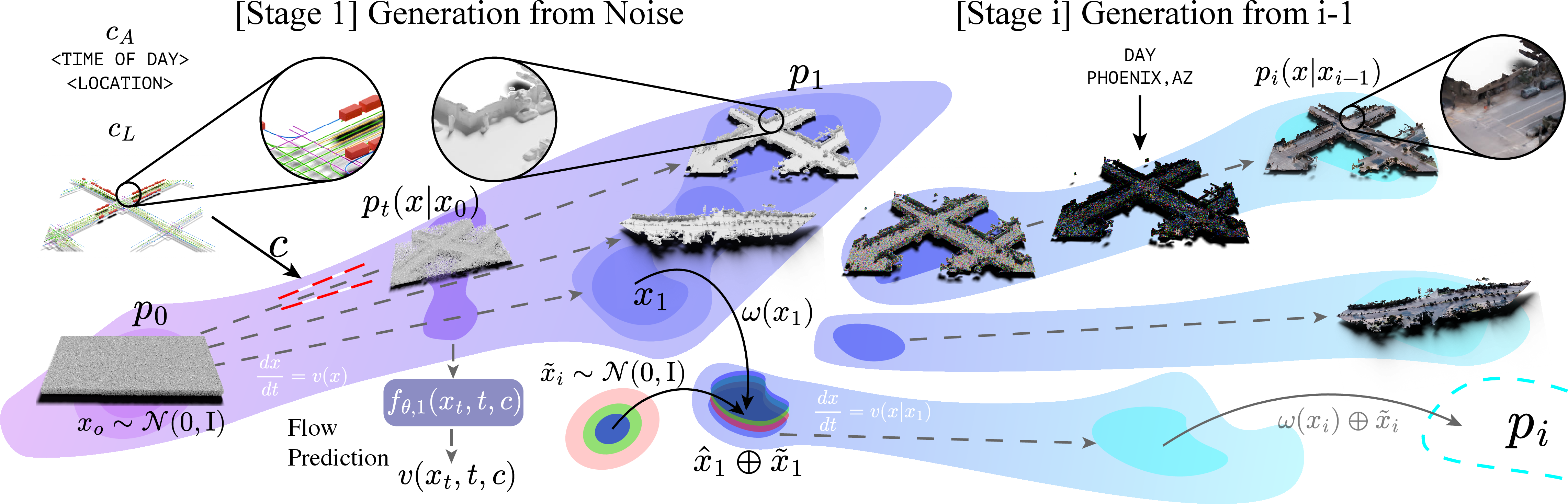
Figure 1: WorldFlow3D decomposes generation into a sequence of independent flows over progressively richer representations—transporting from noise, through coarse geometry into fine geometry, and visual appearance.
Flow Matching Between Hierarchical Distributions
At each generation hierarchy, a conditional flow is fit to transport between adjacent data spaces. The formulation allows independent alignment for each transition (e.g., noise to geometry, geometry to geometry, geometry to texture), using optimal transport-based continuous normalizing flows (CNFs), rectified flow objectives, and neural continuous-time vector fields. This hierarchical design addresses common failure modes in other models, such as structural collapse, texture-geometry misalignment, and mode collapse.
Unbounded Generation via Chunked Velocity Averaging
A crucial technical challenge is to enable the generation of scenes with unbounded spatial extent despite compute limitations. WorldFlow3D addresses this via chunked inference: overlapping 3D scene chunks are each modeled locally, and at each solver timestep, per-chunk velocities are feather-averaged with spatial ramps at borders. This imposes local consistency and avoids visible discontinuities at chunk boundaries.

Figure 2: Feather weighted velocity averaging in overlapping chunk regions significantly improves the generated geometry for unbounded generations.
Explicit Control in Geometry and Appearance
The framework supports structure and appearance controllability using vectorized scene graph layouts and global scene attributes (e.g., lighting, context). Geometric layouts are rendered into vector voxel representations, and appearance attributes are encoded and injected into each flow model. This enables both domain-agnostic geometric conditioning (e.g., maps, room boundaries) and semantic/appearance-level control.
Experimental Evaluation
Outdoor Scene Synthesis
WorldFlow3D was evaluated on the Waymo Open Dataset for urban-scale outdoor driving scenes. It significantly outperforms state-of-the-art baselines such as XCube, LT3SD, and LidarDM in coverage (COV), minimum matching distance (MMD), Jensen-Shannon divergence (JSD), and feature-based distributional similarity (e.g., Fréchet distance in Concerto space). The causal structure of buildings, roadways, and vehicles produced by WorldFlow3D exhibit superior geometric regularity and surface smoothness.
Figure 3: Qualitative comparison on outdoor scene generation with WorldFlow3D and baseline methods trained on the Waymo Open Dataset.
Indoor Scene Synthesis
For synthetic indoor environments (3D-FRONT), WorldFlow3D likewise achieves superior coverage, geometric fidelity, and appearance consistency compared to BlockFusion, WorldGrow, and latent tree-structured patch diffusion. The hierarchical, latent-free approach robustly models spatial layouts, surface smoothness, and object-level details.

Figure 4: Qualitative comparison on indoor scene generation with WorldFlow3D and baseline methods trained on the 3D-FRONT dataset.
Ablation: Hierarchical Flows and Latent-Free Design
Ablation studies demonstrate that standard latent-diffusion and latent-flow approaches produce degenerate or noisy outputs, failing particularly at fine details and structural regularity. Flows that skip intermediate distributions are less stable, and only the full hierarchical, latent-free design of WorldFlow3D yields plausible, diverse, and smooth 3D worlds.

Figure 5: Ablation of Core Components. Hierarchical, latent-free flow matching is uniquely able to produce high-quality, geometrically plausible 3D results.
Texture and Geometry Controllability
Conditioning experiments confirm that explicit controllability over both geometry (via maps or layout polylines) and scene appearance (via textural attributes) is robust. The same geometric context can yield multiple, semantically distinct environments, underscoring versatility.

Figure 6: Visual Texture and Controllability. The method supports large-scale outdoor scenes with controllable geometry and appearance.
Efficiency
WorldFlow3D demonstrates a 2x reduction in training time compared to autoencoder-based latent methods, converging to high-fidelity solutions within hours. There is no requirement for two-stage latent training, and model parameterizations enjoy direct spatial access to prior-level structure for faster convergence.
Human Perceptual Quality
Forced-choice user studies confirm a strong subjective quality advantage, with 88% win rate and significantly higher Bradley-Terry scores over state-of-the-art 3D generative baselines.
Implications and Future Directions
The volumetric, latent-free flow-matching paradigm demonstrated by WorldFlow3D sets a precedent for high-fidelity, controllable, and unbounded 3D world synthesis with rapid convergence characteristics. The theoretical implications are broad for generative 3D modeling: the results suggest that expressive, scalable scene generators can dispense with both hierarchical autoencoding and restrictive denoising paradigms. Practically, this enhances data generation for downstream perception, robotics, and simulation applications, especially where spatial scale and attribute controllability are crucial.
The flow-matching hierarchical framework further opens the door to extension in several directions, including richer scene attribute spaces, joint 4D/temporal flows for dynamic world synthesis, efficient outpainting, and extension to radiance field-based generation or view-consistent text-to-3D pipelines.
Conclusion
WorldFlow3D systematically advances large-scale 3D world generation through a latent-free, hierarchical optimal transport approach using conditional flows between volumetric data distributions (2603.29089). The model achieves superior geometric fidelity, attribute controllability, generalizability across domains, and training efficiency as demonstrated in extensive evaluations and human studies. The methodology establishes a non-latent baseline and a scalable algorithmic toolkit, useful for both scene-centric generative modeling and foundational world simulation in computer vision.

