- The paper proposes encoding probes that invert traditional decoding methods by regressing from interpretable features to neural activations, offering explicit quantification of feature contributions.
- It demonstrates that acoustic and phonetic features dominate variance in speech models while syntactic and lexical features are independently represented in text models.
- The study shows that controlling for feature correlations with encoding probes leads to clearer insights into representation variance and task-dependent model adaptations.
Encoding Probing in LLMs: Quantifying Feature Contributions and Correlations
Introduction
The interpretability of transformer-based models for speech and text remains a central research pursuit, especially given their rapidly growing complexity. Traditional approaches such as probing have primarily relied on decoding probes, which train classifiers or regressors to predict specific interpretable features from model hidden states. While this method can reveal if certain types of information (e.g., speaker identity, phonetics, syntax) are present and decodable from neural representations, it suffers from substantial limitations: (1) comparability across features is confounded by differing task difficulties and baseline rates, and (2) probe outcomes are highly sensitive to feature correlations. The paper "Beyond Decodability: Reconstructing LLM Representations with an Encoding Probe" (2605.00607) proposes a methodological shift by reversing the probing direction—constructing encoding probes that regress from interpretable features to internal model activations. This essay provides a detailed analysis of their approach, findings, and implications in the context of neural model interpretability.
Decoding Probes: Limitations
The canonical decoding probe f:X→Y framework, though widely adopted, offers only indirect and often ambiguous evidence about the structure and composition of neural activation patterns. First, the accuracy or R2 scores from decoding probes reflect both the amount of signal in the representation and the classification/regression hardness intrinsic to the target feature. For instance, interpreting relative decoding accuracies between speaker identity (with a small label set) and phone labels (with a larger, more complex label set) is intrinsically flawed (Figure 1).
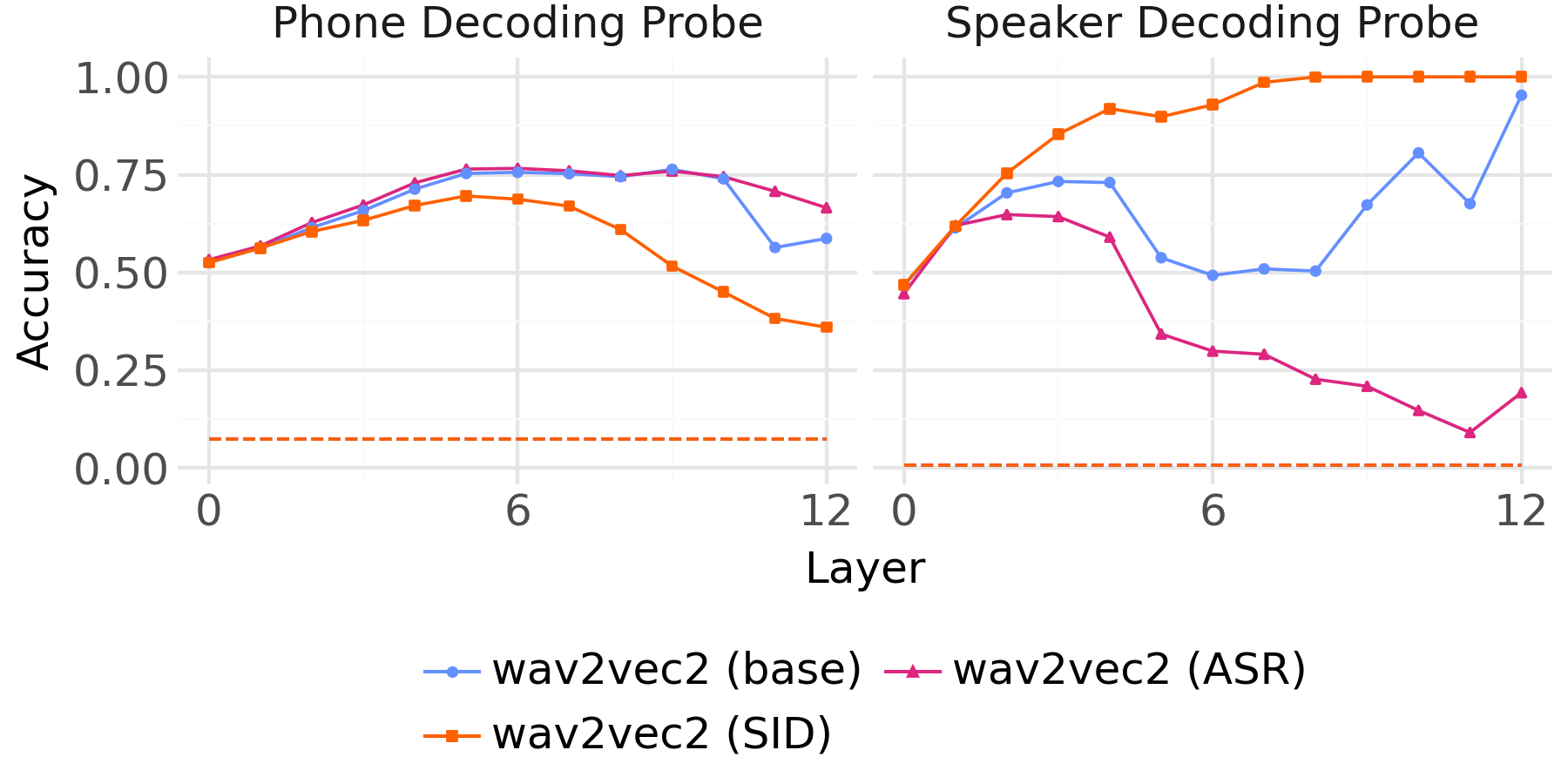
Figure 1: Accuracy of the Decoding Probe on predicting speaker identity and phone label from frames of model internal hidden states; baseline differences confound direct comparison.
Second, decoding probes conflate direct encoding with encoding-by-correlation: decodability can arise either from explicit encoding or via strong statistical association with other features (e.g., grammatical class by virtue of lexical identity). These issues severely limit causal interpretability and the quantification of relative feature contributions.
Encoding Probes: Methodology
Encoding probes invert the mapping, regressing from an ensemble of hand-crafted, interpretable features Y back to the neural activation X (g:Y→X). By performing systematic feature ablations (removing subsets of Y and quantifying the resulting change in reconstruction error), the encoding probe directly quantifies each feature's conditional contribution to the explained variance of the representation. This is formalized via Unexplained Variance (UV) or equivalently, 1−R2 scores for each target feature set ablation.
Critically, this approach supports:
- Direct, quantitative comparison of feature contributions: Since feature ablations are performed within the same regression setting and evaluation metric, differences in UV are meaningful even across heterogenous feature types.
- Explicit control for feature correlations: The inclusion and removal of multiple, potentially correlated, features allows the analysis to be sensitive to unique versus redundant information content in the representations.
The regressors are fit using Ridge regression, and all evaluations are carried out with rigorously sampled, stratified data splits on both spoken (wav2vec2, HuBERT, WavLM) and textual (BERT, RoBERTa, ModernBERT) model families.
Empirical Results
Speaker Identity in Speech Models
The encoding probe is first applied to disentangle the contributions of acoustics, phonetics, and speaker identity within the internal layers of wav2vec2 models trained under different objectives (self-supervised pre-training, ASR, speaker identification).
- For the base and ASR-tuned wav2vec2, ablating acoustic or phonetic features results in a much larger increase in UV than ablating speaker identity at every layer, indicating that acoustic and phonetic properties dominate the representational variance (Figure 2, Figure 3).
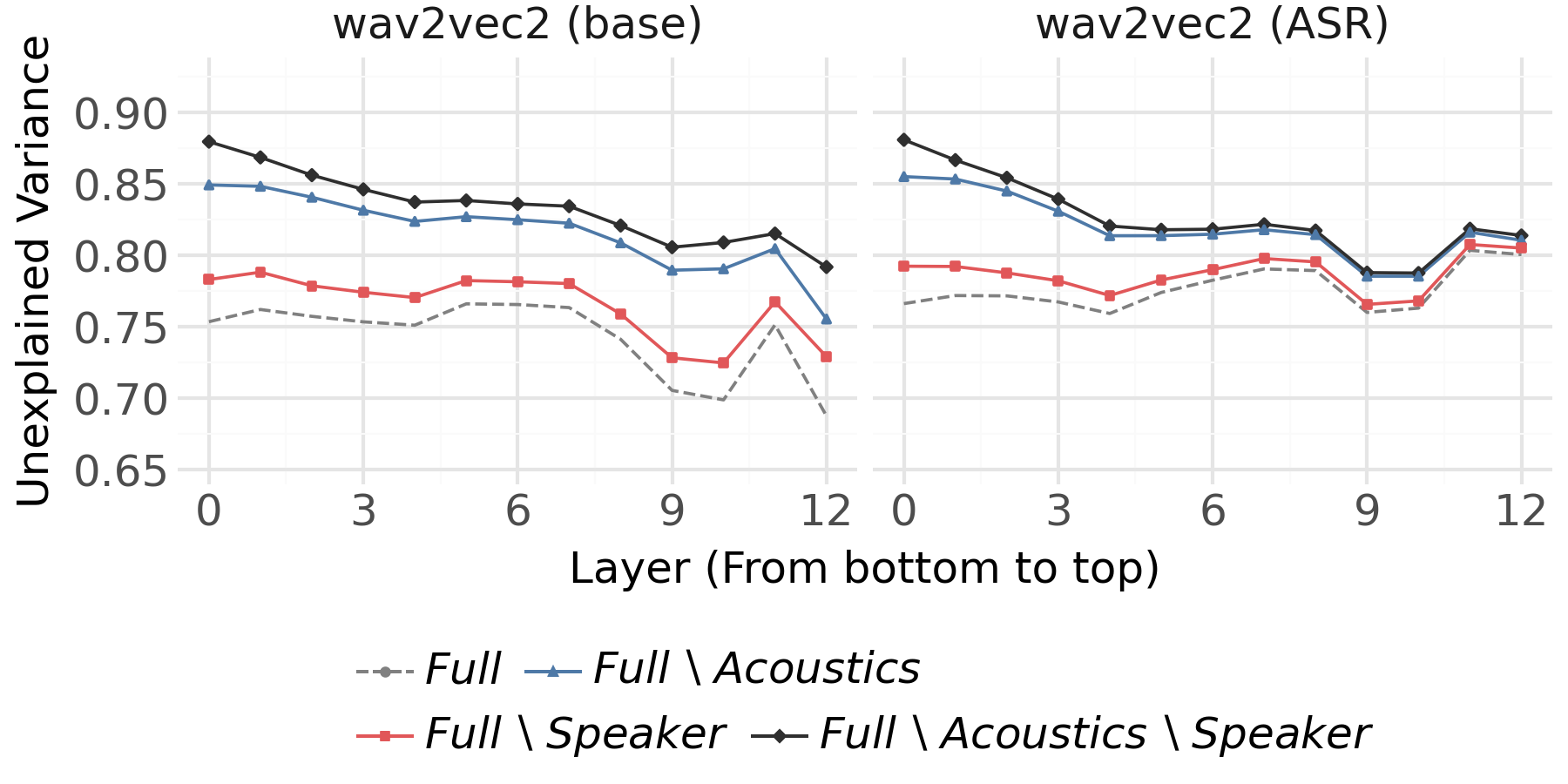
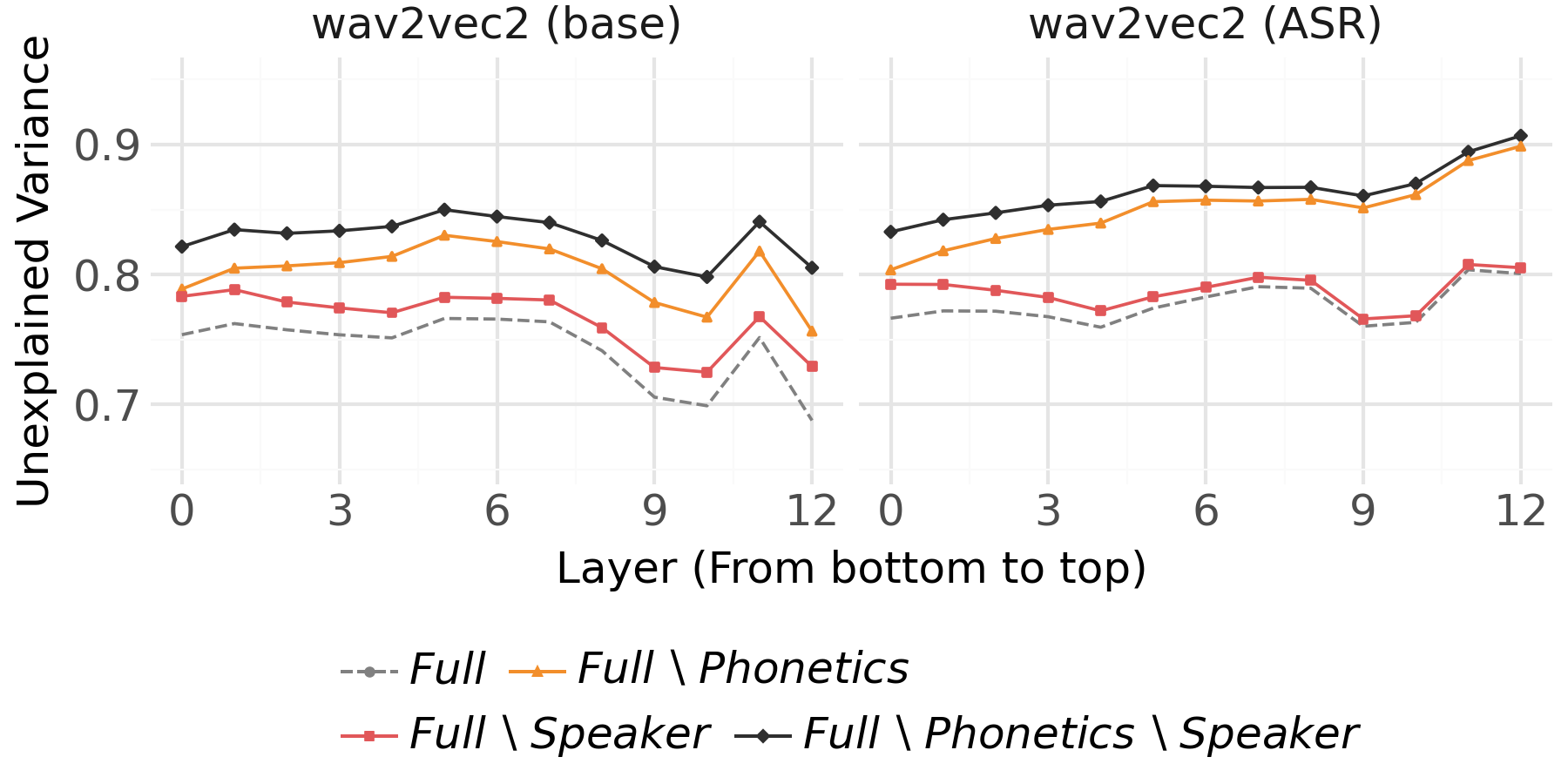
Figure 2: Unexplained variance (UV) for base and ASR wav2vec2 models by ablation of acoustics, speaker identity, and their combinations.
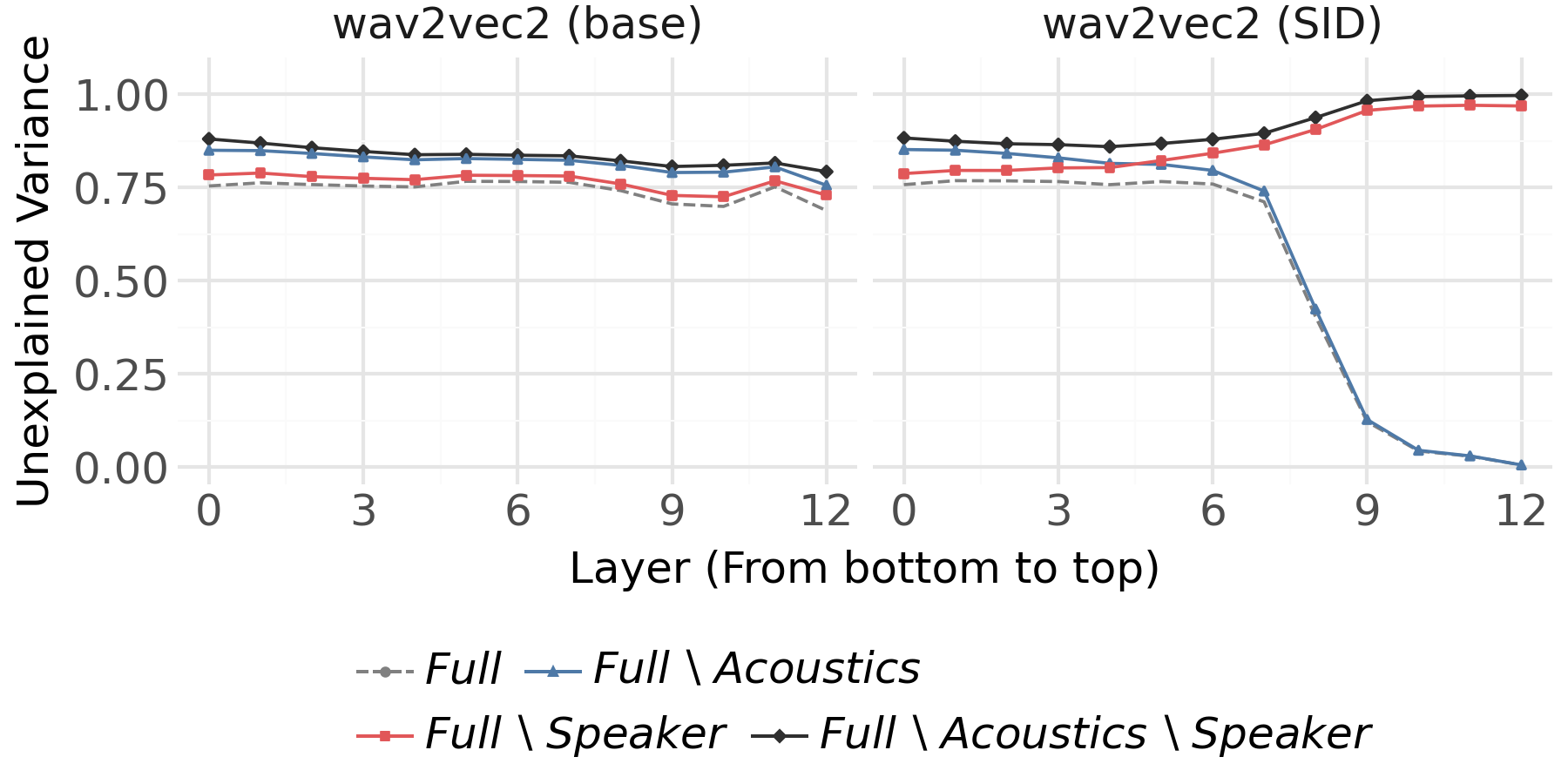
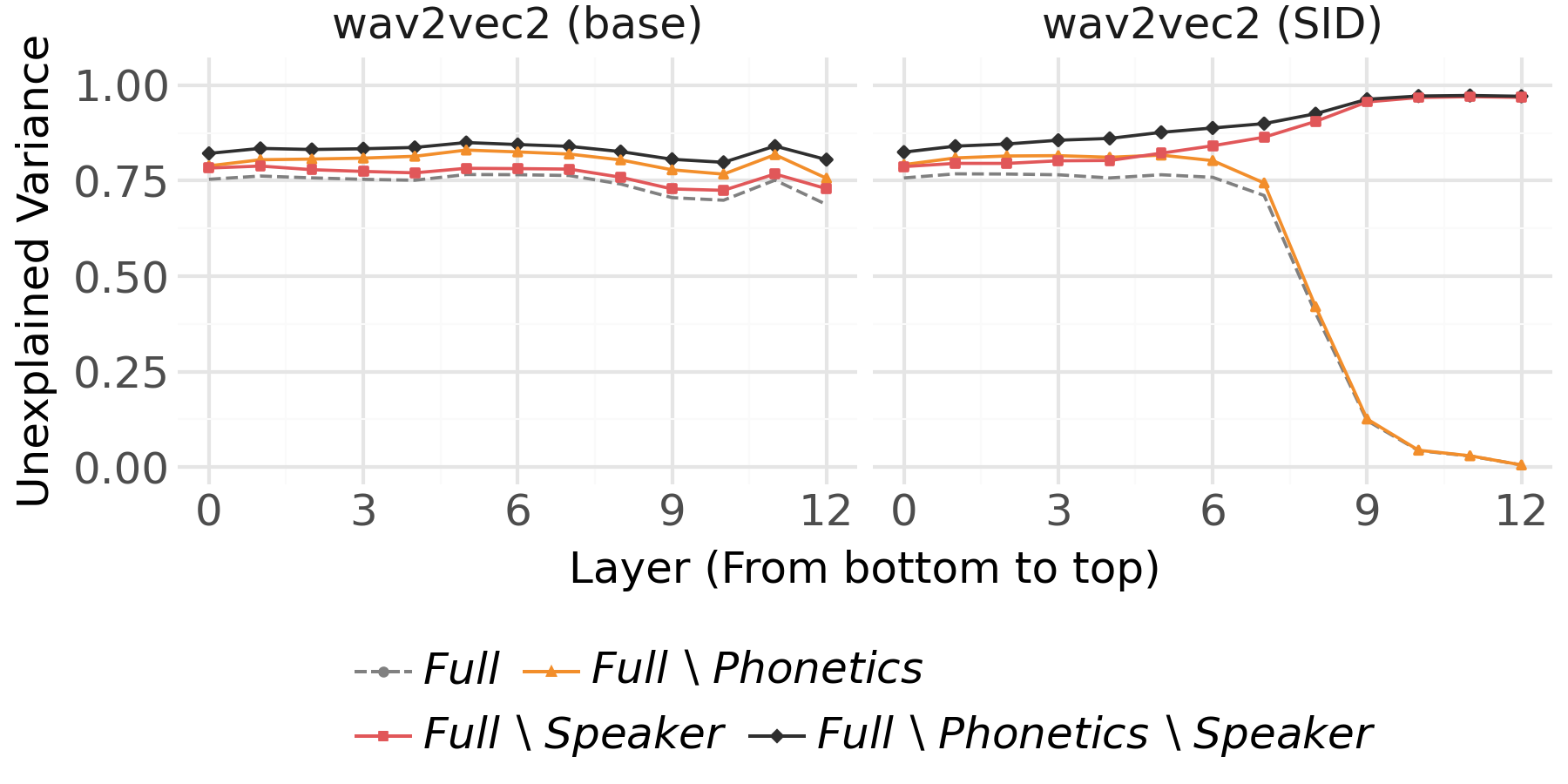
Figure 3: Unexplained variance (UV) for base and SID-tuned wav2vec2 models; top SID layers become highly specialized for speaker identity.
- In the SID-tuned variant, from roughly layer 7 onward, the relative contribution of speaker identity becomes overwhelming, accounting for nearly all the explained variance in upper layers, while the dependence on acoustics and phonetics vanishes.
These results reveal strong task-dependent adaptation of internal spaces: ASR-tuning suppresses speaker idiosyncrasies, enhancing phonetic discrimination, while SID-tuning discards virtually all information not predictive of speaker identity.
Decoding vs. Encoding Dynamics
A striking observation is the divergence between decodability and representational dominance: in the SID-tuned model's higher layers, speaker identity is not only decodable but also dominates the variance; for the ASR-tuned model, while speaker identity remains decodable above baseline, its contribution to variance is negligible. This underscores a key limitation of decoding-only analysis.
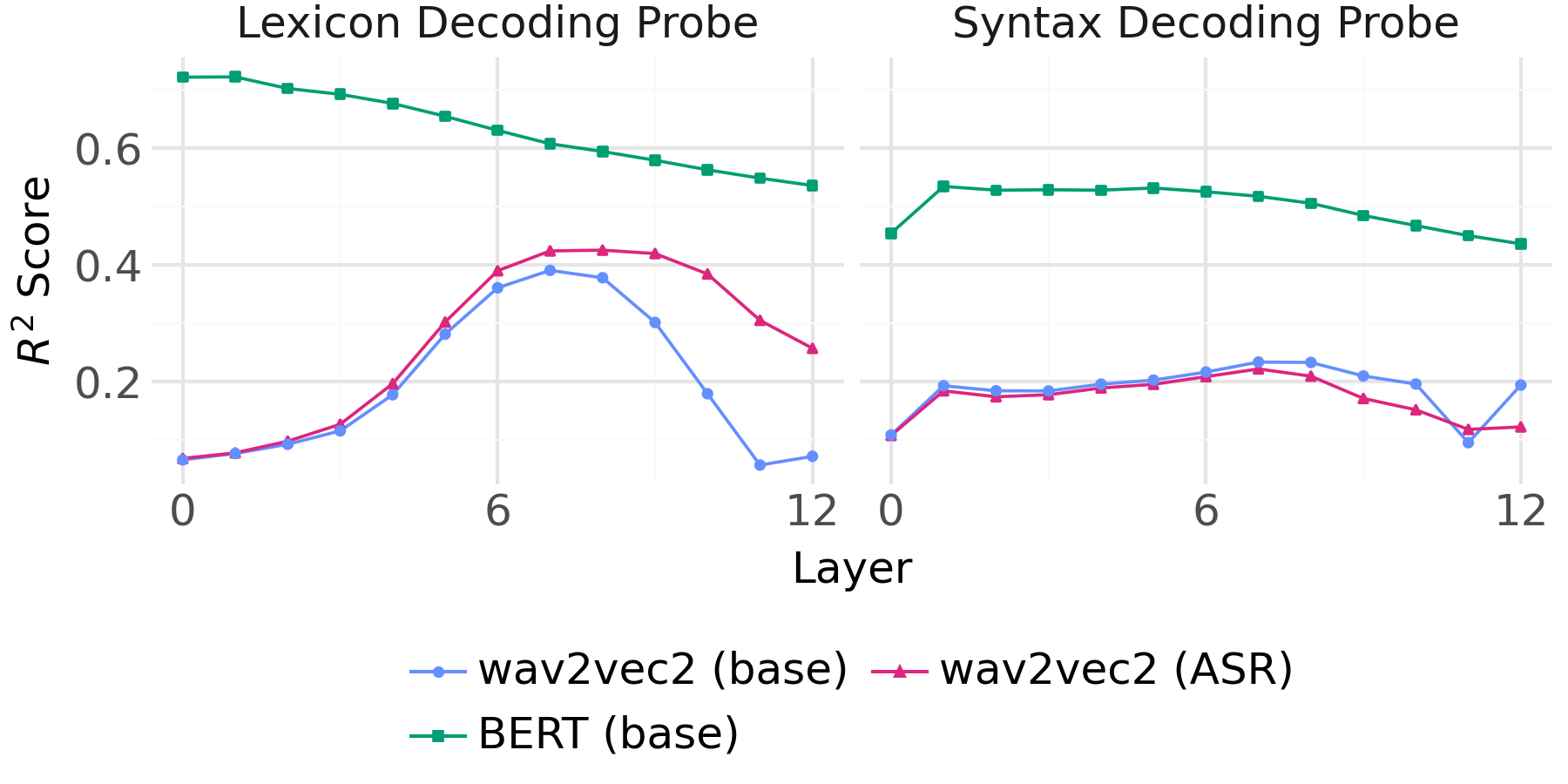
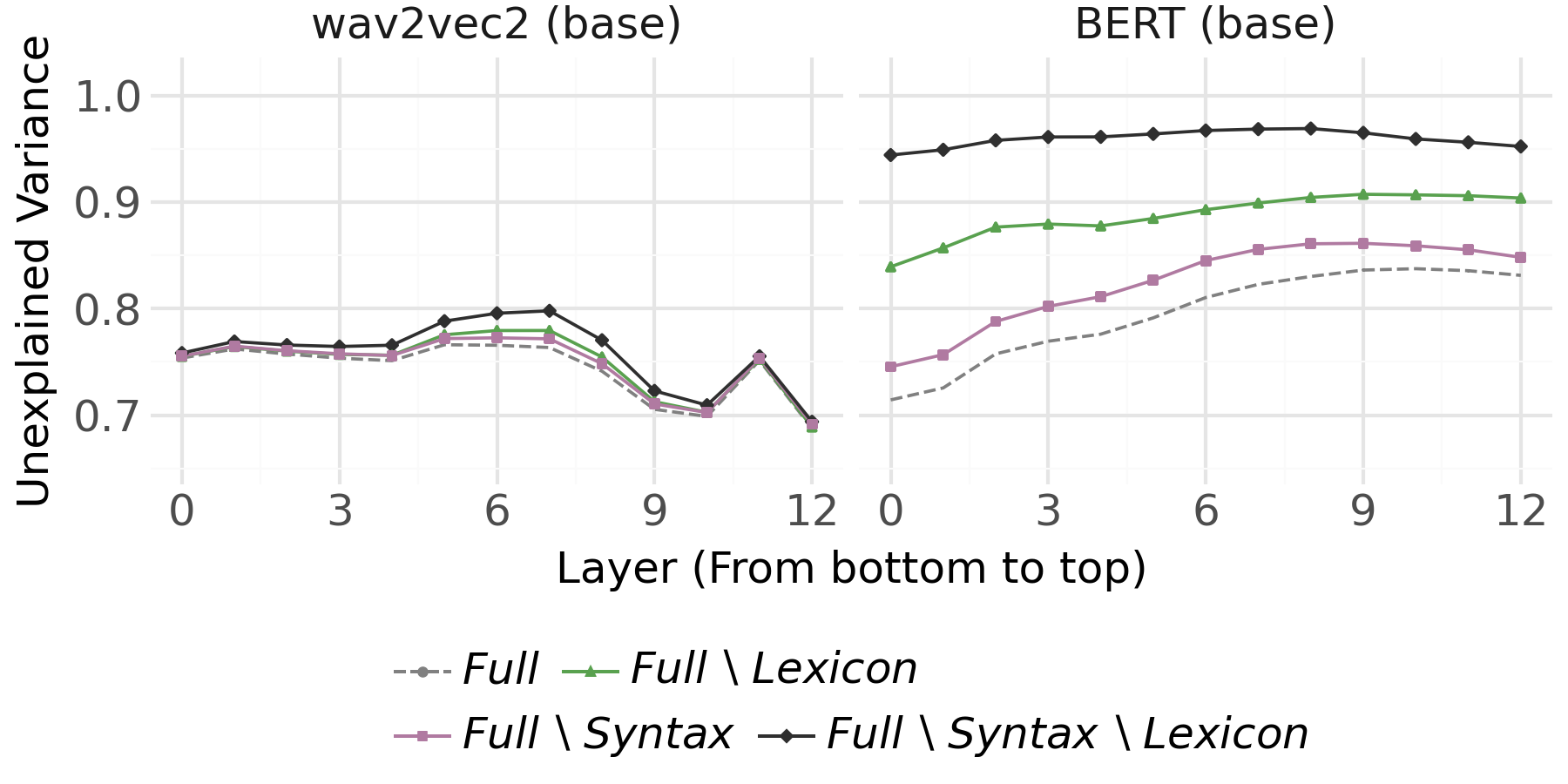
Syntactic versus Lexical Features
Applying the same methodology to BERT and speech transformer models for quantifying the unique contributions of syntactic and lexical features yields complementary insights.
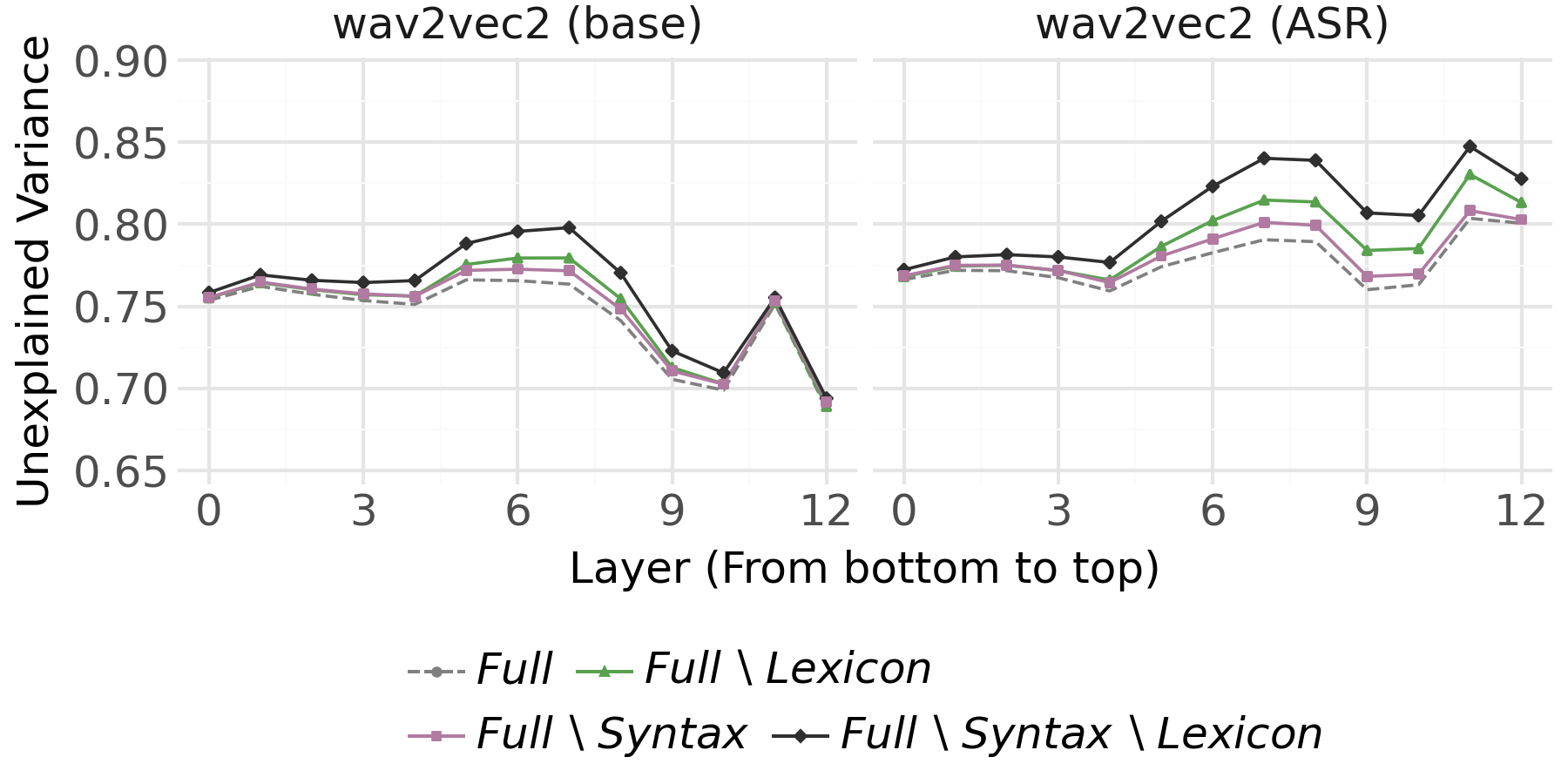
Figure 5: UV results for syntax/lexicon ablation in base BERT and wav2vec2 variants; lexical features dominate, but syntax is independently represented.
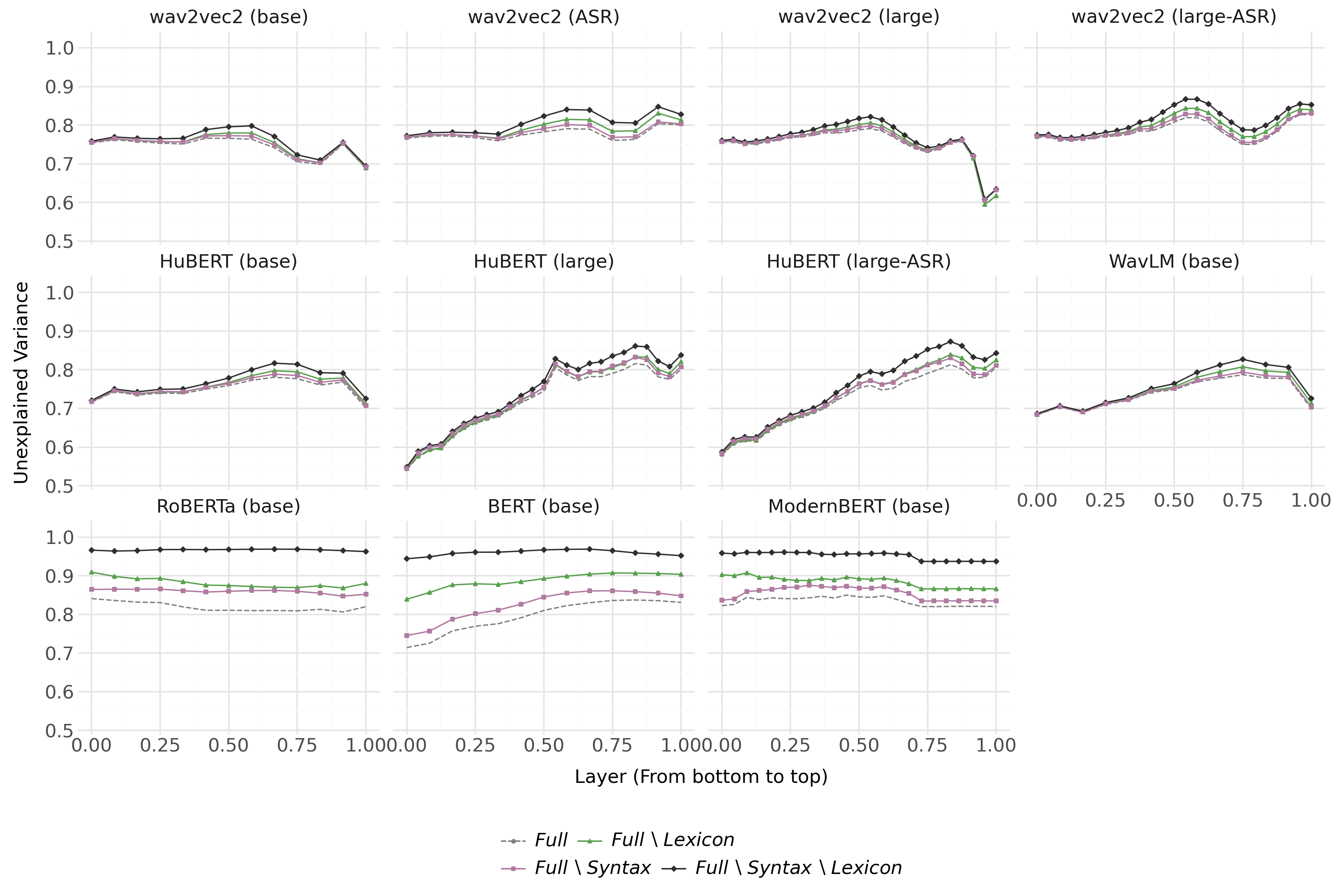
Figure 6: Encoding probe UV results across extended model suite for syntax and lexicon; lexical dominance is robust, but syntactic independence is consistent.
- The effect size of these ablations is much greater in text models than in speech models, indicating that BERT-style models develop richer, more distinct representations of both lexicon and syntax compared to speech transformers.
These findings contradict the hypothesis that syntactic decodability is fully mediated by lexical identity, demonstrating the presence of independent syntactic structure encoding, even in speech models with no explicit syntactic supervision.
Analysis of Feature Representation and Correlation
The study further demonstrates that the choice of feature vectorization (e.g., distributions versus one-hot encoding for phonetic properties) substantially affects encoding probe outcomes, much more so than for decoding probes (Figure 7). Additionally, tests for direct linear dependency show that speaker identity is poorly predictable from local acoustic or phonetic descriptors, and that static word embeddings do not strongly encode most syntactic annotations beyond coarse POS categories, supporting the orthogonality assumptions in the ablation analysis.
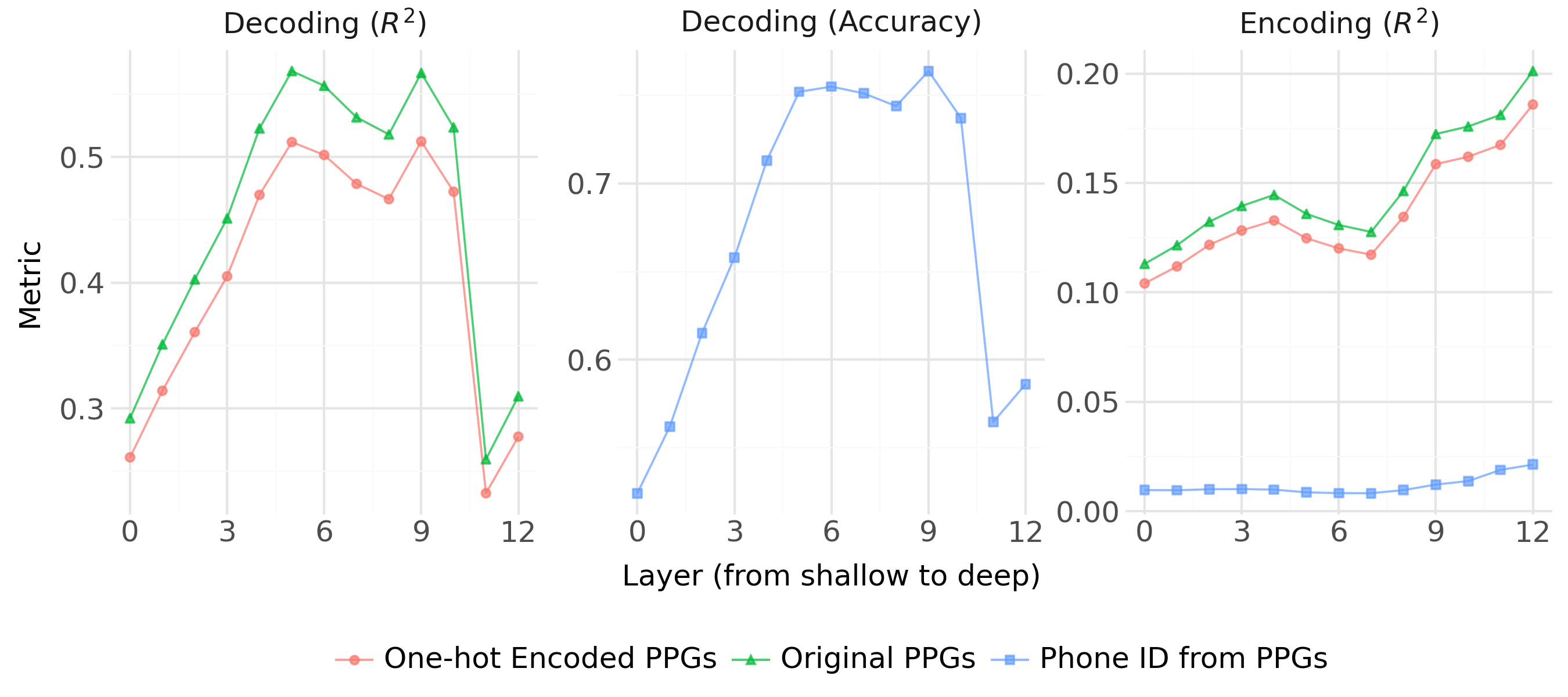
Figure 7: Comparison between encoding and decoding probe results using different representations of the same phonetic feature; encoding probes are sensitive to representation dimensionality.
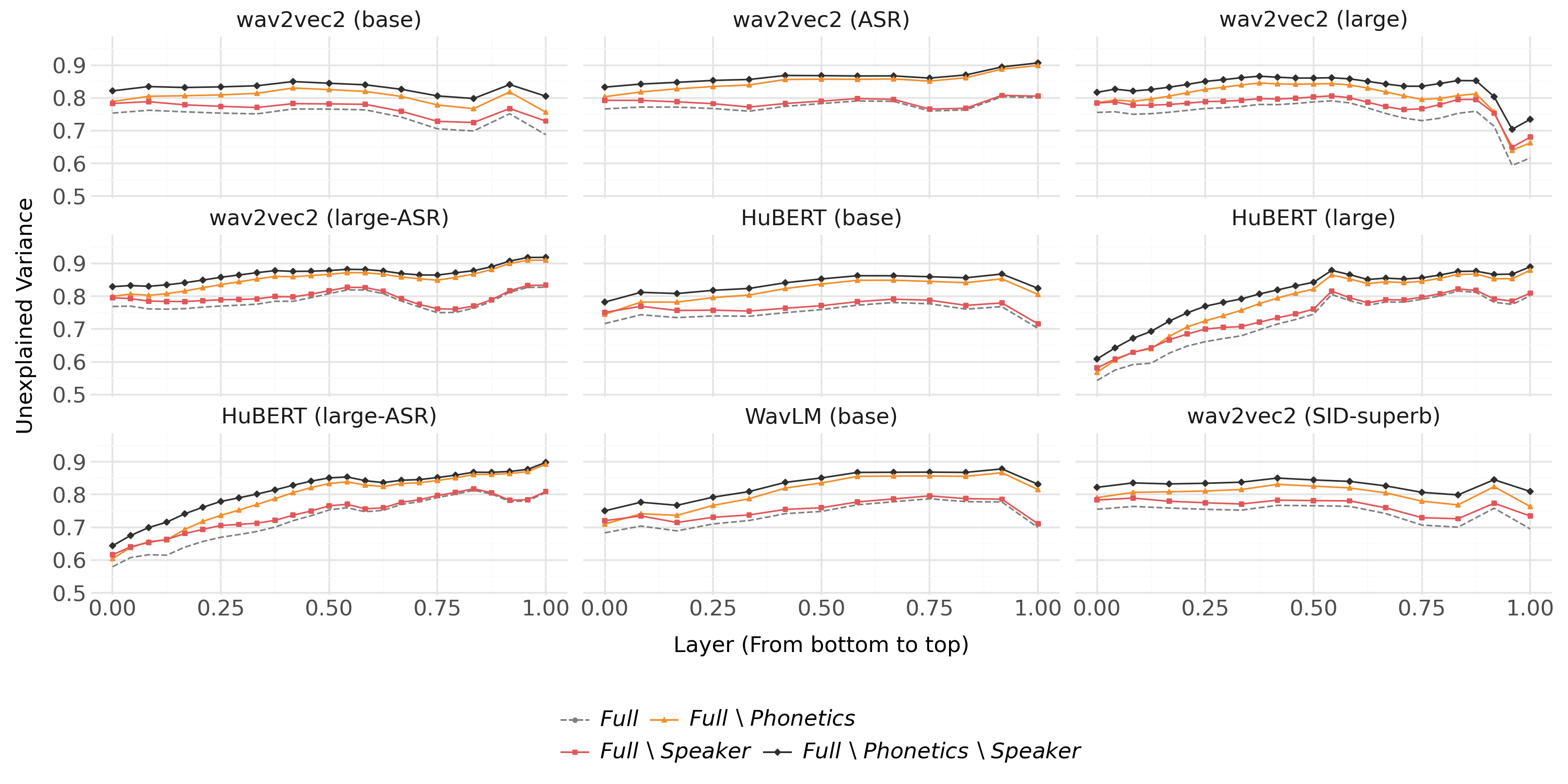
Figure 8: Encoding probe UV score results of phonetics and speaker identity for all models.
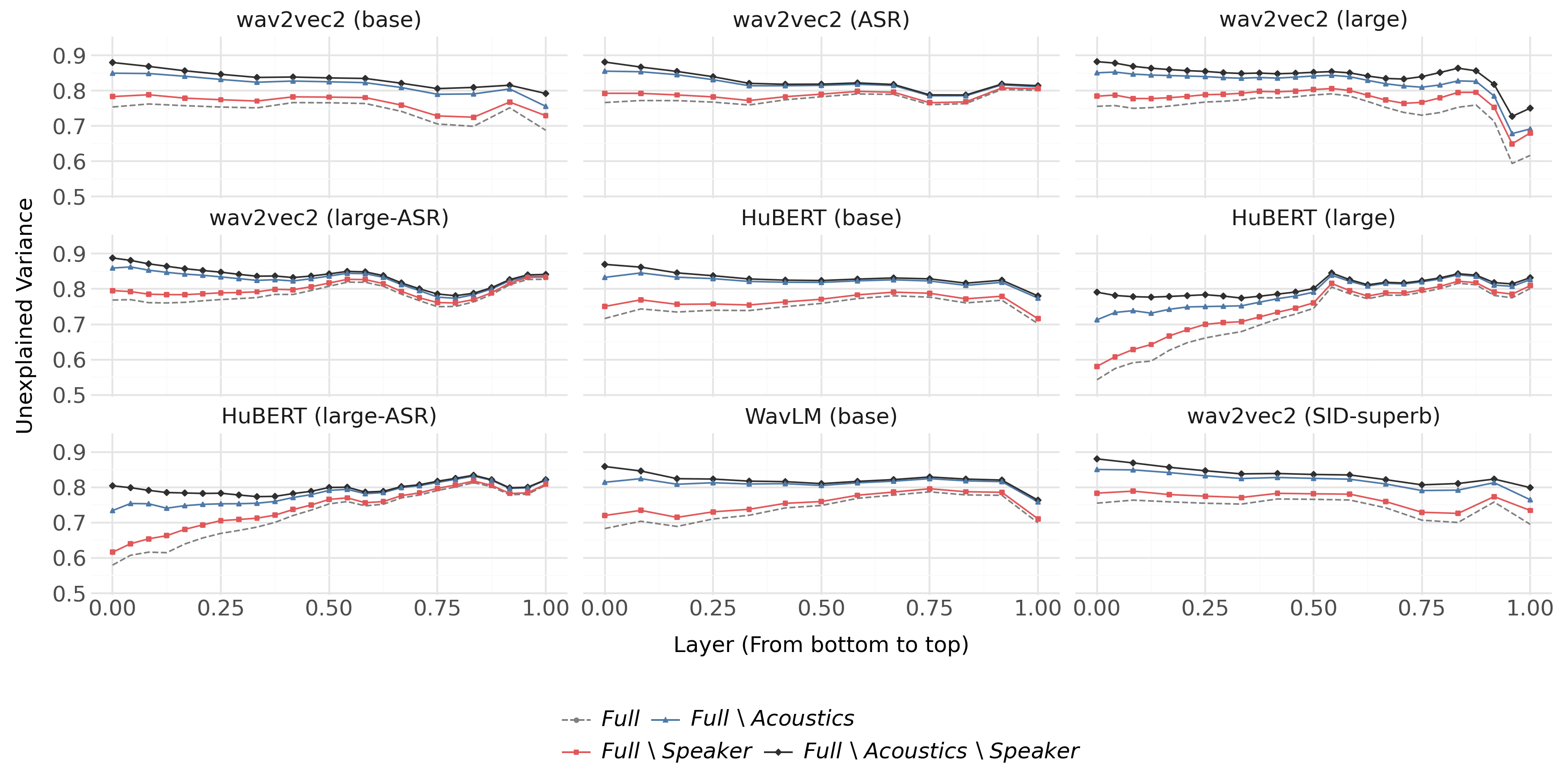
Figure 9: Encoding probe UV score results of acoustics and speaker identity for all models.
Theoretical and Practical Implications
The results provide robust evidence for the superiority of encoding probes in enabling both conditional, quantitative attribution of representation content and control over feature correlations—objectives that decoding probes cannot address in isolation. This enables more principled assessments of model privacy (e.g., speaker identity leakage), modularity, and specialization.
For speech models, the findings reinforce the need for task-aligned model selection or adaptation in applications where disentangling or masking speaker identity is required. In LLMs, quantification of independent syntactic structure has implications for parsing and syntax-sensitive generation tasks.
The encoding probe framework, grounded in multivariate regression, links model interpretability research with established methods from neuroscience and statistical learning, encouraging further integration of regression-based attribution analysis in model auditing and feature analysis pipelines. While the present study employs linear probes for clarity and comparability, future work may extend to nonlinear regression for capturing higher-order interactions and structure in more expressive models.
Limitations and Future Directions
The encoding probe shares with the decoding probe an observational (non-interventional) character: it cannot by itself establish causal contribution to downstream task performance or disentangle structural entanglement not captured by the chosen feature sets. The present analysis is conditional upon the operationalization of features—if salient properties are omitted, their influence cannot be quantified. Speech results are based on read audiobooks and may not fully generalize to spontaneous speech. Moreover, the use of linear probes, while interpretable, may under-represent the role of complex nonlinear dependencies intrinsic to transformer activation manifolds.
Future research directions include nonlinear encoding analysis, expansion of feature inventories (especially semantic representations), testing in realistic deployment scenarios (e.g., multilingual, multi-domain data), and explicit causal inference methods layered atop the encoding probe framework.
Conclusion
This work formally establishes the encoding probe as a rigorous, complementary alternative to the decoding probe for the analysis of model internal representations. It enables the principled quantification of the conditional contribution of interpretable features, properly controls for statistical correlation, and is applicable across both speech and text transformer architectures. The methodological insights provided here are technically significant for the interpretability community and bear practical implications for the design and evaluation of privacy, specialization, and modularity in deep neural LLMs.