- The paper introduces HeadScore and TokenScore to isolate attention head contributions for precise relation classification.
- It shows that per-head attention features achieve over 91% accuracy in few-shot setups, outperforming MLP and whole-state features.
- The study finds that relational complexity, including output range and entity connectedness, systematically modulates probe precision.
Tracing Relational Knowledge Recall in LLMs
Introduction
This paper offers a systematic dissection of how relational knowledge is recalled during text generation in contemporary LLMs, with particular emphasis on pinpointing which latent representations best support linear probes for relation classification. The authors examine both attention head and MLP contributions, addressing the limitations of previous studies that fail to unify or compare segment-level attribution (attention/MLP, heads/tokens) in the context of relation-type classification. The work is empirically grounded using four instruction-tuned LLMs, with results robust across two major open model families (LLaMA3 and Qwen3).
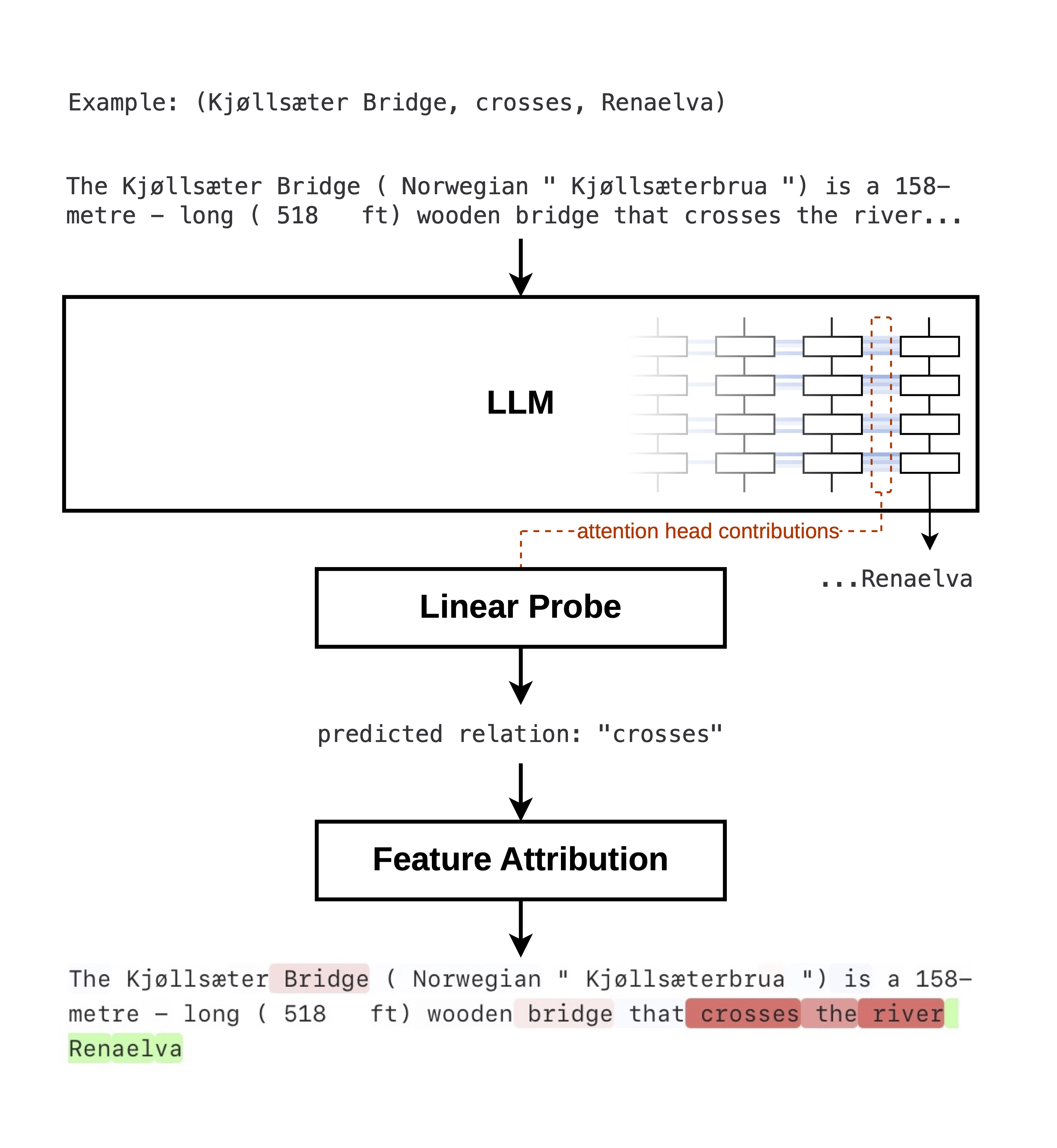
Figure 1: Illustration of attention head contribution probing and token-level feature attribution showing the most influential tokens affecting the probe's prediction.
Methodology
The study frames relation recall as the capacity to classify a relation type from LLM internal features at the "knowledge recall position"—typically, just before the generation of the object in a triple (subject, predicate, object). The feature extraction pipeline is mathematically precise: Attention head outputs to the residual stream at that position are decomposed per head (Δatt,h), per source token (Δatt,h(t,j)), and propagated through subsequent MLP gating and normalization (yielding ΔMLP,h and related variants).
The core innovation is the introduction of HeadScore and TokenScore: two attribution methods that decompose a linear probe’s output across either attention heads or source tokens. Given a trained linear probe, these scores enable precise isolation of evidence for specific relations within the LLM's computational graph, separating probe-driven signal from native model behaviors.
Empirical Evaluation
Feature Selection and Few-Shot Classification
The experimental protocol applies n-way k-shot classification over the FewRel dataset, using highly contextualized fill-in-the-blanks prompts that avoid fixed templates and mitigate prompt-induced lexical bias. Feature selection leverages per-episode average precision to build relation-specific input vectors for each probe.
Probes are systematically trained on a battery of candidate latent features: whole-layer attention or MLP states, per-head contributions, and per-token/attention head decompositions.
Key empirical findings:
- Per-head attention contributions (Δatt,h) yield the highest accuracy for relation classification, consistently outperforming both MLP-propagated and whole-state features.
- Classification accuracies in the 5-way-5-shot setup exceed 91% for LLaMA3-8B, confirming that Δatt,h features are maximally informative within the studied regime.
Effect of Relation-Specific Factors
To interrogate cross-relation performance variability, the authors conduct a multi-faceted correlation analysis, linking probe-level precision to several properties of relation types:

Figure 3: Correlations observed for probe precision (here for LLaMA-3.18B): output range, mean entity connectedness, TF-IDF similarity, and HeadScore concentration.
- Higher output range (i.e., more possible object values per relation) correlates with lower probe precision.
- Greater mean entity connectedness (number of possible Wikidata facts connecting sample pairs for the relation) is negatively associated with probe precision.
- Increasing distribution of HeadScore across many heads (lower sparsity/concentration) correlates with reduced probe accuracy.
- Relations with higher lexical similarity (TF-IDF) in their support examples tend to have higher probe precision, but this is secondary to the above structure-based effects.
Token-Level Analysis and Attribution
The TokenScore mechanism enables token-level attribution, facilitating fine-grained analysis of what linguistic or entity cues the probe exploits:
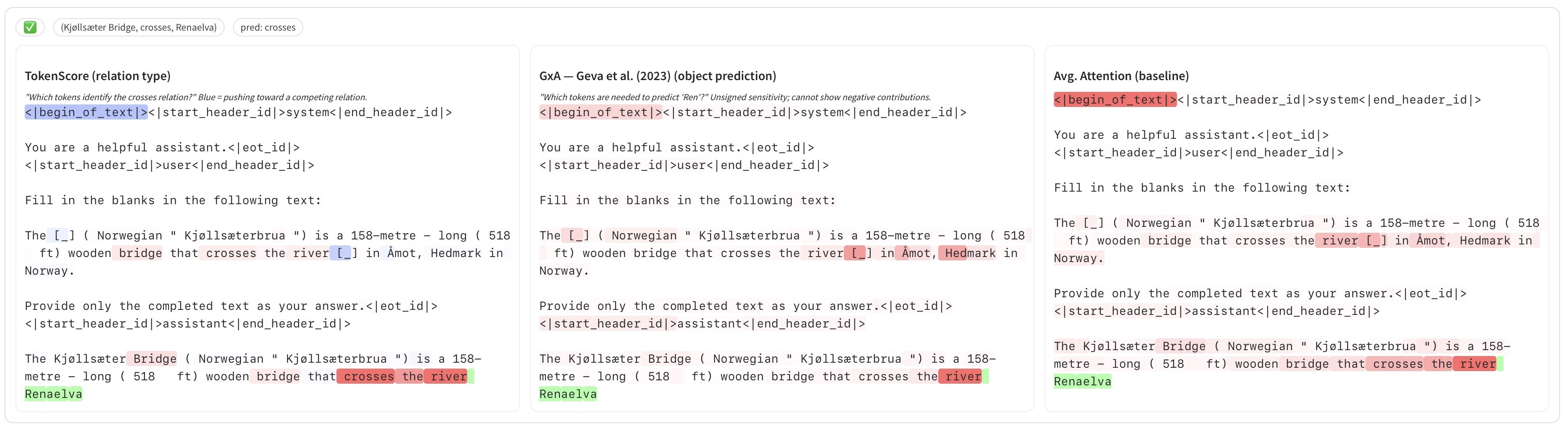
Figure 2: Example of a correct probe prediction for the relation type "crosses" in a 16-way-5-shot setting using LLaMA-3.11B−Instruct.
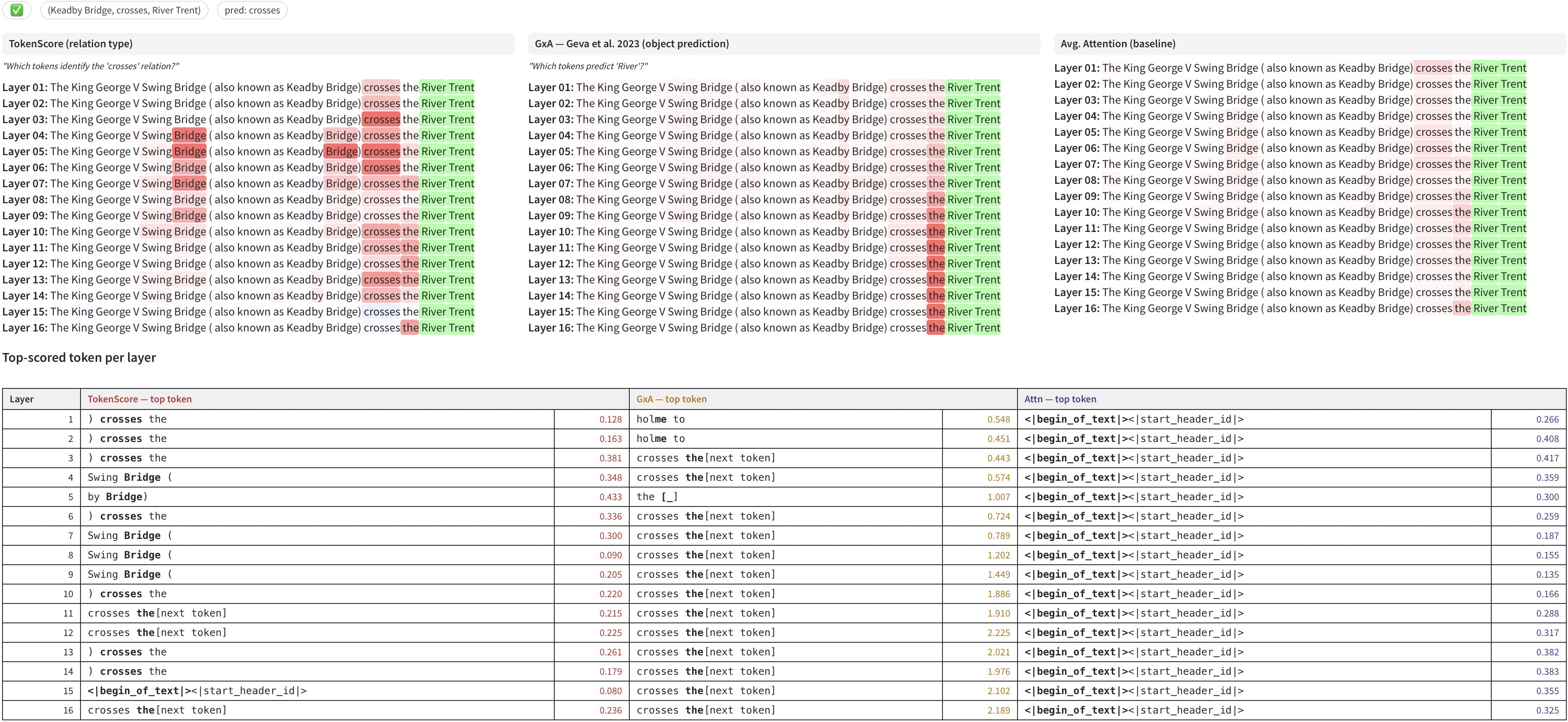
Figure 6: Layerwise TokenScore visualization demonstrates distribution of class evidence across prompt tokens and model layers.
The token-level analysis reveals that:
- Tokens with high attribution frequently align with relation-relevant predicates or entity cues but are not trivially coextensive with tokens salient under bag-of-words or TF-IDF analysis.
- Only a minority (5–7%) of probe errors can be attributed to strong lexical shortcutting, as evidenced by the low TokenScore–lexical alignment.
Architectural Analysis
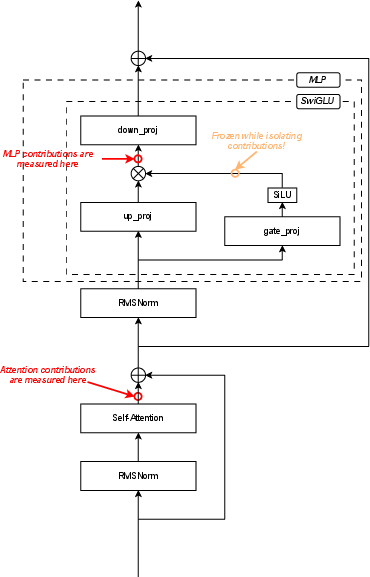
Figure 4: Overview of where attention and MLP contributions are measured in the LLaMA architecture.
Feature tracing within the LLaMA block highlights that the nonlinearities of the MLP stage (e.g., SiGLU gating) do not yield additive improvements over the attention-based features for relation classification; attention head outputs prior to this transformation retain the maximal signal for probeability.
Error and Alignment Analysis
Additional qualitative analysis using TokenScore uncovers instances where model-internal entity attribution diverges from annotated labels, for instance, where synonymous entity mentions are available. This underscores the limitations of static annotation versus dynamic model representations.

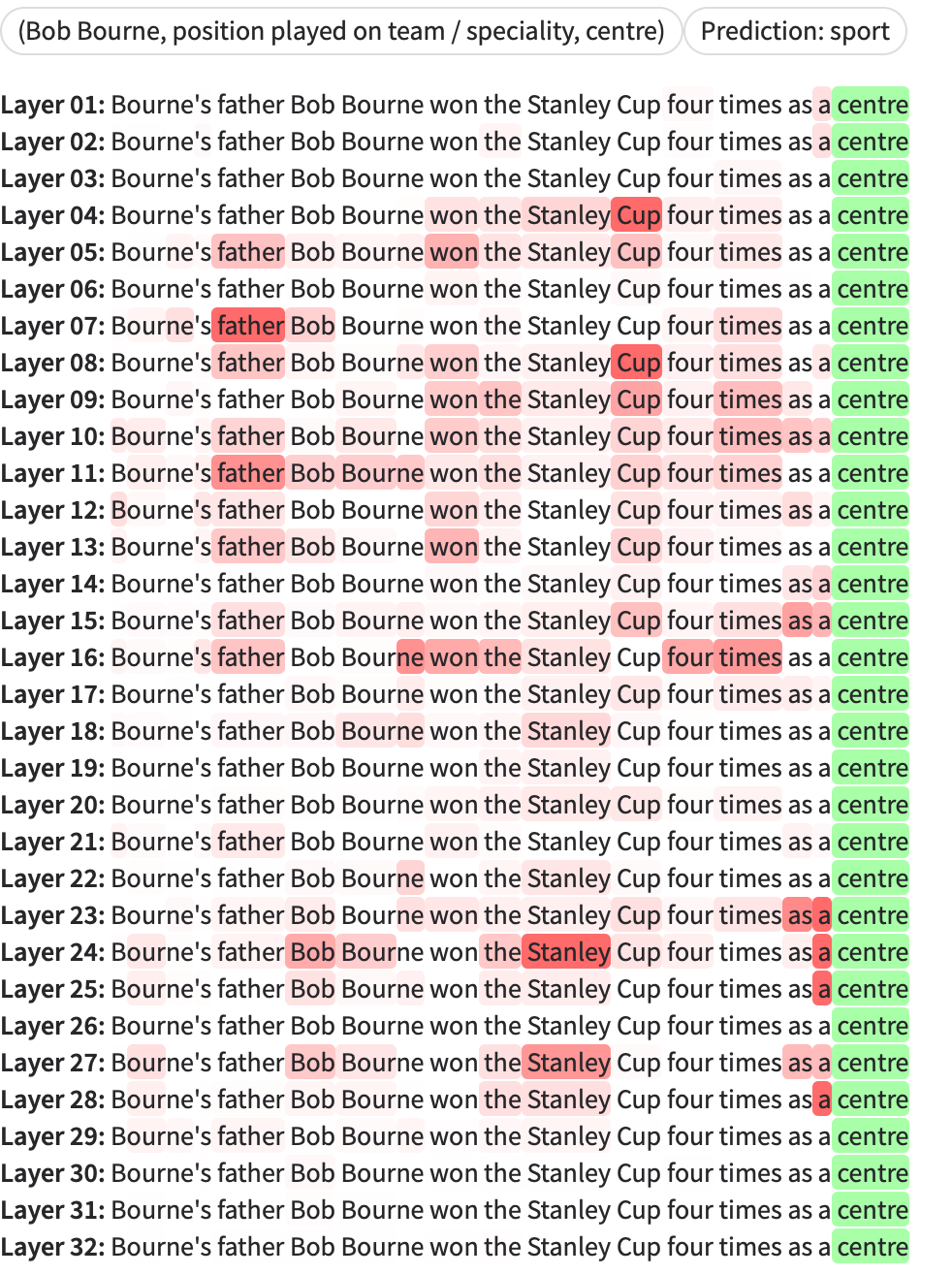
Figure 5: Example showing misalignment of subject entities per annotation versus attention head features (TokenScores), with the model correctly focusing on an alias entity mention.
Implications
Practical implications:
- The clear superiority of per-head attention contributions for faithful linear probing implies that relation classification, for the studied relations, can be robustly diagnosed and potentially intervened upon at the attention mechanism level.
- Probe-side HeadScore concentration provides a data-agnostic diagnostic for probe reliability—a potentially valuable tool in scenarios with limited labeled data or unexplored relational spaces.
Theoretical implications:
- Observed dependencies of probe performance on relation output range and connectedness support a feature superposition perspective: as relational structure complexity (e.g., many-to-many mappings) increases, linear separability of relation-specific features in the residual stream is degraded.
- The fact that only a small fraction of probe errors are lexically aligned suggests a level of abstraction in LLM internal representations not reducible to surface cues.
Future directions:
- Extending probe attribution to open-world extraction and not-only relation classification, integrating NOTA and negative-case reasoning.
- Applying the HeadScore/TokenScore diagnostic framework to other interpretability tasks: coreference, event structure, and compositional reasoning.
- Leveraging the identified relation-specific head subsets for model editing or controlled generation.
- Controlled interventions to disambiguate the effects of relation specificity, connectedness, and feature superposition.
Conclusion
This study provides a formal, empirical, and attributionally transparent account of how current LLMs encode and recall relational facts for inference-time extraction. The critical finding is that per-head attention contributions are the most robust features for relation classification via linear probes, with performance systematically modulated by relation structural properties. Token- and head-level attributions furnish interpretable mechanisms for inspecting, diagnosing, and potentially steering model behavior in relation-centric tasks. Probe reliability is not solely a function of lexical surface form but crucially depends on the interaction between relational structure and attention-based representational geometry. The tools and methodology advanced enable more granular scrutiny and possible manipulation of relational knowledge in LLMs, guiding both interpretability research and targeted model interventions.

